

云环境下的数据库迁移避坑指南
source link: https://dbaplus.cn/news-160-4215-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

云环境下的数据库迁移避坑指南
本文根据韩宇峰老师在〖2021 DAMS中国数据智能管理峰会〗现场演讲内容整理而成。(点击文末“阅读原文”可获取完整PPT)
韩宇峰
中国移动 应用架构师
-
中国移动信息技术有限公司-智慧中台运营中心-应用架构师,负责部门整体数据库云化迁移和国产化改造工作。拥有15年开发工作经验和10年电信运营商工作经验,对应用架构、数据库开发、云化改造等领域有较深涉猎。
分享概要
一、数据库现状
二、迁移过程的探索&总结
三、未来的计划和展望
一、迁移面临的挑战
1、为什么要迁移?首先在做数据库迁移之前我们问了自己一个问题,为什么要迁移?大家都知道,对于技术人员来说一般都不愿意去动一些祖传老代码,但是随着业务的飞速发展和技术的推陈出新,有越来越强烈的驱动力去促使我们去上云,去做云化改造。
一方面是业务的快速发展:业务种类增多、规模扩大;数据体量急剧增长;数据的应用模式也在不断丰富。
另一方面是技术上的驱动:我们需要更灵活、更快速的扩缩容方案;还希望有专职人员运维、专人专事;
同时要求数据库更加稳定、可靠、健壮、易用。正是这些驱动力促使我们有意愿去做数据库的云化迁移改造。

那么再来看看我们的现状是怎样的呢?
首先是选型多样化:免费的、收费的、OLTP、OLAP、HTAP、主备式、集中式,不同的业务场景在选型时考虑点各不相同;
其次是业务耦合比较深:业务逻辑依赖于数据库、数据模型庞大且缺少适当的拆分,尤其一些传统的CRM、BOSS类系统,由于多年的发展一些历史的业务逻辑已经深度耦合在数据库中了;
再来就是部署复杂:主机类型、操作系统、部署架构都非常复杂;
最后就是标准不一致:同样产品版本不一致、工具信息不统一、参数调优各异。

一谈到数据库相关的改造,不管是技术人员还是业务人员,都有非常多的担心和困扰。一方面现网数据库产品的相关技术和生态成熟度较高,让相关人员在开发和运维中更有把握,大家不愿意去动核心技术和架构;另一方面现网数据库产品又不能很好地满足技术和业务的快速发展,相关人员渴望新技术的引入来解决问题。
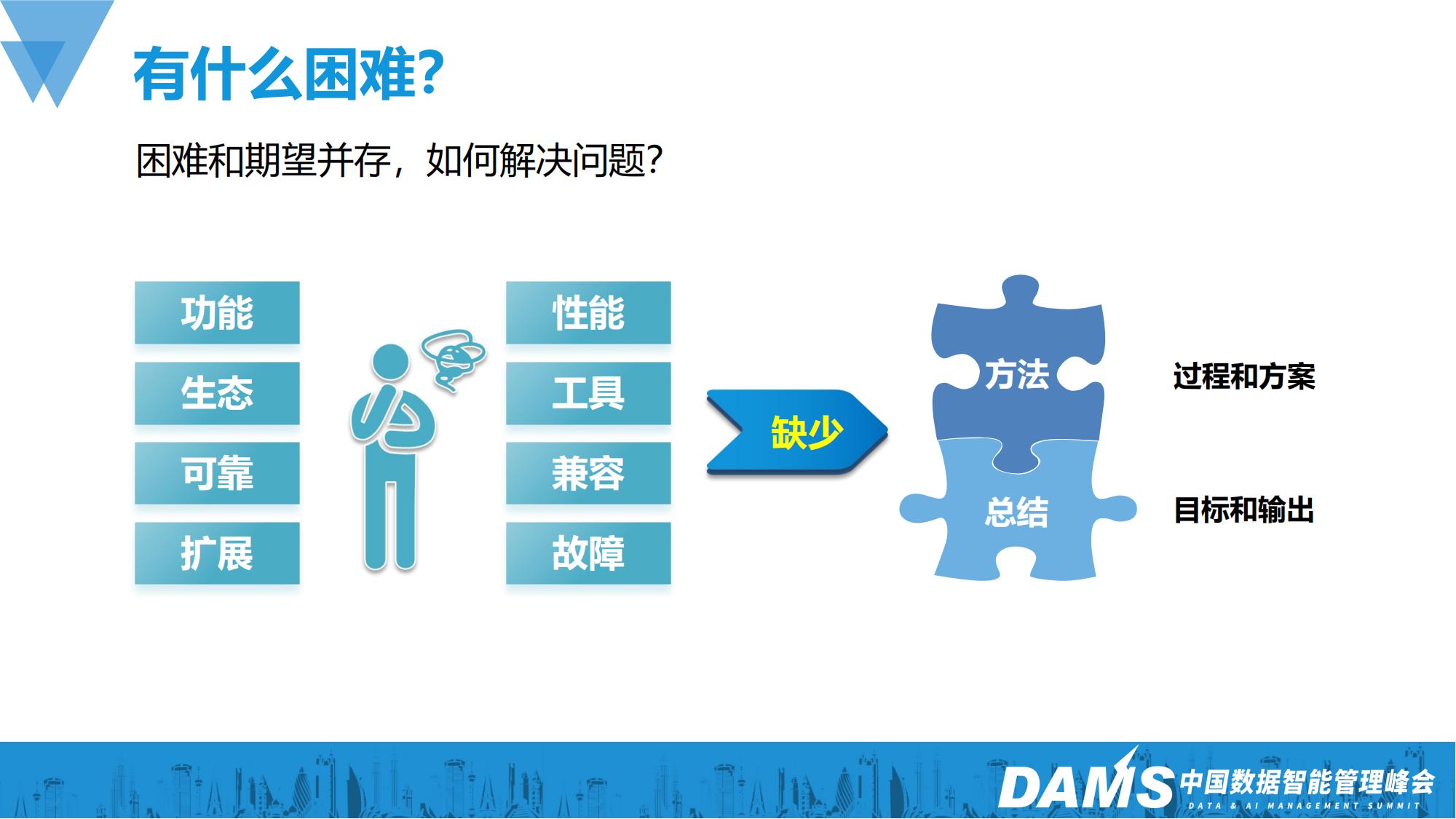
我们在提出问题的同时也在思考,我们到底缺少了什么导致数据库的迁移和替换变得这么难以推进?是缺少好的产品吗?肯定不是,目前国内市场有很多非常优秀的数据库产品,它们的各项指标都很出色。是缺少投入吗?肯定也不是,为了提升自主掌控的能力,我们在各行各业都投入了非常大的资金和人力。
其实我们缺少的是迁移和改造的方法和总结,我们需要通过方法来确保过程和方案的可行,通过总结来确保目标和输出的达成。
分析了驱动和问题,我们要开始寻找方法了。
二、迁移过程的探索&总结
1、迁移过程中的目标?引用《高效能人士的七个习惯》中的一句话:“以终为始 以行为知”,我们需要先确定好目标,再围绕目标来制定计划。于是我们召集了业务、架构、技术、运维等多方面的人员,从自己的岗位角度提出迁移的目标和要求。总结了以下几点:业务稳定、平滑过渡、稳定可靠、有路可退。
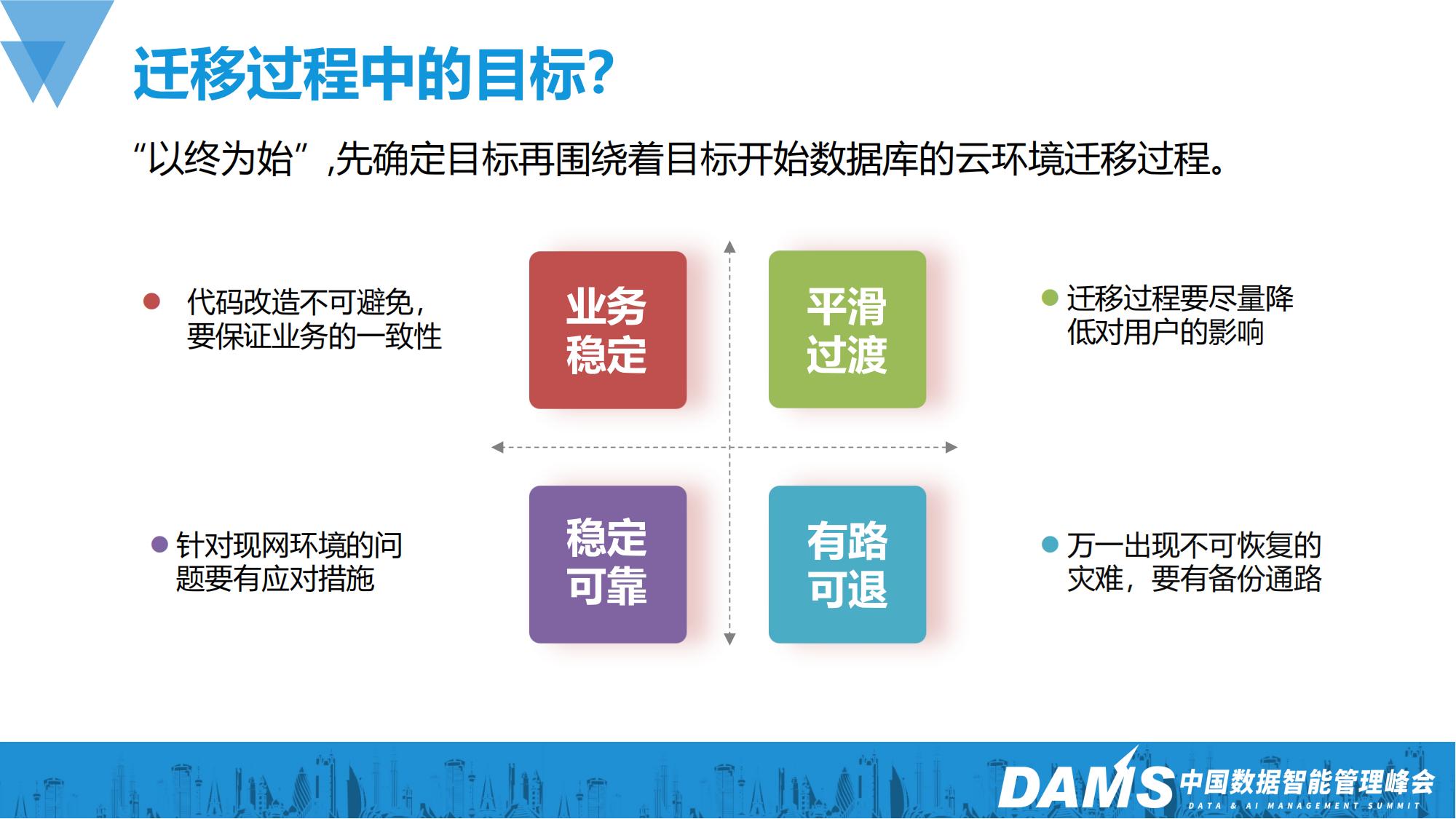
有了目标以后,我们再针对目标做进一步的思考和分解,通过技术手段来确保目标的达成。
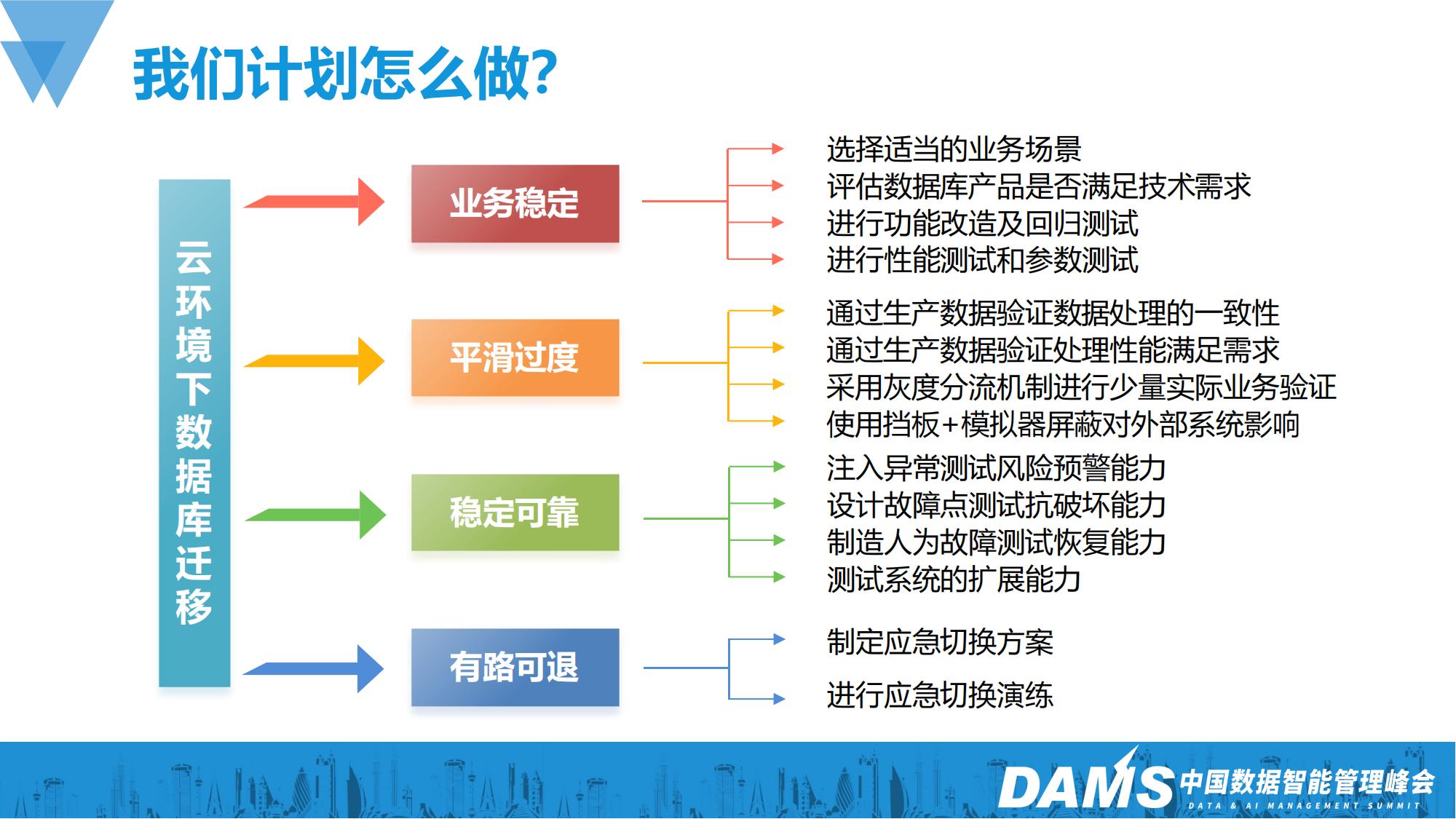
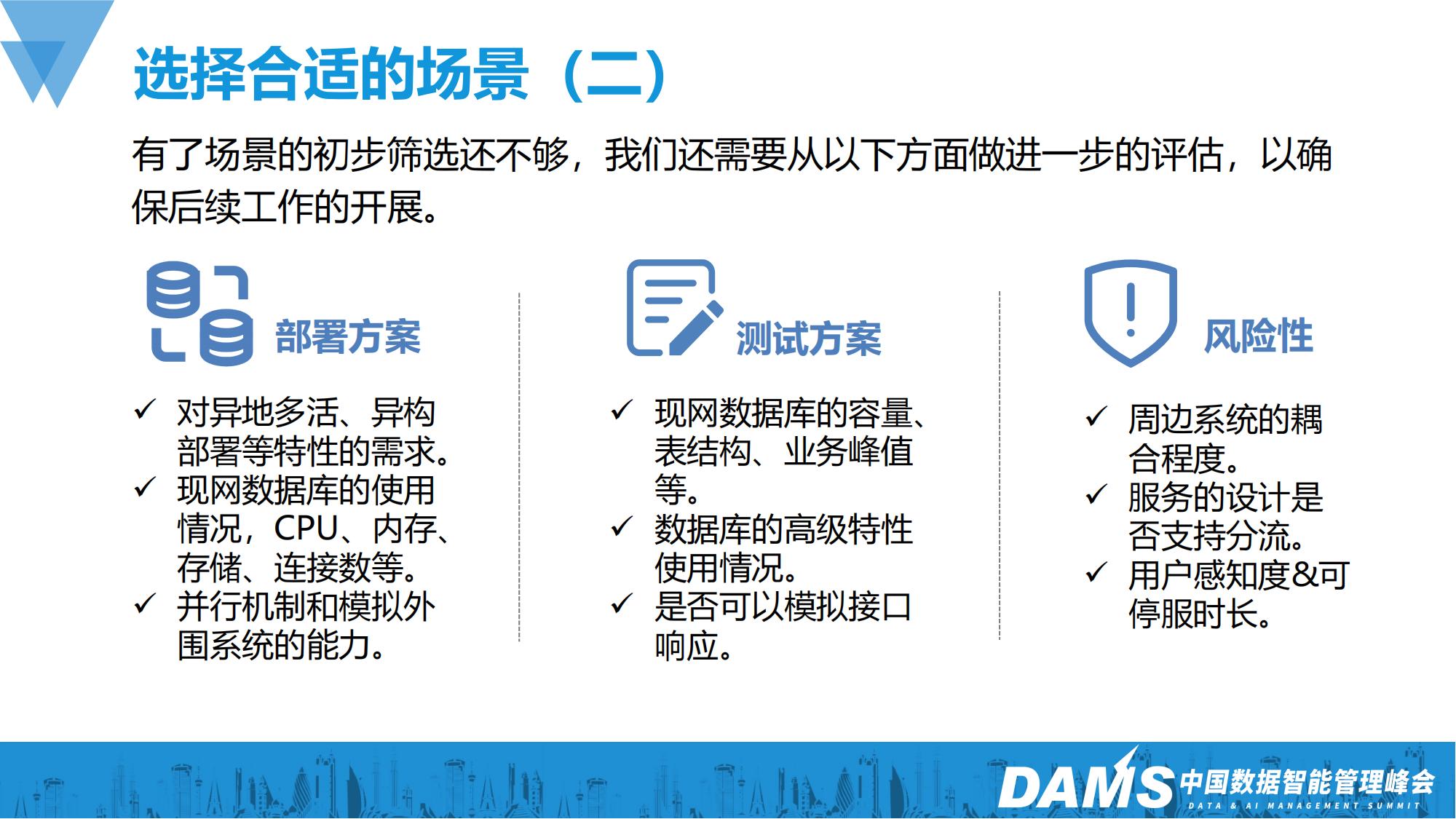
首先我们要选择一个合适的业务场景,我们面临的业务场景非常庞杂,在云化迁移时对数据库的需求也各不相同,为了更好地做出选择,我们对常见的业务场景做了梳理,选择风险相对可控,借鉴意义较高的场景来开展工作。这里需要注意是场景,而不是系统,因为一个系统经过多年的建设往往比较复杂,系统整体迁移的技术比较复杂且风险过大,一旦失败了很难回退处理。而一个场景只是系统中的一部分,既能确保业务相对完整独立,也能保证改造范围相对可控。以下是我们对一些常见业务场景的评分标准:
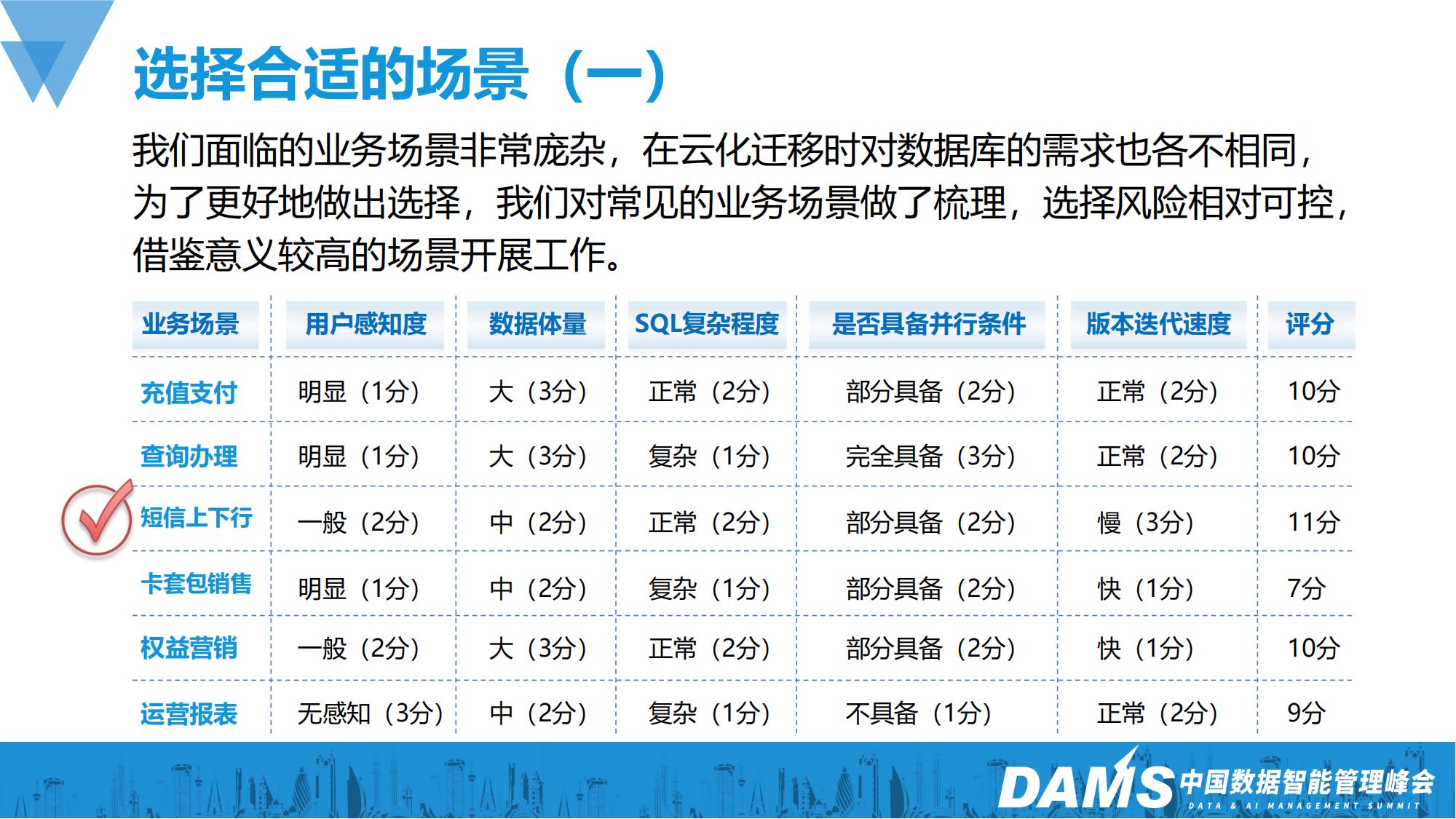
所有评分都是1-3分,分值越高越适合:
-
用户感知度:感知越明显分值越低,明显-1,一般-2,无感知-3
-
数据体量:体量越大的分值越高,小-1,中-2,大-3
-
SQL复杂:SQL越复杂评分越低,复杂-1,正常-2,简单-3
-
并行条件:越容易并行越高,不具备-1,部分具备-2,完全具备-3
-
版本迭代:迭代速度越快分值越低,快-1,正常-2,慢-3
有了场景的初步筛选还不够细致,我们还需要从以下方面做进一步的评估,以确保后续工作的开展:
确定了场景以后,我们优先选择进行数据迁移,一方面是为后续的基础功能测试提供真实的数据结构和数据体量,另一方面是为了尽早发现兼容性问题为后续功能改造提供依据,让后续的基准测试和功能改造可以并行。
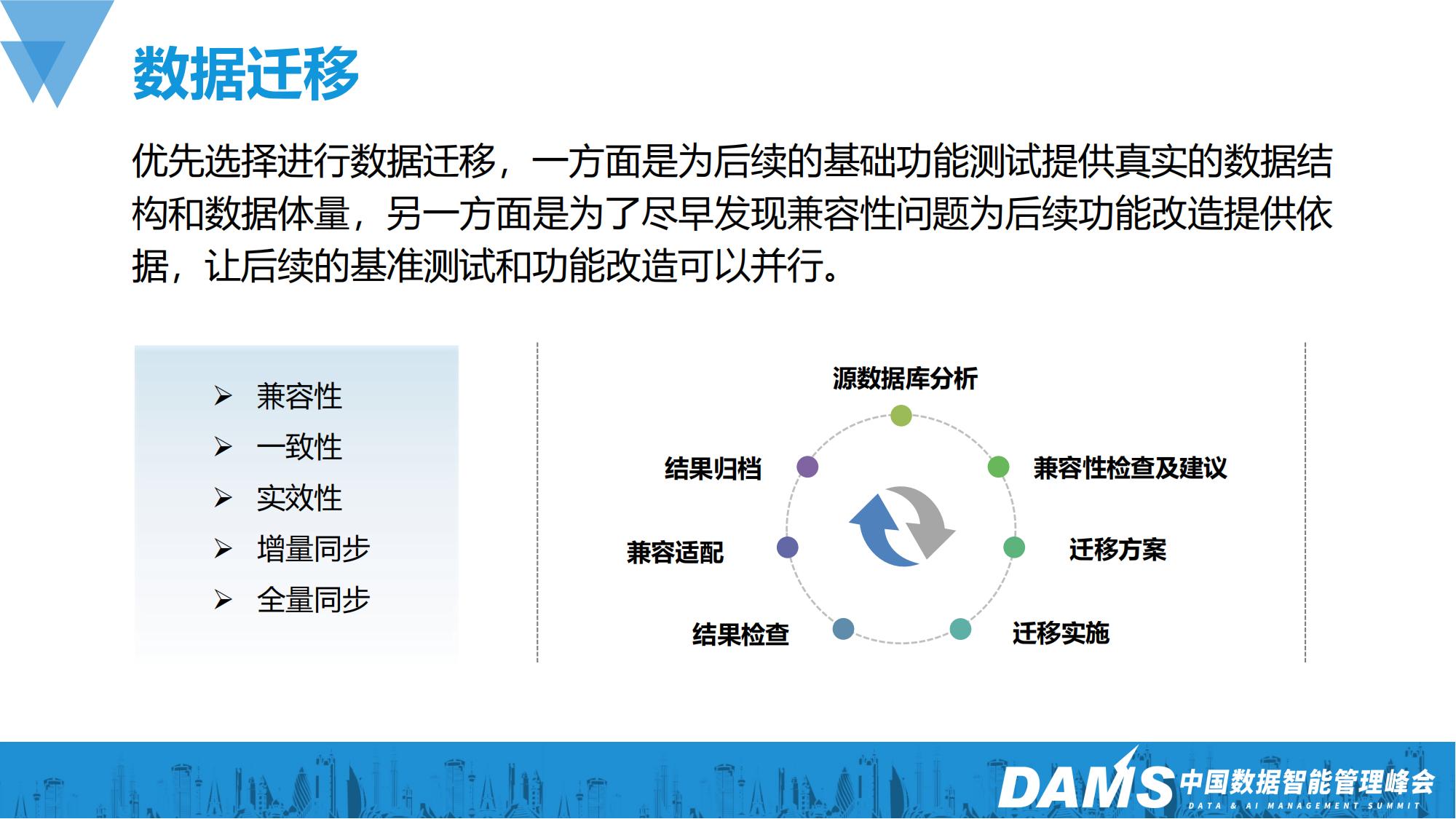
迁移的整个过程如上图右侧所示,共包括7个步骤。在迁移的过程中我们要重点关注上图左侧的这几个问题,在我们的实际操作过程中我们发现问题最多的就是效率问题,一些连续性高的业务场景割接窗口期很短,数据同步时间过长会极大影响用户感知。
5、基准测试有了真实的数据结构和数据体量,我们可以开始对数据库进行一些基准测试,这些基准测试的目标是要确保数据库的基础功能能够满足业务场景的需要。我们把这些基础测试分为了5大类,包括:基础功能、可维护性、可靠性、扩展能力和安全性。

在测试人员进行基础功能测试期间,我们同时在进行应用和数据库的改造。核心原则是:数据层做主要改动,接口层做适当改动,核心逻辑尽量不做改动。数据层的改动多多少少是无法避免的,接口层的改动主要是为后续的分流考虑,核心逻辑只有在评估过后不可避免的情况下才进行调整,而且要重点进行功能复测。
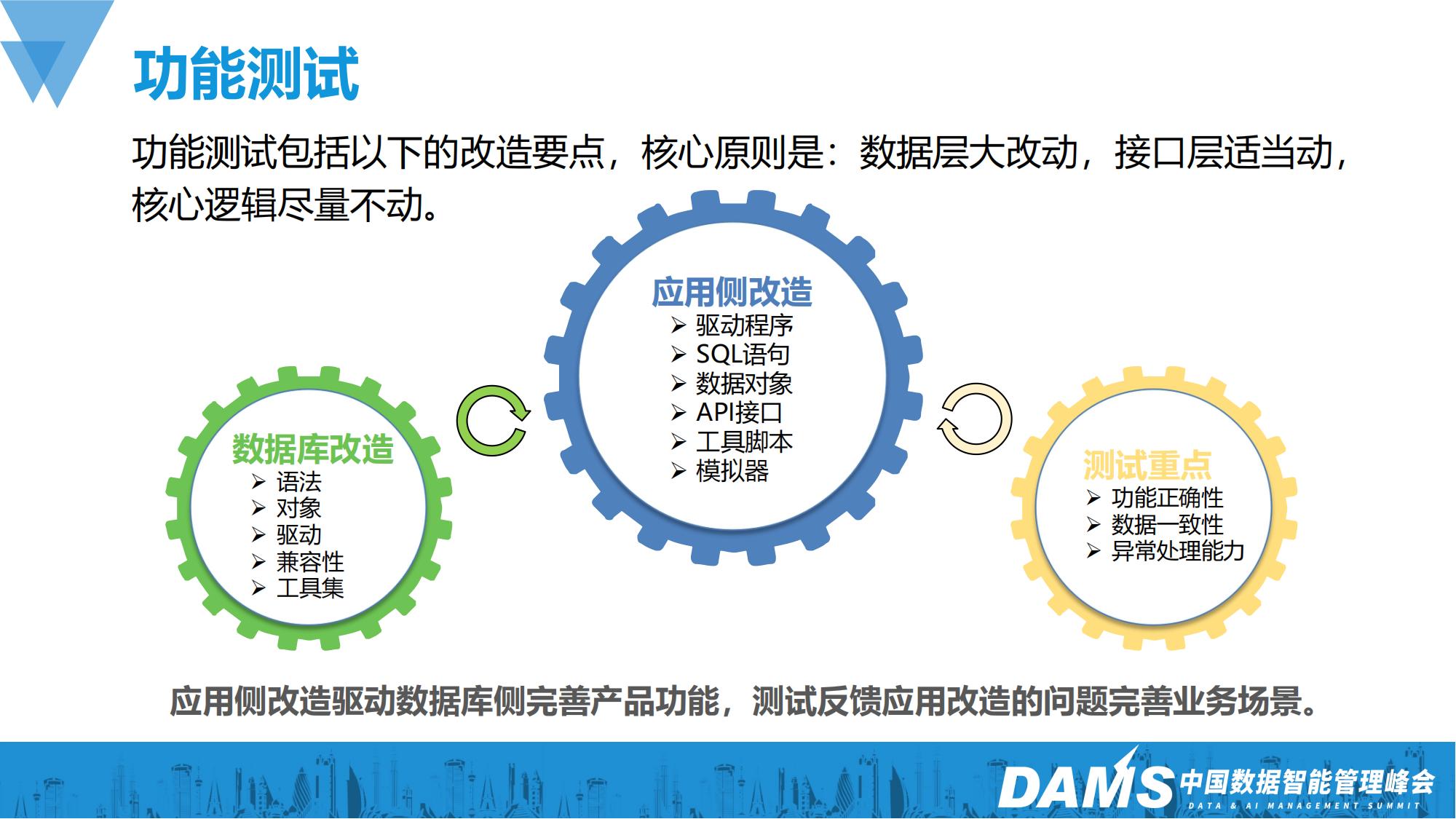
应用侧我们一般会做以下改造:
-
SQL语句
-
API接口
数据库侧一般会在改造期间也发现一些问题,针对这些问题数据库厂商也会进行适当的优化改造:语法、对象、驱动、兼容性、工具集。
最后是功能测试的重点:
-
功能正确性
-
数据一致性
-
异常处理能力
7、性能测试
功能测试完成后我们会开展性能测试工作,首先是接口、数据库和模拟器的基础性能测试,这里要强调一下,千万不要忽略模拟器的性能,曾经我们就因为模拟器性能不足导致性能测试结果无法满足要求。其次是进阶性测试:复杂SQL的执行效率、数据量引发的性能衰减、疲劳测试,其中数据量引发的性能衰减这方面尤其重要,实践过程中我们也发现了这个问题,随着数据量的增长,同样SQL的执行效率在下降,同样体量的压测性能指标也在下降,对于这方面我们要有一个充分的预估。最后是结论:性能指标和性能对比可以给后续上线评估和业务发展提供基础依据。

再说一下性能测试期间,我们重点从哪些方面做了调优:第一是代码层面,一般来说SQL语句、库表结构都有一定的调优空间,如果还不满足要求可能就要考虑分库分表了,不过这对整体代码逻辑有较大的影响要谨慎决策。第二是数据库层面,索引的设置、数据库的参数都是可以调优的。第三是运维层面,主机、容器、中间件、部署架构都有一定的调优空间。

前面这些工作都是在测试环境中做的一些工作,接下来我们要和实际生产有一定的结合,才能够真正评估迁移的可靠性和稳定性。我们需要持续性的将生产数据导入到目标库,来验证数据处理的性能和一致性。首先要从现有环境中抽取SQL,写入消息队列,而后再进行有序消费和入库,最后进行数据一致性的检查。

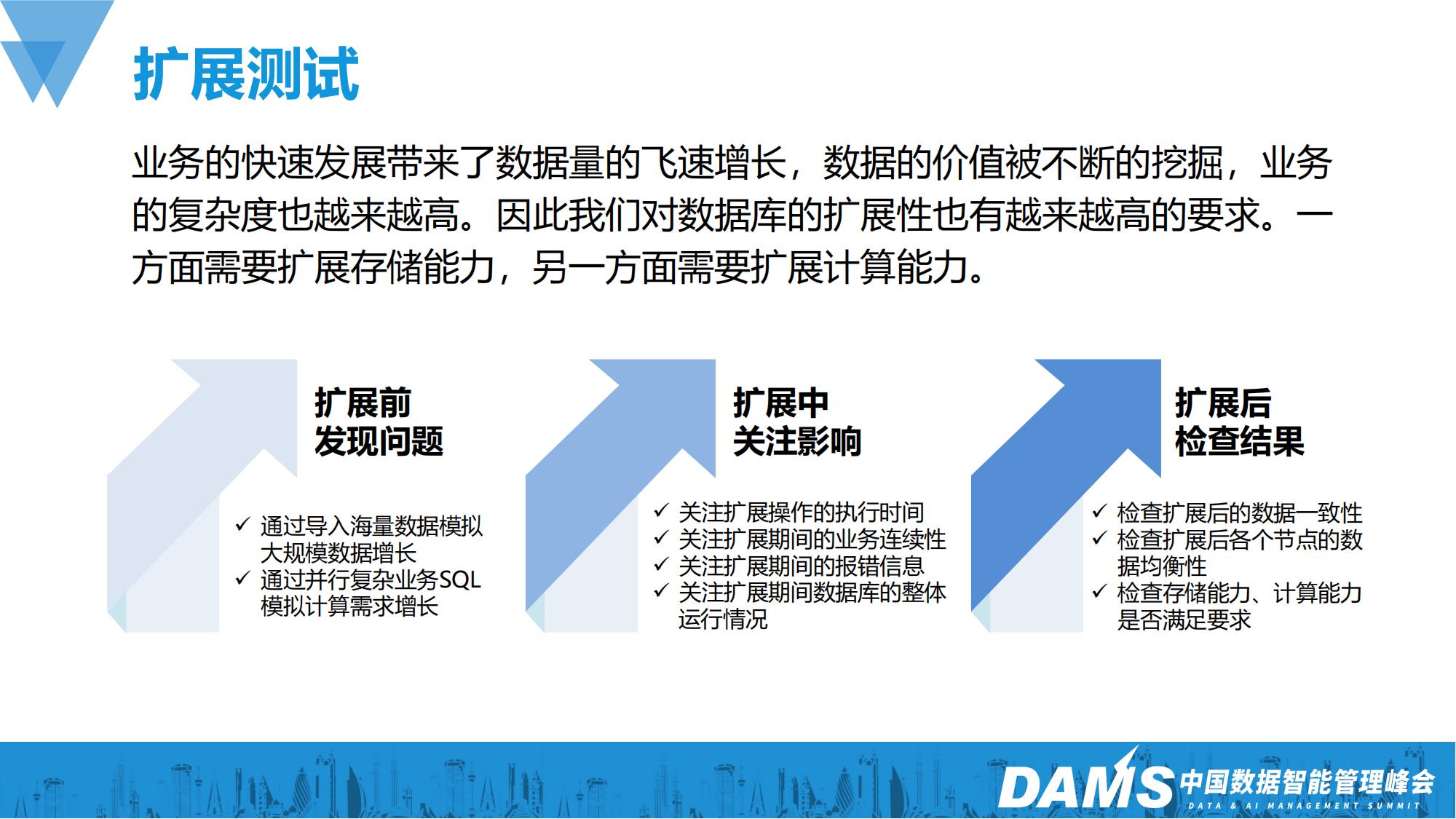
大部分的业务场景都有扩展性的需求,因此我们对扩展功能也进行了带业务的验证测试。在扩展前通过导入海量数据来模拟大规模的数据增长,通过并行复杂业务SQL来模拟计算需求的增长,检查数据库的运维工具是否可以及时发现这种变化并作出提示;在扩展过程中我们要关注方案的执行时间、业务的连续性、应用侧和数据库侧的报错信息、以及数据库的整体运行情况;在扩展操作结束后我们还需要对相应的内容进行检查,包括:数据的一致性、均衡性、以及存储能力和计算能力是否满足要求。
接下来是一些有针对性的破坏性测试,左侧的一些案例是我们从实际故障中提取形成的,在进行破坏性测试期间有4点需要关注和记录的:
-
是否可以及时发现问题
-
出现问题期间对业务的影响
-
出现问题后多久可以恢复
-
恢复期间业务是否丢失

在这个阶段我们往往能够发现一些可靠性和稳定性的缺陷,这时候需要反馈给数据库侧进行优化,从而确保上线后的稳定和可靠。
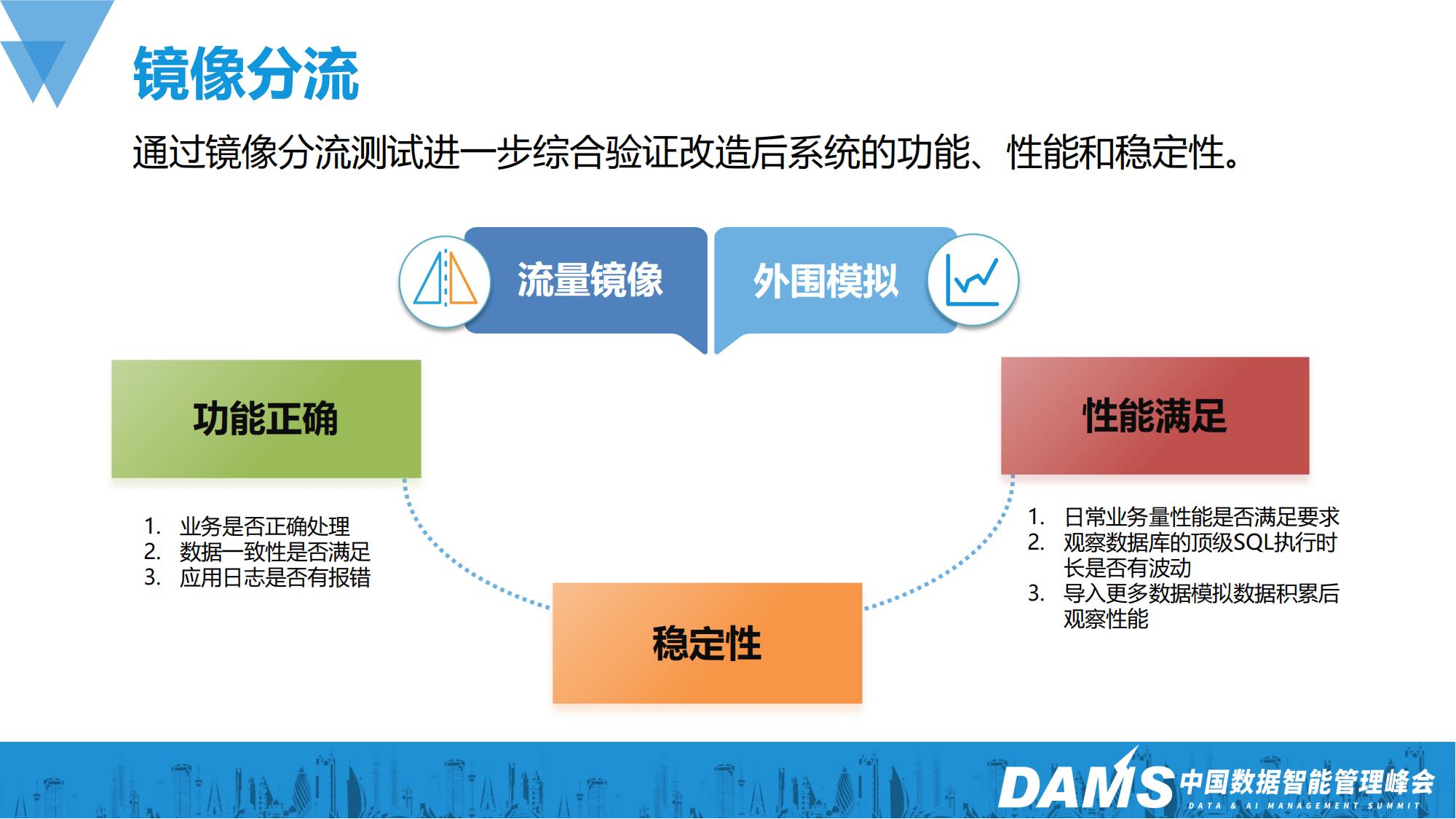
11、镜像分流前面的并行测试只是将SQL做了抽取,还不足以做到端到端的验证。所以我们选择通过镜像分流来进一步综合验证改造后场景的功能、性能和稳定性。
基础的2个技术点是流量镜像和外围模拟:镜像机制复制了100%的生产流量给迁移后的目标系统和数据库;模拟器确保镜像数据不会影响到周边系统的交互。
这期间我们从功能、性能以及稳定性三个方面来进行持续观察。
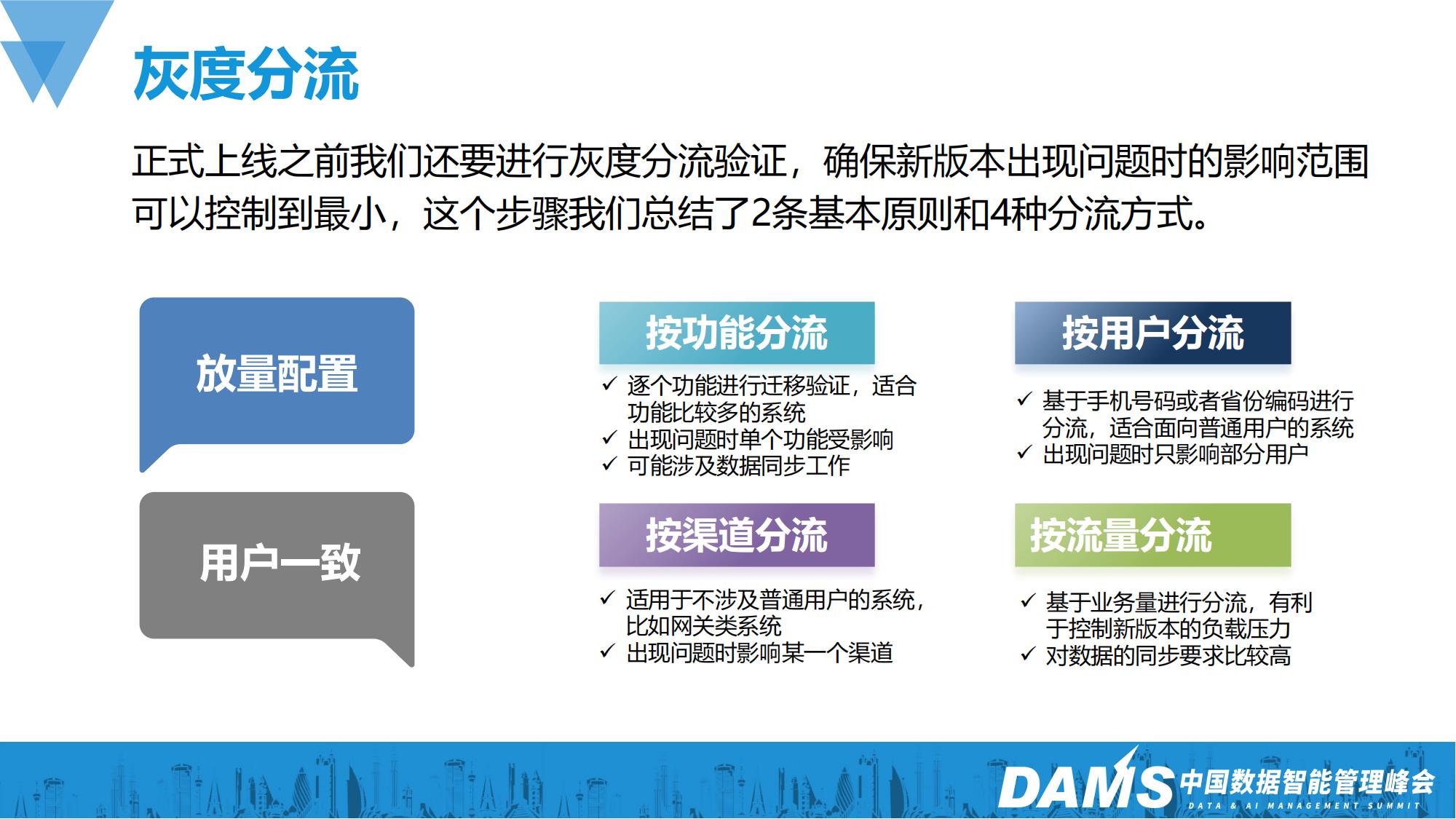
在正式上线之前我们还要进行灰度分流验证,确保新版本出现问题时的影响范围可以控制到最小。这里我们总结了2条基本原则和4种分流方式:
首先是放量配置和用户一致:放量配置是说需要给运维或者运营人员提供一个可视化的配置功能,确保流量是逐步放给新系统的,也可以避免手工调整分流配置时出现低级错误;用户一致是要在方案设计时考虑同一用户始终落在同一个版本上,尽量避免出现插入数据在新数据库,查询数据在旧数据库等类似的情况出现。
分流方式大致可以分为4种:按功能分流、按用户分流、按渠道分流、按流量分流。
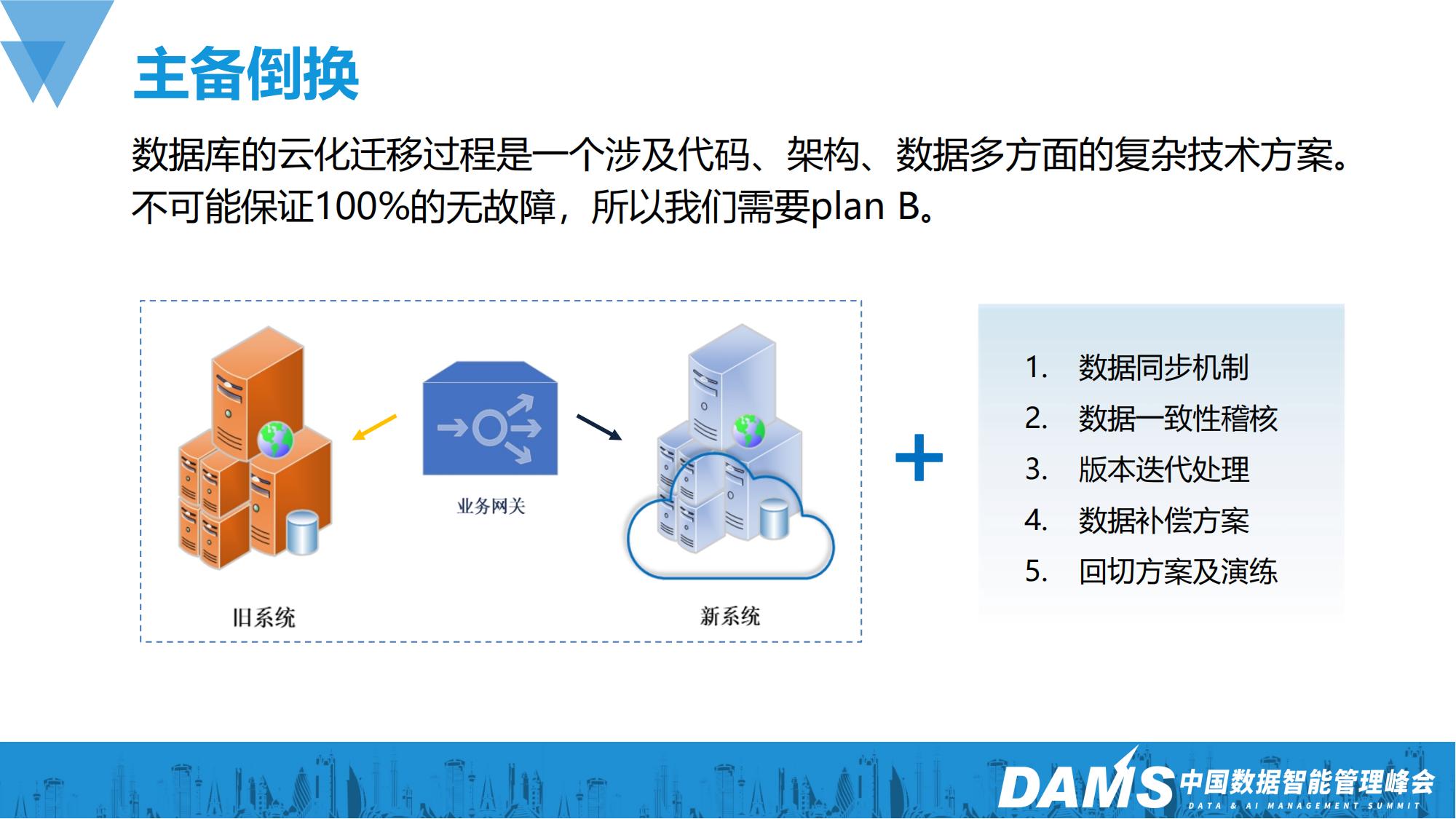
到了最后一步其实我们已经完全上线到生产了,只是数据库的云化迁移过程是一个涉及代码、架构、数据多方面的复杂方案。我们不可能保证100%的无故障,所以我们还需要plan B。这个方案也不复杂,我们在业务网关上做好切换机制,同时再考虑一下下图右侧这几个关键点,就能够做出一个可靠的B计划来。
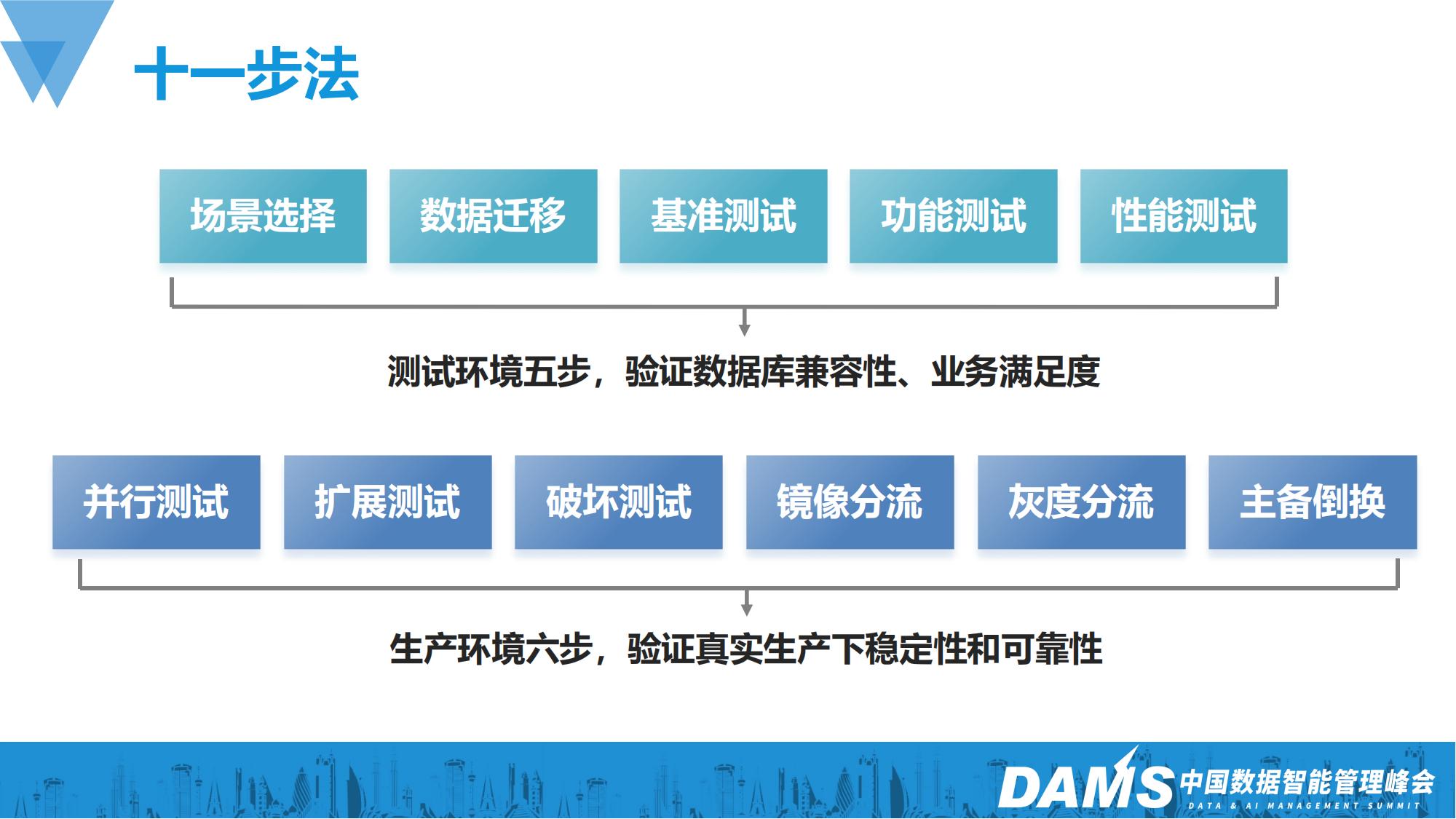
最后我们根据实践的过程,总结了云环境下数据库迁移的十一步法。
下面2张图是我们对各个阶段的总结,包括了每个阶段的主要工作、重点事项以及最终的输出交付,希望能够给大家带来一些启发和帮助。


三、未来的计划和展望
1、未来计划最后说一下我们对未来的一些展望,希望可以围绕更多、更复杂的业务场景开展数据库的云化迁移工作,完善我们的十一步法的同时,也不断打磨数据库产品。

一个好的数据库产品不仅仅需要优秀的设计,更需要复杂多变的场景来打磨,只有这样才能够真正做到核心能力的自主掌控。
2、展望将来关于数据库产品,我们也有一些期盼:
希望我们的一些实践经验能够对大家有所帮助,也希望大家多提意见和建议,帮助我们完善方案和理论。
↓点这里可下载本文PPT,提取码:7g4q
阅读原文
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK