

元学习模型MAML和Reptile详解
source link: https://weisenhui.top/posts/48339.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
记得研究生一年级的时候,每次开组会讲论文,实验室的师兄师姐经常提到元学习以及MAML这些概念。由于我当时比较懒,也觉得我研究方向不是这个,就没有细想,一知半解,只是知道有这个概念。后来我发现很多知识是相联系的,比如了解NLP的常用模型,对你理解其他领域的模型也是很有帮助的。所以深入了解元学习和MAML这些知识也是有助于我自己的科研工作的。于是我花了点时间好好学习了下元学习,并写下来这篇博客。
什么是元学习
对于一个分类任务,我们构建好深度学习模型后,学习的就是模型的参数,学习的目的就是使得最终的参数能够在训练集上达到最佳的精度,损失最小。
但是元学习(Meta-Learning)面向的是学习的过程,并不是学习的结果,也就是元学习不需要学出来最终的模型参数,学习的更像是学习技巧这种东西(这就是为什么叫做learning to learn)。他不是为了解决具体某项具体的任务,而是研究如何提升模型解决一系列任务的能力。
下面这个对比传统机器学习和元学习的例子,来自博客:Meta Learning 入门:MAML 和 Reptile,我觉得讲得很不错,值得阅读。
- 如果把训练算法类比成学生在学校的学习,那么传统的机器学习任务对应的是不同科目,例如数学、语文、英语,每个科目上训练一个模型。而 Meta Learning 则是要提升一个学生整体的学习能力,让学生学会学习(就是所谓的 learn to learn)。就像所有的学生都上一样的课,做一样的作业,可偏偏有的学生各科成绩都好,有的学生偏科,而有的学生各科成绩都差。
- 各科成绩都好的学生,说明他大脑 Meta Learning 的能力强,可以迅速适应不同科目的学习任务。
- 而对于偏科的学生,他们大脑的 Meta Learning 能力就相对弱一些,只能学习某项具体的任务,换个任务就不 work 了。对这种学生,老师的建议一般是:“在弱科上多花一点时间”,可这么做是有风险的,最糟糕的一种情况是:弱势科目没学好,强势科目成绩反而下降了。可以看到,现如今大多数深度神经网络都是“偏科生”,且不说分类、回归这样差别较大的任务对应的网络模型完全不同,即使同样是分类任务,把人脸识别网络架构用在分类 ImageNet 数据上,就未必能达到很高的准确率。
- 至于各科成绩都差的学生,说明他们不但 Meta Learning 能力弱,在任何科目上的学习能力都弱,需要被老师重点关照……
元学习的方法有很多,有些是针对不同的训练任务,输出不同的模型结构和超参数,例如AutoML,这些算法比较复杂,本文将介绍元学习中两种常用的模型:MAML和Reptile,它们不需要改变模型的结构,只改变模型的初始化参数
一、MAML
MAML:Model Agnostic Meta-Learning for Fast Adaptation of Deep Networks, ICML 2017, Paper, Code
摘要:The goal of meta-learning is to train a model on a variety of learning tasks, such that it can solve new learning tasks using only a small number of training samples. In our approach, the parameters of the model are explicitly trained such that a small number of gradient steps with a small amount of training data from a new task will produce good generalization performance on that task.
1.1 MAML的目标
MAML,全称呼叫做Model-Agnostic Meta-Learning ,意思是模型无关的元学习。所以MAML并不是一个深度学习模型(如CNN、RNN等),而更像是一种训练技巧。
模型参数初始化
(1)通常来说,我们的深度学习模型参数初始化方法是随机初始化(从高斯分布中采样),Xavier初始化,He初始化等,这样的初始化方法一般很难直接找到一个好的初始化参数。
(2)我们还可以用预训练来初始化模型的参数。用预训练初始化参数的神经网络本身就有很强的特征提取能力,能够提取很多有含义的特征,例如耳朵,鼻子,眼睛,毛发。分辨猫狗,只需要知道这些特征是如何组合的就好了,这比从头开始学习如何提取耳朵、鼻子等特征要高效得多。
利用预训练的网络进行参数初始化,相当于赋予了网络很多先验知识。类比我们人类,让一个小学没毕业的人去听高等数学,显然他是无法听懂的;而让一个高考数学满分的高中毕业生去听,他可能要学得轻松得多。如果忽略智商因素,我们人类的大脑从结构上说都是大同小异,为啥表现差别那么大呢?因为它们积累的知识量不同,后者积累的知识更多,也就是常说的“基础扎实”,换成神经网络的术语,就是后者的网络只需要 fine tune 一下就好了,而前者需要 train from scratch ,要补很多课才行。
(3)现在MAML要做的事情是学习一个“好”的初始化参数。以前我们是训练一个模型,然后让这个模型的参数θ最优,而现在我们训练MAML是希望初始化参数ϕ最优,这样就可以实现“快速学习”(使用来自新任务的少量数据就能解决学习任务,而且只需要几步梯度下降就能得到好的泛化效果)。
MAML积累的知识是元知识,也就是学习技巧,这使他比随机初始化、预训练更高级!你可以把学习一个“好”的初始化参数的过程理解成掌握一个好的学习技巧。有了这个学习技巧后,你就可以快速地解决新的任务。
MAML是与模型无关的,即该方法既可以用在CNN上,也可以用在RNN上,甚至可以用到强化学习上。但是MAML在用的时候是固定模型的,也就是说不同task ˆθn对应的模型是相同的!我们是希望通过Meta-Learning的方式学习出这个模型的一个“好”的初始化参数ϕ,有了这个初始化参数ϕ后,我们只需要少量的样本就可以快速在这个模型上进行收敛。
MAML是learning to learn,所以他的输入不再是一条条单纯的数据了,而是一个个的任务(task)。好比人们在区分物体之前,已经看过了很多不同的区分任务(task),如猫狗分类、自行车和汽车分类、苹果和橘子分类等,这些都是一个个的任务(task),你可以把他们看作训练MAML的一个个样本。
MAML的损失函数L(ϕ)=∑Nn=1ln(ˆθn),其中ln(ˆθn)是task n(经过训练后参数为ˆθn)在test data(Query Set)上的损失值
在MAML中这个F就是初始化参数ϕ,f1就是ˆθ1
1.2 元学习的data
机器学习的数据
- Train Data(一条条数据)
- Test Data(一条条数据)
元学习的数据
- Train Data(一个个任务)
- 每个任务(task)有自己的训练集(Support Set)和测试集(Query Set)
- Test Data(一个个任务)
- 每个任务(task)有自己的训练集(Support Set)和测试集(Query Set)
1.3 MAML详解
在MAML的实际应用中,每次采样一个任务(MAML的一个样本),其参数为ˆθn,从ϕ到ˆθn的训练过程只会做一个参数更新。尽管在传统的模型训练时,我们的参数会更新成千上万次。但是在MAML中我们假设这个过程参数只会被更新一次。不过我们的ϕ是会更新很多次的。
1.3.1 MAML训练阶段
Task n的参数更新过程:ϕt→ˆθn
ˆθn=ϕ−ϵ∇ϕln(ϕ), loss on support set
MAML的参数更新过程:ϕt→ϕt+1
ϕ←ϕ−η∇ϕL(ϕ) =ϕ−η∇ϕN∑n=1ln(ˆθn), loss on query set ≈ϕ−η∇ˆθnN∑n=1ln(ˆθn), loss on query set
理论上,MAML是用第二行进行参数更新的,但实际上,做MAML实验时,为了实现的方便,MAML用了第三行的一阶近似。
每次更新的过程:N个Task n的参数更新和一次MAML的参数更新
1.3.2 伪代码: MAML for Few-Shot Supervised Learning
1.3.3 MAML推理阶段
1.4 MAML数据集Omniglot
https://github.com/dragen1860/MAML-Pytorch
Omniglot是元学习中常用的数据集,在MAML的实验中也用了这个数据集
Omniglot数据集有1623个类别,每个类别有20个样本。https://github.com/brendenlake/omniglot
Omniglot的用法是这样的,从其中采样 N 个类,每个类有 K 个训练两本,组成一个训练任务(task),称为 N-ways K-shot classification。然后再从剩下的类中,继续重复上一步的采样,构建第二个 task,最终构建了 m 个 task。把这 m 个 task 分成训练 task 和测试 task,在训练 task 上训练 Meta Learning 的算法,然后再用测试 task 评估 Meta Learning 得到的算法的学习能力。
N-ways K-shot classification: In each training and test tasks, there are N classes, each has K examples.
二、模型预训练
请添加图片描述
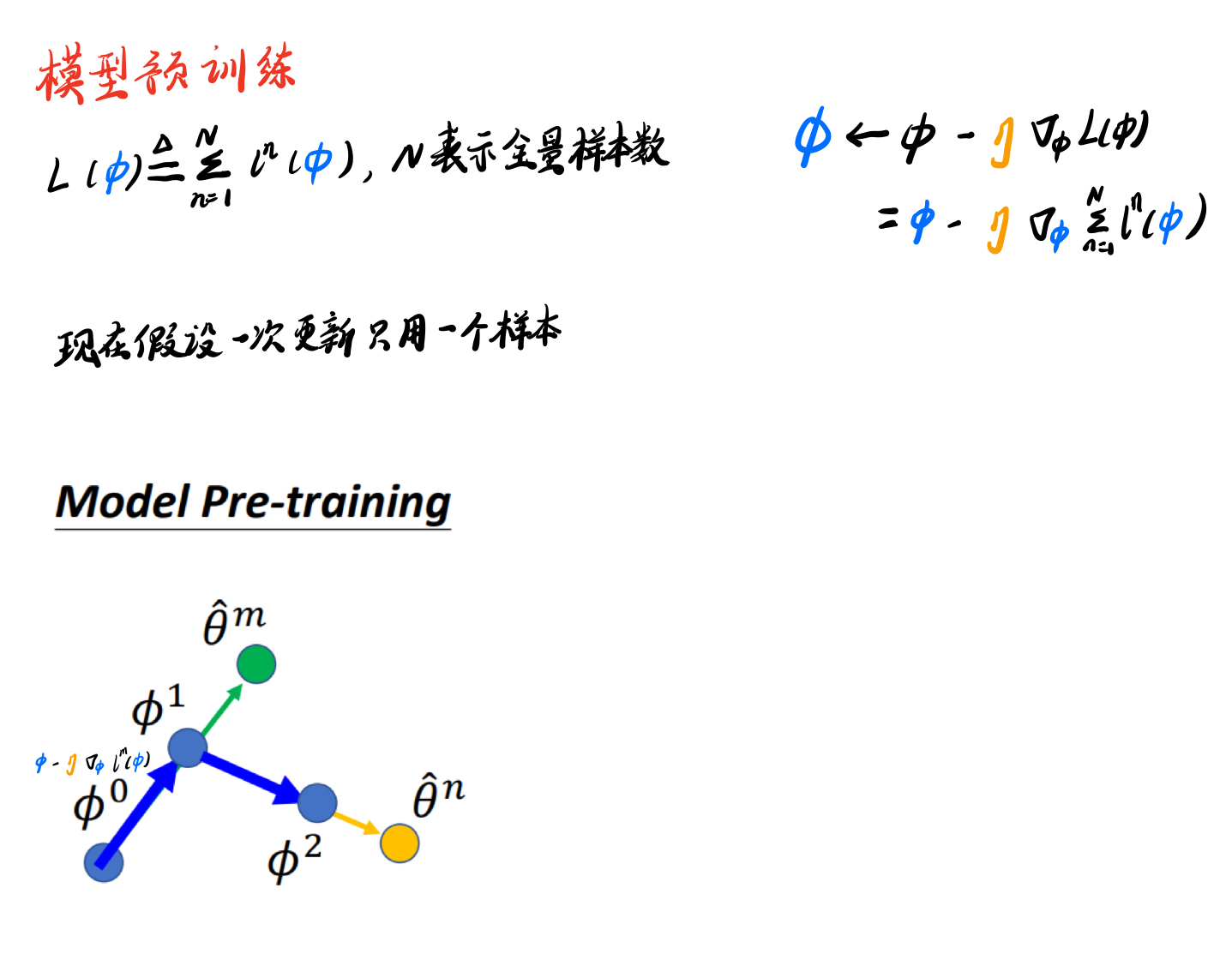
2.1 重点:MAML和Pre-Train的异同点
相同点: MAML和模型预训练都是在找一个好的初始化参数ϕ
不同点: MAML和模型预训练和评判“好的初始化参数”的标准不一样
举个例子:
- MAML:好比读博士,比较看潜力,可能现在没什么钱,但是读完博士后工资会很高
- 模型预训练:好比现在就找工作,比较看当前,我现在就想去赚钱,虽然工资上限可能没有博士高
我们始终要牢记,Meta Learning最终的目的是要让模型获得一个良好的初始化参数。这个初始化参数ϕ在训练 task 上表现或许并不出色(因为ϕ没有直接按照梯度的方向走),但以这个参数ϕ为起点,去学习新的 task 时,学得会又快又好。而模型预训练,则是着眼于解决当前的 task,不会考虑如何面对新的 task。
分析:Model Pre-training认为ϕ拿去做task1和task2的表现要很强,但是并不保证ϕ用task1的数据和task2的数据拿去做训练后,可以变得很强。
MAML不关心这些task在初始化参数上的表现,这不是重点,我们不在乎ϕ现在的表现,而是在乎ϕ经过训练后的表现。
分析:MAML认为虽然ϕ本身拿去做task1和task2的表现可能都不是很强,但是ϕ用task1的数据和task2的数据拿去做训练后,可以变得很强,那他就是一个好的初始化参数ϕ
三、Reptile
Reptile:On First-Order Meta-Learning Algorithms, arXiv, 2018, Paper
四、MAML、Pre-Train和Reptile对比图
下图来自:https://www.cnblogs.com/kailugaji/p/15156806.html
五、参考资料
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK