

一日一技:轻松排雷,爬虫让gzip炸弹变成哑炮
source link: https://www.kingname.info/2022/03/06/kill-gzip-boom/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一日一技:轻松排雷,爬虫让gzip炸弹变成哑炮
在昨天的文章《一日一技:反爬虫的极致手段,几行代码直接炸了爬虫服务器》中,我讲到了后端如何使用gzip返回极高压缩率的文件,从而瞬间卡死爬虫。
大家都知道我的公众号风格,要得罪讨好就两边一起得罪讨好。昨天我帮了后端,今天我就帮帮爬虫。作为爬虫,如何避免踩中gzip炸弹?
最直接的方法,就是把你的爬虫隐藏起来,因为gzip炸弹只能在发现了爬虫以后使用,否则就会影响到正常用户。只要你的爬虫让网站无法发现,那么自然就不会踩中炸弹。
如果你没有把握隐藏爬虫,那么,请继续往下看。
查看gzip炸弹的URL返回的Headers,你会发现如下图所示的字段:

你只需要判断resp.headers中,是否有一个名为content-encoding,值包含gzip或deflate的字段。如果没有这个字段,或者值不含gzip、deflate那么你就可以放心,它大概率不是炸弹。
值得一提的是,当你不读取resp.content、resp.text的时候,Requests是不会擅自给你解压缩的,如下图所示。因此你可以放心查看Headers。:

那么,如果你发现网站返回的内容确实是gzip压缩后的内容了怎么办呢?这个时候,我们如何做到既不解压缩,又能获取到解压以后的大小?
如果你本地检查一个.gz文件,那么你可以使用命令gzip -l xxx.gz来查看它的头信息:
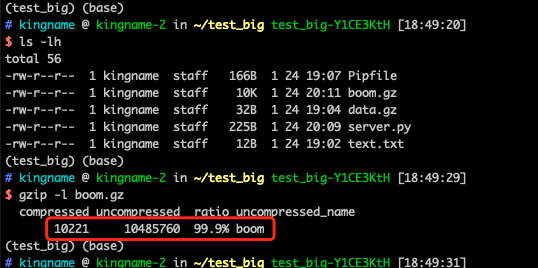
打印出来的数据中,第一个数字是压缩后的大小,第二个数字是解压以后的大小,第三个百分比是压缩率。这些信息是储存在压缩文件的头部信息中的,不用解压就能获取到。
那么当我使用Requests的时候,如何获得压缩后的二进制数据,防止它擅自解压缩?方法其实非常简单:
import requests
resp = requests.get(url, stream=True)
print(resp.raw.read())
运行效果如下图所示:
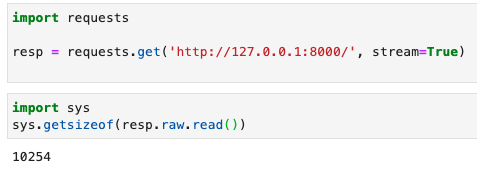
此时可以看到,这个大小是压缩后的二进制数据的大小。现在,我们可以使用如下代码,在不解压的情况下,查询到解压缩后的文件大小:
import gzip
import io
import requests
resp = requests.get(url, stream=True)
decompressed = resp.raw.read()
with gzip.open(io.BytesIO(decompressed), 'rb') as g:
g.seek(0, 2)
origin_size = g.tell()
print(origin_size)
运行效果如下图所示:
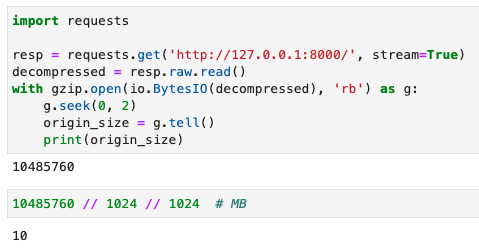
打印出来的数字转成MB就是10MB,也就是我们昨天测试的解压后的文件大小。
使用这个方法,我们就可以在不解压的情况下,知道网站返回的gzip压缩数据的实际大小。如果发现实际尺寸大得离谱,那就可以确定是gzip炸弹了,赶紧把它丢掉。

Recommend
-
72
弹窗非常容易打断正常工作:事情干得好好的,忽然一个弹窗贴着你的脸蹦出来,非得腾出手去摸鼠标,瞄准了弹窗上的按钮再点下去。文件名冲突、文件重复、删除 iCloud 文件(默认会提醒)等常见情况下,弹窗都会如期而至。 Mac 用...
-
44
Matrix 精选 Matrix 是少数派的写作社区,我们主张分享真实的产品体验,有实用价值的经验与思考。我们会不定期挑选 Matrix 最优质的文章,展示来自用户的最真实的体验和观点。 文章代表作者个人观点,少数派仅对标...
-
25
出于保护用户隐私信息的目的,Android 对各类应用能够索取到的权限不断收紧。从用户角度来说,我们无需再绞尽脑汁和过度索取权限的应用斗智斗勇,这无疑是新系统带来的一大利好。 关联阅读:
-
31
Matrix 精选 Matrix 是少数派的写作社区,我们主张分享真实的产品体验,有实用价值的经验与思考。我们会不定期挑选 Matrix 最优质的文章,展示来自用户的最真实的体验和观点。 文章代表作者个人观点,少数...
-
17
一日一技:爬虫模拟浏览器如何避免重复登录? 发表...
-
7
一日一技:拼接个URL你也能搞错,还写个屁的爬虫。 ...
-
10
一日一技:反爬虫的极致手段,几行代码直接炸了爬虫服务器 ...
-
6
一日一技:为什么网站知道我的爬虫使用了代理? 发...
-
10
随着少数派逐渐 All in 飞书,我们少数派作者们也逐渐迁移到飞书文档进行写稿。飞书文档提供了 Web 平台的富文本编辑器,配合「少数派助手」这个服务,可以将稿件一键发布到少数派平台,着实是非常方便。不少的少数派作者都有自己的博客平台,而大部分的博客...
-
8
一日一技:爬虫如何解析JavaScript Object? 2023-10-28 106 342 1 分钟 我们在开发爬虫的过程中,经常发现有一些网站,会直接把数据放到HTML中的<script...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK