

The curious case of Cassandra Reads
source link: https://blog.knoldus.com/the-curious-case-of-cassandra-reads/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
The curious case of Cassandra Reads
Reading Time: 5 minutes
In our previous blog, we discovered how Cassandra handles its write queries. Now it’s time to understand how it ensures all the read requests are fulfilled. Let’s first have an overall view of Cassandra. Apache Cassandra is a free and open-source distributed NoSQL database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure.
Now Let’s jump to how Cassandra handles the read queries.
Reading in Cassandra
In Cassandra, it is easy to read data because clients can connect to any node in the cluster to perform reads, without having to know whether a particular node acts as a replica for that data.
If a client connects to a node that doesn’t have the data it’s trying to read, the node it’s connected to will act as coordinator node to read the data from a node that does have it, identified by token ranges.

Cassandra reads are mostly dependent on Partitioners and Snitches :
Partitioner
A partitioner determines how data is distributed across the nodes in the cluster.Basically, a partitioner is a function for deriving a token representing a row from its partition key, typically by hashing. Each row of data is then distributed across the cluster by the value of the token.
Default Partitioner: Murmer3Partitioner (uniformly distributes data across the cluster based on MurmurHash hash values)
Snitches
Snitches determine the proximity of Cassandra nodes. It determines which datacenters and racks nodes belong to It gathers network topology information and tries to route the request efficiently.
By default, a dynamic snitch layer is used for all snitches. It monitors the read performance and routes the request away from the slow nodes. It’s recommended to keep dynamic snitches enabled for most deployments.
Cassandra Interactions on the Read path
The read path in Cassandra database is little more complicated (actually way more complicated) than the write path, as there are a variety of components involved in reading data from a Cassandra database.
To satisfy a read, Cassandra must combine results from the active memtable and potentially multiple SSTables.
Cassandra processes data at several stages on the read path to discover where the data is stored, starting with the data in the memtable and finishing with SSTables.
Interactions between nodes on the read path
The read path begins when a client initiates a read query to the coordinator node. As on the write path, the coordinator uses the partitioner to determine the replicas and checks that there are enough replicas up to satisfy the requested consistency level. If the coordinator is not itself a replica, the coordinator then sends a read request to the fastest replica, as determined by the dynamic snitch. The coordinator node also sends a digest request to the other replicas. A digest request is similar to a standard read request, except the replicas return a digest, or hash, of the requested data.
The coordinator calculates the digest hash for data returned from the fastest replica
and compares it to the digests returned from the other replicas. If the digests are consistent, and the desired consistency level has been met, then the data from the fastest
replica can be returned. If the digests are not consistent, then the coordinator must
perform a read repair, which we will discuss later.
Interactions within a node on the read path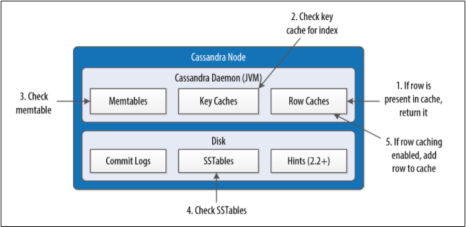
Cassandra processes data at several stages on the read path to discover where the data is stored, starting with the data in the memtable and finishing with SSTables:
- Check row cache, if enabled
- Checks partition key cache, if enabled( Goes directly to the compression offset map if a partition key is found in the partition key cache, or checks the partition summary if not If the partition summary is checked, then the partition index is accessed)
- Check the memtable
- Fetches the data from the SSTable on disk
- If Row cache is enabled the data is added to the row cache
Read Repair
 Read-repair is a lazy mechanism in Cassandra that ensures that the data you request from the database is accurate and consistent.
Read-repair is a lazy mechanism in Cassandra that ensures that the data you request from the database is accurate and consistent.
For every read request, the coordinator node requests to all the node having the data requested by the client. All nodes return the data which client requested for.
The most recent data is sent to the client and asynchronously, the coordinator identifies any replicas that return obsolete data and issues a read-repair request to each of these replicas to update their data based on the latest data.
Note : If read consistency > 1 , the read repair is done before responding to client. Else, it is taken as a background process.
Optimizing Reads in Cassandra
Cassandra implements several features to optimize the SSTable search: key caching, Bloom filters and summary indexes :
- Bloom filters :
– A Bloom filter is a data structure designed to tell you, rapidly and memory-efficiently, whether an element is present in the SS Table or not.
– Bloom filters are stored in files alongside the SSTable data files.Cassandra also maintains a copy of Bloom filters in memory.
– The Bloom filter does not guarantee that the SSTable contains the
partition, only that it might contain it. - Key caching :
– The key cache is implemented as a map structure in which the keys are a combination of the SSTable file descriptor and partition key, and the values are offset locations into SSTable files.
– The key cache helps to eliminate seeks within SSTable files for frequently accessed data, because the data can be read directly. - Partition Summary and Partition Indexes :
– Cassandra uses a two-level index stored on disk in order to locate the offset. The first level index is the partition summary, which is used to obtain an offset for searching for the partition key within the second level index, the partition index.
– The partition index is where the offset into the SSTable for the partition key is stored.
– If the offset for the partition key is found, Cassandra accesses the SSTable at the specified offset and starts reading data.
To Know more about how Cassandra handles its read operations, you can refer to the Cassandra Official Documentation.
In this blog, we tried to understand how Cassandra fulfills a read request and how it tries to optimize the fetching of the data.
I hope you enjoyed reading this article. Stay tuned for more. 
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK