

Harmful Misconceptions in Software Testing
source link: https://dzone.com/articles/harmful-misconceptions-in-software-testing
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

In 1870, the German chemist Erich von Wolf was investigating the amount of iron in spinach. When writing down his findings in his notebook, he misplaced a decimal point, changing the iron content in spinach ten times more than in reality. While Mr. von Wolf found out that there are just 3.5 milligrams of iron in a 100g serving of spinach, the published number became 35 milligrams thanks to his mistake. This caused the well-known misconception that iron is exceptionally high in spinach, which makes the body stronger.
Though Mr. von Wolf's error was detected and fixed 67 years later when someone re-checked his results, spinach is still popularly thought to be one of the most iron-rich vegetables, probably due to the popular cartoon character Popeye.
There are many common misconceptions in software testing as well. In this article, I reveal them as they are harmful.
Misconception I – Testing Cost and Software Quality Is a Trade-off
Many books, blog posts, etc. state that either you spend lots of money and time for testing to reach high quality or you save money but your software quality remains poor. It’s not true. The reality is that there are two significant cost elements in the software development lifecycle (SDLC) that the teams can modify: testing and bug fixing. Neither of them is linear. The cost of testing increases when we want to find more bugs. In the very beginning, the increase is more or less linear, i.e., executing twice as many test cases the number of detected bugs will be doubled. However, it shortly becomes over-linear. The reason is that after a certain level we need to combine (and test) the elements of the input domain by combinatorial methods.
The other factor is the cost of bug fixing. The later we find a bug in the software lifecycle, the more costly its correction. According to some publications, the correction cost is “exponential in time” but clearly over linear, most likely showing polynomial growth. Therefore, if we can find faults early enough in the lifecycle, then the total correcting costs can drastically be reduced. You can see in the figure below that considering these two factors together, the total cost has an optimum value.
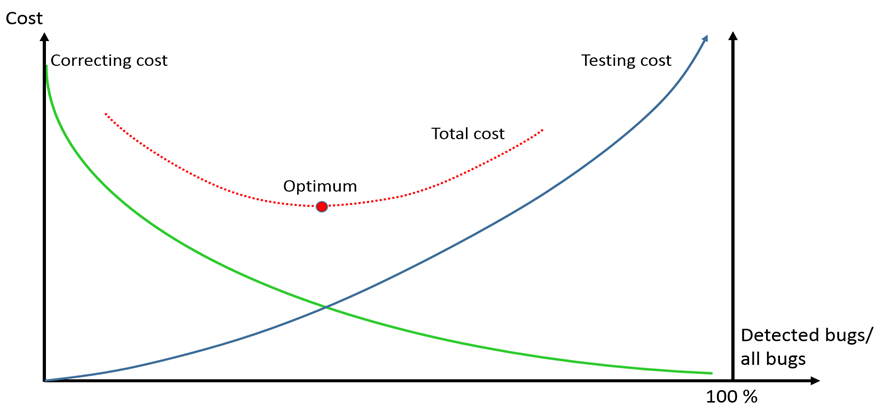
That’s why this misconception is very dangerous. Thus, if your boss wants to reduce costs by reducing the testing effort, the total SDLC cost will increase, in addition, your customers get low-quality software. Always say no and explain why it’s a wrong solution. Exceeding the optimum by too much testing effort is also a bad solution, but this is very rare in practice.
The only good solution is that your team should try to reach the optimum.
You can have several questions such as
- How to reach this optimum?
- Does reaching the optimum result in acceptable quality?
- Does risk analysis help us get this optimum?
For the first question, the answer is to make risk and complexity analyses and collect historical data for each project. The answer for 2. is yes. And risk analysis is a must to reach the optimum. If you want to learn more, read Chapter 2 from this book.
Misconception II – Two-point or Three-point Boundary Testing
Every software tester believes that a single boundary should be tested by two or three points. This misconception is similar to the one of iron in spinach but much more dangerous. There is an old software testing book where this unreliable solution originated from. There is no explanation when two use the two-point and when the three-point version.
Unfortunately, neither solution is reliable, i.e., boundary bugs remain undetected. The reliable testing of a single boundary requires four test cases, i.e., four data points concerning the boundary. These four points are one ON, one OFF, one IN and one OUT point.
- A data point on the closed boundary is called an ON point; for an open boundary, an ON point is a test input “closest” to the boundary inside the examined domain.
- A data point inside the examined domain that differs from the ON point and the neighbour of the ON point is called an IN point.
- A data point outside a closed boundary and “closest” to the ON point is called an OFF point; for an open boundary, an OFF point is on the boundary.
- A data point outside the boundary of the examined domain and not being an OFF point is called an OUT point.
It’s not difficult to justify this assertion. The only thing is needed to create 8 incorrect program versions called mutants. For example, if the related code for a boundary is x >= 43 (x is an integer), then the incorrect versions are:
- x > 43
- x <= 43
- x < 43
- x <> 43
- x <> 43 – Ɛ
- x >= 43 + δ
- x >= 43 – δ
where Ɛ is the accuracy (suppose, it is 1), δ is any greater than one multiple of the accuracy. Here the ON point is 43, the OFF point is 42, the OUT point can be 20 and the in point can be 50, for instance. For the ON and the IN point, the condition is true, for OUT and OFF it’s false.
- To detect the incorrect version #1 you need to test with the ON point (43)
- To detect the incorrect version #4 you need to test with the IN point (50)
- To detect the incorrect version #6 you need to test with the OUT point (20)
- To detect the incorrect version #8 you need to test with the OFF point (42)
Thus you need four test cases otherwise the bug remains in the code waiting for the users to become angry.
This is the simplest case. In practice, you have more compound predicates. There is a new test design technique called general predicate testing (GPT) that is reliable and finds all the boundary bugs. There is an algorithm that gives you a close-to-minimum number of reliable tests. You can freely use it, visit this website. If you want to learn more about GPT, read this article.
Misconception III – Test Automation Automates Testing
If you read about test automation at different websites you will find quite similar definitions such as ‘a method to automate the testing process.’ These sites list the most widely used ‘test automation tools’ such as Selenium, Appium, Cypress, etc. However, these are not test automation tools just test execution automation tools. The testing process consists of five phases, where the two most time-consuming phases are (1) test design, (2) test implementation and execution. These two parts can be automated, therefore efficient test automation consists of both test design and test execution automation. Unfortunately, quite a few tools involve efficient test design automation. Thus, the test design phase remains ad-hoc and lots of bugs remain undetected increasing the maintenance costs (see the first misconception in our blog series).
Lots of testers believe that only test execution can be automated. Therefore, test design and test implementation are manual work. But it is not true. Both can be automated even if some parts remain manual. The tools doing test design and automate test implementation are called model-based testing tools. Of course, you should make the model, and the test code will be implemented based on them. There are lots of modelling types, but what they have in common is that models are more compact than writing all the test cases one by one.
Model-based testing is very useful if you want not only automated test execution but find most of the bugs. Lets’s try to solve some exercises on stateful applications manually you will fail (as I failed as well). Without using automation it’s very difficult to make a reliable test set that finds all the bugs (seeded into the correct program). However, if you know the required techniques and make models by applying Harmony Exercise you can do it.
Another misconception considering test automation is that codeless test automation is helpful in the short term but doesn't contain any added value in long term. This view is completely wrong. It’s important to know that models may contain some code, but usually codeless or low code solutions. Making coded test cases, one of the main problems is breaking the "Don't repeat yourself" (DRY) principle, i.e., some test code is written several times. On the contrary, by applying codeless modelling techniques, the DRY principle is fulfilled, and maintenance becomes much cheaper.
To summarise, there are lots of misconceptions related to test automation. These are very dangerous as testers may select the wrong automation methods and tools by which software testing becomes poor and expensive.
Misconception IV – Testers Know How Good They Are
Both developers and testers need technical skills. Developers should write good code, while testers should produce reliable tests. However, developers can exercise coding on many different online platforms. There are exercises at various levels, and the courses involve hints and help when needed. On the other hand, when the code is ready, it is validated by the testers giving feedback to the developers.
The same doesn’t hold for testing. In some sense, testing is more difficult than coding, as validating the efficiency of the test cases (i.e., the bug revealing capability of the tests) is much harder than validating code correctness. In practice, the tests are just executed comparing the result with the expected outcome.
By designing and executing the test cases the result is that some tests have passed, and some others have failed. Testers do not know much about how many bugs remain in the code and do not know much about their bug-revealing efficiency (the defect detection percentage (DDP) gives only an overall measure of the testing effectiveness).
Yet, well-known test professionals believe that testers reliably know about their effectiveness as there are plenty of measures for the testing effort. For example, the mentioned DDP measures how many defects were missed in testing, i.e., found by users after the application is released. If you detect 75 bugs during testing and 25 were found afterwards, then you know that you are finding 75% of them and your effectiveness is 75%.
Unfortunately, this is only a nice theory. If you work in a large company, then an application is tested by many testers and you will only know the effectiveness of the whole team, not of the individuals. If you work for a small company, and you are the only tester of an application, then DDP will not be measured with high probability. Please write to us if we are wrong.
To the best of our knowledge, there are no online courses available where after entering the test cases the test course platform tells which tests are missing (if any) and why. Thus, testers cannot measure their technical abilities. The consequence is that testers have only a vague assumption about their test design efficiency. That was the reason for establishing a test design website, where you can check your technical knowledge and you can learn how to improve it.
Fortunately, the efficiency of the tests can be measured. Let us assume that you want to know how efficient your test cases are. You can insert 100 artificial, but yet realistic bugs into your application. If the test cases find 80 bugs, then you can think that the test case efficiency is about 80%. Unfortunately, the bugs influence each other, i.e., a bug can suppress some others. Therefore, you should make 100 alternative applications with a single-seeded bug in each, then execute them. Now, if you find 80 artificial bugs, your efficiency is close to 80% (if the bugs were realistic). This is the way how mutation testing works.
The basic concept of mutation testing is to design test cases that would distinguish the program under test from the alternative programs that contain artificial faults. We carefully created the mutants so that only very good tests are able to differentiate all of them from the original. Therefore, by solving all the exercises you become a much better tester and you will know how good a tester you are.
Misconception V – Testing Only Shows the Presence of Defects
The mentioned principle means that software testing tells nothing about the absence of defects, testing only reduces the chance of occurring undetected bugs in the software. If no defects are found, it doesn’t mean that the software is correct, it just shows the ineffectiveness of the current testing method. The principle is generally true. However, considering our actual test design knowledge, in some circumstances we can state a better assertion.
In mathematics, we prove theorems often with constraints. Similar is the case in software testing. There are some types of faults for which we can prove that by applying a certain test design technique correctly, all defects can be revealed. This assertion weakens the original negative principle and test experts need to develop new test design techniques that detect all the faults in a fault class.
An example is the general predicate testing (GPT) technique. Assume we want to test the correctness of some business logic. Suppose that we have the following set of conditions
IF cond11 AND cond12 AND … AND cond1n THEN …
IF cond21 AND cond22 AND … AND cond2n THEN …
….
IF condm1 AND condm2 AND … AND condmn THEN …
where condij is an atomic logical condition. Recall that a logical condition can be true or false, and may have the form ‘variable operator value’ (like x < 42), etc. The operators can be <, ≤, >, ≥, = and ≠. In that case, by GPT, all logical faults can be revealed. What is more, either the tester or the developer (or both) make errors, by applying GPT all the bugs will be detected, independently of the applied programming language or technology. Of course, the code consists of more than just predicates and there some bugs may remain undetected. Yet, it’s good to know that some types of bugs can be one hundred percent revealed.
GPT consists of three main steps:
- Understand the requirements or user stories. Search for logical rules (conditions), express and simplifythem by applying decision tables or cause-effect graphs. This step is the only manual part of the method.
- Define the abstract test cases according to the rules identified in step 1 by using ON/OFF/IN/OUT points.
- Optimize the tests, define concrete test data and determine the expected values.
If you determine the set of conditions, the remaining work is automatedly done.
Let us see an example.
Soldiers or card members, or those under 4 years can travel for free. Young people between ages 4 and 18 (inclusive), or people who turn 65 years can travel for half price. Then the rules are:
IF is_soldier = true THEN …
IF has_card = true THEN …
IF age is in [4, 18] THEN …
IF age ≥ 65 THEN …
Giving it to our tool (30 sec):
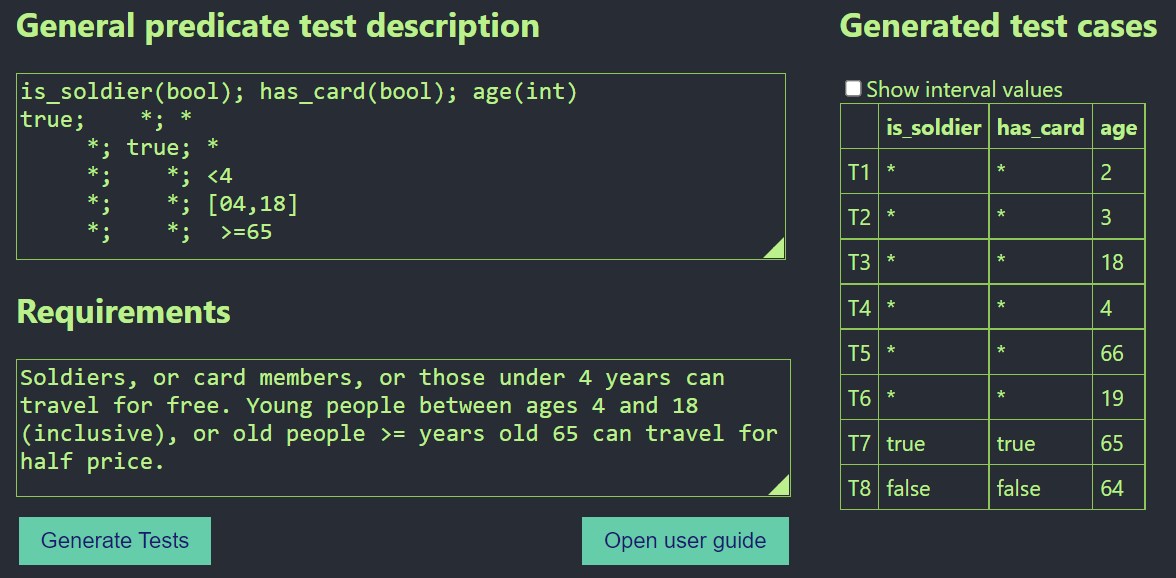
Hence, 8 tests are enough for revealing ALL predicate bugs. The ‘*’ means anything, thus T1 can be {true, false, 2}
A few years ago, the example above was one of the main topics for a half-day tutorial in EuroStar, by applying different test design methods, risks, coverage, etc. The resulting tests were unable to reveal all bugs.
Conclusion
I described five misconceptions about software testing I believe are the most important to learn. Knowing them will help you decrease SDLC costs, improve code quality and become a better software tester. If you know any other misconceptions, please write a comment.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK