

Learn best practices for debugging and error handling in an enterprise-grade blo...
source link: https://developer.ibm.com/blogs/debugging-and-error-handling-best-practices-in-a-blockchain-application/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Blog Post
Learn best practices for debugging and error handling in an enterprise-grade blockchain application
Identify where failures take place and resolve them
Blockchain is a shared, replicated immutable ledger for recording transactions, tracking assets, and building trust. An asset can be tangible (for example, a house or a car) or intangible (for example, intellectual property or patents). Blockchain is built on properties like consensus, provenance, immutability, finality.
In a traditional business scenario, a transaction that involves multiple organizations is recorded differently by each business. If two organizations disagree on the state of a transaction, then a dispute occurs, which can often be costly and time consuming to resolve. Blockchain introduces the following concepts:
- Multiparty transactions: Signed by everyone involved in the transaction.
- Shared ledgers: The same ledger is replicated in every organization in the network and kept synchronized using a process called consensus. Ledgers are immutable and final; after a multiparty transaction is written to the ledger, it cannot be reversed.
To get an overview of blockchain in more detail, check out the Get started with blockchain learning path. This blog post focuses on different points of failures in a typical blockchain-based application, possible reasons for failures, and recommended debugging and error handling techniques.
The importance of error handling
In cloud-based application deployments that involve multiple integration points, there is always a possibility of encountering transient failures. Planning for and handling these transient failures is important to maintain a resilient architecture.
Unhandled error conditions can lead to failures and system crashes, and they often expose the application in a vulnerable state. Good exception handling can help to anticipate errors or systems crashes in advance and then put in appropriate code to recover from them. It might not be possible to handle all exceptional cases or unexpected conditions, but a well designed system ensures graceful exit without causing any major issues, inconsistencies, and security vulnerabilities to the system.
Helpful blockchain terminology
- Peer: Maintains ledger and state, commits transactions, and can also endorse transactions by receiving a transaction proposal and responding by granting or denying endorsement (must hold smart contract to endorse).
- Ordering node: Orders and packages transactions into blocks and then communicates these blocks to committing peers.
- CA: Issues digital certificates to member organizations and their users.
- Channels: Channels provide privacy between different ledgers. Ledgers exist in the scope of a channel.
- Smart contract: Contains the business logic that governs how data is written to and read from the ledger.
- Transaction: Any operation that modifies the ledger state is recorded as a transaction, such as asset exchange or a transfer.
- Ledger: A ledger is maintained by each peer and includes the blockchain and world state.
- Identity: The resources that you can access in a network are determined by the identity and is typically represented by an X.509 certificate issued by the CA.
- Endorsement policy: Describes the conditions by which a transaction can be endorsed. A transaction can only be considered valid if it has been endorsed according to its policy.
- Connection profile: Contains network information such as node level connection information, TLS certs, and more.
The following image represents the steps involved in a regular blockchain transaction flow:
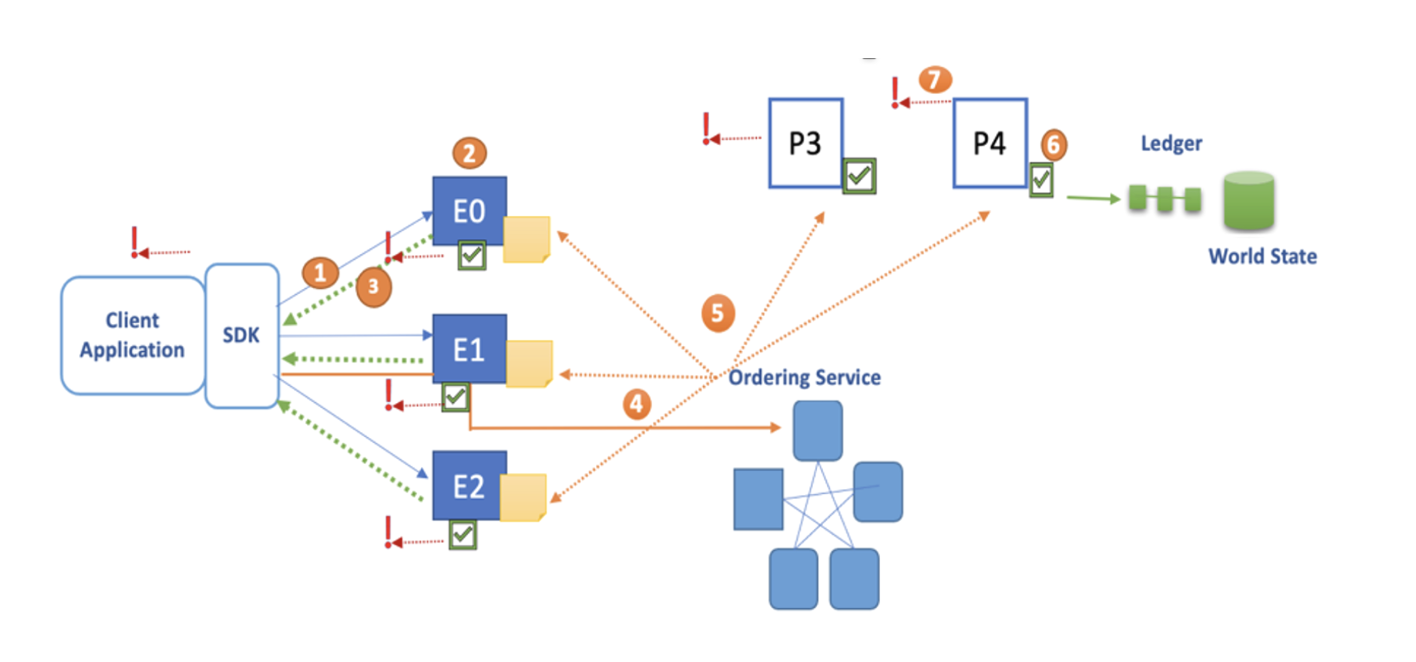
- Client application submits a transaction proposal.
- Endorsers E0, E1, and E2 each execute the proposed transaction. None of these executions update the ledger. Each execution captures the set of Read Write data (called an RW-set), which now flows in the fabric.
- Application receives responses. The RW-sets are signed by each endorser and also include each record version number.
- Application submits proposal responses as a transaction for ordering.
- Orderer sends blocks to committing peers.
- Committing peers validate transactions. Validated transactions are applied to the world state and retained on the ledger.
- Application is notified when a block is committed to the ledger of a peer.
Potential errors in a blockchain network
Errors can arise at any point of the transaction and are caused by the underlying network, business logic, outdated data, or network time-outs. You can resolve errors that are not caused by application input or incorrect usage by adding the right error handling and retry mechanism in the application layer to build in application resiliency.
Errors generally fall into one of two categories:
- Retryable: Errors from chain code or the network should be propagated back to the application layer for error handling and a retry mechanism.
- Nonretryable: Errors that are caused by incorrect usage should be handled leading to a graceful exit of the code path.
Network errors
A Hyperledger Fabric node or Java client communicates with the Hyperledger Fabric network using gRPC. The gRPC technology handles moving data reliably between the Fabric network and the Fabric client application. The application sets the gRPC settings based on the application usage.
Problem summary
grpc request timeout while submitting the proposal
This timeout typically happens at any stage of blockchain transaction flow. In the previous image, the time out occurs during Steps 1-4 where the client communicates with the network due to network latency, unavailability of the chain code container, or poor peer health.
Error message:
sendPeersProposal - Promise is rejected: Error: REQUEST_TIMEOUT
Peer{ id: 1 , name: peer1.org1.example.com, channelName: mychannel,
url:grpcs://192.168.1.1:7051, mspid: Org1MSP} failed because of
timeout(35000 milliseconds) expiration
java.util.concurrent.TimeoutException: null
Request timeout during the execution of a proposal
This error occurs when the time taken for executing the proposal exceeds the configured execution time default of 30 seconds. As a best practice, you should limit the computations or operations that can be performed in a smart contract, and if the application logic does not support the same, then you can increase the execution timeout to mitigate the issue.
This error can be thrown by the lifecycle system chaincode (LSCC) in Hyperledger Fabric as well during the startup of the chaincode container. However, the resolution stays the same in this case as well.
Error message:
"peer1.org.com:7051" failed: message=failed to execute transaction 799eb959954a7f2f8f75dee735969a4ba374b4bc98b4bbacd2fc85fc57a860b9: error sending: timeout expired while executing transaction, stack=Error: failed to execute transaction 799eb959954a7f2f8f75dee735969a4ba374b4bc98b4bbacd2fc85fc57a860b9: error sending: timeout expired while executing transaction
Recommended handling
- Set CORE_CHAINCODE_EXECUTETIMEOUT =<60s or higher> in the Fabric configuration for handling the request timeout during the execution of a proposal.
Set the following gRPC settings at the Fabric client end to help increase the gRPC timeout, which generally happens because of network latency:
"grpc.keepalive_time_ms": 120000, "grpc.http2.min_time_between_pings_ms": 120000, "grpc.keepalive_timeout_ms": 20000,- Check the Fabric client time out configuration and tune it based on the application processing logic and network recommendations.
- Check the peer health and the health of IO operations at the peer, and if the peer is not healthy, a restart might resolve the issue.
- Client-side retry handling: Timeout Exception should be categorised as a retryable error and handled by writing retry logic on the client side. You can use a simple retry handling of this exception with exponential backoff to recover if it is caused by intermittent network issues.
MVCC_READ_CONFLICT errors
Read-write sets are generated by the peer when a transaction is submitted to a peer. This read/write set is then used when the transaction is committed to the ledger. It contains the name of the variables to be read/written and their version when they were read.
Problem summary
Every peer in the network (VSCC) validates the number of signed proposals and the version of every read key in the read-write sets against the world state upon receiving the blocks from the ordering service.
If, during the time between set creation and committing, a different transaction was committed and changed the version of the key in the peer’s current world state, then the original transaction is rejected during committal because the version when read is not the current version. This error is typically seen during commit.
Error message:
Peerpeer1.org.com:7051 has rejected transaction "c91172484bad08eaae2595522a0a8c0a30891b4a90110e0a4fc490c0aacdb399" with code "MVCC_READ_CONFLICT" , validationCode=11
Recommended handling
To address this scenario, at the design level, you can create data and transaction structures that avoid editing the same key concurrently. Take a look at the Hyperledger Fabric samples for an example of how to do this.
The application needs to avoid key collisions as much as possible and might need to write retry logic on the client side. The retry logic should query the latest state of the key from the ledger and apply the required changes on the latest state.
Client-side retry handling
If(validationCode == 11) {
Object a = // query the ledger again for the latest state.where a being an object on the ledger
//perform the writes on a
a.setAction() }
In a typical blockchain transaction flow, when applications are registered to be notified when a block is committed to the ledger of a peer, when the transaction fails, the notification typically has VALIDATION_CODE: 11, which indicates MVCC_READ_CONFLICT.
You can also consider VALIDATION_CODE: 12 that indicates PHANTOM_READ_CONFLICT under the same category.
A sample blockchain event:
[eventTransactionId: f948056aa59d42810d3318dc1df7643152e220d3bb75924d5228a5e9efb95017, ,status: failure,eventName: xxxx,actionType: xxxx,errorCode: VALIDATION_CODE: 11,errorMessage:null,validationCode:11,channel: xxxx,blockNum: 24712079]
The blockchain event includes the transaction ID that was submitted and the details indicating whether it was committed on the blockchain or not. The status: failure indicates the block was not committed and validationCode indicates the reason for failure. In this example, VALIDATION_CODE:11 indicates there was MVCC_READ_CONFLICT. VALIDATION_CODE: 12 indicating PHANTOM_READ_CONFLICT also falls in the same category.
Sample retry code:
If ( blockChainNotificationObject.getValidationCode() == 11 || blockChainNotificationObject.getValidationCode == 12 ){
1.Query Ledger to get the latest state of the Object
2. if the state is already performed/applied
{//probably parallel duplicate invocation
2.1 Consider the event as success and proceed the application logic }
3.else{ apply the required changes on the latest state and retry the Transaction }}
Peer lag errors
Network delays can often lead to the peers being out of sync where one peer might be still catching up with the latest block. So, any queries made on the lagging peer would return an outdated state that might no longer be valid for the application.
Problem summary
P1 and P2 are two peers, and K1 is the new key added to the ledger. Because of network latency, K1 is not yet added to P2’s ledger. The application has queried for K1 on P2, which would receive a null value.
Recommended handling
It is important that you program the application to identify and handle inconsistent data caused by peer lag. Applications should have a mechanism to listen to block addition events and ascertain that the block has been added successfully. In the case of inconsistent behaviour or null values returned while querying, then you can implement retry logic to ascertain the state update. A retry with exponential backoff provides the time for peers to overcome the network issues/delay and sync up on the state.
Endorsement policy failures
All transactions need to be endorsed by the endorsing peers in the execution phase (second step) of a blockchain transaction flow. The endorsement of transactions can fail for multiple reasons, such as invalid endorser signatures or other technical reasons. Most of the possible causes for endorsement policy failures are because of misconfigurations or transient world state inconsistencies between the peers. The key-value store, which maintains the world state, is updated by each peer independently in the validation phase. Therefore, transient world state inconsistencies between the peers are possible. At the same time, the endorsing peers use the world state to generate read/write sets in the execution phase. Thus, the world state inconsistencies lead to a read/write set mismatch in the endorsement response causing an endorsement policy failure of the transaction.
Recommended handling
- In the case of endorsement policy failures due to misconfigurations, the you need to validate the configurations and correct them.
- Applications can have resiliency and retry logic in place and try fetching endorsements from every peer in an organization before giving up.
- The application can change the endorsement policy, based on its logic. To change the endorsement policy, you can specify Channel/Application/Endorsement in configtx.yaml to ANY endorsement. Fabric uses this configuration as the default endorsement policy in all chaincode.
- In the case of the world state inconsistencies, it is recommended to have client side retry logic as discussed in the MVCC_READ_CONFLICT errors section.
Chaincode errors
Chaincode to chaincode communication error
There are applications where chaincode business logic would require communication with other chaincode to enforce a rule or logic.
Problem summary
Chaincode to chaincode communication can fail because of multiple reasons, such as unavailability of particular chaincode on a given channel or the dependent chaincode not being ready to accept requests. Some of the errors fall under nonretryable errors like INVALID CHAINOCDE NAME, INVALID CHAINOCDE VERION, INVALID ARGUMENTS, and CHAINCODE_UNAVAILABLE. You should handle other chaincode to chaincode communication errors by having retry logic on the client side.
Error message:
Error: INVOKE_CHAINCODE failed: transaction ID: f6ab6dbd747ddf25ebfe158eea5a9b0b7478d6a031b66a08a4f3c2f02fe2f7fe: cannot retrieve package for chaincode test/1.0, error open /var/hyperledger/production/chaincodes/test.1.0: no such file or directory"
This message indicates that the chaincode container is unavailable. However, if you have ascertained that the chaincode is installed and instantiated on the peers and is only unavailable because of the dependent container startup delay, then you can implement customized handling at the application resiliency layer to recover the transient failure.
Recommended handling
To handle chaincode to chaincode communication errors, unique error codes can be propagated by the caller chaincode and the client application can be programmed to identify and categorise these as retriable errors based on the same. You can retry with exponential backoff for recovery.
No LedgerContext found error
Some of the errors are not thrown as part of the validation phase VSCC but occur during the execution phase. There could be multiple reasons for these errors, and they often happen if any of the operations on the ledger are taking longer than the expected time.
Error message:
ERRO 09f [ddc81d1b] Failed to handle PUT_STATE. error: no ledger context runtime.goexit /opt/go/src/runtime/asm_amd64.s:1333 PUT_STATE failed: transaction ID: ddc81d1bcb69eecd6c6bbcf85ba16b2168486d4b232ef3c03fe5bbc7bb2adea1 github.com/hyperledger/fabric/core/chaincode. runtime.goexit
Recommended handling
These error scenarios can be handled in chaincode wherein a unique error code can be propagated by the chaincode and the client application can be programmed to identify and categorise these as retriable errors based on the same. You can retry with exponential backoff for recovery.
ValidationCode=17 and ValidationCode=18 errors
Some of the chaincode invocation can fail with error validationCode=17 or validationCode=18. validationCode=17 indicates EXPIRED_CHAINCODE and validationCode=18 indicates CHAINCODE_VERSION_CONFLICT.
Problem summary
The transaction submitted on an older chaincode container that later expired because of the availability of a new container; during the validation phase (VSCC), the transaction gets rejected.
Error message:
Nov 22 16:32:52 peerxxxxxxx-r2yyyy peer 2021-11-22 11:02:52.180 UTC [valimpl] preprocessProtoBlock -> WARN fdd59 Channel [XXXXX]: Block [22596691] Transaction index [3] TxId [2224af5907927c60fad8b39f82537620b89d438ee5c44229533a3779985b833f] marked as invalid by committer. Reason code [EXPIRED_CHAINCODE]
Recommended handling
You can program the client to identify and categorise these as retryable errors. You can retry with exponential backoff for recovery.
Summary
These are some of the major types of errors that you might run into in any blockchain-based application. By understanding these points of failure ahead of time, you can have the right configurations, error handling, and recovery strategies in place from the design phase to deployment. This is crucial to building a resilient architecture.
Recommend
-
37
Benchling is a data platform to help scientists do research. Hundreds of thousands of scientists across academic labs and enterprise companies use Benchling to store and analyze s...
-
14
Poltergeist 0.6.0: Javascript error handling and remote debugging 15 April 2012 Recently I pushed version 0.6.0 of Poltergeist. This version brin...
-
7
-
15
React Error Handling and Logging Best PracticesHow to handle errors and properly log them using the right tools
-
9
<?xml encoding="utf-8" ??>Introduction This guide explains error handling in Go and the best practices for handling API errors in Go. You should have a working knowledge of Go and understand how...
-
12
Quick Microsoft .NET 6 Overview Microsoft .NET 6 is a cross-platform framework that merges the .NET Core, .NET Framew...
-
7
Robust Error Handling and Debugging in AWS KinesisIntroductionSince Flexport began its transition to a service-oriented architecture (SOA), we’ve started using
-
4
Introduction One of the challenges of working with any graphics API is that under the hood they tend to be very asynchronous in nature. The work you send to the GPU isn’t completed the moment you call draw or dispatch,...
-
10
Debugging and Error Handling Daniel Opitz - Blog Developer, Trainer, Open Source Contributor Blog
-
11
Avoiding Silent Failures in Python: Best Practices for Error Handling By Bob Belderbos on 7 August 2023 ...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK