

Simple Fast Adaptive Grid To Accelerate Collision Detection Between AABB of part...
source link: https://www.codeproject.com/Articles/5327631/Simple-Fast-Adaptive-Grid-To-Accelerate-Collision
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Collision Detection
Collision detection is the act of finding intersections of multiple objects in a dimension or in higher number of dimensions. As it sounds simple on talking, it is very useful on multiple branches of science, video games and web sites. A popular use case is keeping rigid bodies from moving into each others volume in a video game's physics simulation.
Background
In coding for a simple physics simulation or writing some tutorial for a graphics-related problem, developers may require a collision-detection algorithm but many include a whole fully-fledged game-engine (as large as 100s of megabytes) only to use it as a collision detector and go through long installation & dependency compilation phases. It may be useful to have a less-than-1000-line header-only solution and simply "#include" the header, that does only AABB collision detection for many particles (and preferably fast enough for real-time work) and nothing more.
Baseline
Before starting optimizations, there is a given challenge (with simplified edge-cases handling):
- Detect all-pairs collisions between 10k point-cloud object instances,
- each cloud object made of 125 points (3 floating-point variables each)
- randomly sized
- randomly distributed on 3D space
- Do same, but at 60 FPS. (crude definition of real-time)
- Detect collisions between 1 dynamic point cloud AABB vs 10k static point-cloud AABBs, quicker than 1 microsecond
- Use a low-end system (FX8150 CPU at 2.1 GHz, single-channel 1333MHz DDR3 RAM)
- In C++ (g++-10 for Ubuntu)

As a simplest reference solution (to be the base of performance comparisons), program will have a highly simplified brute-force intersection test:
// psudo-code
CollisionList collisionPairList;
for(each a object in scene)
for(each b object in scene)
for(each c point in a)
for(each d point in b)
{
if(c is close enough to d)
{
// a intersects b
add id-values of a and b into collisionPairList
end the loops of c and d
}
}
Reference test program source code (uses the FastCollisionDetectionLib.h header file from this github repository)
#include"FastCollisionDetectionLib.h"
#include<iostream>
template<typename CoordType>
struct Vector3D
{
CoordType x,y,z;
Vector3D<CoordType> crossProduct(Vector3D<CoordType> vec)
{
Vector3D<CoordType> res;
res.x = y*vec.z - z*vec.y;
res.y = z*vec.x - x*vec.z;
res.z = x*vec.y - y*vec.x;
return res;
}
Vector3D<CoordType> operator - (Vector3D<CoordType> vec)
{
Vector3D<CoordType> result;
result.x = x-vec.x;
result.y = y-vec.y;
result.z = z-vec.z;
return result;
}
Vector3D<CoordType> operator + (Vector3D<CoordType> vec)
{
Vector3D<CoordType> result;
result.x = x+vec.x;
result.y = y+vec.y;
result.z = z+vec.z;
return result;
}
Vector3D<CoordType> operator * (CoordType v)
{
Vector3D<CoordType> result;
result.x = x*v;
result.y = y*v;
result.z = z*v;
return result;
}
CoordType abs()
{
return std::sqrt(x*x+y*y+z*z);
}
};
template<typename CoordType>
struct PointCloud
{
Vector3D<CoordType> point[125];
PointCloud(CoordType x, CoordType y, CoordType z)
{
for(int i=0;i<125;i++)
{
point[i].x=x+i%5-2.5f;
point[i].y=y+(i/5)%5-2.5f;
point[i].z=z+i/25-2.5f;
}
}
};
template<typename CoordType>
bool pointCloudIntersection(PointCloud<CoordType>& cl1, PointCloud<CoordType>& cl2)
{
for(Vector3D<CoordType>& p:cl1.point)
{
for(Vector3D<CoordType>& p2:cl2.point)
{
if((p-p2).abs()<1.0f)
{
return true;
}
}
}
return false;
}
int main()
{
using cotype = float;
bool results[41*41];
PointCloud<cotype> ico1(0,0,0);
// heating the CPU for benchmarking
for(int i=0;i<10000;i++)
{
PointCloud<cotype> ico2(0,0.1f,i*0.1f);
results[0]=pointCloudIntersection(ico1,ico2);
}
// benchmark begin
size_t nano;
{
FastColDetLib::Bench bench(&nano);
for(int j=-20;j<=20;j++)
for(int i=-20;i<=20;i++)
{
PointCloud<cotype> ico2(0,i*0.5f,j*0.5f);
results[i+20+(j+20)*41 ]=pointCloudIntersection(ico1,ico2);
}
}
std::cout<<41*41<<"x collision checks between 2 clouds = "<<nano<<" nanoseconds ("<<(nano/(41.0*41.0))<<" ns per collision check)"<<std::endl;
for(int i=0;i<41*41;i++)
{
if(i%41==0)
std::cout<<std::endl;
std::cout<<results[i];
}
std::cout<<std::endl;
return 0;
}
As expected, the program outputs below result:
1681x collision checks between 2 clouds = 253073988 nanoseconds (150550 ns per collision check) 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000111111111111111111100000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000 00000000000000000000000000000000000000000
Every point-cloud vs point-cloud collision-check takes 150 microseconds. On next test, collision detection for 100 point-clouds is computed:
int main()
{
using cotype = float;
PointCloud<cotype> ico1(0,0,0);
// heating the CPU for benchmarking
for(int i=0;i<10000;i++)
{
PointCloud<cotype> ico2(0,0.1f,i*0.1f);
pointCloudIntersection(ico1,ico2);
}
const int N = 100;
std::vector<PointCloud<cotype>> objects;
for(int i=0;i<N;i++)
{
objects.push_back(PointCloud<cotype>(i*1.5,i*1.5,i*1.5));
}
// benchmark begin
size_t nano;
std::map<int,std::map<int,bool>> collisionMatrix;
{
FastColDetLib::Bench bench(&nano);
for(int i=0;i<N;i++)
for(int j=0;j<N;j++)
{
collisionMatrix[i][j]=pointCloudIntersection(objects[i],objects[j]);
}
}
std::cout<<N*N<<"x collision checks between 2 clouds = "<<nano<<" nanoseconds ("<<(nano/((double)N*N))<<" ns per collision check)"<<std::endl;
std::cout<<collisionMatrix.size()<<" unique object are in a collision"<<std::endl;
return 0;
}
result:
10000x collision checks between 2 clouds = 1002381391 nanoseconds (100238 ns per collision check) 100 unique object are in a collision
Same test with N=500:
250000x collision checks between 2 icosahedrons = 25975908607 nanoseconds (103904 ns per collision check) 500 unique object are in a collision
Run-time increased from 1 second to 26 seconds (despite 1 collision computation lowered to 103 microseconds). At this scaling rate ( O(N^2) ), 10k point clouds needs no less than 3 hours. This is not close enough to real-time performance.
First Optimization: AABB
To evade unnecessary collision checking (such as between object 1 and object 100 in test above), axis-aligned bounding-box of each object can be computed and used for "approximation" of collision checking such that it makes it safe to say "these two objects are certainly not overlapping" depending on AABB collision test result (false). If AABB collision returns true, then it will be useful to do check the finer grained point-cloud vs point-cloud collision.
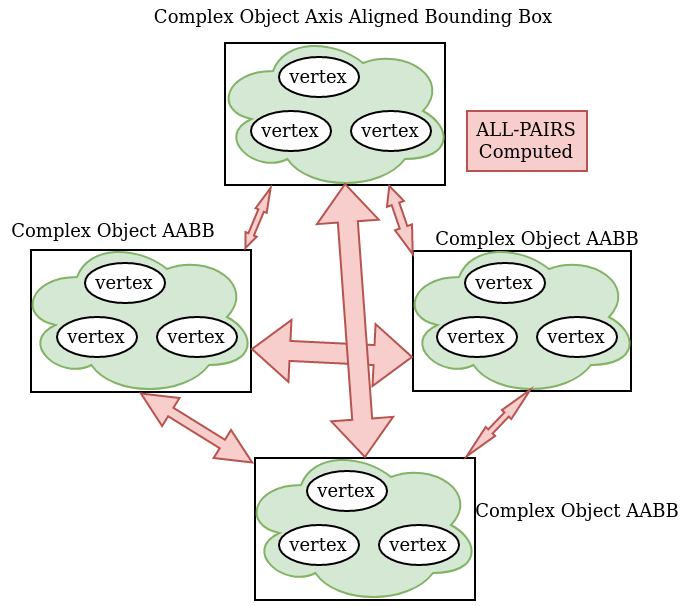
AABB requires only simple min-max points in 3D space for each object, for every axis X,Y and Z.
- minimum X: the minimum X coordinate of all points in the object that makes first contact in X dimension
- maximum X: the maximum X coordinate of all points in the object that makes first contact in X dimension
- same for Y and Z
Axis-aligned bounding-buffer collision checking is simple:
- Check if two object AABBs collide on X dimension (projection on X axis)
- if they don't collide, there is no collision
- Do same checking for Y and Z dimensions
- If all axis have collision, then there is collision between AABBs
Following function can be repeatedly used for X,Y and Z dimensions of two AABBs to find a collision:
bool intersectDim(
const CoordType minx, const CoordType maxx,
const CoordType minx2, const CoordType maxx2)
{
return !((maxx < minx2) || (maxx2 < minx));
}
New point cloud class is given extra boundary calculations:
template<typename CoordType>
struct PointCloud
{
CoordType xmin,ymin,zmin;
CoordType xmax,ymax,zmax;
Vector3D<CoordType> point[125];
PointCloud(CoordType x, CoordType y, CoordType z)
{
xmin=x-2.5f;
ymin=y-2.5f;
zmin=z-2.5f;
xmax=x-2.5f;
ymax=y-2.5f;
zmax=z-2.5f;
for(int i=0;i<125;i++)
{
point[i].x=x+i%5-2.5f;
point[i].y=y+(i/5)%5-2.5f;
point[i].z=z+i/25-2.5f;
if(xmin>point[i].x)
xmin=point[i].x;
if(ymin>point[i].y)
ymin=point[i].y;
if(zmin>point[i].z)
zmin=point[i].z;
if(xmax<point[i].x)
xmax=point[i].x;
if(ymax<point[i].y)
ymax=point[i].y;
if(zmax<point[i].z)
zmax=point[i].z;
}
}
};
New 3D collision test, still brute-force but evading unnecessary checks by broad-phase collision check:
std::map<int,std::map<int,bool>> collisionMatrix;
{
FastColDetLib::Bench bench(&nano);
for(int i=0;i<N;i++)
for(int j=0;j<N;j++)
{
// check AABB collision on X axis
if(intersectDim(objects[i].xmin,objects[i].xmax,objects[j].xmin,objects[j].xmax))
// check AABB collision on Y axis
if(intersectDim(objects[i].ymin,objects[i].ymax,objects[j].ymin,objects[j].ymax))
// check AABB collision on Z axis
if(intersectDim(objects[i].zmin,objects[i].zmax,objects[j].zmin,objects[j].zmax))
// only then, real fine-grained collision-checking is made
collisionMatrix[i][j]=pointCloudIntersection(objects[i],objects[j]);
}
}
output (for 500 point-clouds again, with same initializations):
250000x collision checks between 2 clouds = 55842744 nanoseconds (223.371 ns per collision check) 500 unique object are in a collision
Decreasing run-time from 26 seconds to 55 milliseconds is very helpful on the way to real-time performance but still not enough.
At this point, scale of benchmark can be increased again, below output is from same test ran for 10000 particles:
100000000x collision checks between 2 clouds = 2015666583 nanoseconds (20.1567 ns per collision check) 10000 unique object are in a collision
2 seconds of run-time for 10k objects is only 59.5 FPS far from real-time performance. AABB collision checking is useful for early-exiting from collision checking. If X-dimension check fails, all the other dimension calculations are evaded. Since processing a sorted array is faster due to branch-prediction of CPU, the initialization of point-clouds on increasing X dimension is also helping here. For a pseudo-random distribution, it is not wrong to expect a lower performance.
Performance with random distribution (source code):
100000000x collision checks between 2 clouds = 20054203334 nanoseconds (200.542 ns per collision check) 10000 unique object are in a collision
It has only 1/10 speed compared to a sorted array of AABB of objects. Even an old CPU like FX8150 takes speculation serious and maintains 10x performance with sorted arrays, at least when run-time is dominated by branching.
This means, for real-world scenarios (with randomness), it is currently only 0.05 FPS, or 59.95 FPS away from real-time performance and indicates the need for a spatial acceleration structure.
Second Optimization: Grid
There are multiple types of acceleration-structures that are better on their application areas and have specific disadvantages.
- Uniform Grid: Divides volume into single 3D layer of cells to store objects that touch them.
- Advantage: Performs good when object density is uniform accross the computed volume.
- Disadvantage: Teapot-in-stadium problem causes uniform grid to waste too high memory unused and lose efficiency for computing colllisions.
- Octree: Divides volume into fixed hieararchical volumes made of 8 child-nodes per parent-node.
- Advantage: irregular object density is handled much better than a uniform grid, reducing memory footprint.
- Disadvantage: tree-traversal latency
- Kd-Tree: Similar to octree but division is maintained as dual child-nodes per parent-node
- Advantage: Closest neighbor search is faster
- Disadvantage: Requires extra time to rebalance when adding/removing objects
- BVH: Divides groups objects instead of volume.
- Advantage: Nodes have no bounds, they can map practically an infinite volume.
- Disadvantage: Nodes can overlap, even between child-node and parent-node, this makes it harder to compute closest neighbors or other attributes that use "spatial hashing".
In this article, the simplest spatial acceleration, uniform grid structure, is implemented, benchmarked against brute-force and optimized to become adaptive.
Implementing a grid is straighforward, with two different versions:
- 1) Grid of collision masks
- Create an array of integers and reinterpret them as cells of an imaginary grid of a volume.
- For each object, put its pointer or id value into all overlapping cells in the grid
- For every other object, check id values / pointers found only in overlapping cells
- Compute collisions only within cells that have least 1 object id
- 2) Grid of center points
- Create an array of integers and reinterpret them as cells again
- For each object, put id value only to the cell that contains the center of AABB
- For every other object, scan all neighboring cells that may contain an object's id
These implementations have different performance characteristics. Using only center points to insert id value saves more memory and insertion operation takes less time. Using collision masks makes collision query faster if objects are smaller than a cell. Center point variant does not work efficient when there are various shaped objects with different AABB sizes. This forces the grid to scan for cells over a greater distance due to find bigger objects' collisions. Collision masking on the other hand, signs only the cells that overlap with the object AABB regardless of its size and is still maintain speed if high percentage of objects are small enough.
In short definition, collision mask gives greater collision scanning performance for the grid while center point version has much better object-insertion performance.
The test implementation will be using collision mask version of the uniform grid:
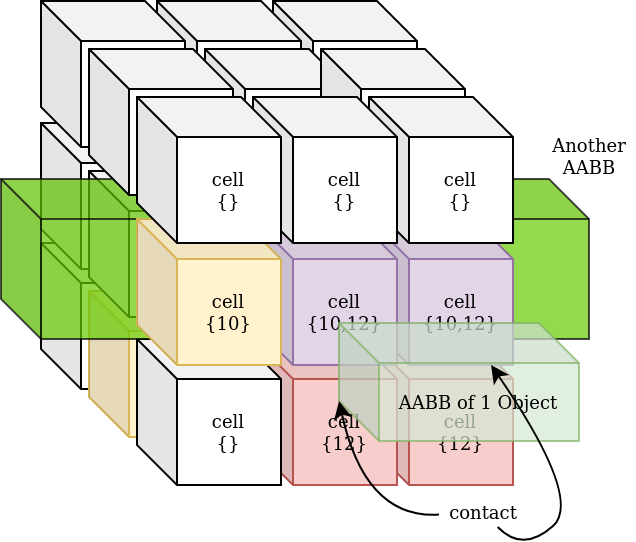
- Finding a list of overlapping cells is O(1) operation
- Traversing overlapping cells (to insert id value) is O(k) where k=number of overlapping cells
- Computing collisions by brute-force is O(m*m) where m=maximum number of particles in cell
- Overall complexity becomes O(N*k*m*m)
- If objects are smaller than cells, it becomes O(N*m*m)
- If cells are given only small number of objects, it becomes O(N) with a constant

Grid Implementation
By offloading AABB-related calculations from PointCloud to AABBofPointCloud struct (source code), it becomes easier to work with different objects later, but for simplicity, interface declarations are postponed to later titles and only simple struct wrapper is used.
New point cloud struct:
template<typename CoordType>
struct PointCloud
{
Vector3D<CoordType> point[125];
PointCloud(CoordType x, CoordType y, CoordType z)
{
for(int i=0;i<125;i++)
{
point[i].x=x+i%5-2.5f;
point[i].y=y+(i/5)%5-2.5f;
point[i].z=z+i/25-2.5f;
}
}
};
AABB struct:
template<typename CoordType>
struct AABBofPointCloud
{
AABBofPointCloud(int idPrm, PointCloud<CoordType> * pCloudPrm)
{
id=idPrm;
pCloud = pCloudPrm;
xmin=pCloud->point[0].x;
ymin=pCloud->point[0].y;
zmin=pCloud->point[0].z;
xmax=pCloud->point[0].x;
ymax=pCloud->point[0].y;
zmax=pCloud->point[0].z;
for(int i=0;i<125;i++)
{
if(xmin>pCloud->point[i].x)
xmin=pCloud->point[i].x;
if(ymin>pCloud->point[i].y)
ymin=pCloud->point[i].y;
if(zmin>pCloud->point[i].z)
zmin=pCloud->point[i].z;
if(xmax<pCloud->point[i].x)
xmax=pCloud->point[i].x;
if(ymax<pCloud->point[i].y)
ymax=pCloud->point[i].y;
if(zmax<pCloud->point[i].z)
zmax=pCloud->point[i].z;
}
}
int id;
PointCloud<CoordType>* pCloud;
CoordType xmin;
CoordType ymin;
CoordType zmin;
CoordType xmax;
CoordType ymax;
CoordType zmax;
};
Grid class:
template<typename CoordType, int Size, int ObjectsPerCell>
class Grid
{
public:
Grid(CoordType minCor, CoordType maxCor)
{
id=0;
mincorner=minCor;
maxcorner=maxCor;
cellData.resize(Size*Size*Size*(ObjectsPerCell+1));
for(int i=0;i<cellData.size();i++)
cellData[i]=0;
}
template<typename Func>
void forEachCellColliding(AABBofPointCloud<CoordType>* aabb, const Func& func)
{
// calculate cell size (equal for all dimensions for now)
const CoordType step = (maxcorner - mincorner)/Size;
// calculate overlapping region's cell indices
const int mincornerstartx = std::floor((aabb->xmin - mincorner) / step);
const int maxcornerendx = std::floor((aabb->xmax - mincorner) / step);
const int mincornerstarty = std::floor((aabb->ymin - mincorner) / step);
const int maxcornerendy = std::floor((aabb->ymax - mincorner) / step);
const int mincornerstartz = std::floor((aabb->zmin - mincorner) / step);
const int maxcornerendz = std::floor((aabb->zmax - mincorner) / step);
for(int i=mincornerstartz;i<=maxcornerendz;i++)
for(int j=mincornerstarty;j<=maxcornerendy;j++)
for(int k=mincornerstartx;k<=maxcornerendx;k++)
{
if(i<0 || i>=Size || j<0 || j>=Size || k<0 || k>=Size)
continue;
func(k,j,i,aabb);
}
}
void addObject(AABBofPointCloud<CoordType>* aabb)
{
forEachCellColliding(aabb, [&](int k, int j, int i, AABBofPointCloud<CoordType>* aabb){
const int collidingCellIndex = (k+j*Size+i*Size*Size)*(ObjectsPerCell+1);
const int lastUsedIndex = cellData[collidingCellIndex]++;
cellData[collidingCellIndex+lastUsedIndex+1]=id;
idMapping[id++]=aabb;
});
}
std::vector<AABBofPointCloud<CoordType>*> checkCollisionsWithSingleAABB(AABBofPointCloud<CoordType>* aabb)
{
std::vector<AABBofPointCloud<CoordType>*> result;
forEachCellColliding(aabb, [&](int k, int j, int i, AABBofPointCloud<CoordType>* aabb){
const int collidingCellIndex = (k+j*Size+i*Size*Size)*(ObjectsPerCell+1);
const int numObjectsInCell = cellData[collidingCellIndex];
for(int p=0;p<numObjectsInCell;p++)
{
const int idObj = cellData[collidingCellIndex+1+p];
AABBofPointCloud<CoordType>* aabbPtr = idMapping[idObj];
// evade self-collision and duplicated collisions
if( aabb->id < aabbPtr->id)
if(intersectDim(aabb->xmin, aabb->xmax, aabbPtr->xmin, aabbPtr->xmax))
if(intersectDim(aabb->ymin, aabb->ymax, aabbPtr->ymin, aabbPtr->ymax))
if(intersectDim(aabb->zmin, aabb->zmax, aabbPtr->zmin, aabbPtr->zmax))
{
result.push_back(aabbPtr);
}
}
});
return result;
}
private:
int id;
CoordType mincorner,maxcorner;
std::map<int,AABBofPointCloud<CoordType>*> idMapping;
std::vector<int> cellData;
};
Both object insertion and collision checking are using the same base function that scans over all overlapping cells and only the innermost part is changed between the insertion and checking, by a lambda function.
Please note that all duplicated calculations and self-collisions are evaded by a simple id comparison before collision tests. This effectively gives 2x performance even without any optimization.
Due to uniform grid requires uniform distribution, object distribution area is increased to a cube of width 450 while each point cloud has size of 5 units. With 10000 clouds:
const int N = 10000;
std::vector<PointCloud<cotype>> objects;
oofrng::Generator<64> gen;
for(int i=0;i<N;i++)
{
objects.push_back(PointCloud<cotype>(gen.generate1Float()*450,gen.generate1Float()*450,gen.generate1Float()*450));
}
std::vector<AABBofPointCloud<cotype>> AABBs;
for(int i=0;i<N;i++)
{
AABBs.push_back(AABBofPointCloud<cotype>(i,&objects[i]));
}
// benchmark begin
size_t nano;
std::map<int,std::map<int,bool>> collisionMatrix;
{
FastColDetLib::Bench bench(&nano);
// uniform grid for 32x32x32 cells each with 30 objects max
// mapped to (0,0,0) - (450,450,450) cube
Grid<cotype,32,30> grid(0,450);
// add AABBs to grid
for(int i=0;i<N;i++)
{
grid.addObject(&AABBs[i]);
}
for(int i=0;i<N;i++)
{
std::vector<AABBofPointCloud<cotype>*> collisions = grid.checkCollisionsWithSingleAABB(&AABBs[i]);
for(AABBofPointCloud<cotype>* aabb:collisions)
{
if(pointCloudIntersection(*aabb->pCloud, *AABBs[i].pCloud))
{
collisionMatrix[AABBs[i].id][aabb->id]=true;
collisionMatrix[aabb->id][AABBs[i].id]=true;
}
}
}
}
std::cout<<N<<" vs "<<N<<" point-clouds collision checking by uniform grid= "<<nano<<" nanoseconds"<<std::endl;
int total = 0;
for(auto c:collisionMatrix)
{
for(auto c2:c.second)
{
if(c2.second)
total++;
}
}
std::cout<<total<<" total collisions (half as many for pairs)"<<std::endl;
output:
10000 vs 10000 point-clouds collision checking by uniform grid= 32221053 nanoseconds 564 total collisions (half as many for pairs)
32 milliseconds per 10000 vs 10000 collision test is very close to the 60 FPS target (16.6 ms) and not too far from 1 microsecond per dynamic collision check (3.2 microsecond per cloud currently).
For simple grid implementations, tuning is required to achieve best performance for a specific scene. The above test uses a grid of 32x32x32 cells and maximum 30 objects per cell. To have an idea about best performance, the latency of pointCloudUntersection(p1,p2) function must be subtracted from total latency. Commenting this function call out results in 18 milliseconds of run-time. This means that on the grid-side, there is 14 milliseconds of headroom to optimize. This can be achieved by tuning grid parameters, memory access pattern, types of data to be saved on cells.
Filling a grid and doing collision tests for each AABB versus whole grid one by one is most probably thrashing the cache contents of CPU. By the time second AABB is tested, the first AABB's traversed cell data is replaced. To fix this issue, tiled-computing is needed. Tiling size needs to be at most the size of L1 cache of CPU to benefit from fastest cell data access.
Since each cell was given a limit of 30 AABBs to store, running brute-force on each cell could use L1 cache efficiently without increasing time-complexity beyond unacceptable levels, if there are not many duplicates of cell contents.
With a new method for Grid class (source code), collision-test algorithm iterates over cells instead of AABBs and does basic duplicate-removal by maintaining an internal collision matrix:
std::map<int,std::map<int,bool>> checkCollisionAllPairs()
{
std::map<int,std::map<int,bool>> collisionMatrix;
for(int k=0;k<Size;k++)
for(int j=0;j<Size;j++)
for(int i=0;i<Size;i++)
{
const int cellIndex = (i+j*Size+k*Size*Size)*(ObjectsPerCell+1);
const int nAABB = cellData[cellIndex];
// no check if only 1 or less AABB found
if(nAABB<2)
continue;
// evading duplicates
for(int o1 = 0; o1<nAABB-1; o1++)
{
for(int o2 = o1+1; o2<nAABB; o2++)
{
AABBofPointCloud<CoordType>* aabbPtr1 = idMapping[cellData[cellIndex+1+o1]];
AABBofPointCloud<CoordType>* aabbPtr2 = idMapping[cellData[cellIndex+1+o2]];
if( aabbPtr1->id < aabbPtr2->id)
if(intersectDim(aabbPtr1->xmin, aabbPtr1->xmax, aabbPtr2->xmin, aabbPtr2->xmax))
if(intersectDim(aabbPtr1->ymin, aabbPtr1->ymax, aabbPtr2->ymin, aabbPtr2->ymax))
if(intersectDim(aabbPtr1->zmin, aabbPtr1->zmax, aabbPtr2->zmin, aabbPtr2->zmax))
{
collisionMatrix[aabbPtr1->id][aabbPtr2->id]=true;
}
}
}
}
return collisionMatrix;
}
allows only a simple change in the benchmarking algorithm to do same work, faster:
size_t nano;
std::map<int,std::map<int,bool>> collisionMatrixTmp;
std::map<int,std::map<int,bool>> collisionMatrix;
{
FastColDetLib::Bench bench(&nano);
// uniform grid for 16x16x16 cells each with 30 objects max
// mapped to (0,0,0) - (450,450,450) cube
Grid<cotype,16,30> grid(0,450);
// add AABBs to grid
for(int i=0;i<N;i++)
{
grid.addObject(&AABBs[i]);
}
collisionMatrixTmp = grid.checkCollisionAllPairs();
for(auto c:collisionMatrixTmp)
{
for(auto c2:c.second)
{
if(c2.second)
if(pointCloudIntersection(*AABBs[c.first].pCloud,*AABBs[c2.first].pCloud))
{
collisionMatrix[c.first][c2.first]=true;
collisionMatrix[c2.first][c.first]=true;
}
}
}
}
output:
10000 vs 10000 point-clouds collision checking by uniform grid= 22510565 nanoseconds 564 total collisions (half as many for pairs)
Finding same collisions in 22.5 milliseconds indicates a high percentage of optimization headroom is used this time, despite having duplicated AABB ids in each cell that have multiple overlapping AABBs.
Grid Implementation With Multi-Threaded Single-AABB Collision Check
Without changing cloud-cloud collision test algorithm, the only optimization left to accelerate the overall collision checking process is multiple-threading. In current state of the sample Grid implementation (out of library header), single-object-AABB collision test is inherently thread-safe as it does not create nor edit any internal state. OpenMP can accelerate this part easily while all-pairs computation requires a custom thread-pool (as in library header).
To test the multi-threaded collision computation (without all-pairs at once but single vs all for N times), following OpenMP parallelization is used (source code):
// a simple global locking point
std::mutex mut;
// fx8150 has 8 integer cores, 4 shared FPUs
#pragma omp parallel for
for(int i=0;i<N;i++)
{
std::vector<AABBofPointCloud<cotype>*> result = grid.checkCollisionsWithSingleAABB(&AABBs[i]);
for(auto c:result)
{
if(pointCloudIntersection(*c->pCloud,*AABBs[i].pCloud))
{
// modern C++ scope-based locking
std::lock_guard<std::mutex> lg(mut);
collisionMatrix[c->id][AABBs[i].id]=true;
collisionMatrix[AABBs[i].id][c->id]=true;
}
}
}
output:
10000 vs 10000 point-clouds collision checking by uniform grid= 13742454 nanoseconds 564 total collisions (half as many for pairs)
13.7 milliseconds, including fine-grain collision check and no special multi-threading optimization (all threads using a global lock instead of non-false-sharing per-element lock ).
Since this performance satisfies the initial performance constraints, tests will continue on harder parts of problem: The Teapot in Stadium.
Third Optimization: Adaptive Grid
Up to this point, the uniform grid has this memory layout:

Where each header is either zero or a positive integer. For the upper sample, if grid is given 6 or more AABB instances to add into same cell's volume, it causes segmentation fault (if that is the last cell in the integer array) or it overwrites other cells' header values and causes undefined behavior.
Even when there is no cell-overflow, a clustering pattern of objects makes big portion of the grid unused due to mostly empty cells between clusters of objects. This forces the uniform grid's settings to have many more AABB capacity per cell and cause a higher time-complexity on top of the latency of allocating a bigger integer buffer.
To reproduce such scenario, the coordinate initialization of objects (point clouds) is given an extra 3 iterations that use very close X,Y,Z center coordinates but too far from center-of-mass of the rest of the clouds (source code):
const int N = 10003;
std::vector<PointCloud<cotype>> objects;
oofrng::Generator<64> gen;
for(int i=0;i<N-3;i++)
{
objects.push_back(PointCloud<cotype>(gen.generate1Float()*450,gen.generate1Float()*450,gen.generate1Float()*450));
}
// the teapot in stadium problem
objects.push_back(PointCloud<cotype>(10000,10000,10000));
objects.push_back(PointCloud<cotype>(10001,10001,10001));
objects.push_back(PointCloud<cotype>(10002,10002,10002));
// uniform grid for 16x16x16 cells each with 30 objects max // mapped to (0,0,0) - (10005,10005,10005) cube // due to the teapot-in-stadium problem, has to have a bigger mapping Grid<cotype,16,30> grid(0,10005);
output:
10003 vs 10003 point-clouds collision checking by uniform grid= 2238980417 nanoseconds 570 total collisions (half as many for pairs)
For only 6 more collisions from 3 objects, the performance dropped to 0.45 FPS (2.2 seconds per computation), with 8 threads in use and 14 seconds for single thread. This is even slower than simple brute-force algorithm.
To optimize memory access pattern, allocation usage and time complexity, each cell is made to adapt incoming number of objects, by only using a different cell-header logic:


On every cell-overflow during insertion, algorithm adds a new low-resolution low-capacity grid to the parent grid's child-grid (dynamic) array and inserts all the object AABB ids that are in the overflowed cell (and the currently inserted AABB's id) to the new grid, recursively computed until all overflowed AABBs are inserted successfully. To evade infinite recursion, every deeper grid layer is allocated with 2 more AABB capacity per cell.
Same teapot-in-stadium problem is solved using adaptive-grid implementation from header-file of FastCollisionDetectionLib repository (source code):
std::map<int,std::map<int,bool>> collisionMatrix;
{
FastColDetLib::Bench bench(&nano);
// adaptive grid
FastColDetLib::ThreadPool<cotype> thr;
FastColDetLib::AdaptiveGrid<cotype> grid(thr,0,0,0,10005,10005,10005);
// add AABBs to grid
for(int i=0;i<N;i++)
{
grid.add(&AABBs[i],1);
}
std::mutex mut;
#pragma omp parallel for
for(int i=0;i<N;i++)
{
std::vector<FastColDetLib::IParticle<cotype>*> result = grid.getDynamicCollisionListFor((FastColDetLib::IParticle<cotype>*)&AABBs[i]);
for(auto c:result)
{
if(c->getId() != AABBs[i].getId())
if(pointCloudIntersection(*AABBs[c->getId()].pCloud,*AABBs[i].pCloud))
{
std::lock_guard<std::mutex> lg(mut);
collisionMatrix[c->getId()][AABBs[i].id]=true;
collisionMatrix[AABBs[i].id][c->getId()]=true;
}
}
}
}
output:
10003 vs 10003 point-clouds collision checking by uniform grid= 16226199 nanoseconds 570 total collisions (half as many for pairs)
Slightly less than 16.7 milliseconds (60FPS), with 8 threads in-use and simple locking. Adaptation keeps maximum objects per cell low and allocates much lower amount of integer buffer areas that are left unused. Both combine into better caching of (child-grid) traversal and higher density per volume (assuming that the maximum number of same-cell overlapping objects do not reach hundreds on many cells).
Similar performance is shown by multi-threaded all-pairs computation method (source code):
10003 vs 10003 point-clouds collision checking by uniform grid= 16811872 nanoseconds 570 total collisions (half as many for pairs)
FastCollisionDetectionLib's adaptive-grid implementation is only marginally different than this article's contents and is incrementally optimized for more performance (next optimization is multi-threading support for AABB insertion method of grid.add(..) ).
Second part of the challenge was querying collision list for single AABB quicker than 1 microsecond. With a change on the benchmarking:
for(int i=0;i<10003;i++)
{
std::vector<FastColDetLib::IParticle<cotype>*> result;
{
FastColDetLib::Bench bench(&nano);
result = grid.getDynamicCollisionListFor((FastColDetLib::IParticle<cotype>*)&AABBs[i]);
}
std::cout<<1<<" vs "<<N<<" AABB collision checking by adaptive grid= "<<nano<<" nanoseconds "<<std::endl;
std::cout<<result.size()<<" collisions detected for this AABB"<<std::endl;
}
output:
... 1 vs 10003 AABB collision checking by adaptive grid= 1767 nanoseconds 1 collisions detected for this AABB 1 vs 10003 AABB collision checking by adaptive grid= 5340 nanoseconds 1 collisions detected for this AABB 1 vs 10003 AABB collision checking by adaptive grid= 1757 nanoseconds 1 collisions detected for this AABB 1 vs 10003 AABB collision checking by adaptive grid= 1743 nanoseconds 3 collisions detected for this AABB 1 vs 10003 AABB collision checking by adaptive grid= 1276 nanoseconds 3 collisions detected for this AABB 1 vs 10003 AABB collision checking by adaptive grid= 1114 nanoseconds 3 collisions detected for this AABB
It has at least 10% more latency than 1 microsecond given by challenge and only when there are few collisions in a non-branching grid cell. Adaptation has more latency due to grid-to-grid traversing logic.
Latency can be hidden with multithreading or pipelining. With multithreading and no locking (fully independent collision query), 10003 queries finish quicker than a microsecond if per-cell locking is used (less than 16 ms from earlier benchmark):
std::atomic<int> ctr;
ctr.store(0);
{
{
FastColDetLib::Bench bench(&nano);
#pragma omp parallel for
for(int i=0;i<N;i++)
{
std::vector<FastColDetLib::IParticle<cotype>*> result;
result = grid.getDynamicCollisionListFor((FastColDetLib::IParticle<cotype>*)&AABBs[i]);
ctr+= result.size();
}
}
std::cout<<N<<" vs "<<N<<" AABB collision checking by adaptive grid= "<<nano<<" nanoseconds "<<std::endl;
std::cout<<"total = "<<ctr.load()<<std::endl;
}
output:
10003 vs 10003 AABB collision checking by adaptive grid= 3760629 nanoseconds total = 10573
3.7 milliseconds for 10k objects is equivalent to 370 nanoseconds per object.
The FastColDetLib library works only on pointers of IParticle interface (and decouples the user-implementation from library implementation) to maintain different types of objects within same scene. Interface expects user to implement these methods:
struct AABBofPointCloud: public FastColDetLib::IParticle<CoordType>
{
...
const CoordType getMaxX()const {return xmax;}
const CoordType getMaxY()const {return ymax;}
const CoordType getMaxZ()const {return zmax;}
const CoordType getMinX()const {return xmin;}
const CoordType getMinY()const {return ymin;}
const CoordType getMinZ()const {return zmin;}
const int getId()const {return id;}
...
};
getMaxX/Y/Z and getMinX/Y/Z methods are used for computing collisions while getId method is used to evade duplications inside all-pairs computation (grid.getCollisions()). Working only with pointers makes algorithm use less temporary memory but adds an indirection overhead.This indirection overhead can be partially hidden by use of threads.
Points of Interest
It is fun to work with uniform grid as a spatial acceleration structure, optimizing it to suit more scenarios. Currently it is not very well balanced on inserting / querying performance ratio. Since inserting is simple, it will be straightforward to add multi-threading support as a next update.
Next challenge: compute 20k AABB all-pair collisions at 60FPS for a simple physics simulation of spherical objects.
All diagrams were made inside this site: https://app.diagrams.net/
History
- Friday March 18, 2022: initial submission with barely-enough performance for performance constraint given at beginning of article. (todo: scaling tests for various scenes with different object sizes and densities)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK