

Uniform random sampling on a disc
source link: https://gieseanw.wordpress.com/2021/10/15/uniform-random-sampling-on-a-disc/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
A local pizza place has the following deals going:
- 2 medium (12 inch) pizzas, or
- 1 jumbo (18 inch) pizza
Which is the better deal?
There are entire websites dedicated to telling you which pizza deal is the better pick, and it comes down to one thing: how much pizza can you get for your value? Do we get more pizza in the first deal or the second?
Maximum Pizza
Let’s assume that the pizzas are equally tall, no matter what size they come in. Therefore, the only thing that matters is the area of pizza.
Recall the formula for the area of a circle:
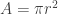
Pizzas are measured by their diameters, therefore the radius of a medium pizza is 



A jumbo pizza is 2.25 times the size of a medium pizza! The second deal is the best way to maximize your pizza.
"What does pizza have to do with uniformly sampling a disc?"
Everything. If you had to randomly drop a pepperoni onto the pizza on the left or the pizza on the right (below), shouldn’t the one on the right have a higher chance to get the pepperoni?
Attempting to randomly place a point on a disc pepperoni on a pizza
Let’s start with a jumbo pizza. Let’s call the radius of this pizza 
I know! First we’ll choose a radius 

That picture (above) isn’t quite right. It’s more accurate to say that, by choosing only a radius, we’ve merely narrowed down the possible locations of our pepperoni to the circumference of some sub-pizza with radius
To get a point on the sub-pizza’s circumference, we need to choose some angle 



And that’s it! We now have enough information to place our pepperoni (We’ve used polar coordinates to describe a point on the circle).
A catch
We certainly succeeded in choosing some place to put a pepperoni, but was our method "fair" in that every place on the pizza had an equal chance of receiving it? In fact, the answer is a resounding
"NO!"
If we chose 

We need to change how we choose our radius to account for this relationship.
In a minute I’ll provide another analogy to more intuitively explain the math, but first I have a confession to make.
A confession
In 2007, I took a course on computer graphics, and one of our assignments was to make a little game using only raw OpenGL code.
The game was simple: two players take turns drawing lines between any two adjacent points in a grid, and if your line completed one or more squares, you "owned" that square. Whoever had the most squares at the end won.
I decided to add a little flair; I rendered "fireworks" to celebrate the end of the game. The "explosion" was just a bunch of little dots randomly sampled inside a circle that grew larger, and then fell straight down, growing smaller and darker until they disappeared.
My confession is that I incorrectly sampled these points inside the circle in exactly the way I just said would accidentally bias them.
Look upon my shame!
Sampling points on a disc
Please allow me to make a little analogy to better intuitively understand the math for sampling points on a disc.
Train analogy
Imagine you have a train consisting of 5 train cars. How might you fairly select a length of train at random (0 cars, 1 car, 2 cars, …, 5 cars)?
Apologies for the patronization here; it’s fairly straightforward to choose a length at random by a uniform random sampling a number between 0 and 5 (inclusive).
Okay, but what if there is 1 person in each train car, and we want to select a length of train at random such that the percentage of people in the resulting train is also selected randomly (fairly)?
I hear you, I hear you, it’s the same thing as before since there is only one person in each car, we again randomly sample a number between 0 and 5. That is, the percentage of people is linearly correlated with the length of the train.
Let’s change it up a bit.
What if, instead of 1 person per train car, the distribution instead followed the sequence of odd numbers; the first car had 1 person, the second car 3 people, and so on (1, 3, 5, 7, 9)?
We still want to select a length of train such that the percentage of people is chosen fairly. How can we do it?
Not so easy now, is it?
Let’s step back a second and look at some concrete numbers.
- If we continued to uniformly sample train car lengths and we chose five (100% of the train cars), we’d get 100% of all the people.
- If we continued to uniformly sample train car lengths and we chose zero (0% of the train cars), we’d get 0% of all the people.
Hmm, so far it seems like it’s still linearly correlated? Why can’t we just continue to uniformly sample train car lengths?
Well, what happens when we choose a length of three (60% of the train cars)?
There are 9 people in the first three train cars, which is only 36% of all people, not 60%! The percentage of people is no longer linearly correlated with the percentage of train cars.
How many people are in each train length?
CarsPeople00112439416525Number of people on the first N train cars
In other words, the number of people in a train increases by the square of the number of cars.
Restated semi-formally, in a train of length 




For example, if we wanted to choose 16% of the passengers, we’d have the following equation (for 

Multiply both sides by
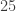

Take the square root of both sides to solve for

So to get 16% of the population on the train, we’d need to take the first two train cars.
Let’s double check our math.
From before, there are 4 people in the first two train cars. There is a total of 25 people. Therefore the percentage of people in the first two train cars is 
Randomly sampling points in a disc works the exact same way, except there are an infinite number of train cars!
The train analogy doesn’t perfectly work because we’ve discretized the problem.
We can’t select, say, 50% of people because we’d need to take 
Sampling on a disc
Like selecting a percentage of people (rather than train cars) on our train, we should select a percentage of area (rather than radius) on our disc.
Returning to our pizza analogy, if you were to randomly select a pizza size between medium (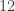
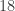
Therefore we can randomly sample a percentage (of area), which concretely means choosing a value in the continuous range ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
We do that like we did before with the train — we assign our desired percentage to the ratio of area taken up by the resulting circle.
Let 

Take the square root of both sides

Finally multiply both sides by

Since both 
It may seem counterintuitive that taking the square root of our randomly chosen percentage allowed us to bias (or rather, unbias) our sampling towards larger areas, but remember that 
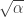


A disc’s area does not change as a function of angle chosen, so we are free to randomly sample ![[0, 2\pi]](https://s0.wp.com/latex.php?latex=%5B0%2C+2%5Cpi%5D&bg=ffffff&fg=333333&s=0&c=20201002)


Formal derivation
Now that you’ve gotten a good intuition for how to uniformly sample a disc, you’re ready for the next step where we make the math a bit more rigorous. Feel free to skip right over this section if you feel like you understand the material well enough already.
Creation of a probability distribution
Let’s reason our way into creating a probability distribution. Afterwards, we can use the distribution to draw samples from and show that the math comes out exactly as before.
"Every point on this disc is equally likely to be sampled"
If we split our disc of 

We are really making an argument about area here, aren’t we? Each half has an equal chance because it has the same area.
Let’s change how we break the halves up:

The inner circle occupies the same area as the outer annulus, even though the radii ranges they cover are vastly different.
If we were to sample randomly 1000 times, we’d expect 500 samples to end up in each differently-colored area. Let’s begin making a histogram.
If we further break up the inner circle into equal areas, leaving the outer annulus intact:

We’d expect 250 samples in each.
The first 

Let’s see what our histogram looks like if every bucket represented
The last inch of radius on our disc is expected to receive 17x as many samples as the first inch.
If we normalized the number of samples so that the first bin received exactly 1 sample, the histogram looks a little more familiar to our train from earlier:
Returning to our previous histogram (1000 samples), we begin constructing a cumulative distribution function (cdf) by modifying our buckets such that all of them begin at 0 (meaning later buckets include earlier ones).
This tells us how many samples landed in the range from ![[0, r]](https://s0.wp.com/latex.php?latex=%5B0%2C+r%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Because a cdf represents the probability a sample falls between 
Our cdf is clearly not linear. In fact it perfectly fits the equation

Recognizing that 

Rewritten more formally, the random variable ![[0, R]](https://s0.wp.com/latex.php?latex=%5B0%2C+R%5D&bg=ffffff&fg=333333&s=0&c=20201002)

Sampling from our distribution
Now that we have a cdf, we can use a technique called inverse transform sampling
to compute a function 

Where
In other words, we will transform a sample drawn from the uniform random distribution into a sample drawn from our distribution, given our cdf.
Substituting for 

Multiplying both sides by 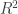

And finally taking the square root of both sides:

The math comes out exactly the same as before when we treated
"But what about the probability distribution for our angle ?"
If you follow the same process as before, you will see that
Closing thoughts
This wouldn’t be a very good blog post if I didn’t show you the difference between sampling the "wrong" way (discussed in the beginning) versus sampling the "correct" way, so here it is. The uniform random numbers used are identical between the figures, the only difference is that the "correct" way subsequently takes the square root. Notice how close to the center the samples end up being in the "wrong" way.
I didn’t think the internet had very many good resources on such a seemingly-simple topic as this. All the discussions I found were usually immediately math-heavy and not very intuitive for someone that doesn’t work with statistics every day. I purposely put the heavier math stuff in its own section near the end because I myself have trouble understanding that kind of thing. If you wanted a rigorous discussion of those things, you probably didn’t need this blog post to understand them in the first place. I hope that you are inspired by this post, and confident that if you are ever asked to code up something like this in an interview, you’d ace it. Happy coding!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK