

10 tips for machine learning experiment tracking and reproducibility: Do it your...
source link: https://developer.ibm.com/blogs/10-diy-tips-for-machine-learning-experiment-tracking-and-reproducibility/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Blog Post
10 tips for machine learning experiment tracking and reproducibility: Do it yourself approach without additional tooling
Easy-to-implement practices that require no additional tooling
As machine learning practitioners, we invest significant time and effort to improve our models. You usually do it iteratively and experimentally by repeatedly changing your model, running an experiment, and examining the results, then deciding whether the recent model change was positive and should be kept or discarded.
Changes in each iteration might involve, for example, changing a value for a hyperparameter, adding a new input feature, changing the underlying machine learning model (for example, by using gradient boosting classification instead of random forest classification), trying a new heuristic, or trying an entirely new approach.
Experimentation cycles can cause a great deal of confusion. It’s easy to get lost, forgetting what changes you made in the recent experiments and whether the latest results are indeed better than before. A single experiment can take hours or even longer to complete. So, you try to optimize your time and execute multiple experiments simultaneously. This makes it even less manageable, and the confusion gets even worse.
In this blog, I share lessons and good practices that I learned in my recent machine learning projects. Although I call it a “Do it yourself” approach, some might call it “The caveman way.” I am fully aware that nowadays there are many experiment tracking and management platforms, but it is not always possible or convenient to use them. Some platforms require that you execute your experiments on their platform. Sometimes you can’t share sensitive information outside of your organization, not just the data sets but also results and code. Many platforms require a paid subscription, which can also be a problem in some cases. Sometimes you just want full control of your experiment management approach and data.
The following practices are easy to implement and do not require additional tooling. They are mostly suitable for small to medium machine learning projects with a single researcher or a small team. Most of the artifacts are saved locally, and adaptations might be required if you want to use a shared storage. As a seasoned developer of production systems, I’m aware that a few of the tips might be considered ‘code-smells’ or bad practices when it comes to traditional development of such systems. However, I believe that they have their place and are justified for short-term research projects. I would like to emphasize that the tips reflect my personal journey and point of view, and not necessarily any official views or practices.
Tracking what you did
1. Use source control
It goes without saying that your experimentation code should be source-controlled. That said, when using modern interactive environments like Jupyter Notebooks, it’s easy to be tempted to make quick experiments on-the-fly without committing changes to Git or any other source-control system. Try to avoid that as much as possible. Maybe it is only me, but I prefer using a decent IDE and plain Python scripts to run experiments. I might use a notebook for the initial data exploration, but soon after an initial model skeleton is ready, I switch to a full-fledged Python script, which also allows debugging, refactoring, and so on.
2. Use identifiable experiments
But you know what? Source control isn’t enough. Even if everything is source-controlled, it can be tedious to browse the repository’s history and to understand what source was used for running an experiment 12 days ago. I would like to suggest an additional practice that I call “Copy on Write.” Duplicate your latest experiment script file or folder before each new experiment and make the changes on the new file. Make your experiments identifiable by adding a sequential number to each experiment in the source file name. For example, animal_classifier_009.py for experiment #9. And, yes, this works also for notebooks: you can create a notebook per experiment. This means that you need only a file diff to understand what changed between experiment #9 and #12. Storage is cheap, and the size of all of your experiments’ source code is probably dwarfed by the size of your data.
3. Automatic source code snapshots
Another tip is to automatically take a snapshot of your experiment code for each run. You can do this easily inside the experiment script itself, by bootstrapping code that copies the source file or folder to a directory with the experiment start timestamp in its name. This makes your experiment tracking strategy robust even if you were tempted to make on-the-fly experiments without committing or copy-on-write above (that is, “Dirty Commits”). For example, when running the experiment animal_classifier_009.py, we create the folder out/animal_classifier_009/2021_11_03–12_34_12/source and store a snapshot of the relevant source code inside.
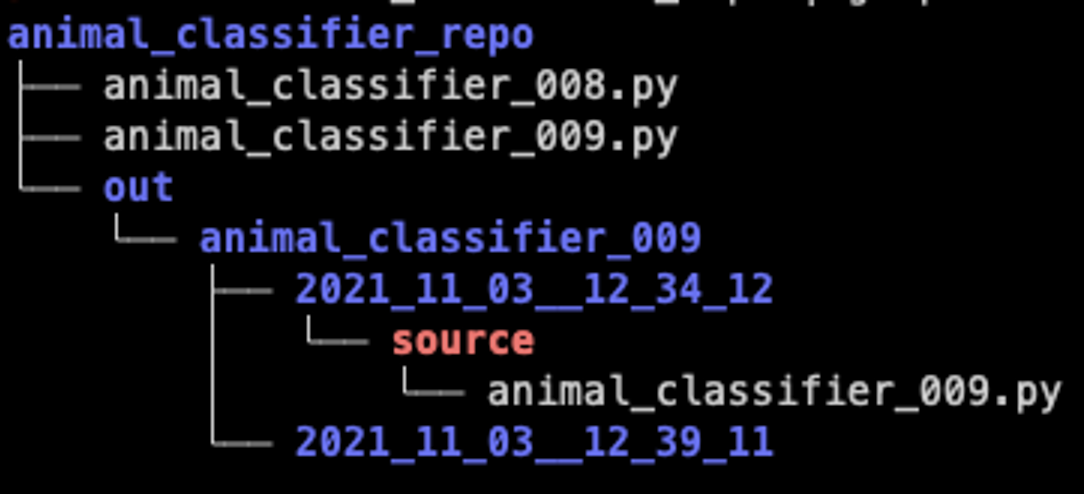
4. Treat experiment configuration parameters the same as source code
Avoid tuning experiment parameters or hyperparameters in the command-line, environment variables, or any other external way that is not part of the source code. Otherwise, you risk losing traceability for changes if you forget to log the parameter values.
To embed experiment configuration, you can use either plain Python, dictionary, JSON, YAML, or any other format that you find convenient. Just make sure you commit the configuration files together with the experiment code. Does hardcoding stuff seem like a code smell? Well, not in this case. If you do accept external runtime parameters, be sure to log their values!
Each configuration changeset should be treated as a unique experiment. It should be committed to source control, configuration files shall be included in the experiment code snapshot, and it should get its own experiment ID.
The advantage of embedding configuration as part of the source control is that you can be sure you reproduced the same experiment just by running the program file, not other moving parts that you might forget to set.
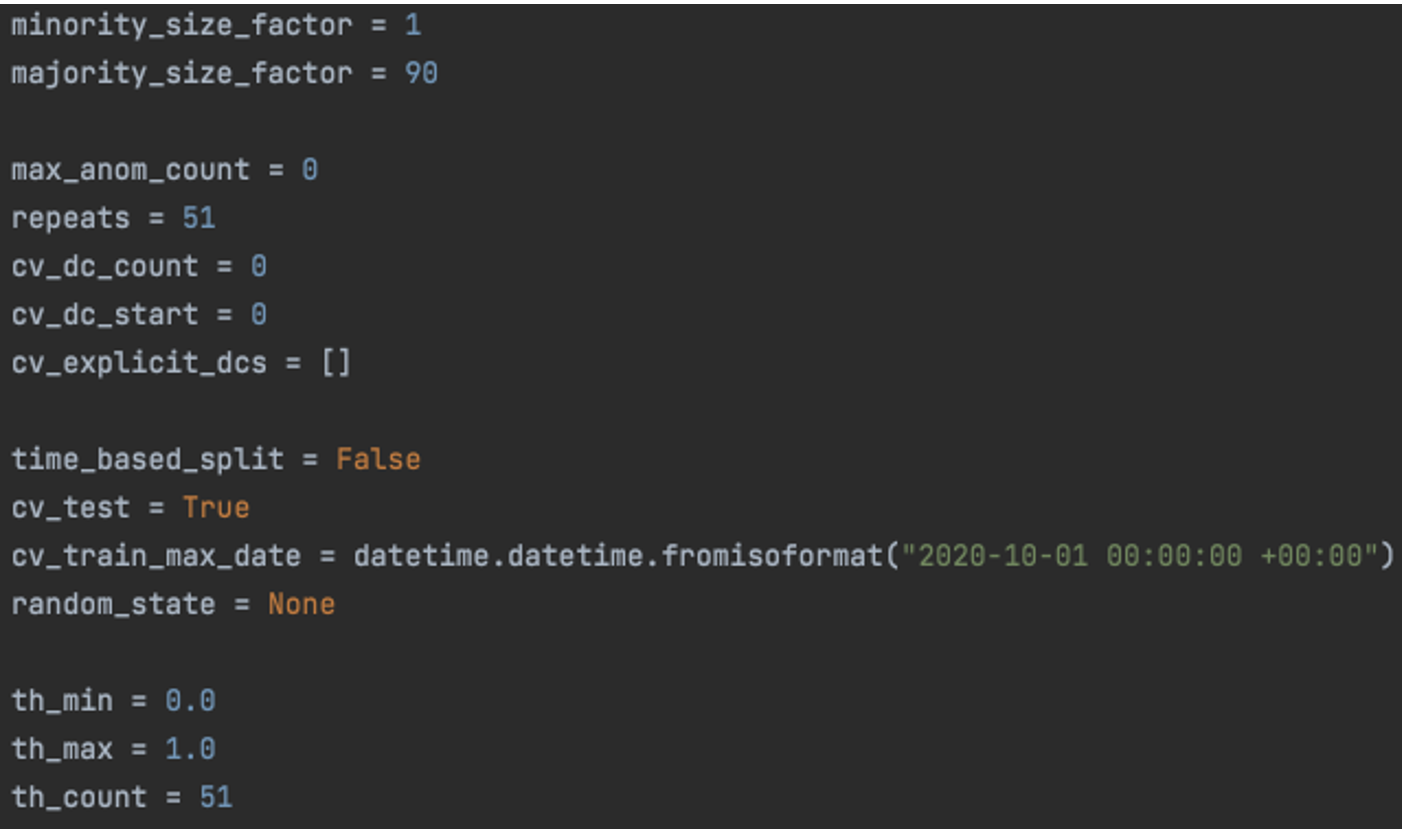
5. Track experiment evolution tree
One of the things that helps me a lot is to keep track of the reference experiment – the predecessor baseline that I am trying to improve upon. This is easy to do if your experiments are identifiable. When you create a new experiment by duplicating, keep track of the parent experiment ID plus the essence of what you’ve tried in this experiment that is different from the parent. This information helps you quickly recall what you did, without relying on code diffs. It also makes it possible to traverse back in the experiment tree and quickly get the full picture. You can track the parent experiment inside the source code itself as a code comment.

However, this might cause a problem if you forget to update the notes before running the experiment. I suggest a simple spreadsheet.

In the spreadsheet, you can also capture other information or parameters that you used in this experiment, and, of course, experiment results. But I’ll touch on that later.
Tracking what happened
6. Keep console/log output
Be generous with logging statements that track what happened in the experiment. Track many metrics and types of information, like data set size, label count, date ranges, experiment execution time, and more. These can help you detect issues and mistakes. Be paranoid! Every unexplained change in a metric could be caused by some mistake in the experiment setup. This helps you understand its root cause.
Any experiment output should be persisted. I recommend using the Python logging module instead of plain console prints so that you can redirect logging messages to both stdout and a file. In addition, you get timestamps for each log event, which can help you to solve performance bottlenecks. You can store the log file under a folder that is correlated to the experiment ID and execution time.
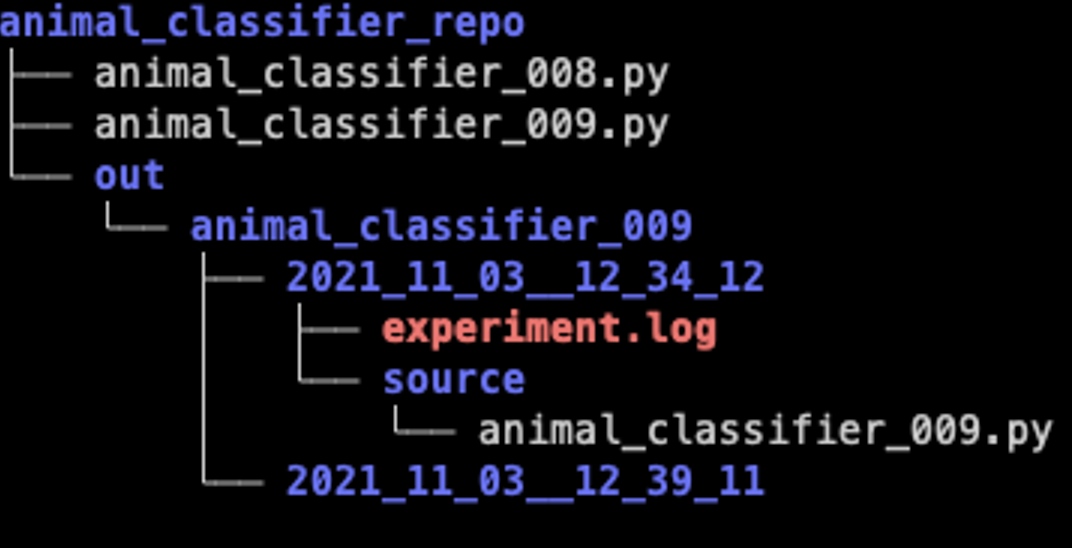
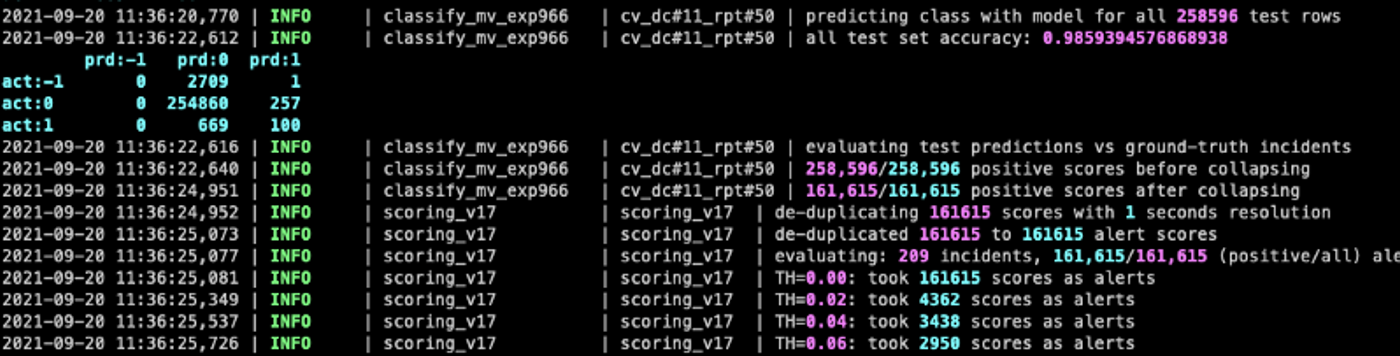
7. Track experiment results
You might use multiple metrics that quantify the quality of your model. For example, accuracy, precision, recall, F-score, and AUC. Make sure that you track these in a separate, structured results file that you can automatically process later to show charts and more.
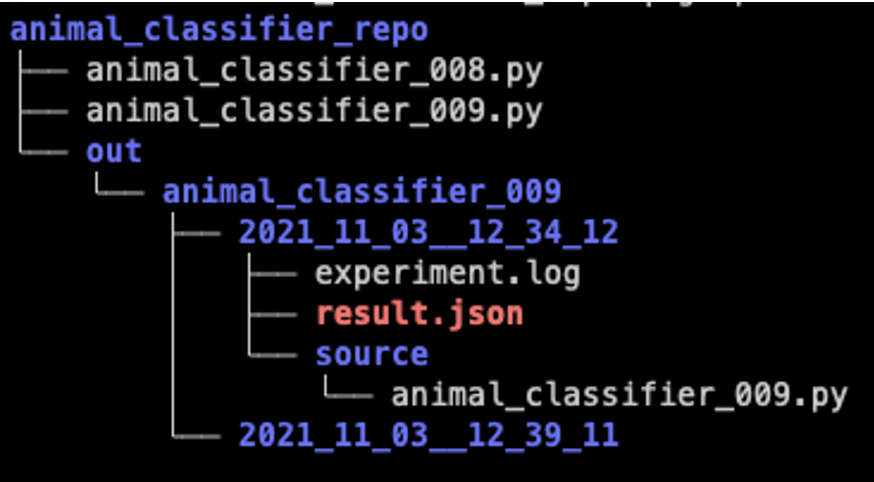
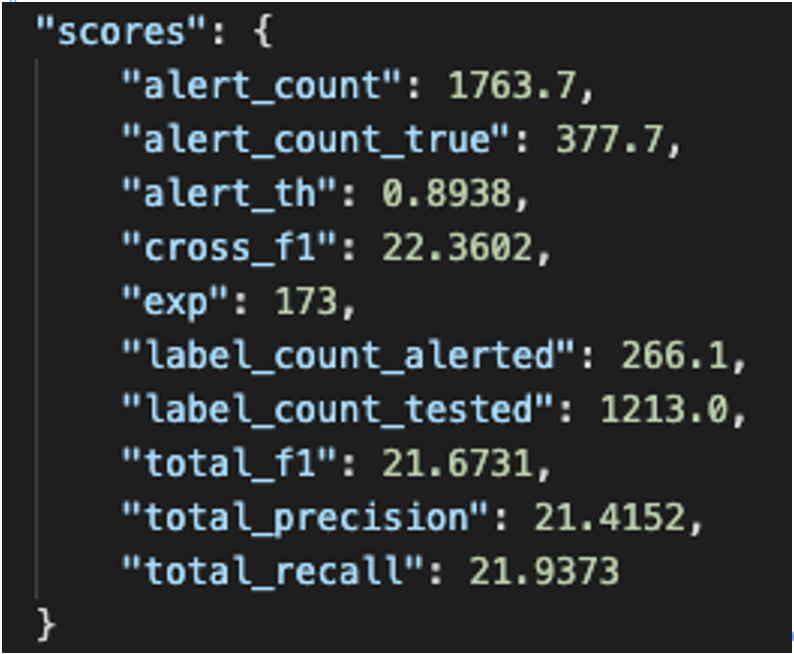
It’s also a good idea to track your most important metrics in the experiment spreadsheet so that you can get the full picture quickly and decide on future directions. I like using colors to mark results (green=improved, red=got worse, yellow=not sure).

8. Do multiple repeats for stochastic models
You want your results to be reproducible, but still avoid getting misleading results due to chance. The solution lies in repetition with random seeds. Avoid using fixed random seeds if your models are stochastic. The same applies when shuffling, down sampling, or any operation that contains a random element. For example, if you use scikit-learn, always run your models with random_state=none. Perform multiple repeats in each experiment, and average the results of your optimization target metrics in all repeats so that you get stable numbers. You can use metrics like Standard Error of the Mean (SEM) to estimate how close your repeats’ mean is to the true mean of the population (if you could run an infinite number of repeats). The SEM metric value decreases as you increase the number of repeats. This helps you gain confidence and understand if your latest results are indeed better or if it was just luck, and you should increase the repeat count to be sure. In general, when your model gets more mature/stable, your optimizations will probably have a smaller impact, and you might need to increase the repeat count.
Tracking input and intermediate data sets
9. Track input data sets
Remember to version and name the data sets that are used as input to your model with the version identifier. Input data sets tend to be large, so I wouldn’t recommend duplicating them into each experiment’s tracking folder. Just make sure to log the file names/URIs of the input data sets that you used. You can also find these file names in the source code snapshots for the relevant experiment. You can add another safety layer here by computing and logging a hash/digest of the contents of each input data set. Log also the basic characteristics of the data, such as its dimensions and sample counts for each class.
10. Avoid or track intermediate data sets
Some of your code might perform heavy preprocessing of data sets. This can sometimes take a long time, so you might do it once and then use the output in later steps. If your preprocessing has a stochastic nature, (shuffling, train/test splitting, and so on), try to avoid creating intermediate data sets unless the processing can really save a lot of experiment time. Otherwise, you might have an inherent bias in your data, similar to when using a fixed seed. Instead, you can invest in optimizing the execution time of the preprocessing steps.
If you do generate intermediate data sets, treat the source code that you wrote for that purpose just like a normal experiment by using the practices described so far. Use version numbers for the source file, track the source code, and track the logs. It’s a good idea to save the output intermediate data sets in the out folder of each experiment. This makes the data sets inherently identifiable.
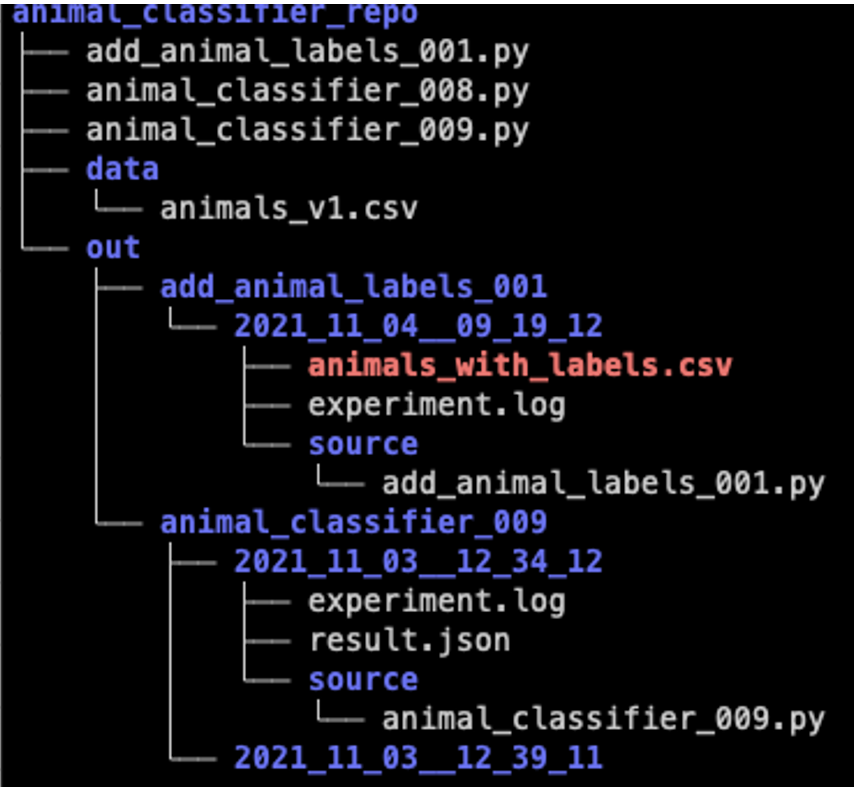
Summary
In short, experiment management is essential and pretty easy to do if you adopt some simple techniques. No matter whether you do it yourself or use an experiment management platform, just do it!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK