

Linux 内核分析 之一:How Computer Works 实验
source link: https://changkun.de/blog/posts/linux-kernel-1/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Linux 内核分析 之一:How Computer Works 实验
Published at:
2015-03-03
|
Reading: 3169 words ~7min
|
PV/UV: 7/7
说明 欧长坤 原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000 这学期学校恰好有操作系统的课程,上个学习就开始寻思研究研究Linux内核代码,恰好MOOC有这个课程,遂选了此课。
一、实验过程 首先,我们将C语言代码利用编译器编译成汇编代码,下面是C语言代码:
int g(int x)
{
return x + 999;
}
int f(int x)
{
return g(x);
}
int main(void)
{
return f(0) + 1;
}
值得一提的是,事实上在我们没有使用标准C语言库的时候,可以不引用任何头文件(比如#include 就是不需要的)。显然,上面的代码并没有用到任何库函数。
通过gcc的功能,我们可以自定义编译参数来控制编译选项,我们为了让上面的代码编译成32位汇编代码,使用下面的命令:
gcc -S -o main.s main.c -m32
其中我们的编译环境为Mac OS X 10.10,所以提供的编译环境为64位编译环境,所以使用了参数-m32将C语言代码编译为32位汇编代码,而-S表示只是编译不汇编,生成汇编代码。而-o file表示将结果输出到file中。
我们可以观察生成的.s文件,如下图所示。
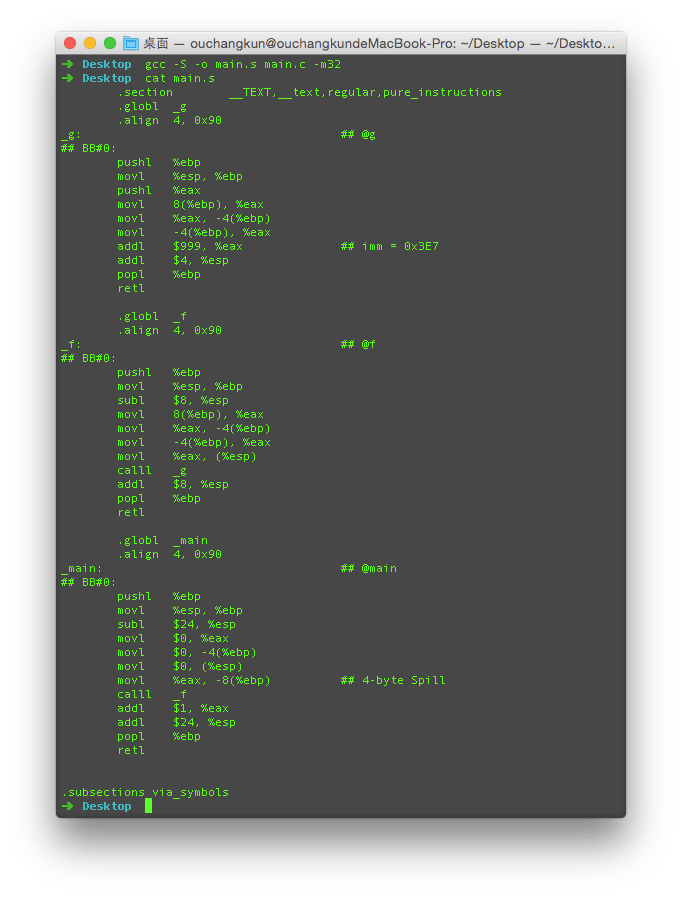
bwlq分别代表8、16、32、64位寄存器操作,所以我们可以看到这里的汇编指令l结尾,说明这些指令都是操控32位寄存器长度。
我们保留纯汇编代码的部分,得到如下的汇编代码
_g:
pushl %ebp
movl %esp, %ebp
pushl %eax
movl 8(%ebp), %eax
movl %eax, -4(%ebp)
movl -4(%ebp), %eax
addl $999, %eax ## imm = 0x3E7
addl $4, %esp
popl %ebp
retl
_f:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
movl 8(%ebp), %eax
movl %eax, -4(%ebp)
movl -4(%ebp), %eax
movl %eax, (%esp)
calll _g
addl $8, %esp
popl %ebp
retl
_main:
pushl %ebp
movl %esp, %ebp
subl $24, %esp
movl $0, %eax
movl $0, -4(%ebp)
movl $0, (%esp)
movl %eax, -8(%ebp) ## 4-byte Spill
calll _f
addl $1, %eax
addl $24, %esp
popl %ebp
retl
下面我们来分析这段代码的行为。
二、汇编代码行为分析
在分析这段汇编代码之前,我们需要牢记以下几点,不然分析起来就会对代码的各种诡异行为产生困惑,从而导致无法理解代码。 另外,这里的编译平台是Mac OS X,虽然使用的是gcc编译器,但是实际上在Mac中表现为clang的编译器,所以得到的汇编代码会和老师所分析的代码有很大差异。
注意以下六点知识:
- 堆栈分配是从高地址往低地址分配的,所以subl
eip的ip全称ip = instruction pointer指令指针,用来存放当前指令的下一条指令地址;ebp是堆栈指针,指向栈底;esp是堆栈指针,指向栈顶;- 函数调用堆栈实际上是逻辑上多个堆栈所叠加而成的;
- 函数的返回值默认使用eax寄存器存储返回给上一级函数。
汇编代码和C语言一样,都是从main函数开始的,所以我们在执行上面的汇编代码时,是从_main标签开始的。
首先,我们知道,main函数实际上是在系统的管理下分配出了另外一个内存空间来运行当前的函数,所以根据第五点知识,函数调用堆栈实际上是逻辑上多个堆栈所叠加而成,main函数的堆栈,会叠加在上一层函数(系统)。因此,在执行_main之前,系统的汇编代码就会表现为 call _main 状态,并且在堆栈中压入 eip 的值,这时 eip 的值是系统在执行完这个main函数的时候进行的下一步处理指令的地址。
我们假设不知道当前 ebp 和 esp 的位置,不妨设成如下图所示。
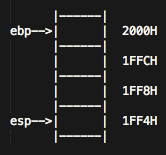
那么,第一句pushl %ebp,会再esp的位置压入ebp的的值,这时,在1FF0H这个位置会存入2000H,并且esp会移动到1FF0H的位置(堆栈分配从高地址往底地址分配,esp进行push时,指针会做减法,pop时,指针会做加法),接下来movl %esp, %ebp 会将esp的值传给ebp,因此,这时候ebp来到了esp的位置1FF0H。
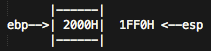
接下来的这步subl $24, %esp很诡异,可能是clang编译器对每个堆栈分配的时候都会预留24,我们先不去管它,直接对堆栈指针进行变动,这条让esp指针下移了24位。然后的四句:
movl $0, %eax ## eax = 0
movl $0, -4(%ebp) ## 这时候 ebp - 4 的位置也被赋值为0
movl $0, (%esp) ## esp 所指向的单元也被赋值为了0
movl %eax, -8(%ebp) ## 而ebp - 8的位置,被赋值为了eax,也是0。
得到下面图所示:
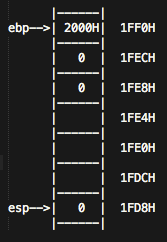
好,接下来这一步是 calll _f,这时候,会往堆栈中压入eip的值,而此时 eip 的值是 call _f的下一条指令addl $1, %eax的地址,我们不妨设为 X。
我们来到 _f 函数,
pushl %ebp ## 这时候继续压入ebp的值
movl %esp, %ebp ## 同样的,把栈底的位置移动到当前esp的位置上去
然后呢,这个堆栈似乎并没有如同main函数那样,clang编译器只给预留了8个单位的空间,所以esp会继续向下移动两个单元,并且,我们会把这时候ebp的前两个单元的值赋值给eax,
subl $8, %esp ## esp = 1FC8H
movl 8(%ebp), %eax ## eax = 0
movl %eax, -4(%ebp) ## (1FCCH) = 0
movl -4(%ebp), %eax ## eax = 0
movl %eax, (%esp) ## (1FC8H) = 0
我们就可以得到如下图所示:
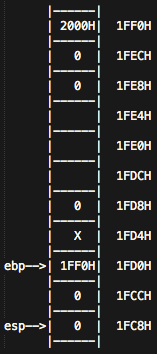
calll _g
这时候继续增加堆栈,进入函数g,这时候又会压入下一条命令 addl $8, %esp 的地址Y,然后开始执行函数 _g。现在我们来到函数 _g ,
pushl %ebp
movl %esp, %ebp
pushl %eax
继续压入ebp的值,把esp的值给ebp,同时把eax的值压入堆栈中。 然后,会把ebp前面两个位置的值赋值给eax = 0,并且把eax的值赋值给ebp,而ebp下面那个单元的值又会赋值给eax(又是好诡异)
movl 8(%ebp), %eax
movl %eax, -4(%ebp)
movl -4(%ebp), %eax
无论如何,eax的值始终是0,到这,如图所示:
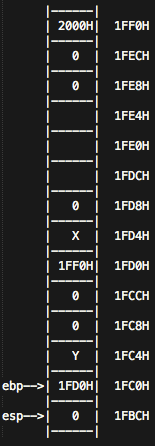
addl $999, %eax ## eax = 0 + 999 = 999
addl $4, %esp ## esp = 1FC0H
popl %ebp
eax的值会加上999,esp会向上移动一格,然后弹栈,把1FD0H值赋值给ebp。这时候esp = 1FC4H
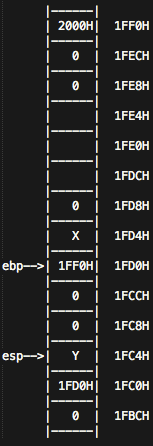
retl
返回。这时候会弹出esp所在位置的值赋值给eip,而esp会增四。
这时,ebp = 1FD0H, esp =1FC8H, eip =Y,eax = 999,所以下一步将会执行Y地址的指令,我们上面假设了,Y地址的指令恰好就是函数f的命令addl $8, %esp。所以我们从这里开始:
addl $8, %esp
popl %ebp
esp会继续向上移动两个格子,同时出栈,把1FF0H的值赋值给ebp,如图所示。
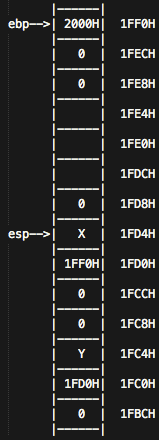
这时候我们再retl,会继续出栈,eip会得到X的值,esp会移动到1FD8H的位置
我们刚才假设过,X地址的指令,其实就是main函数addl $1, %eax指令的位置,所以这时候
addl $1, %eax
结果为:eax = 999 + 1 = 1000。
addl $24, %esp
接下来,esp加24,回到了最初的位置1FF0H, 最后,popl %ebp,继续弹栈,ebp回到了2000H的位置。 得到:
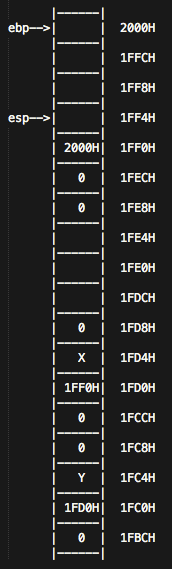
通过retl,完成了整个main函数的运行,而eax寄存器里面的内容,则作为默认的返回值,最终返回给系统了,这时eax的值为:1000。符合我们所编译的C语言代码的main函数的预期返回值。说明我们的分析是正确地。
三、总结
从上面的过程我们可以看出,计算机中,函数调用的这部分工作实际上是通过堆栈的层层堆叠完成的。我们编写的程序,同样也是在系统上进一步堆叠一个堆栈从而执行。我们完成了从代码层面上得详细分析。 下面谈谈我个人对计算机内部的函数调用模型的个人理解:
计算机的工作过程在最简单的情况下,只涉及两个硬件——CPU和内存。在冯诺依曼体系下,CPU在一个时刻内,从内存中取出执行的指令,送往内部的控制器进行指令的解释执行。 与此同时,在内存中存放的不仅仅是指令,还有CPU在执行指令时候的数据,因此,指令和数据在内存中实际上是混合排布在一起的,区分他们的唯一方式就是这个单元的数字如果被送往控制器,则为指令,否则为数据。 在操作系统管理内存的时候,堆栈是从高地址往低地址进行分配,堆栈也是如此堆叠而成(我目前还不清楚是否有意外)。目的是为了和低内存地址位置的系统数据和指令加以区分,防止出现意外。 计算机的CPU通过CPU内部的几个寄存器,来记录并模拟堆栈的行为。当在一个函数A中调用另一个函数B时,实际上是把指令指针eip的地址压入堆栈来确保以后能成功的返回上一级堆栈,然后从函数B的入口地址进入转去执行函数B,当函数B执行完后,此时弹出堆栈时,eip会接受弹栈的值,并返回去执行函数A没有执行完的内容。
将以上过程放大到整个计算机来看,四个字:“取值,执行”,这就是计算机的工作原理。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK