

一年实现降本60%,货拉拉全链路监控演进史
source link: https://dbaplus.cn/news-134-4362-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一年实现降本60%,货拉拉全链路监控演进史
本文根据曹伟老师在〖deeplus直播:多云场景下核心基础设施的稳定性、高可用建设〗线上分享演讲内容整理而成。(文末有回放的方式,不要错过)
今天的分享主要包含以下几个方面的内容:

一、监控演进史
1、行业
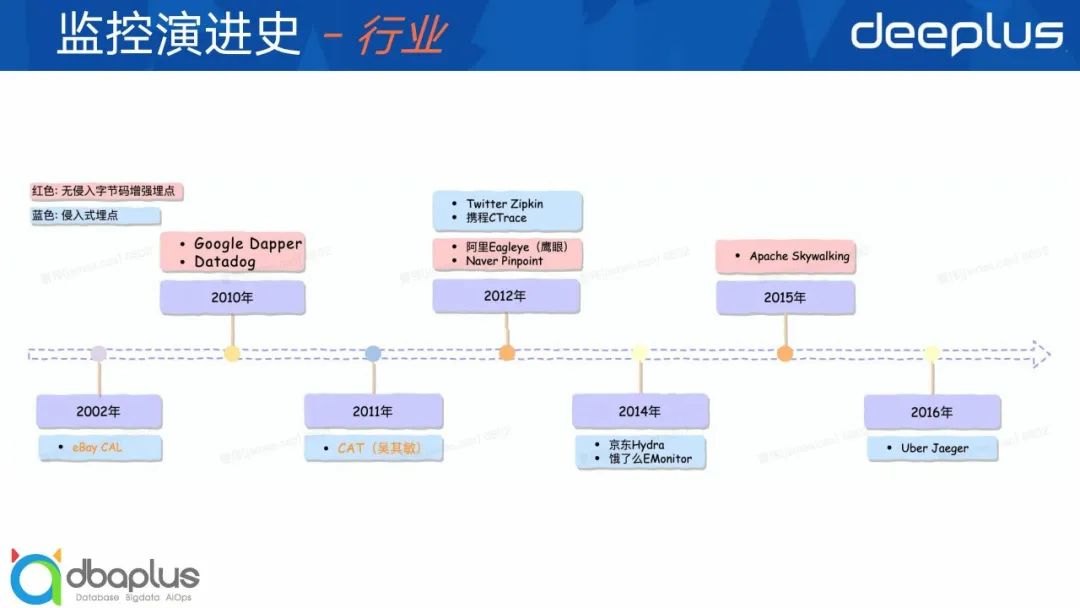
首先我们看一下整个监控行业的演进历史。
较早的是02年eBay的CAL这么一个全链路监控产品,在eBay内部也大面积的运用,是他的前资深架构师吴其敏主导研发的。
然后是10年谷歌的Dapper,这是内部做的一个监控产品并没有开源,不过发表了一篇Dapper论文,是后面很多监控产品的鼻祖,大部分都是基于Dapper论文的实现和演进;同年出现一个商用产品产品Datadog,功能比较全面,是行业一流的标杆产品。
11年吴其敏从eBay离职来到美团,开发了CAT,相当于CAL的Java版实现,同时做了很多的优化、迭代,将CAT在就开源领域发扬光大,在整个开源监控领域受到的欢迎程度比较高的,整体的覆盖率也相当的高。
12年Twitter的开发出了Zipkin,相当于Dapper的开源实现。同年阿里也在搞他的Eagleye(鹰眼)监控,韩国的一个Pinpoint也出现了,值得说的是他是基于字码增强技术来实现监控数据埋点,有个亮点是他的埋点非常的细致,细到底层方法维度,同时这也是个缺点,因为埋点多多少少会有点性能损耗,其次他会导致单个Trace数据的膨胀。
14年,饿了么开始搞EMonitor,他对用户的一个排障思路的引导,以及用户体验都做的非常好,是我用过所有监控里面最好的一个产品。货拉拉的全链路监控体系的很多思想都是借鉴于他的,比如说我们的“所见即所得”的思想是如何运用到监控可视化建设中的。
15年,华为的吴晟开发了skywalking并且将他开源,近些年发展还挺好的,加入了Apache基金会,在当前的监控领域还是比较受欢迎,特别是他在微服务体系这块支持的比较好,所以受到很多中小型公司的追捧,甚至一些大公司也在用。像我们货拉拉的全链路Trace服务初期也是基于他结合货拉拉场景进行深度定制开发的,期间也经过几次大的架构升级,这个在后面会详细的说。
最近的是16年Uber的Jaeger是基于Go语言来实现,滴滴内部也在使用,目前也开源了。
2、货拉拉
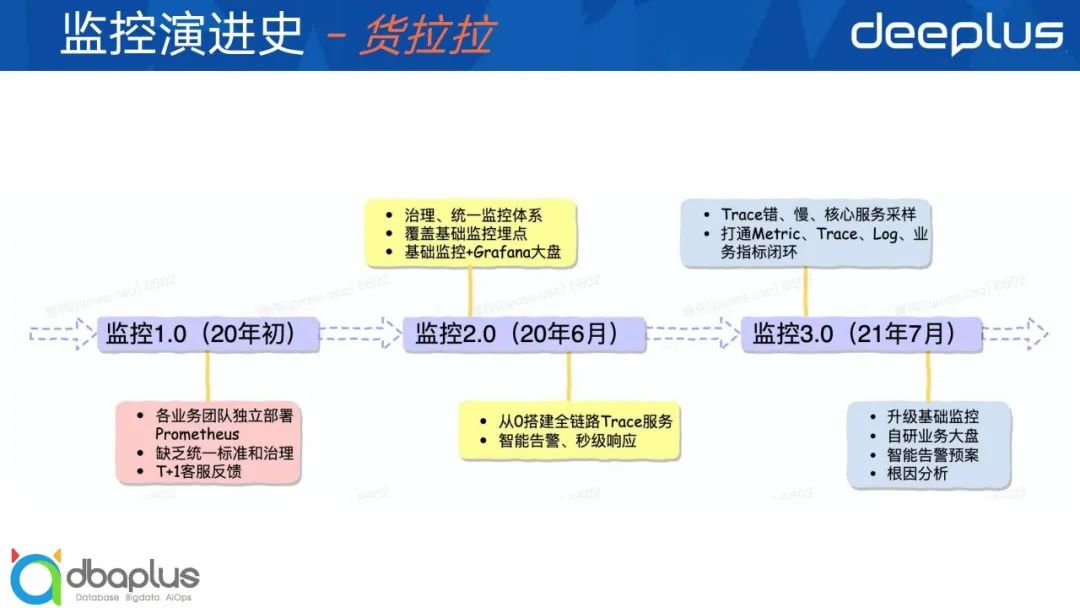
接下来我们看一下货拉拉的监控演进史,我将它划分成3个阶段,分别是监控1.0、2.0和3.0时期。
1)监控1.0时期
各个业务团队独立维护一套Prometheus监控体系,也没有全链路Trace监控,缺乏统一标准,更别说治理能力了,夸张一点说很多时候是客服接到投诉后把问题反馈给业务,业务才知道系统出现问题,然后再去排障,所以效率极其的低。
2)监控2.0时期
我们开始制定标准并逐步统一监控,进行监控治理,推进业务基础监控全覆盖,得益于字节码增强技术帮助我们实现业务“零代码”改造快速接入基础监控,实现监控“弯道超车”,Java核心服务监控100%覆盖。同时我们也自研一些基础监控页面,结合着Grafana大盘来满足日常的监控场景。我们在中期也开始从0搭建全链路Trace服务,自研智能告警体系。
3)监控3.0时期
这个阶段我们主要针对各个监控领域专项做深度迭代和打磨,比如Trace,我们实现错、慢、核心服务完整全采样,在不影响业务排障体感的前提下,将整体存储成本降低60%。另一方面,由于历史原因Metric、Trace和Log都是各个团队独立维护的,缺乏较强的关联性,整体监控体系的价值得不到最大化,所以我们在这个阶段将他们和业务之间的指标做一个闭环的打通,来提高业务整体的排障流畅度。同时我们重新自研基础监控和业务大盘页面,给业务提供更智能便捷的大盘自助配置能力。最后我们在告警预案、根因分析等方面也有一定的研究和实践。
二、货拉拉监控体系整体架构
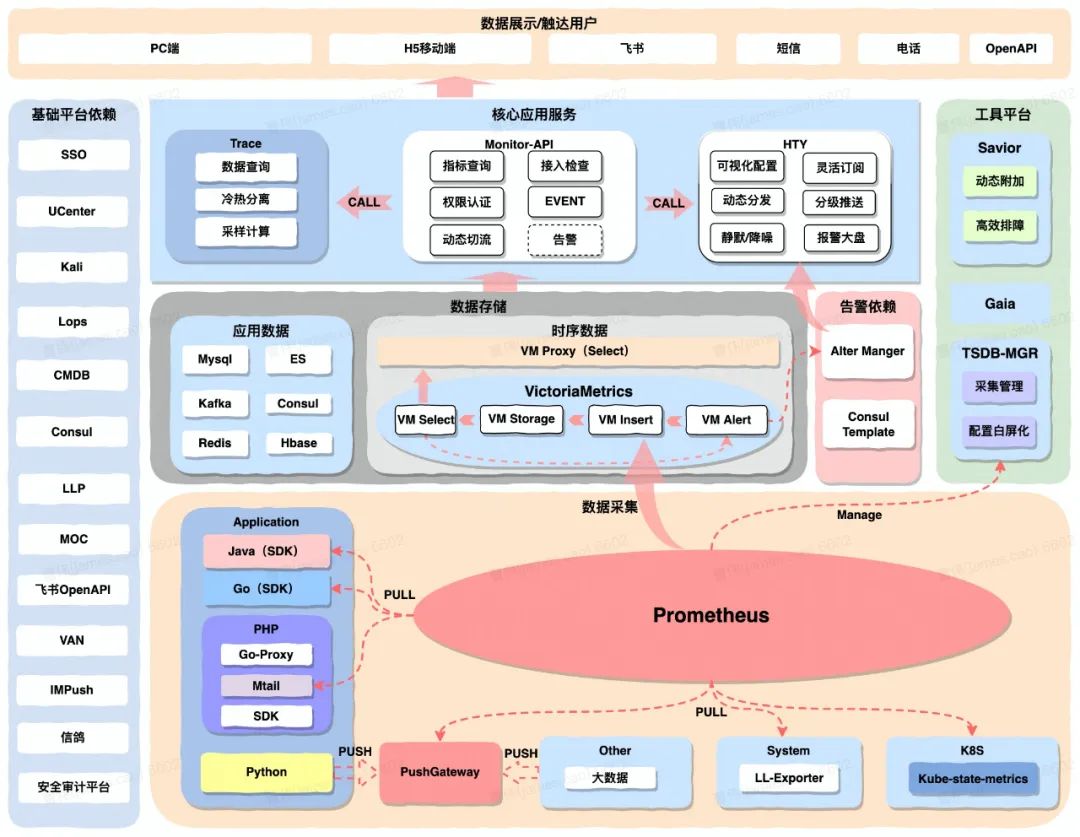
上图是我们货拉拉监控体系全局架构图,我们可以从下往上看。
首先是Prometheus集群,它主要进行数据的采集,可以从多个维度采集数据,比如说我们应用层,有Java、Go、PHP和Python等类型服务暴露指标数据,这里也可以看到货拉拉的语言栈比较丰富。除此之外,还可以通过Push-Gateway来获取像大数据场景下的一些数据,还有一些系统级别的监控数据,比如CPU、网络指标,通过Export暴露出来,K8S指标等。
再看中间层,左边的应用数据包含一些常规存储,比如ES和HBase,主要用来存储Trace数据。中间是时序数据库Victoria集群,Prometheus将收集到吐给这个Victoria集群进行时序数据的存储、计算以及供上层展示,同时他也承担一部分的告警的计算能力。
再往上是核心应用层,比如Trace数据的收集和展示层、指标数据展示层,还有智能告警服务等。 简单来说就是Prometheus + Victoria实现Metric指标服务,然后用Skywalking搭建Trace服务。当然我们Skywalking的基础上做了很多的升级改造,后面会说。 在这些数据基础上,我们自研了智能告警、预案系统,这就是货拉拉整体的全链路监控体系架构。三、监控埋点
1、JAVA SDK图谱
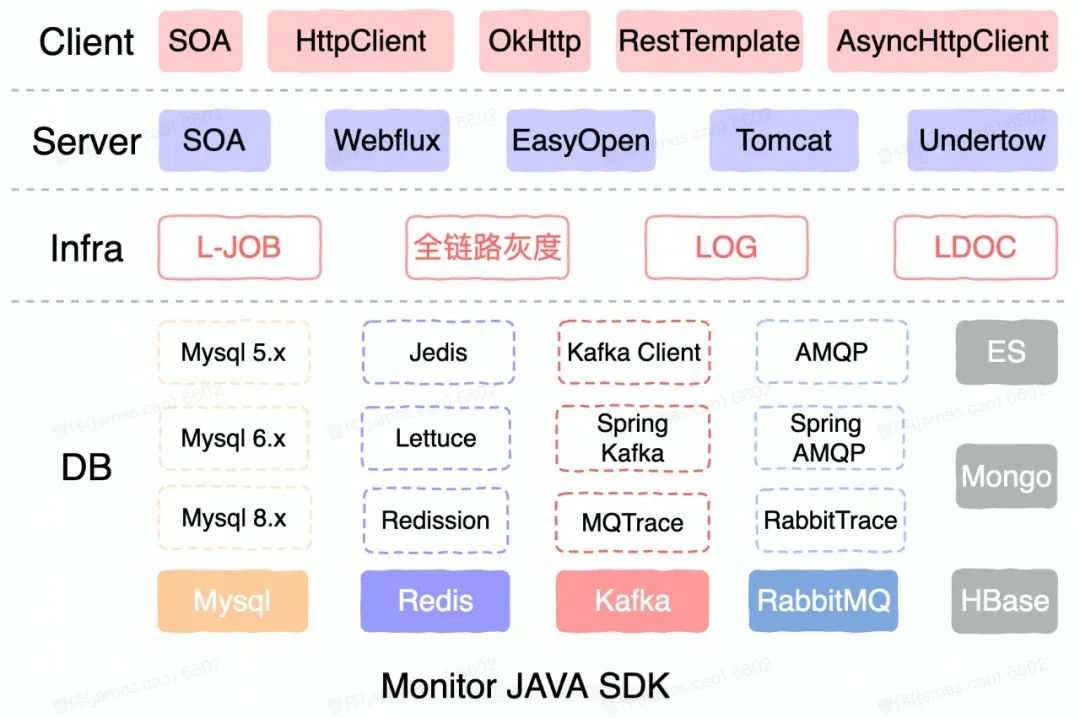
上图是我们的JAVA 埋点SDK图谱,整体看各基础组件都覆盖到了非常完善。
-
客户端:支持自研的SOA Client,支持市面上主流的同步、异步Http Client;
-
服务端:同样支持自研的SOA,主流的Tomcat、Undertow以及Webflux异步埋点都支持得非常好;
-
基础服务层面:支持Job、全链路灰度和Log等;
-
数据DB层:支持当前主流的组件、客户端和版本,整体的覆盖率能达到100%,完全能满足当前货拉拉复杂的场景。
我们所有的埋点完全基于字节码增强技术实现代码“零侵入”。实现业务“零代码”改造“一键快速接入”,这是我们实现“弯道超车”的基础。
2、什么是字节码增强技术?
1)字节码增强技术的应用 - 热修复Log4j2漏洞

我们一直在讲字节码增强技术,那么到底什么是字节码增强技术呢?因为时间原因这里不会跟大家详细升入原理,但希望通过下面这节让大家对这个技术能有个全面的认识。
这里举了一个大家非常熟悉的Log4j2漏洞的例子,正常的业务服务能通升级迭代来修复这个BUG,但是有一些基础服务,比如说一些开源的Kafka和ES并不能通过简单的升级来解决。首先升级版本可能会存在数据不兼容或者服务端和客户端版本不兼容问题,甚至仅仅是重启也可能对依赖的业务方服务产生不小的抖动。所以要求我们提出不重启服务的热修复方案,这里就可以基于字节码增强技术来实现服务的热更新,实际上我们提供出去的Agent Jar帮助整个货拉拉数千个基础服务节点实现热更新,来完美修复这个Bug。
这里的修复其实很简单,只涉及到一行代码的改动,在lookup这个方法进入之初就return null,避免执行下面的可能产生BUG的代码,那这个Bug自然就解决了。
那具体改如何做呢?这里我们需要明白下面2个概念:
-
谁去修改字节码,就是字节码修改框架做的事。针对字节码修复框架,后面列了3个主流框架会逐一介绍。
-
修改后的字节码数据是怎么生效的,主要由Java Agent技术来实现。
2)Java Agent技术
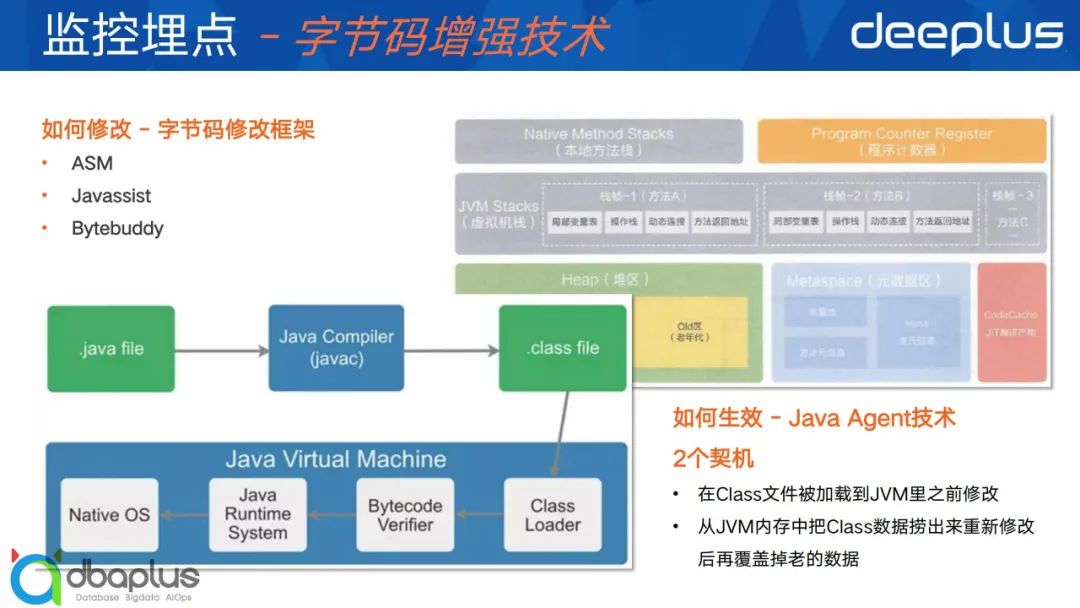
这里我们先看一下Java Agent是个什么东西?我们知道Class数据最终是被加载到JVM内存里,我们如果要在运行是修改Class数据其实是有2个契机:
-
在Class文件被加载到JVM之前,对他做修改,将修改后的数据加载到JVM内存中。
-
针对已经加载到JVM中的数据,在JAVA 7之后的版本,是支持把JVM内存里面的Class数据捞出来修改增强然后再放回去,覆盖之前老的数据,这样能达到一个替换、增强的效果。
所以简单说,Java Agent技术就是一套支持运行时动态修改JVM内存中的Class数据的技术或者手段。
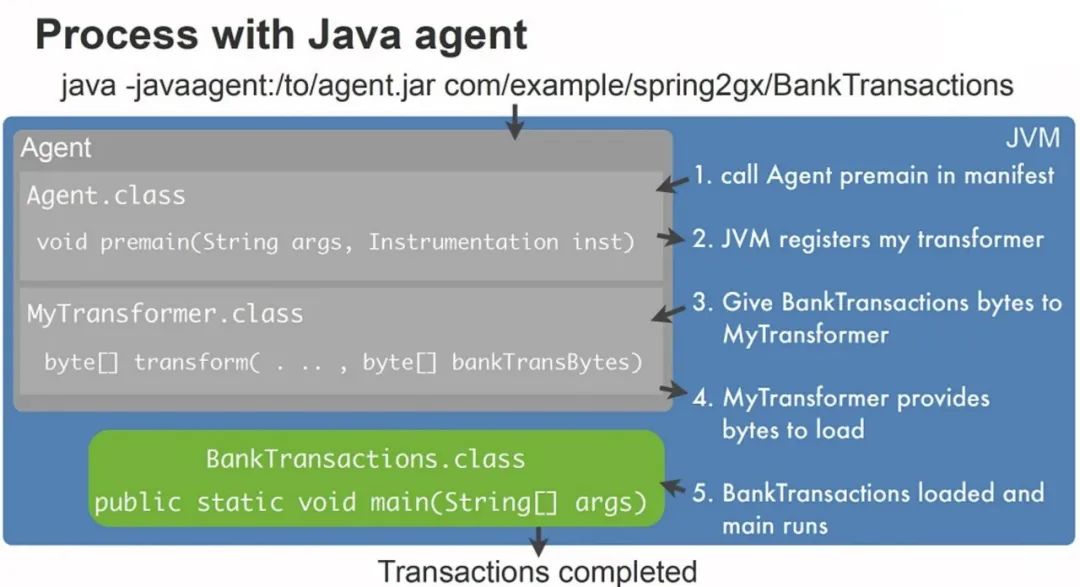
上图是Java Agen核心原理图,我们主要关注 2 点:
-
Agent.class
JVM启动后会先进入premain方法,方法JVM会注册一个Transformer。
-
Transformer.class
前文提到的2个修改字节码源数据的契机都会触发Tranceformer的tranceform方法的执行,入参bankTransBytes就是Class源数据,tranceform方法体里会通过字节码框架对源数据进行一系列修改,然后将修改后的字节码数据以返回值的形式交还给JVM。再次new新的Class实例时就会用修改后的Class字节码数据作为模板进行实例创建,从而达到增强的效果。
以下是Java Agent运用的例子,通过简单的编码就可以实现Base.class里process方法的增强。
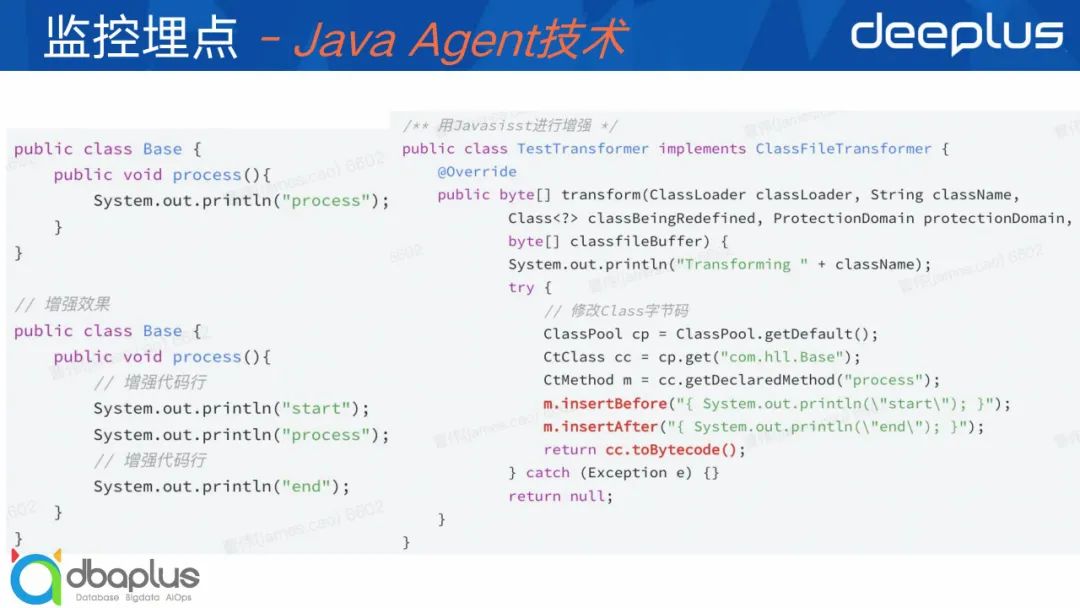
3)字节码增强框架
这里我们列举3个主流的字节码增强框架,分别是:
-
Javassist
-
ByteBuddy
接下来将结合刚才Base.class的例子逐个重点介绍下3个框架的不同编码规范。
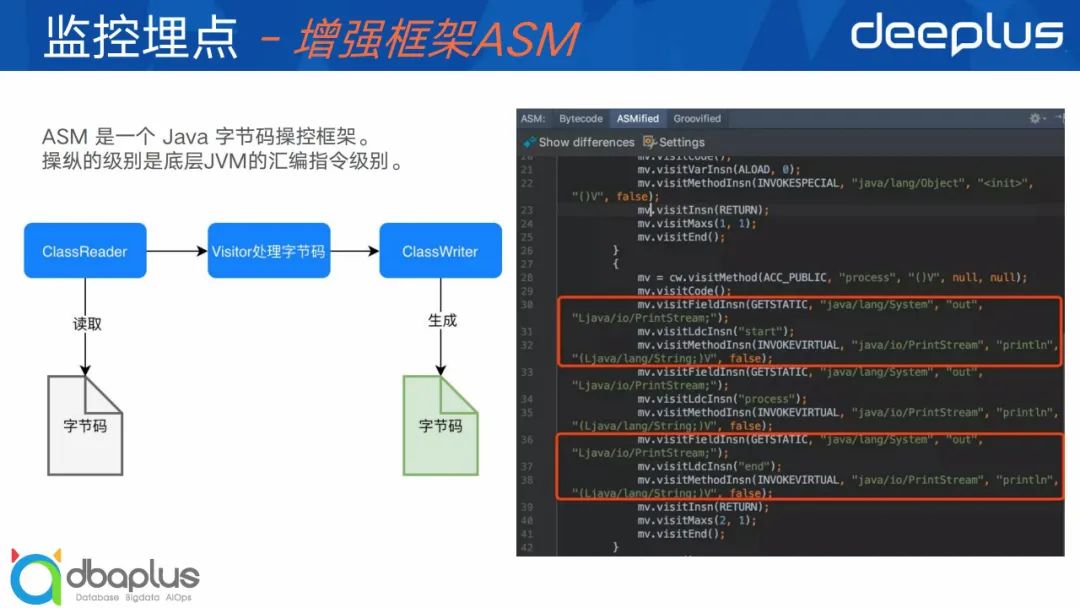
首先是ASM,它是一个比较底层的框架,是字节码增强框架的鼻祖。从上图代码中我们可以看到你需要了解JVM的指令集、Class文件规范,才能很好的进行增强编码。整体学习成本非常高,操作性也不强,除此之外我们没法针对某行增强代码进行断点Debug,开发效率大打折扣。

第二个是Javassist,它一个日本人基于ASM进行二次开发的更高级的框架,它对用户屏蔽JVM指令集和Class文件等这些晦涩难记的概念,我们可以遵循Java语法进行开发,但是从图中我们也不难看到,所有的增强逻辑都是采用硬编码(转义字符串)的形式开发,同时也一样不支持断点Debug,整体开发效率还是受到很大的限制。

最后是ByteBuddy框架,它比Javassist更高级,也更符文Java开发习惯,首先它采用切面编程思想,整体结构更清晰,这里我们只关注切面代码,会发现我们可以像日常写Java代码一样写我们的增强逻辑,并且可以随意对增强部分的代码进行断点调试,易上手、调试,整体编码效率有质的飞跃。
4)字节码增强框架对比
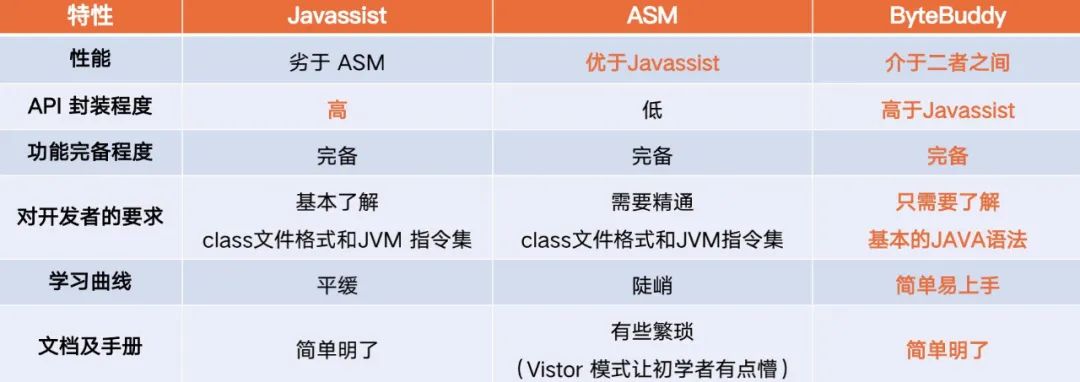
显而易见,ByteBuddy是最优的选择,它不需要太多的学习成本,又支持随意的断点调试,是个非常友好的字节码增强框架。
5)基于字节码增强埋点的优势
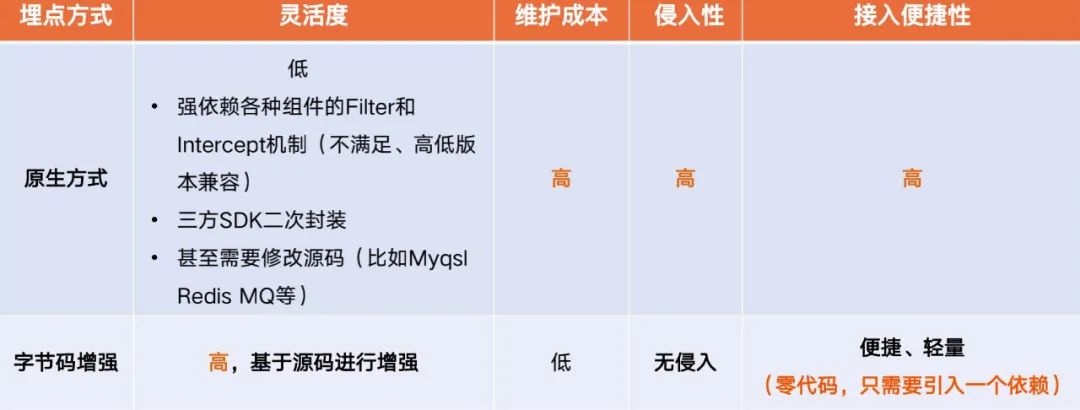
对比发现,字节码增强形式埋点的优点有很多,比如代码无侵入、不需要进行二次封装、更不需要维护源码、接入轻便快捷,能做到业务无感升级。
四、全链路Trace建设
1、架构演进
1)架构1.0

1.0架构很简单,其实就是原生的skywalking服务(ci-trace-svr)用ES作为Trace存储。架构简单但也存在弊端,它不满足我们货拉拉全量服务的接入,也无法满足我们业务的快速发展和体量的上升。
为什么呢?ES在我理解他不适合存储Trace这种结构类型的数据,或者说不适合将完整的Trace数据一股脑的都存入ES,一段完整的Trace数据可以划分为两段,一段是基础数据,包含TraceID、AppID、IP、Endpoint和起止时间等基本信息,可用于复杂查询,另一段是详细数据(源数据,包含所有的Span数据),它的大小是基础数据的好几倍甚至数十倍,如果将不承担复杂查询的大体量的源数据也存到ES中会导致ES的内存被大量的源数据占用,在整体内存大小有限的情况下,这会大大降低查询时的缓存命中率,查询被迫从磁盘读取数据,这样会极大的影响整个Trace的查询效率,同时也会影响Trace的写入性能。
2)架构2.0
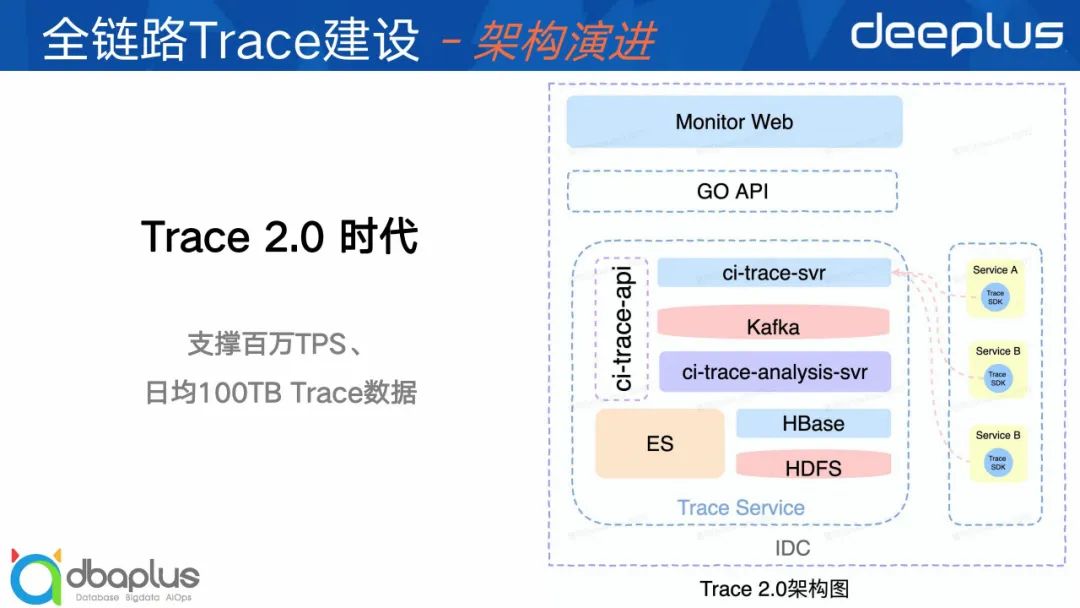
针对1.0架构存在的问题,我们如何解决呢?
首先,我们采样ES作为HBase二级索引的解决方案,将Trace数据拆成基础数据和源数据二部分,基础数据体量很小还放到ES里面用做复杂查询,源数据放在HBase。那么整个Trace查询流程就是,首先通过复杂查询从ES里面查到某个Trace基本信息,再用TraceID到HBase里面查源数据。
其次,我们将原来的Trace服务拆成2个服务,分别是ci-trace-svr和ci-trace-analysis-svr。ci-trace-svr用来接受客户端上报的Trace数据,并将数据吐给Kafka集群,ci-trace-analysis-svr异步消费Kafka进行计算、采样和存储。
这套架构再结合一些异步批处理技术、ES调优,完美得解决了ES瓶颈问题,并且支持通过不断的水平扩容来提高整体服务的一个吞吐量,目前整体架构能支撑了百万TPS、日均100T的Trace数据。
3)架构3.0
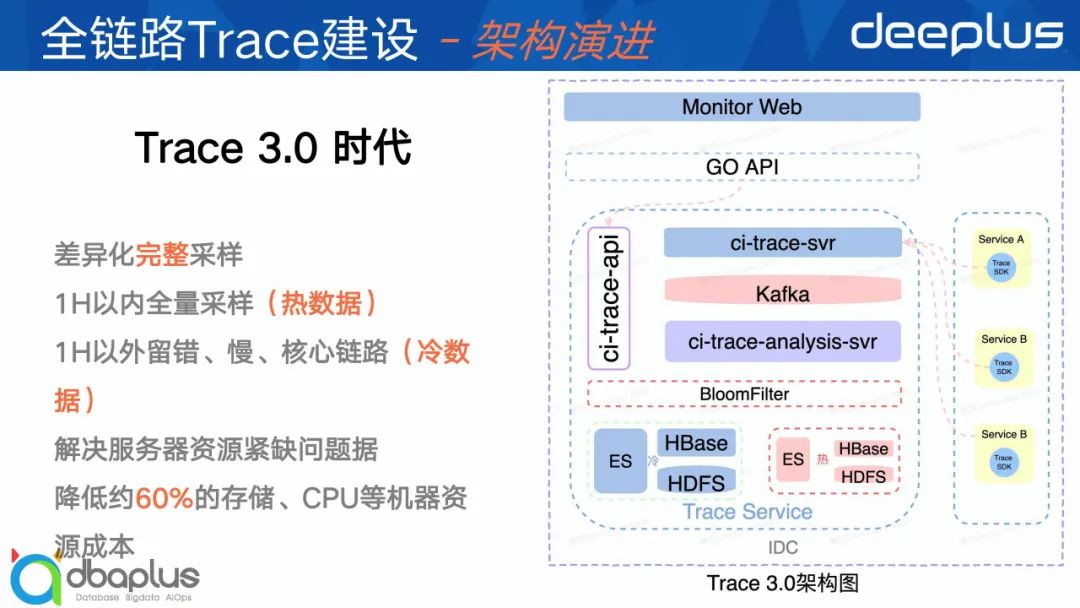
2.0架构虽然能满足高吞吐量,但是也存在存储成本浪费的问题。其实从实践经验看,我们会发现80~90%的Trace数据都是无价值的、无意义的数据,或者说是用户不关心的。那么用户关心哪些数据呢?关心链路中错、慢的请求以及部分核心服务的请求。那么我们是不是可以通过某些方式,把这些有价值的数据给过滤采样出来从而降低整体存储成本?
在这个背景下,我们进行3.0的改造,实现了差异化的完成链路采样,保证1H以内的数据全量保存,我定义它为热数据,而一小时以外的数据,只保留错、慢、核心服务请求Trace,定义为冷数据,这样就将整体的存储成本降低了60%。
从3.0的架构图我们也能发现,我们将ES和HBase集群拆分成冷热两个集群。具体我们是如何做差异化链路完整采样的,将在后面的章节中详细介绍。
2、数据完整采样与冷热分离
1)冷热分离的价值
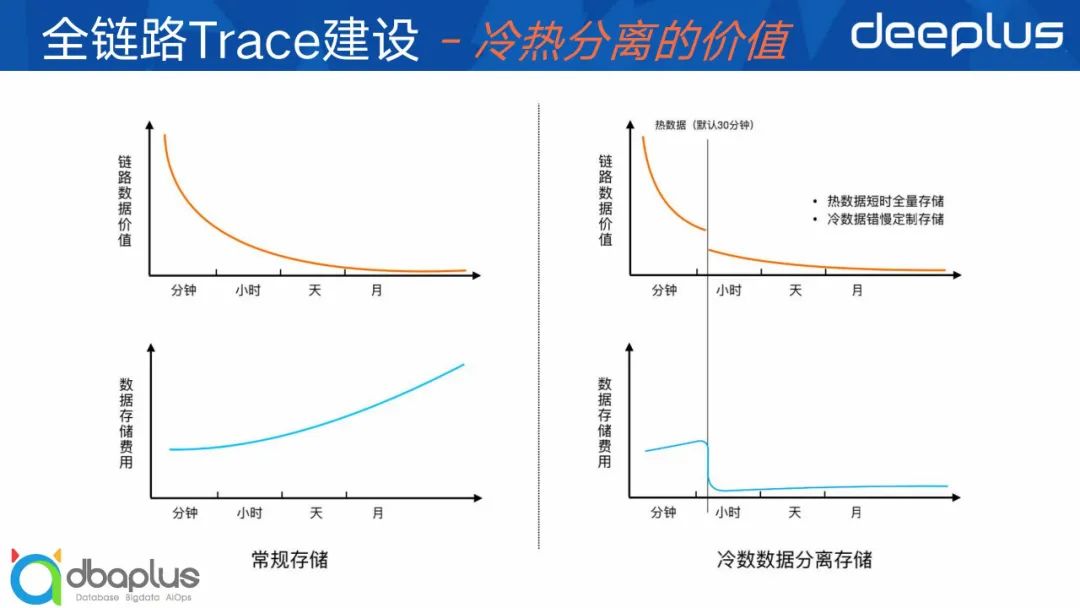
在介绍采样之前,我们先思考下冷热分离的价值?从左边的2个曲线图,我们发现Trace数据的价值是随着时间的推移急速降低的。其实也很好理解,从我们实际的生产情况看,但凡你发生一个线上的调用异常,就需要我们在30分钟以内发现解决,甚至几分钟之内就处理掉。如果等几天过会你还不看的话,它其实就是无关紧要的异常,也就说明没什么价值,但是存储量随着时间推移会越来越大,成本自然越来越贵。所以如果我们把过去一小时以外的数据进行采样、清洗最终只保留上面定义的有价值的数据,存储成本自然就能极大地降低。
2)常规采样

Trace的采样方式有很多种,这里我们先介绍下Skywalking原生的常规采样方式,其实是一种常规、无差别的采样手段。那么他是怎么做的呢?我们先简单了解下TraceID的结构,他主要由3段组成,最前面是PROCESS_ID,简单理解为UUID,中间是个线程ID,第三段是我们比较关心的毫秒级时间戳加上一个自增序列,原生Skywalking取这个时间戳的毫秒级的千位数据段来制定采样规则,比如说Trace满足毫秒数据段小于100就保留,从而来达到10%的采样率效果。这种常规采样简单易实现但仅凭TraceID无法筛选出有价值的数据。
3)错、慢、核心服务采样

所以我们提出另外一种方案,就是更深入一点,从Trace详情数据入手。我们可以看到这个Trace的结构是由多个Span组成,Trace维度包含APPID、Latency信息Span维度又包含耗时、类型等更细粒度的信息,根据不同的Span类型设置不同的阈值,比如远程调用SOA耗时大于500ms可以认为是慢请求,而如果是Redis请求,阈值就需要设置小一些,比如20ms,通过这种方式可以将慢请求规则更精细化,同样可以通过判断APPID是否为核心服务来过滤保留核心服务的Trace数据。
4)链路完整采样
① 什么是链路完整采样?
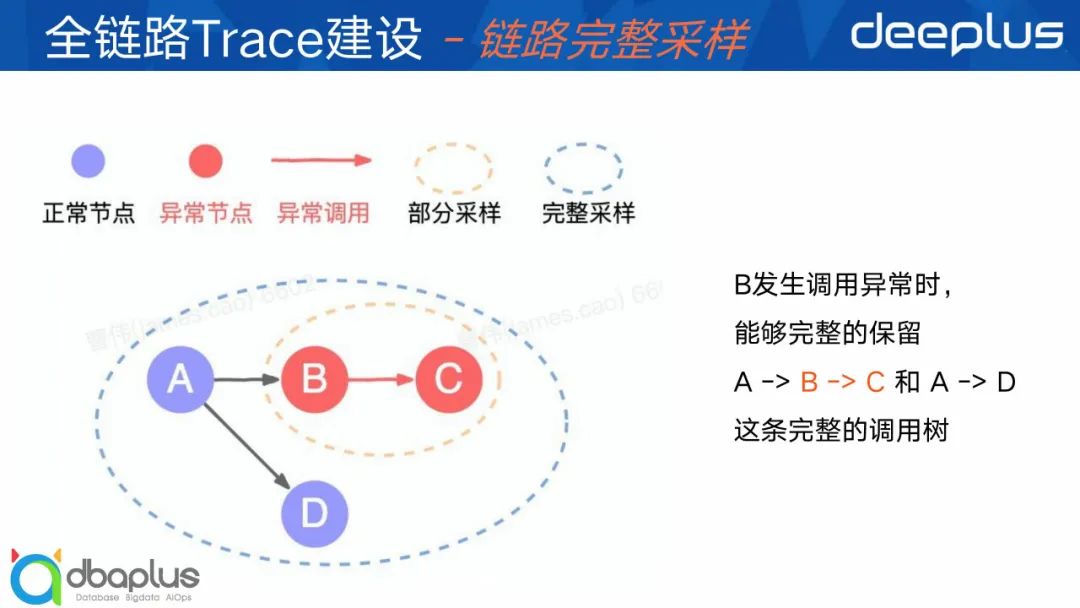
上面解决了差异化、精细化采样,但还有个棘手的问题,就是在采样是如何保证链路的完整性?解答这个问题前,让我们先了解下什么是链路完整性?
这里举个例子,如图现在有一条远程调用,经过ABC和分支AD。这里有个前提就是ABCD它是4个不同的服务,独立异步上报Trace数据没有严格的时间顺序。在B调用C出现异常时,我们能轻松识别到并将B和C的Trace数据段采样到,只保留B和C的这种情况,称为部分采样。但是在实际的一个排障过程中,我们还需要A和D这条链路数据作为辅助信息来支持排障,所以最好的方式是把ABCD都采样到,作为一个完整的异常链路保存起来,这称为完整采样。
我们的目标是完整采样,如何实现完整采样也是业界的一个难点,当前行业有一些解决方案,比如阿里鹰眼和字节的方案,接下来我们一起了解下。
② 阿里鹰眼方案
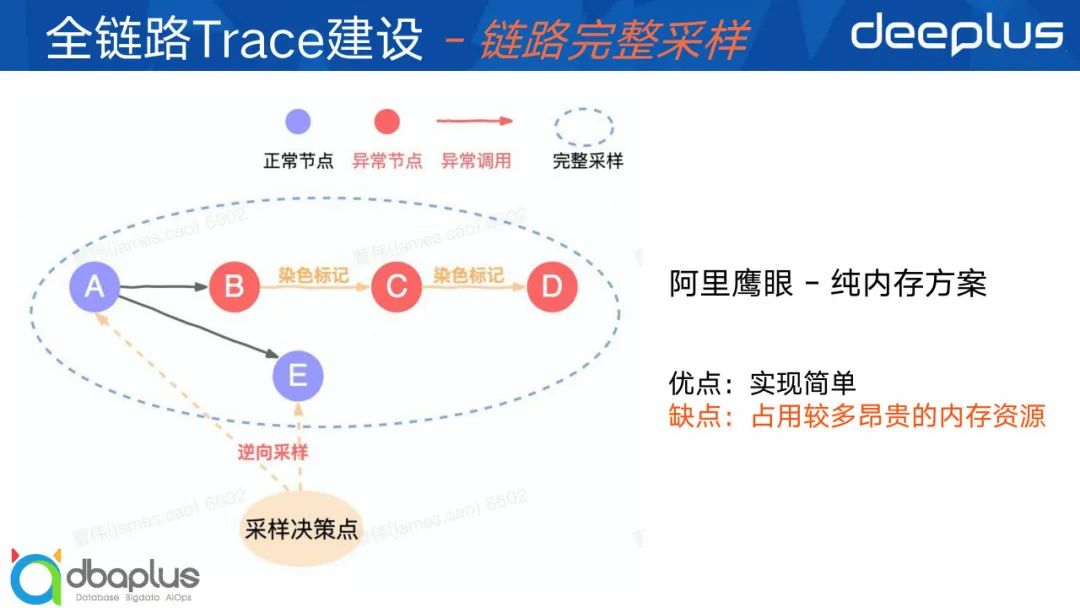
阿里鹰眼采用一直纯内存的解决方案,具体怎么做呢?
例如现在有个链路经过ABCD和分支AE,B调用C出现异常时,他会做一个染色标记,那么C到D自然也携带了染色标记,理论上BCD会被采样的保存起来,但是A和E是前置的节点也没有异常也没被染色,该怎么办呢?他引入一个采样决策点的角色,假设B出了异常,采样决策点感知到,最后在内存里查是否存在像A和E这种异常链路的前置节点,然后将它保存起来。
这里需要注意这种场景对查询的QPS要求非常的高,那如果不是存在内存而是类似HBase这种服务里的话是很难满足这种高QPS的需求。所以他选择将一小时或者半小时内的Trace数据放内存中,来满足采样决策点快速查询的要求。
但基于内存存储也存在弊端,因为内存资源是比较昂贵的。我们做个简单的计算,如果想保存1小时以内的Trace数据,单条Trace 2K大小,要支撑百万TPS,大约需要6T的内存,这个在我们货拉拉场景是没有很好的存储解决方案,而且成本太高了,所以我们是采样自研的一种巧妙的方案,后面会进行分析。
③ 字节方案
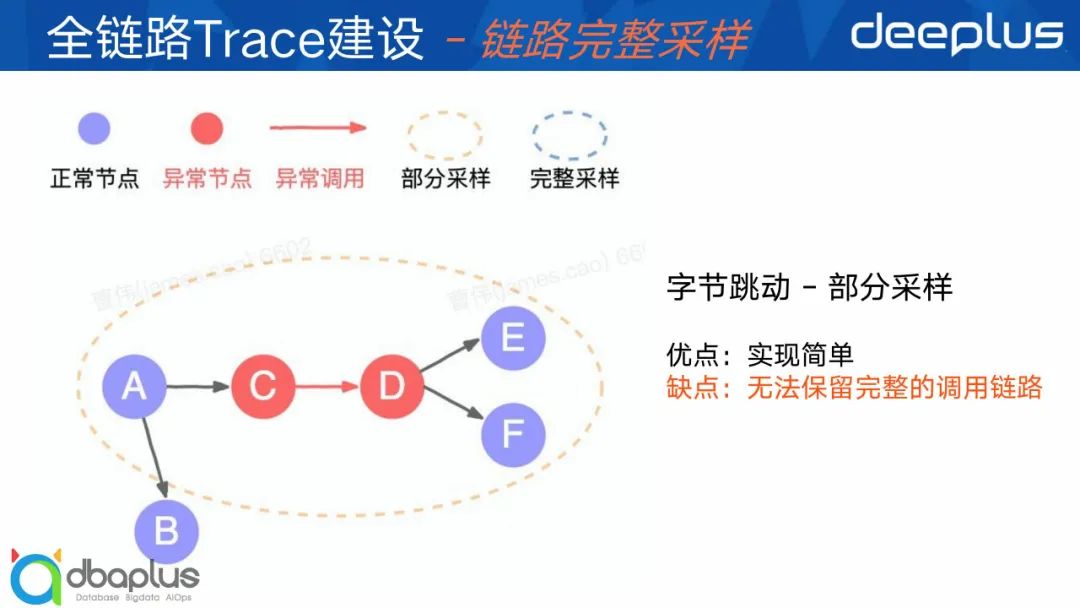
字节码的方案比较简单,但没做到完整采样,只保留了部分异常主链路,比如说现在一个链路是AB和ACDEF,他在CD出现异常的时候只能保存ACDEF这一段,B无法被保存下来,具体原理就不展开了。
④ 货拉拉方案
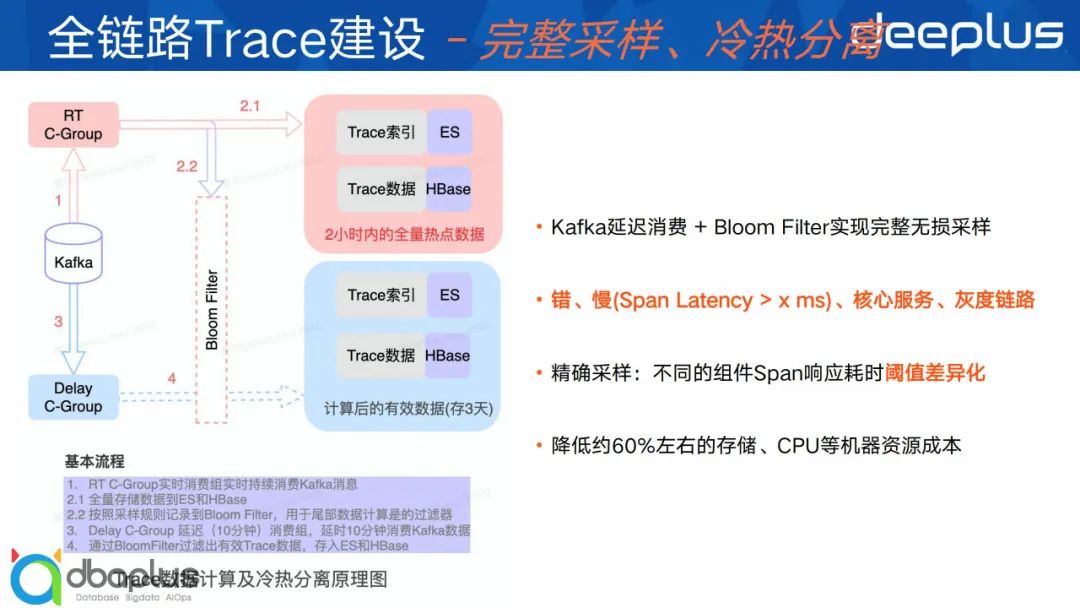
接下来看下我们是怎么解决的?简单说我们基于Kafka延迟消费+Bloom Filter来实现完整采样。
比如说我们Kafka有两个消费组,一个是实时消费,一个是延迟消费,实时消费每条Trace数据时会判断下是否满足我们的采用规则,如果满足就将TraceID放在Bloom Filter里,另外一方面延时消费组在半小时(可配置)开始消费,从第一条Trace数据开始消费,针对每条Trace数据判断TraceID是否在Bloom Filter中,如果命中了,就认为这条Trace应该被保留的,从而能做到整个Trace链路的完整采样保存。
除此之外,里面其实还有一些细节,比如说Bloom不可能无限大,所以我们对其按分钟进行划分出多个小的Bloom,又比如我们其实采用的是一个Redis的Bloom,但Redis Bloom如果想达到百万QPS预计需要10~20个2C4G的节点,但是我们实际只用了5个2C4G的节点就能满足百万的一个吞吐量。这里涉及到专利保护规定,就不展开说了,大家如果感兴趣,有机会可以私底下聊。整体上我们就是具有这套采样方案实现整体成本的降低了60%。
五、监控可视化建设
1、 监控大盘

接下来,这一章节主要带大家看看我们在监控可视化建设中如何运用“所见即所得”思想的。首先看下我们的基础监控大盘页面,左边主要有一些Exception、Http、SOA以及核心基础服务的一些指标数据。我们的一大亮点就是所有的曲线都可以通过点击展示出具体的Trace页面。针对QPS、RT标高曲线可以点击查看Trace详情,进一步排查异常点。
2、Trace页面
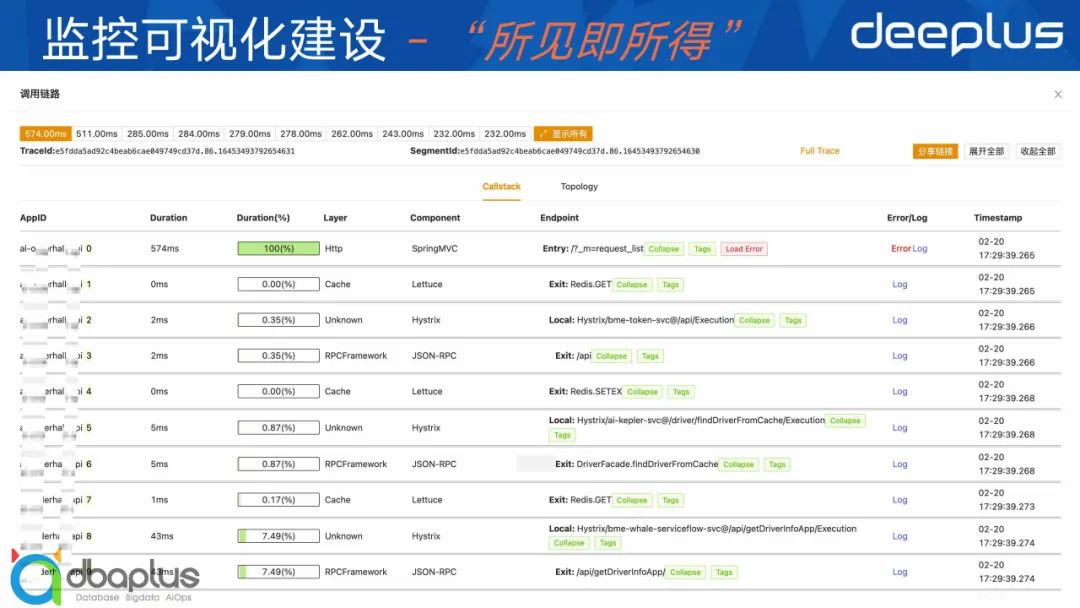
从Trace页面可以看到详细的Trace数据,接口、方法耗时、异常调用栈等信息。这样下来整体的排障流畅度非常的高,如果异常调用栈信息还满足不了排障需求的话,还可以点击log跳转到日志页面来查看日志详情,进行更详细的信息查看和排障。
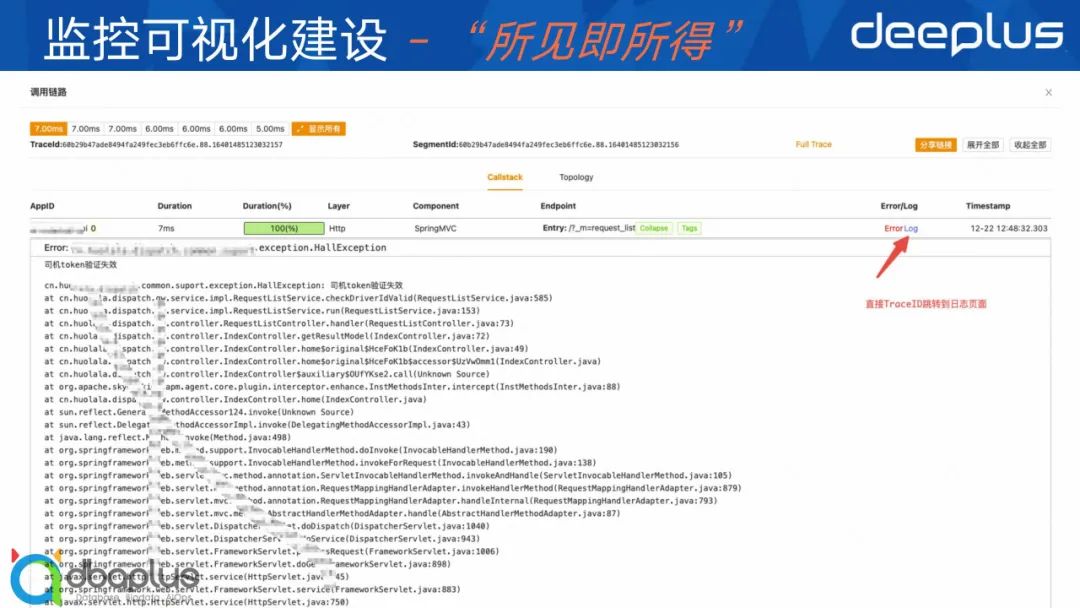
3、Trace拓扑图

这里是一个Trace拓扑图,拓扑图可以帮助我们站在更高的维度去查看我们整个链路的调用情况,比如说整条链路经过哪些服务?哪些服务的耗时比较大?出现异常等,点击异常节点也可以查看异常信息,提供更丰富的视觉体验和排障手段。
六、串联Metric、Trace、Log以及业务指标闭环
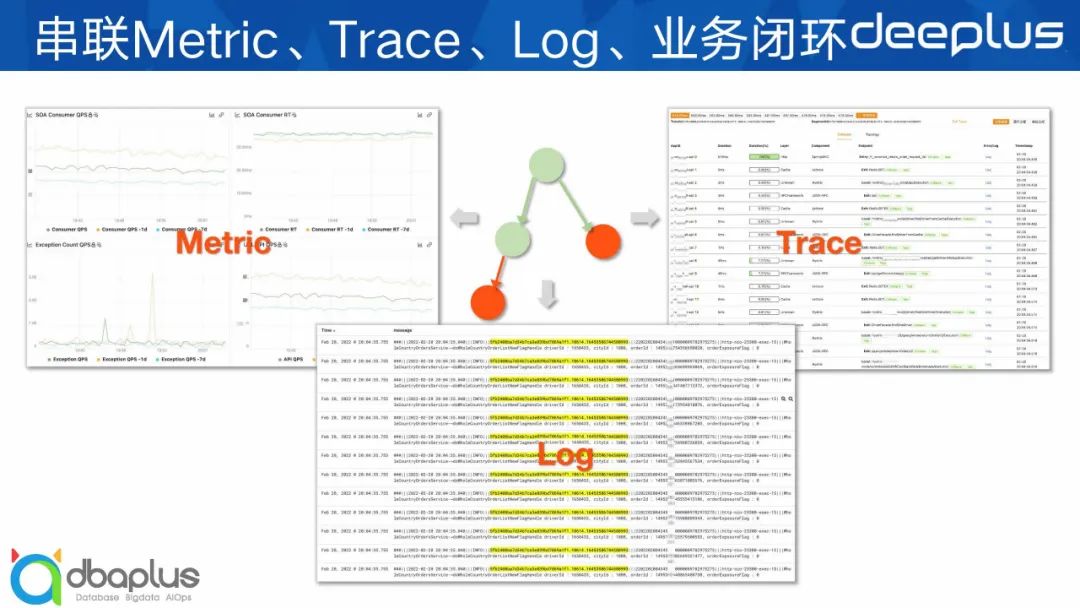
这一章节主要介绍下我们如何将Metric、Trace、Log和业务服务这四个独立的服务的指标数据打通的。
前面也提到过因为历史原因Metric、Trace、Log三个服务一直是独立的团队在维护,最初其实没有关联的,但我们在排障的时候又需要这几个服务的数据紧密关联、配合才能满足日常的排障需要。串联他们之间的闭环,才能提供更顺畅高效的排障手段,实现整个监控体系的价值最大化。
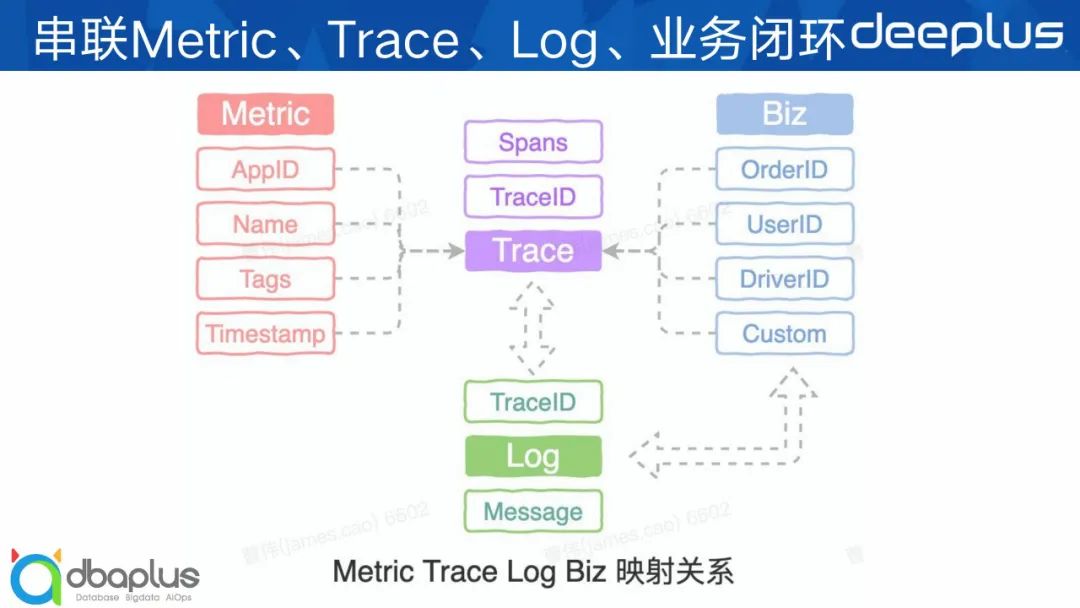
那么我们是如果打通的?其实重点就是建设对应数据结构的映射关系。我们可以从左往右看映射关系图。
首先是Metric数据,包含APPID、Name、Tags和时间戳等关键信息,这些信息都可以作为Trace列表查询入参,到ES里查到对应的Trace基础信息列表,再通过TraceID从HBase中查询Trace详情,包含整体调用链的Span列表,最终构建出Trace调用链展示到前端。
同时Trace和Log之间通过TraceID建立很强的关联关系,业务在接入监控后每条log都会自动添加TraceID数据以此来建立强关联。
再看右边的业务数据,我们支持业务代码中自由埋点,以Trace Tag的形式将业务数据(OrderID、UserID、DriverID等)埋到Trace数据中,这样就将业务数据和具体的Trace关联上了,同时我们支持根据OrderID、UserID等业务参数查询对应的Trace列表,这样就把各方面数据串联起来了。
下面 3 张是我们的串联效果展示图。
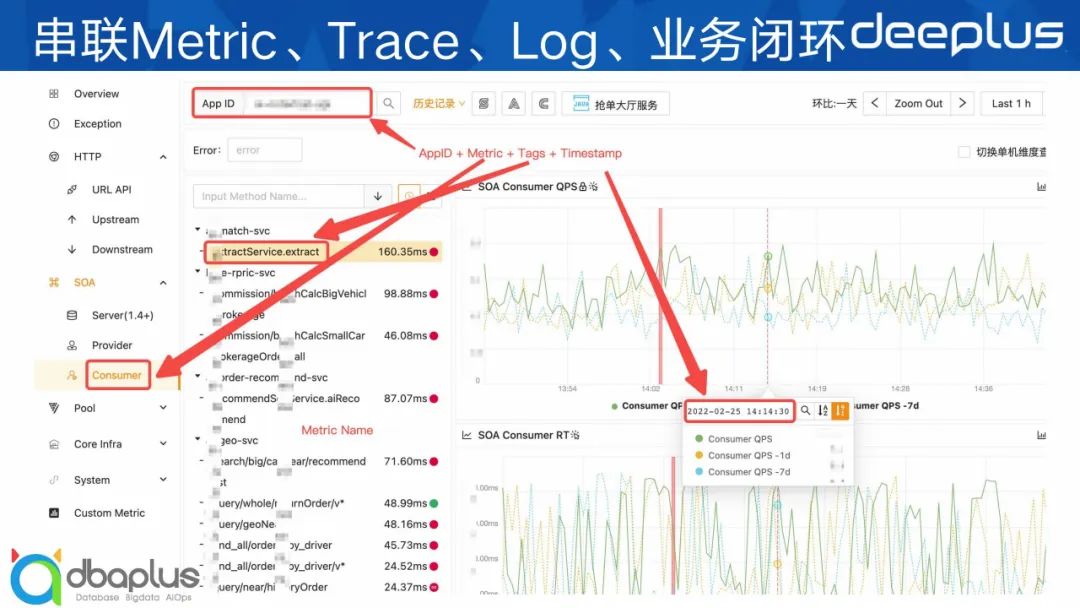
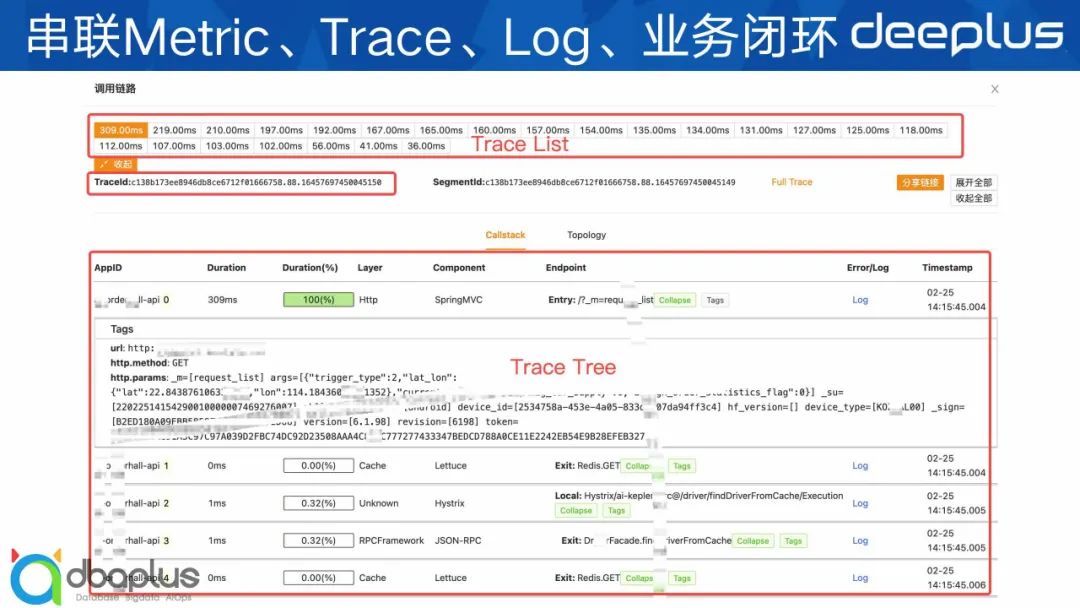
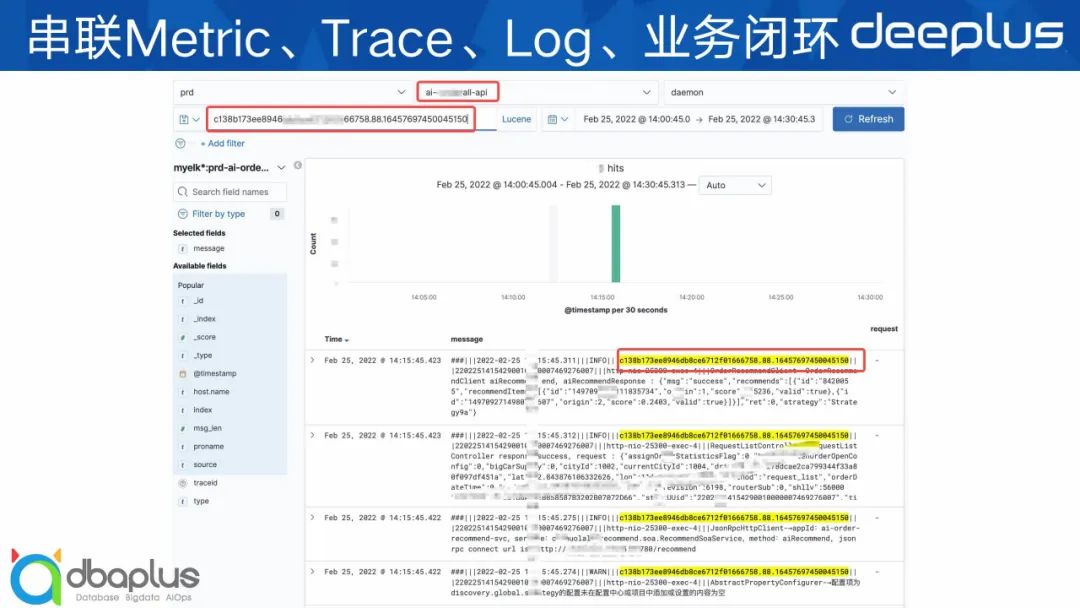
在这个这套体系出来之前,业务大部分都是通过日志里面查关键字来进行第一步的异常发现和排障,效率非常得低。现在首先是从Metric指标页面去看哪些QPS、RT飙高,然后点击曲线看Trace链路,查看异常调用栈,如果还看不到有用的信息再点击跳转到TraceID对应的日志里面查看。整个排障思路和手段更高效、规范,相当于重新定义了业务的排查思路。
七、展望
1、根因分析
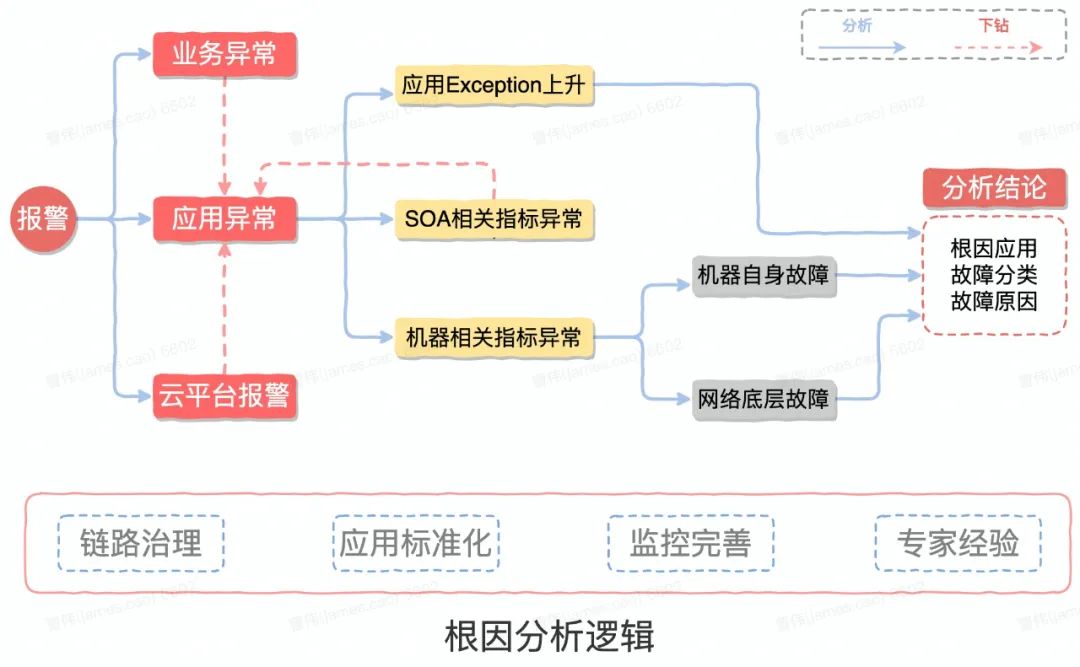
最后分享下根因分析这块的建设,简单来说根因分析其实就是将我们日常的一些排障思路和经验沉淀固化成为一些专家经验,然后让代码自动执行排障流程,比如说图中的场景,报警原因可能有多种,比如:业务异常、应用异常云平台报警的一些异常,但最终它都能归因到应用异常,应用异常又分Exception、SOA调用异常或者机器指标异常,那如果是Exception就直接得出结论。
如果是一个SOA异常,就需要做指标下钻找他的下游。下游服务又回到上面的判断逻辑,就这样递归直到找到真正发生异常的那个根应用,最终诊断出是应该Exception异常还是机器相关异常,得出最终的分析结论,包括根因应用、根因分类和故障原因。
要达到根因分析的目标,我们需要做很多前置动作,链路治理、应用标准化,例如推广内部调用SOA化,还有监控需要完善,不仅要完善业务接入监控的覆盖率,还要完善我们的监控的指标类型覆盖率,不只要应用维度的数据,还要业务维度的数据、网络层面的数据。
2、智能告警、预案

智能告警、预案简单理解就是把我们日常的一个应对异常情况时候的一些SOP固化、沉淀成为我们的专家经验,然后形成一套规则,根据这些规则构建规则引擎,不同的场景参数会匹配到特定的规则或一些规则,通过规则引擎计算得出对应的一些处理手段,比如说报警或者给出一些建议提示,更进一步的话还可以做到自动化执行一些预案动作。
如图,左边可以认为是一些场景入参,它可以是一些应用指标,也可以云平台的一些数据,比如网络指标数据,也可能是一些历史的业务数据趋势,也可能是一些大促的关键信息、日常的发布变更信息等。不通的入参命中不通的规则,执行对应的右边的动作。
举个简单的例子,假如现在有个业务,他的某个接口的OPS和CPU同时飙高,我们可以简单理解他的上游调用量因为某些原因飙高,这种场景我们一般可以进行一个扩容动作来缓解服务集群的压力,那这平台首先进行电话、飞书告警并给出集群扩容的建议,当然这里是可以进一步做到智能化自动扩容,这也是我们后面要发展的方向。
所以在整体预案告警这一块后续的规划上,主要有2个方向:完善场景覆盖率和不断智能化。不断的丰富规则引擎,在执行这块做更多的智能化,比如自动扩容自动执行预案等。

活动推荐 - Gdevops峰会·广州站
2022 Gdevops全球敏捷运维峰会·广州站将于5月13日举办,精选运维热门议题,共同探索云原生时代下的运维转型蜕变之路,部分议题抢先剧透:
-
【腾讯游戏】腾讯游戏SRE工具链建设实践
-
【平安银行】数据库智能化运维实践之故障自愈
-
【光大银行】光大银行智能运维探索与实践
-
【网易游戏】网易游戏AIOps探索与实践
-
【vivo】万级实例规模下的数据库可用性保障实践
-
【微众银行】亿级金融系统智能运维的深度实践
-
【顺丰科技】运维DevOps体系解析与落地实践(拟)
-
【去哪儿网】大规模混沌工程自动演练实践
-
【货拉拉】货拉拉智能监控平台的设计与实践
-
(持续更新……)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK