

How I Built a Faster and More Reliable APOD API
source link: https://www.freecodecamp.org/news/building-a-faster-and-more-reliable-apod-api/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

How I Built a Faster and More Reliable APOD API
Astronomy Picture of the Day (APOD) is like the universe’s Instagram account. It’s a website where a new awe-inspiring image of the universe has been posted every day since 1995.
As I was building a project using APOD’s official API, I found that requests would periodically time out, or take a surprisingly long time to return.
Curious and a bit confused (the data being returned was simple, shouldn’t require much computation, and should be easy to cache), I decided to poke around the API’s repo and see if I could find the cause, and perhaps even fix it.
Website as a Database
I was fascinated to find that there was no database. The API was parsing data out of the APOD website’s HTML using BeautifulSoup, live per request.
Then I remembered, this website was created in 1995. MySQL would have only been released mere weeks before the first APOD photo on June 16th.
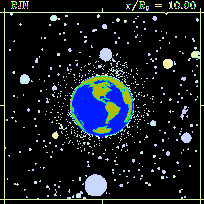 ap950616, the first APOD
ap950616, the first APODThis wasn't great for performance though, as each day’s data that the API needed to return needed an additional network request to be fetched.
It also looked like requests for date ranges were made serially rather than in parallel, so asking for even a month of data took a long time to come back. And it took over half a minute for a year's data when it didn’t just time out or send back a server error instead.
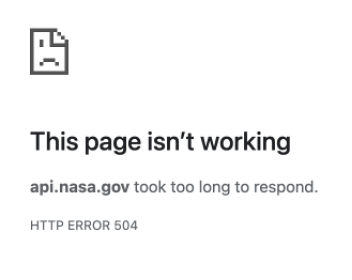 womp womp
womp wompThe official API also didn’t seem to do any caching – a request that took 30 seconds to load the first time would take another 30s to load the second time.
I believed that we could do better.
A faster and more reliable APOD API
Since I’m using APOD API to power a portfolio project (yes I’m job hunting 😛), I really need it to be reliable and load quickly. I decided to implement my own API.
You can find all the code in this GitHub repo if you want to look through it in detail as you read.
Here are the approaches I took:
1. Avoid on-demand scraping
One of the main reasons why NASA’s API response is slow is because data scraping and parsing happens live, adding a significant overhead to each request. We can separate the data extraction step from the handling of API requests.
I ended up writing a script to dump the website’s data into a single 12MB JSON file. Pretty chunky for a JSON file, but given that a free tier Vercel function can have an unzipped size of 250MB and has 1024MB of memory, it’s still small enough to be directly loaded without needing to bother with a database.
The script comprises of two parts:
getDataByDate(date: DateTime)is a function that, when given a particular date, will fetch the corresponding APOD webpage for that day, parse pieces of data out of the HTML using cheerio (JavaScript's equivalent to BeautifulSoup), and return structured data in the form of a JavaScript object.extractData.ts, which callsgetDataByDatewith days from a date range (initially "every day between today and June 16th, 1995") using the async library'seachLimitmethod to make multiple requests in parallel. It stores each day's result as a separate JSON file on the filesystem, and finally combines all the daily JSON data into one single data.json.
You might wonder – why not fetch all the data first and save just one file at the end? When making 9000+ network requests, some of them are bound to fail, and you really don't want to have to start back from zero. Saving each day's data as it runs allows us to continue from where the failure happened.
Here's a comparison of timings before and after on-demand scraping:
Arguments
My APOD-API
NASA's APOD API
Average TTFB*
(n=20)
Standard
Deviation
Average TTFB
(n=20)
Standard
Deviation
no argument
110 ms
105 ms
start_date=2021-01-01
&end_date=2022-01-01
151 ms
35,358 ms
2,891 ms
count=100
9,701 ms
1,198 ms
*https://en.wikipedia.org/wiki/Time_to_first_byte
2. Fallback to on-demand data extraction
The extracted JSON will only have data up to the time when extraction was run. This means that sometimes there’ll be a new APOD that will be missing from our JSON. For those situations, it’d still be nice to fallback to live requests as a supplementary source of data.
In the code of our API request handler, we check our extracted data.json to find which date is the last date that we have data for, and if the number of days between the last date and today is greater than 1, we then fetch data for any missing dates in parallel (once again using getDataByDate, the same function we used for extracting data for the JSON file).
3. Aggressively cache requests
The bulk of time on APOD’s official API was spent waiting for the server to send the first byte. Since historical data doesn’t change, and new entries are added once a day, the actual application server doesn't need to be hit most of the time.
We can use headers to tell the Content Delivery Network (CDN) to aggressively cache the response of our cloud function. I’m hosting on Vercel, but this should work with Netlify and Cloudflare as well.
The code for the specific headers we want to send from the function handler is:
response
.status(200)
.setHeader(
'Cache-Control',
'max-age=0, ' +
`s-maxage=${cacheDurationSeconds}, `+
`stale-while-revalidate=${cacheDurationSeconds}`
)Breaking that down,
max-agetells browsers how long to cache a request. If a request for a resource is within the max-age, the cached response would be used instead. We setmax-ageto0, following Vercel's advice, to prevent browsers from caching API response locally. That way clients will still get new data as soon as it updates.s-maxagetells servers how long to cache a request. So when a request for a resource is within the s-maxage, the server (in our case, Vercel's CDN) will send the cached response. This is really powerful since this cache is shared across all users and devices.- We set
s-maxageto a variable amount of time, because for requests that ask for dates using a relative time ("today's data", or "the last 10 day's data"), we only want to ask the CDN to cache that for roughly an hour since that might update when the next APOD comes out. For requests that ask for a specific date's data (for example between "2001-01-01" and "2002-01-01"), we can ask the CDN to cache that for a lot longer, since that isn't expected to change. - We finally set a
stale-while-revalidateheader. That way, when the specified cache time expires, instead of having the next user wait until fresh data comes back, we tell the CDN to serve the cached data to the current user – but at the same time, hit our API endpoint for fresh data and cache that for the next request.
Since our API was loading all the data into memory already, the performance difference between cached vs. uncached requests shouldn’t be too noticeable, but faster is always better.
The main goal with caching is to avoid running the cloud function, since Vercel’s free tier has a quota of 100 GB-hours (not sure what that means, but whatever it is, I don’t want to hit it).
Comparison of timings before and after caching requests:
Arguments
My APOD-API
NASA's APOD API
Average TTFB
(n=20)
Standard
Deviation
Average TTFB
(n=20)
Standard
Deviation
no argument
105 ms
start_date=2021-01-01
&end_date=2022-01-01
35,358 ms
2,891 ms
count=100
9,701 ms
1,198 ms
4. (Bonus) Automated daily updates
We want to keep our data file in sync with NASA’s APOD website as much as possible, since reading data from our JSON file is much faster than falling back to fetching data over network.
Automating this doesn't exactly improve performance – I could set an alarm for myself to run the extraction script every night at midnight, commit any changes, and push to trigger a new deploy.
Thankfully, I won't have to, since apparently Github Actions aren't limited to running on Pull Requests, you can schedule them too.
name: Update Data Every 3 Hours
on:
schedule:
# At minute 15 past every 3rd hour.
- cron: '15 */3 * * *'
workflow_dispatch:
jobs:
update-data:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: actions/setup-node@v2
with:
node-version: '16'
- run: npm install
- run: npm run update-data
- name: Commit changes
run: |
if [ -n "$(git status --porcelain)" ]; then
git config --global user.name 'your_username'
git config --global user.email '[email protected]'
git add .
git commit -m "Automated data update"
git push
else
echo "no changes";
fi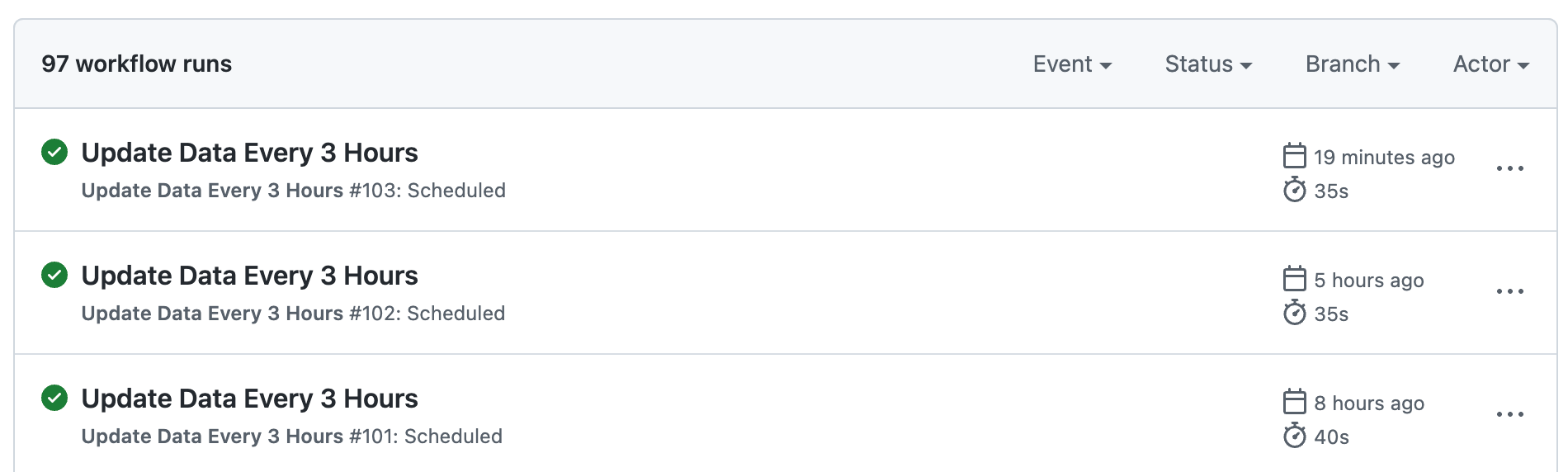
Conclusion
In summary, where possible and sensible:
- Extract data before requests are received and try to keep it up-to-date
- Make fallback requests in parallel
- Cache responses on the CDN
The code for all this is a bit too lengthy to fit into an article, but I believe these principles should be more broadly applicable for public-facing APIs (plenty more just on api.nasa.gov!). Feel free to peruse the repo to see how it all fits together.
Thank you for reading! I’d love to hear any feedback you may have. You can find me on Twitter @ellanan_ or on LinkedIn.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK