

文本数据可视化(下)——一图胜千言
source link: https://geekplux.com/posts/text-data-visualization
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
文本数据可视化(下)——一图胜千言
本文首发于:GraphiCon 知乎专栏-文本数据可视化(下)——一图胜千言。原文地址:https://geekplux.com/2017/06/26/text-data-visualization
文字是传递信息最常用的载体。在当前这个信息爆炸的时代,人们接收信息的速度已经小于信息产生的速度,尤其是文本信息。当大段大段的文字摆在面前,已经很少有耐心去认真把它读完,经常是先找文中的图片来看。这一方面说明人们对图形的接受程度比枯燥的文字要高很多,另一方面说明人们急需一种更高效的信息接收方式,文本可视化正是解药良方。「一图胜千言」我们从小就有体会,教材里的解释图、自己笔记里总结的知识结构图,一直到现在经常用的思维导图等,其实都是简单、实用的文本可视化。本文将简单介绍文本可视化的基础概念,然后重点通过各类文本可视化的案例来阐述可视化之美(多图,不过为了学到知识这点流量不算什么)。
为什么要文本数据可视化#
虽然一般这种讲必要性的段落很多人都略过不看,虽然文本可视化的必要性大家用脚趾头估计都能想到,但我还是稍微说一说吧。文本可视化的作用有以下四点:
- 理解 - 理解主旨
- 组织 - 组织、分类信息
- 比较 - 对比文档信息
- 关联 - 关联文本的 pattern 和其他信息
简单来说就是让你更加直观迅速的获取、分析信息(所有可视化的作用都是这个)。举个例子,针对一篇文章,文本可视化能更快的告诉我们文章在讲什么;针对社交网络上的发言,文本可视化可以帮我们信息归类,情感分析;针对一个大新闻,文本可视化可以帮我们捋顺事情发展的脉络、每个人物的关系等等;针对一系列的文档,我们可以通过文本可视化来找到它们之间的联系等等。
一般来说,情报分析人员、网络内容分析人员、情感分析或文学研究者等相关职业更需要文本可视化。不过随着信息图(例如图 1)等的普及,越来越多的人已经接受并善用文本可视化了。
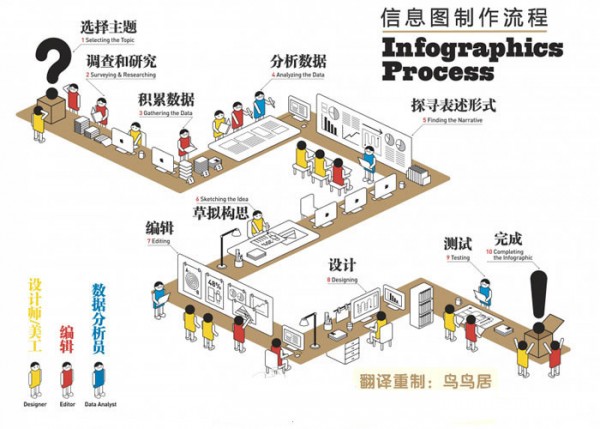
文本数据可视化的流程#
如图 2 所示,其实任何可视化的流程[1]都类似。
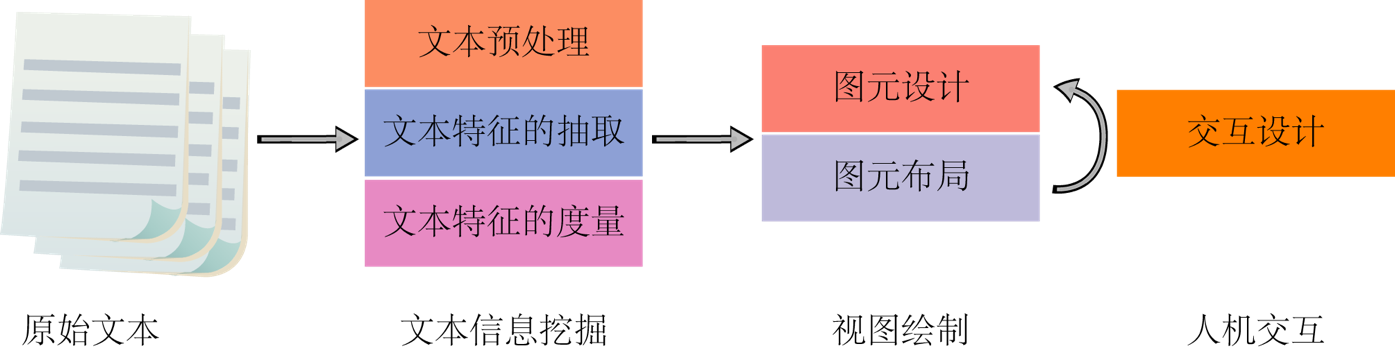
一般把对文本的理解需求分成三级:词汇级(Lexical Level)、语法级(Syntactic Level)和语义级(Semantic Level)。不同级的信息挖掘方法也不同,词汇级当然是用各类分词算法,语法级用一些句法分析算法,语义级用主题抽取算法[2]。以上这些都在第二步文本信息挖掘中进行,其中文本数据预处理是将无效数据过滤,提取有效词等;文本特征抽取是指提取文本的关键词、词频分布、语法级的实体信息、语义级的主题等;文本特征的度量是指在多种环境或多个数据源所抽取的文本特征进行深层分析,如相似性、文本聚类等。这里就简单笼统地说一下文本分析的基础方法,有兴趣的同学可以自行搜索学习,我们把重点放在可视化设计上。
![Wordcount[3] 统计了通常用的86800个单词](https://ooo.0o0.ooo/2017/06/04/5933efa249cfe.png)
文本可视化类型#
文本数据大致可分为三种:单文本、文档集合和时序文本数据。对应的文本可视化也可分为三类:
- 文本内容的可视化
- 文本关系的可视化
- 文本多层面信息的可视化
以下我们通过案例来一一介绍。
文本内容可视化#
上篇文章所说的标签云和 Wordle [4]是目前研究领域和 Web 上最受欢迎的文本内容可视化方法了,它们都是基于关键词的文本内容可视化。
基于关键词的文本内容可视化#
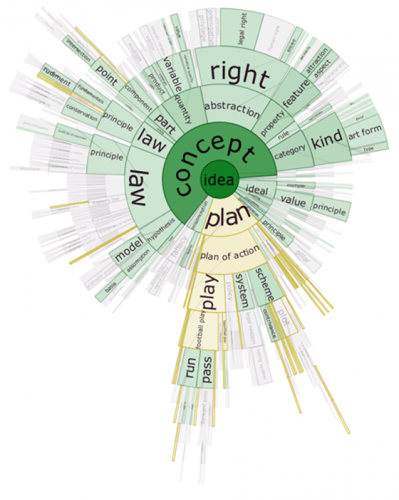
DocuBurst#
文档散(DocuBurst [5])也是基于关键词的文本可视化,不过它还通过径向布局体现了词的语义等级。如下图所示,外层的词是内层词的下义祠,颜色饱和度的深浅用来体现词频的高低。
Document Cards#
文档卡片(Document Cards)[6]则是结合了文档中的关键词和关键图片进行可视化,布局在一张小卡片中。其中的关键图片是指采用智能算法抽取并根据颜色分类后的代表性图片。

时序文本内容可视化#
时序数据是指具有时间或顺序特性的文本,例如一篇小说故事情节的变化,或一个新闻事件随时间的演化。
SparkClouds#
SparkClouds[7]是在标签云的基础上,在每个词下面增加了一条折线图,用以显示该词的词频随时间的演变。

ThemeRiver#
主题河流(ThemeRiver)[8]是一种经典的时序文本可视化方法。光阴似水,用河流来隐喻时间的变化几乎所有人都能非常好地理解。
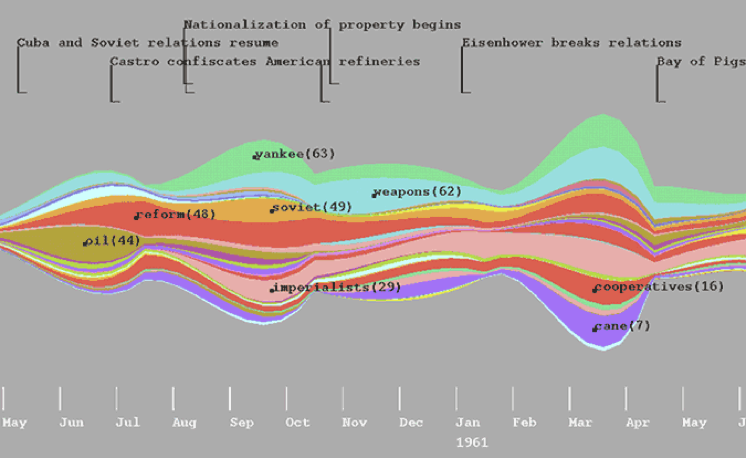
横轴表示时间,每一条不同颜色线条可视作一条河流,而每条河流则表示一个主题,河流的宽度代表其在当前时间点上的一个度量(如主题的强度)。这样既可以在宏观上看出多个主题的发展变化,又能看出在特定时间点上主题的分布。
TIARA#
TIARA[9]结合了标签云,通过主题分析技术(latent dirichlet allocation,LDA),将文本关键词根据时间点放置在每条色带上,并用词的大小来表示关键词在该时刻出现的频率。因此用TIARA就可以帮助用户快速分析文本具体内容随时间变化的规律,而不是仅仅一个度量带变化。
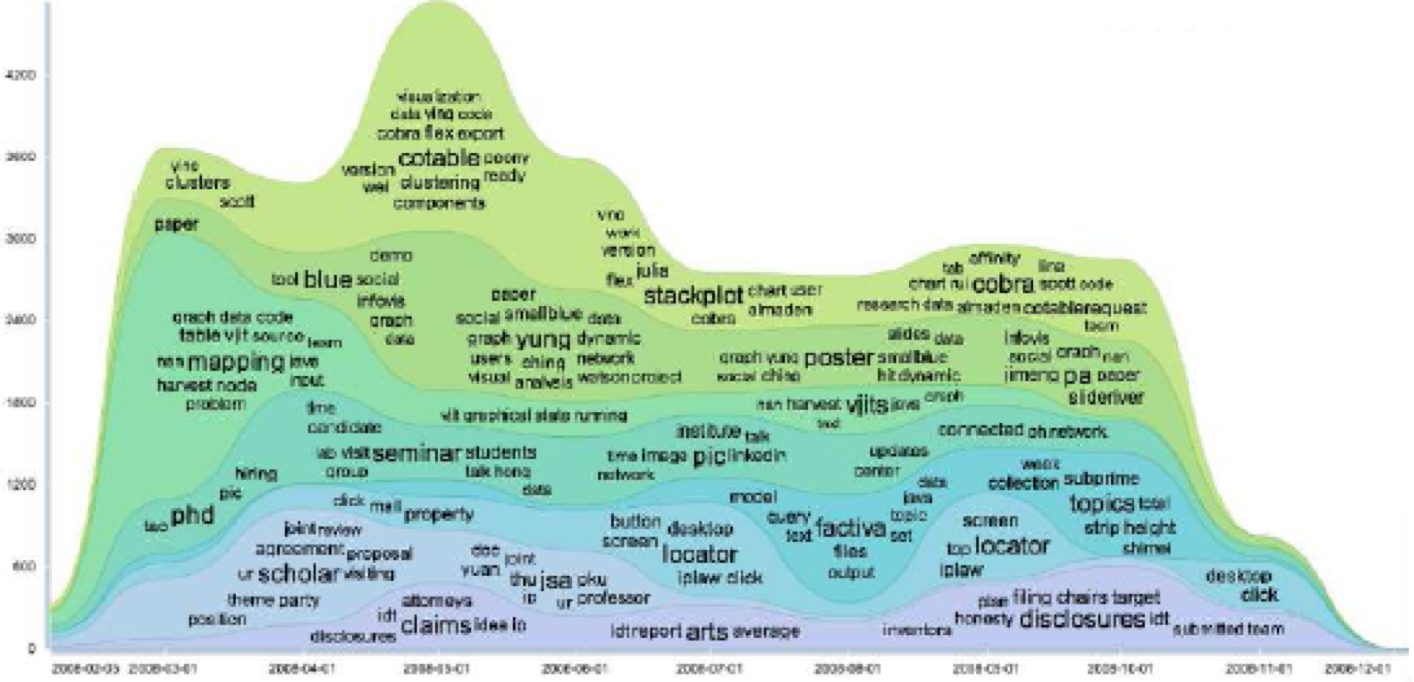
TextFlow#
TextFlow [10]也算是 ThemeRiver 的一种拓展,它不仅表达了主题的变化,还表达了各个主题随着时间的分裂与合并。如某个主题在某个时间分成了两个主题,或多个主题在某个时间合并成了一个主题。

HistoryFlow#
HistoryFlow [11]则主要研究文档内容随时间的变化。下图以维基百科一篇词条的更新为例,纵轴表示文章的版本更新时间点,每一种颜色代表一个作者,在同一个时间轴上色块代表相应的作者所贡献的文字块,并且色块的位置代表该文字块在文章中的顺序。所以纵览全图就可以轻易看出文章的修改。
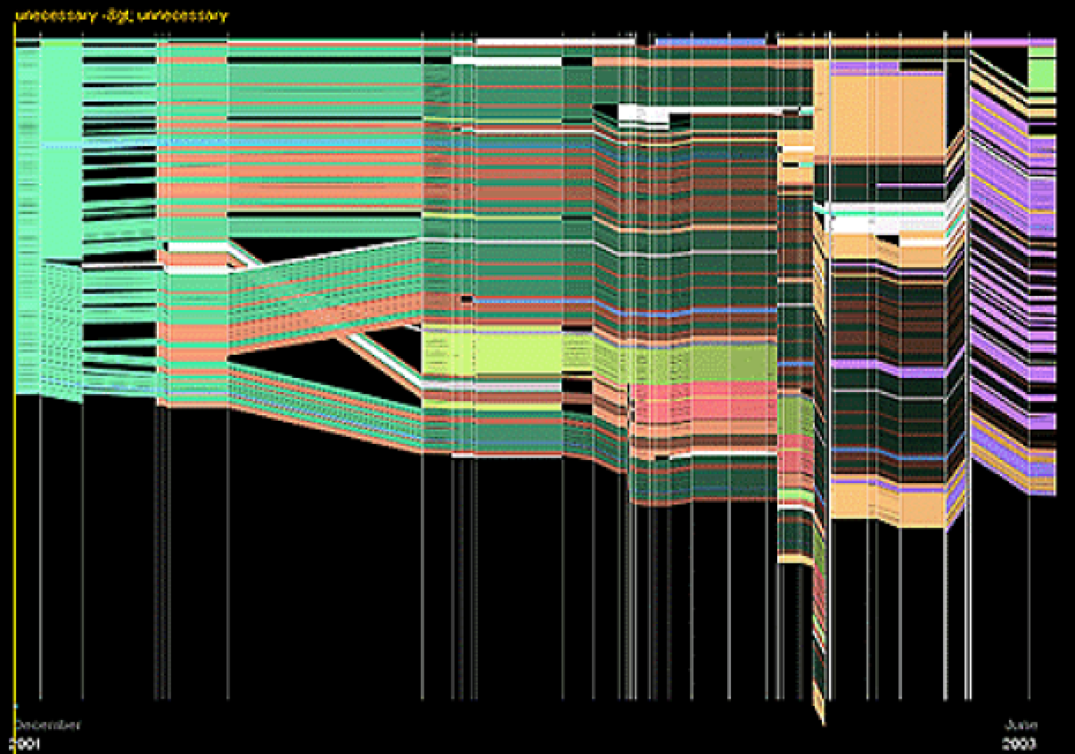
StoryFlow#
我们看电影或小说经常说到时间线、剧情线等,都能用 StoryFlow [12]来表示,它通过层次渲染的方式,生成一个 StoryLine 布局。每条线是一条人物线,当两人在剧情中有某种联系(同时出场或其他交集)时会在图中相交,横轴表示时间。
StoryFlow 还允许用户实时交互,包括捆绑操作、删除、移动以及直线化等等。视频演示非常精彩,需科学上网:https://www.youtube.com/watch?v=yoq82mC30Iw
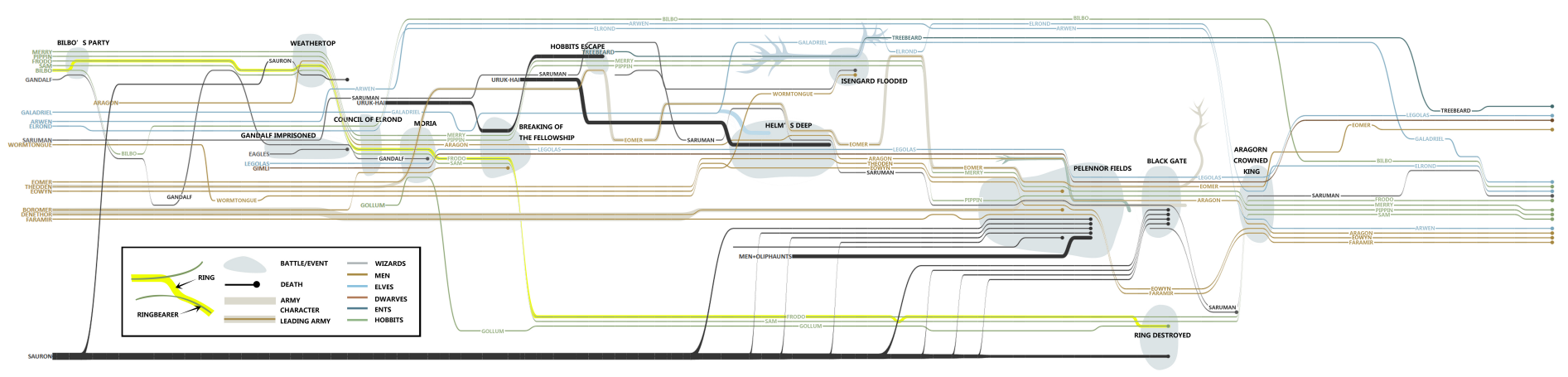
文本特征分布模式可视化#
可视化也能很好的表现文本特征。
TextArc#
TextArc [13]用来可视化一个文档中的词频和词的分布情况。整个文档用一条螺线表示,文档的句子按文字的组织顺序布局在螺线上,螺线包围着的是文档中出现的单词,每个单词的位置由其在文本中的频率和出现位置决定,饱和度用来映射词频。所以全局出现频率越高的词越靠近中心,而局部出现频率越高的词越靠近其相应的螺线区域。选中某个单词后,自动用射线关联到它在文中出现的位置。

Literature Fingerprinting#
文献指纹(Literature Fingerprinting)[14]是体现全文特征分布的一项工作。一个像素块代表一段文本,一组像素块代表一本书。颜色映射的是文本特征,下图中是句子的平均长度。从图中明显看出两人的写作风格迥异。
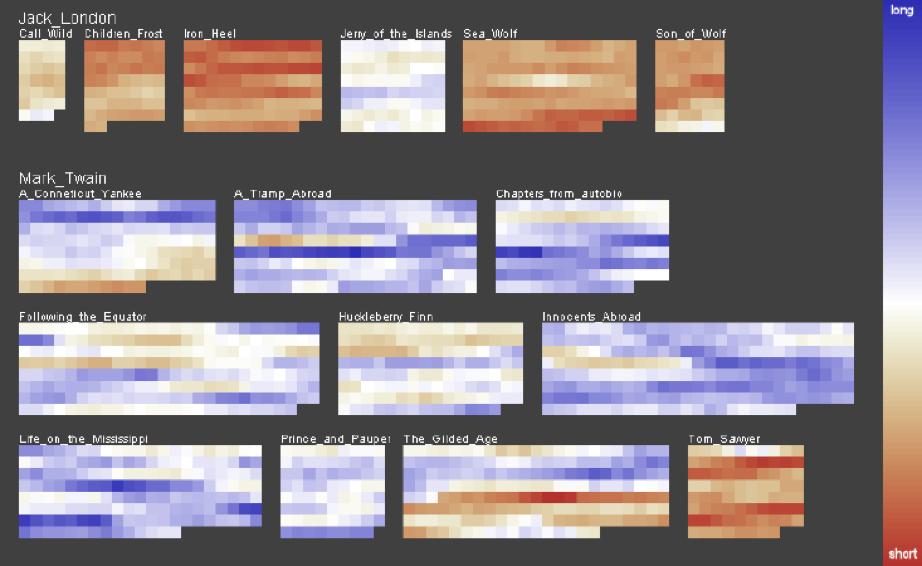
情感分析可视化#
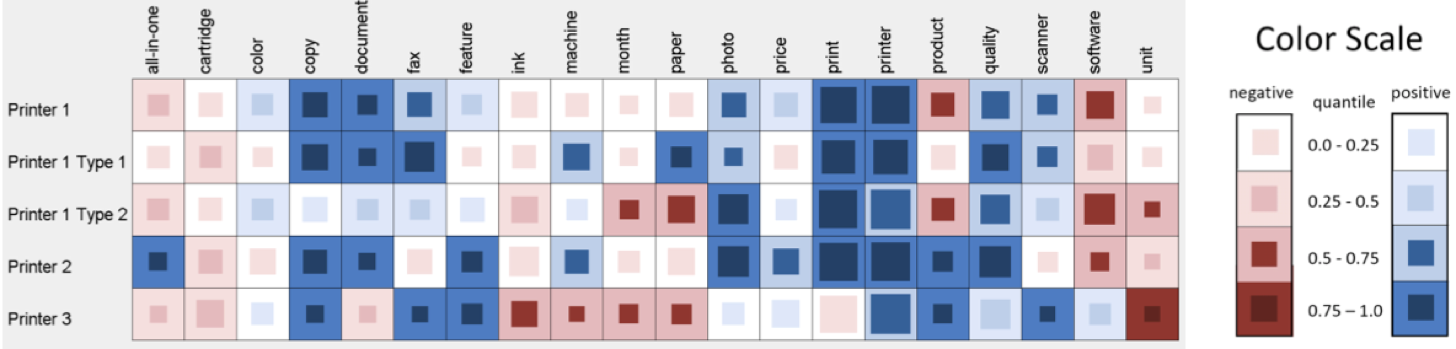
情感分析是指从文本中挖掘出心情、喜好、感觉等主观信息。现在人们把各类社交网络当作感情、观点的出口,所以分析这类文本就能掌握人们对于一个事件的观点或情感的发展。下图是基于矩阵视图的客户反馈信息的可视化工作[15],其中的行是指文本(用户观点)的载体,列是用户的评价,颜色表达的是用户评价的倾向程度,红色代表消极,蓝色代表积极,每个方格内的小格子代表用户评价的人数,评价人数越多小格子越大。
文本关系可视化#
顾名思义,文本关系可视化研究的是文本或文档集合中的关系信息,比如文本的相似性、互相引用的情况、链接等。说到关系布局,一般都是树或图。
文本内容关系可视化#
Word Tree#
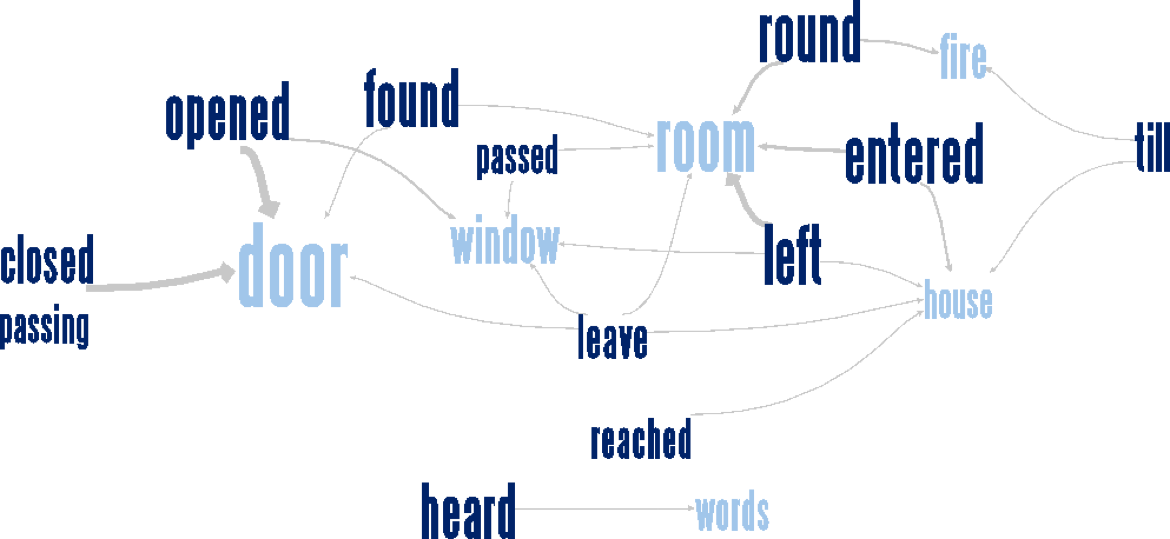
单词树(Word Tree)[16]很好理解,把文本中的句子按树形结构布局,可以很好的看出一个单词在文本中出现的频率和单词前后的联系。

Phrase Nets#
短语网络(Phrase Nets)[17]是经典的力导向图结构,图中的节点是从文本中挖掘出的词汇级或语法级的语义单元,边代表语义单元的联系,边的方向即短语的方向,边的宽度是短语在文本中出现的频率。
NewsMap#
TreeMap 也是一种经典的可视化关系布局。NewsMap 就是基于 TreeMap 展示新闻,颜色用于区分新闻类型。

文档集合关系可视化#
文档数量到一定量的时候,再针对文本做可视化就不现实了,所以通常是对单个文档定义一个特征向量,利用向量空间模型计算文档间的相似性,并采用相应的投影技术呈现文档集合的关系。
Galaxy View#
星系图(Galaxy View)[18]把一篇文档比作一颗星星,通过投影的方法把所有文档按照其主题的相似性投影为二维平面的点集,星星离的越近则代表文档越相似,因此一个星团可以非常直观地看出文档主题的紧凑和离散。

ThemeScape#
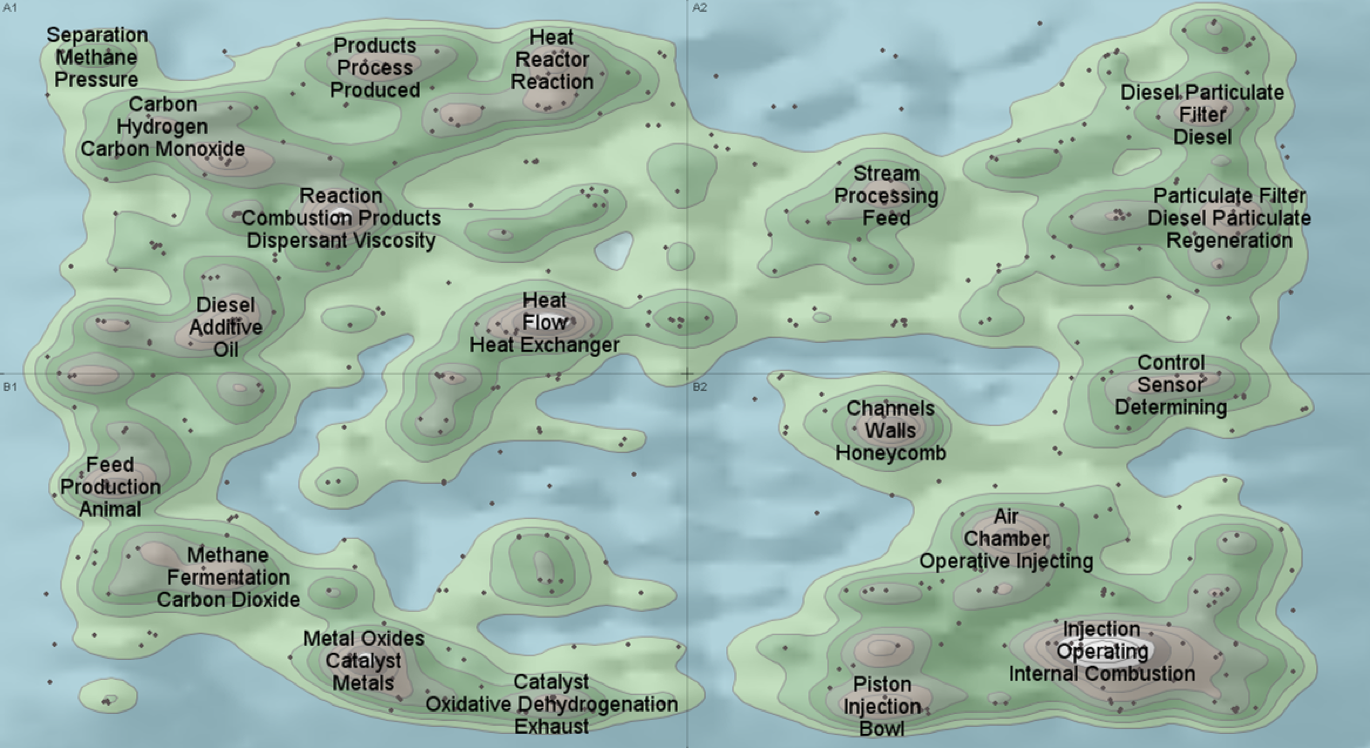
主题地貌(ThemeScape)[18]是对星系图的改进。地图中的等高线我相信大家都理解,把等高线加入投影的二维平面中,文档相似性相同的放在一个等高线内,再用颜色来编码文本分布的密集程度,把二维平面背景变成一幅地图,这样就把刚才星系图中的星团变成了一座座山丘。文档越相似,则分布约密集,这座山峰就越高,是不是一目了然?
Jigsaw#
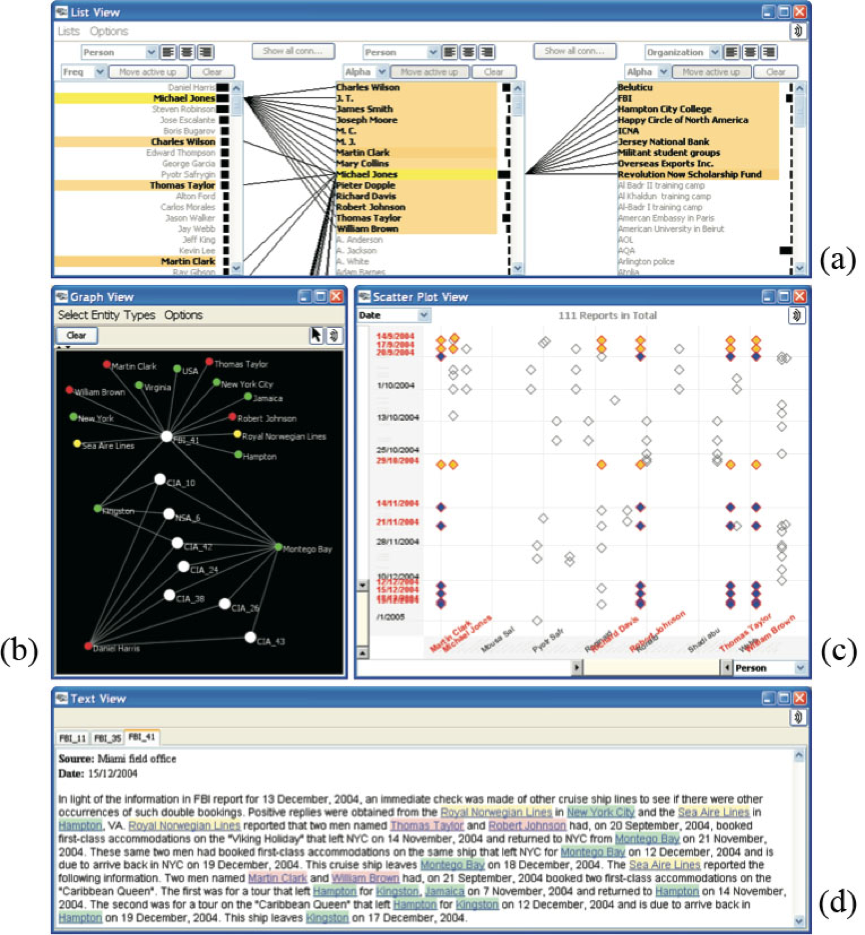
Jigsaw [19]通过提供多种视图让用户交互分析文档间的关系。最下面是文档视图,里面是单个文档的内容,最上面列表图中每一行是文档中的一个实体,连线代表实体间的关系。中间部分,左面是一副节点-链接图,白色节点表示一篇文档,其他节点是文档中的实体,链接同样代表联系;右面的散点图中,一个菱形代表两个实体的联系。
文本多层面信息可视化#
多层面或多维度是指从多个角度或提取多种特征对文本集合分析。
FaceAtlas#
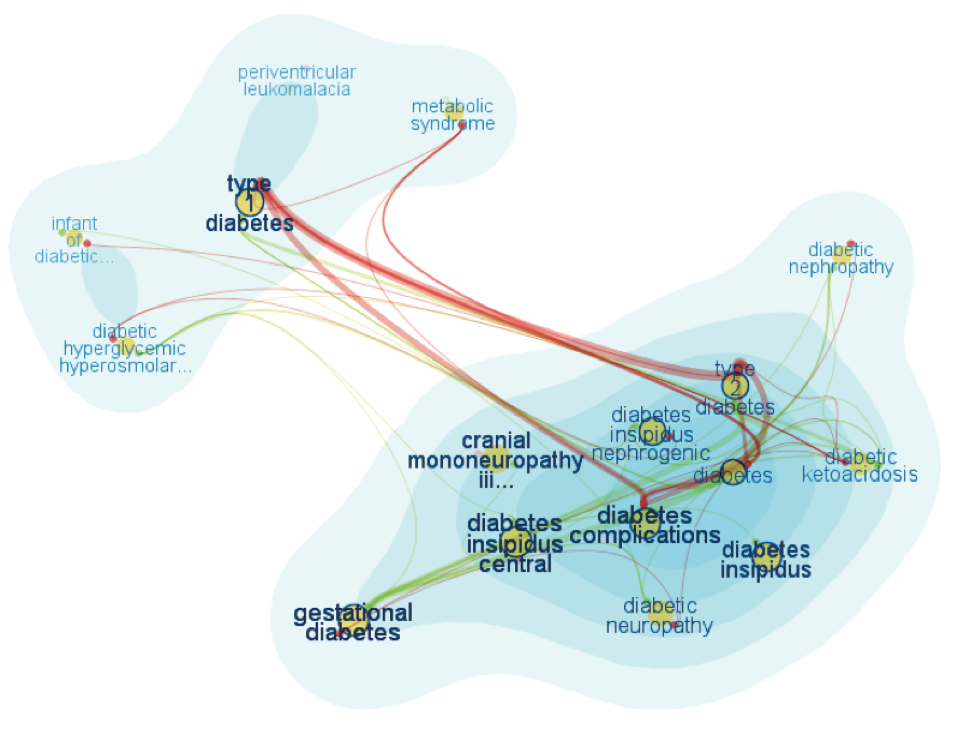
FaceAtlas [20]结合了气泡集和节点-链接图两种视图,用于表达文本各层面信息内部和外部的关联。每个节点表示一个实体,用 KDE 方法刻画出气泡图的轮廓,然后用线将同一层面的实体链接起来,一种颜色代表一种实体。下图是基于医疗健康文档,展示了病名、病因、症状、诊断方案等多层面的信息,两团分别代表糖尿病1号和2号,连线是指他俩之间的并发症。
Parallel Tag Clouds#
平行标签云(Parallel Tag Clouds)[21]结合了平行坐标(该视图在多维数据可视化中经常使用)和标签云视图。每一列是一个层面的标签云,然后连接的折线展现了选中标签在多个层面的分布。

总结#
今天带大家看了这么多图,相信大家一定眼花缭乱了。要理解文本数据可视化,就要先了解文本数据的特点,如何从文本中挖掘出你想要的信息,如何设计数据结构,最后再如何映射出实用又美观的视图都是你需要思考的问题。目前文本可视分析已经开始运用在各行各业,直观的交互将人类的智慧引入到数据分析的过程中,帮助我们从浩瀚的文字中跳脱出来,避免一叶障目。希望我的文章能给大家带来一些微小的帮助。
参考文献#
- [1] 数据可视化基础——可视化流程
- [2] 陈为 沈则潜 陶煜波. 数据可视化[M]. 电子工业出版社, 2013.
- [3] WordCount
- [4] 文本数据可视化(上)——从 Wordle 谈起
- [5] Collins C, Carpendale S, Penn G. Docuburst: Visualizing document content using language structure[C]//Computer graphics forum. Blackwell Publishing Ltd, 2009, 28(3): 1039-1046.
- [6] Strobelt H, Oelke D, Rohrdantz C, et al. Document cards: A top trumps visualization for documents[J]. IEEE Transactions on Visualization and Computer Graphics, 2009, 15(6): 1145-1152.
- [7] Lee B, Riche N H, Karlson A K, et al. Sparkclouds: Visualizing trends in tag clouds[J]. IEEE transactions on visualization and computer graphics, 2010, 16(6): 1182-1189.
- [8] Havre S, Hetzler E, Whitney P, et al. Themeriver: Visualizing thematic changes in large document collections[J]. IEEE transactions on visualization and computer graphics, 2002, 8(1): 9-20.
- [9] Wei F, Liu S, Song Y, et al. Tiara: a visual exploratory text analytic system[C]//Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2010: 153-162.
- [10] Cui W, Liu S, Tan L, et al. Textflow: Towards better understanding of evolving topics in text[J]. IEEE transactions on visualization and computer graphics, 2011, 17(12): 2412-2421.
- [11] Wattenberg M, Viégas F B. Historyflow: visualizing dynamic, evolving documents and the interactions of multiple collaborating authors, A preliminary report[J]. IBM Research, Collaborative User Experience research group, 2003.
- [12] Liu S, Wu Y, Wei E, et al. Storyflow: Tracking the evolution of stories[J]. IEEE Transactions on Visualization and Computer Graphics, 2013, 19(12): 2436-2445.
- [13] Paley W B. TextArc: Showing word frequency and distribution in text[C]//Poster presented at IEEE Symposium on Information Visualization. 2002, 2002.
- [14] Keim D A, Oelke D. Literature fingerprinting: A new method for visual literary analysis[C]//Visual Analytics Science and Technology, 2007. VAST 2007. IEEE Symposium on. IEEE, 2007: 115-122.
- [15] Oelke D, Hao M, Rohrdantz C, et al. Visual opinion analysis of customer feedback data[C]//Visual Analytics Science and Technology, 2009. VAST 2009. IEEE Symposium on. IEEE, 2009: 187-194.
- [16] Wattenberg M, Viégas F B. The word tree, an interactive visual concordance[J]. IEEE transactions on visualization and computer graphics, 2008, 14(6).
- [17] Van Ham F, Wattenberg M, Viégas F B. Mapping text with phrase nets[J]. IEEE transactions on visualization and computer graphics, 2009, 15(6).
- [18] Wise J A. The ecological approach to text visualization[J]. Journal of the Association for Information Science and Technology, 1999, 50(13): 1224.
- [19] Stasko J, Görg C, Liu Z. Jigsaw: supporting investigative analysis through interactive visualization[J]. Information visualization, 2008, 7(2): 118-132.
- [20] Cao N, Sun J, Lin Y R, et al. Facetatlas: Multifaceted visualization for rich text corpora[J]. IEEE transactions on visualization and computer graphics, 2010, 16(6): 1172-1181.
- [21] Collins C, Viegas F B, Wattenberg M. Parallel tag clouds to explore and analyze faceted text corpora[C]//Visual Analytics Science and Technology, 2009. VAST 2009. IEEE Symposium on. IEEE, 2009: 91-98.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK