
3

Flink的sink实战之二:kafka
source link: https://blog.51cto.com/zq2599/5141957
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Flink的sink实战之二:kafka
推荐 原创欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码): https://github.com/zq2599/blog_demos
- 本文是《Flink的sink实战》系列的第二篇,前文 《Flink的sink实战之一:初探》对sink有了基本的了解,本章来体验将数据sink到kafka的操作;
版本和环境准备
- 本次实战的环境和版本如下:
- JDK:1.8.0_211
- Flink:1.9.2
- Maven:3.6.0
- 操作系统:macOS Catalina 10.15.3 (MacBook Pro 13-inch, 2018)
- IDEA:2018.3.5 (Ultimate Edition)
- Kafka:2.4.0
- Zookeeper:3.5.5
请确保上述环境和服务已经就绪;
- 如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示( https://github.com/zq2599/blog_demos):
名称 链接 备注
项目主页 https://github.com/zq2599/blog_demos 该项目在GitHub上的主页
git仓库地址(https) https://github.com/zq2599/blog_demos.git 该项目源码的仓库地址,https协议
git仓库地址(ssh) [email protected]:zq2599/blog_demos.git 该项目源码的仓库地址,ssh协议
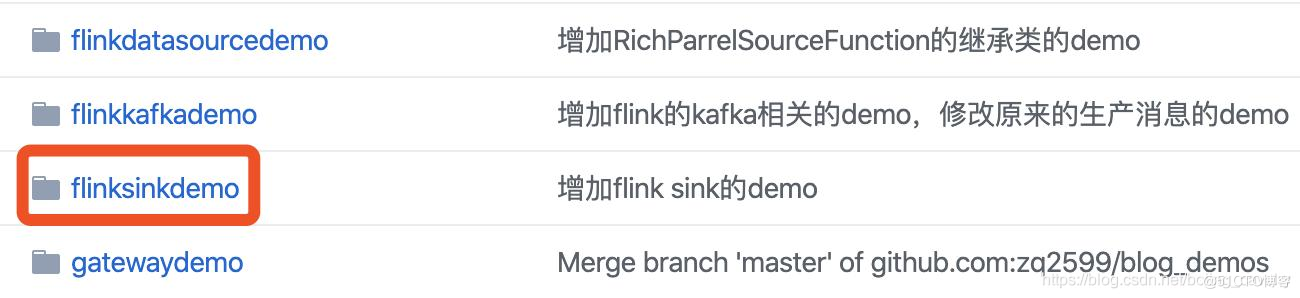
- 这个git项目中有多个文件夹,本章的应用在flinksinkdemo文件夹下,如下图红框所示:
- 准备完毕,开始开发;
- 正式编码前,先去官网查看相关资料了解基本情况:
- 地址: https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/connectors/kafka.html
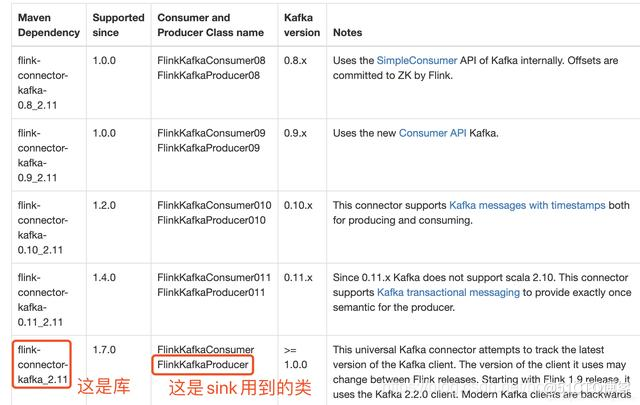
- 我这里用的kafka是2.4.0版本,在官方文档查找对应的库和类,如下图红框所示:
kafka准备
- 创建名为test006的topic,有四个分区,参考命令:
./kafka-topics.sh \
--create \
--bootstrap-server 127.0.0.1:9092 \
--replication-factor 1 \
--partitions 4 \
--topic test006
- 在控制台消费test006的消息,参考命令:
./kafka-console-consumer.sh \
--bootstrap-server 127.0.0.1:9092 \
--topic test006
- 此时如果该topic有消息进来,就会在控制台输出;
- 接下来开始编码;
- 用maven命令创建flink工程:
mvn \
archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.9.2
- 根据提示,groupid输入com.bolingcavalry,artifactid输入flinksinkdemo,即可创建一个maven工程;
- 在pom.xml中增加kafka依赖库:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.9.0</version>
</dependency>
- 工程创建完成,开始编写flink任务的代码;
发送字符串消息的sink
- 先尝试发送字符串类型的消息:
- 创建KafkaSerializationSchema接口的实现类,后面这个类要作为创建sink对象的参数使用:
package com.bolingcavalry.addsink;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.nio.charset.StandardCharsets;
public class ProducerStringSerializationSchema implements KafkaSerializationSchema<String> {
private String topic;
public ProducerStringSerializationSchema(String topic) {
super();
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, Long timestamp) {
return new ProducerRecord<byte[], byte[]>(topic, element.getBytes(StandardCharsets.UTF_8));
}
}
- 创建任务类KafkaStrSink,请注意FlinkKafkaProducer对象的参数,FlinkKafkaProducer.Semantic.EXACTLY_ONCE表示严格一次:
package com.bolingcavalry.addsink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KafkaStrSink {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并行度为1
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
String topic = "test006";
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(topic,
new ProducerStringSerializationSchema(topic),
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
//创建一个List,里面有两个Tuple2元素
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
list.add("ddd");
list.add("eee");
list.add("fff");
list.add("aaa");
//统计每个单词的数量
env.fromCollection(list)
.addSink(producer)
.setParallelism(4);
env.execute("sink demo : kafka str");
}
}
- 使用mvn命令编译构建,在target目录得到文件flinksinkdemo-1.0-SNAPSHOT.jar;
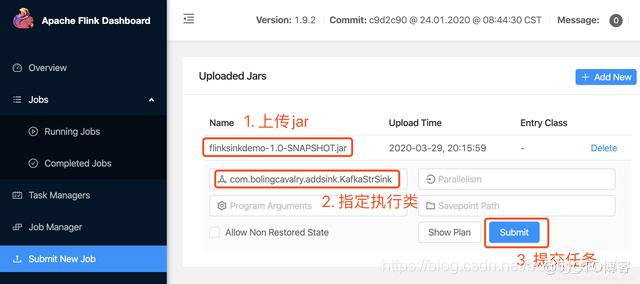
- 在flink的web页面提交flinksinkdemo-1.0-SNAPSHOT.jar,并制定执行类,如下图:
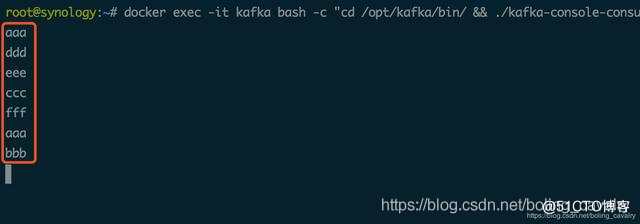
- 提交成功后,如果flink有四个可用slot,任务会立即执行,会在消费kafak消息的终端收到消息,如下图:
- 任务执行情况如下图:
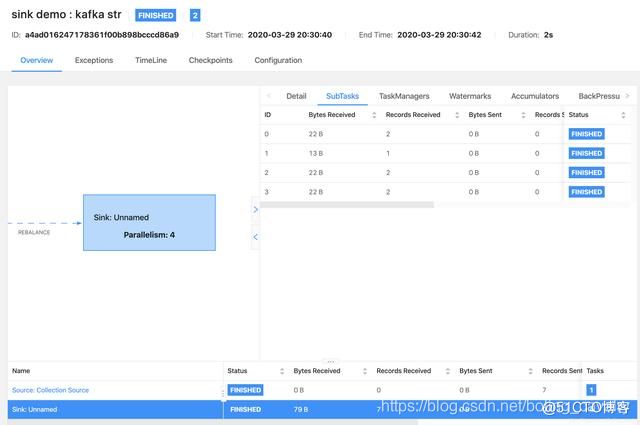
发送对象消息的sink
- 再来尝试如何发送对象类型的消息,这里的对象选择常用的Tuple2对象:
- 创建KafkaSerializationSchema接口的实现类,该类后面要用作sink对象的入参,请注意代码中捕获异常的那段注释:生产环境慎用printStackTrace()!!!
package com.bolingcavalry.addsink;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.JsonProcessingException;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
public class ObjSerializationSchema implements KafkaSerializationSchema<Tuple2<String, Integer>> {
private String topic;
private ObjectMapper mapper;
public ObjSerializationSchema(String topic) {
super();
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(Tuple2<String, Integer> stringIntegerTuple2, @Nullable Long timestamp) {
byte[] b = null;
if (mapper == null) {
mapper = new ObjectMapper();
}
try {
b= mapper.writeValueAsBytes(stringIntegerTuple2);
} catch (JsonProcessingException e) {
// 注意,在生产环境这是个非常危险的操作,
// 过多的错误打印会严重影响系统性能,请根据生产环境情况做调整
e.printStackTrace();
}
return new ProducerRecord<byte[], byte[]>(topic, b);
}
}
- 创建flink任务类:
package com.bolingcavalry.addsink;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KafkaObjSink {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并行度为1
env.setParallelism(1);
Properties properties = new Properties();
//kafka的broker地址
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
String topic = "test006";
FlinkKafkaProducer<Tuple2<String, Integer>> producer = new FlinkKafkaProducer<>(topic,
new ObjSerializationSchema(topic),
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
//创建一个List,里面有两个Tuple2元素
List<Tuple2<String, Integer>> list = new ArrayList<>();
list.add(new Tuple2("aaa", 1));
list.add(new Tuple2("bbb", 1));
list.add(new Tuple2("ccc", 1));
list.add(new Tuple2("ddd", 1));
list.add(new Tuple2("eee", 1));
list.add(new Tuple2("fff", 1));
list.add(new Tuple2("aaa", 1));
//统计每个单词的数量
env.fromCollection(list)
.keyBy(0)
.sum(1)
.addSink(producer)
.setParallelism(4);
env.execute("sink demo : kafka obj");
}
}
- 像前一个任务那样编译构建,把jar提交到flink,并指定执行类是com.bolingcavalry.addsink.KafkaObjSink;
- 消费kafka消息的控制台输出如下:
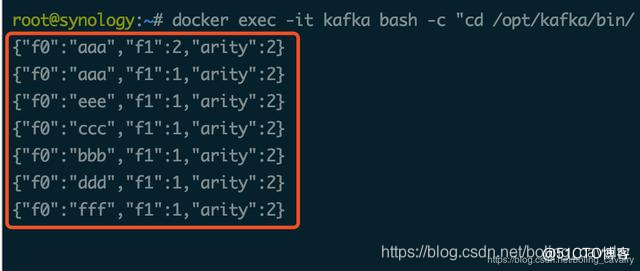
- 在web页面可见执行情况如下:

- 至此,flink将计算结果作为kafka消息发送出去的实战就完成了,希望能给您提供参考,接下来的章节,我们会继续体验官方提供的sink能力;
欢迎关注51CTO博客:程序员欣宸
- 赞
- 收藏
- 评论
- 分享
- 举报
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK