

适合AI场景的调度器 - Gang-Schedule
source link: https://xigang.github.io/2019/02/17/gang-scheduler/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Do it right or don't do it at all
适合AI场景的调度器 - Gang-Schedule
使用kubeflow结合kubernetes进行大规模分布式训练时,由于AI场景下对任务的调度需要: all or nothing, multi-tenant task queue, task priority, preemption,gpu affinity等条件,但是kubernetes默认的调度器对这些条件还没有完全的支持,幸运的是kubernetes社区孵化了一个适合训练的调度器kube-batch。
AI 场景下的调度有何不同?
- gang-schedule(all or nothing)
- multi-tenant task queue
- task priority
- preemption
- gpu affinity
第一点比较重要的就是gang-schedule。gang-schedule是什么概念? 用用户提交一个 batch job, 这个batch job 包含100个任务,要不这100个任务全部调度成功,要么一个都调度不成功。这种all or nothing调度场景,就被称作:gang-schedule,通常用于集群资源不足的场景,比如 AI 场景下调用GPU资源。
第二点就是AI场景需要提供多住户的任务队列。因为GPU资源是非常宝贵的,经常会出现集群资源不可用的情况。当不可用时,需要有租户或者任务的优先级,并且每个租户需要有对应的优先级队列,队列里面又有任务优先级,设计不同的优先级住户之间的资源抢占,或者同一个租户不同优先级任务的资源抢占。另外GPU Affinity的调度能力,可以提高模型的训练性能,也是scheduler需要考虑的事情。
kube-batch 调度器介绍
kube-batch是一个为kubernetes实现批量任务调度的一个调度器,主要用于机器学习,大数据,HPC等场景。
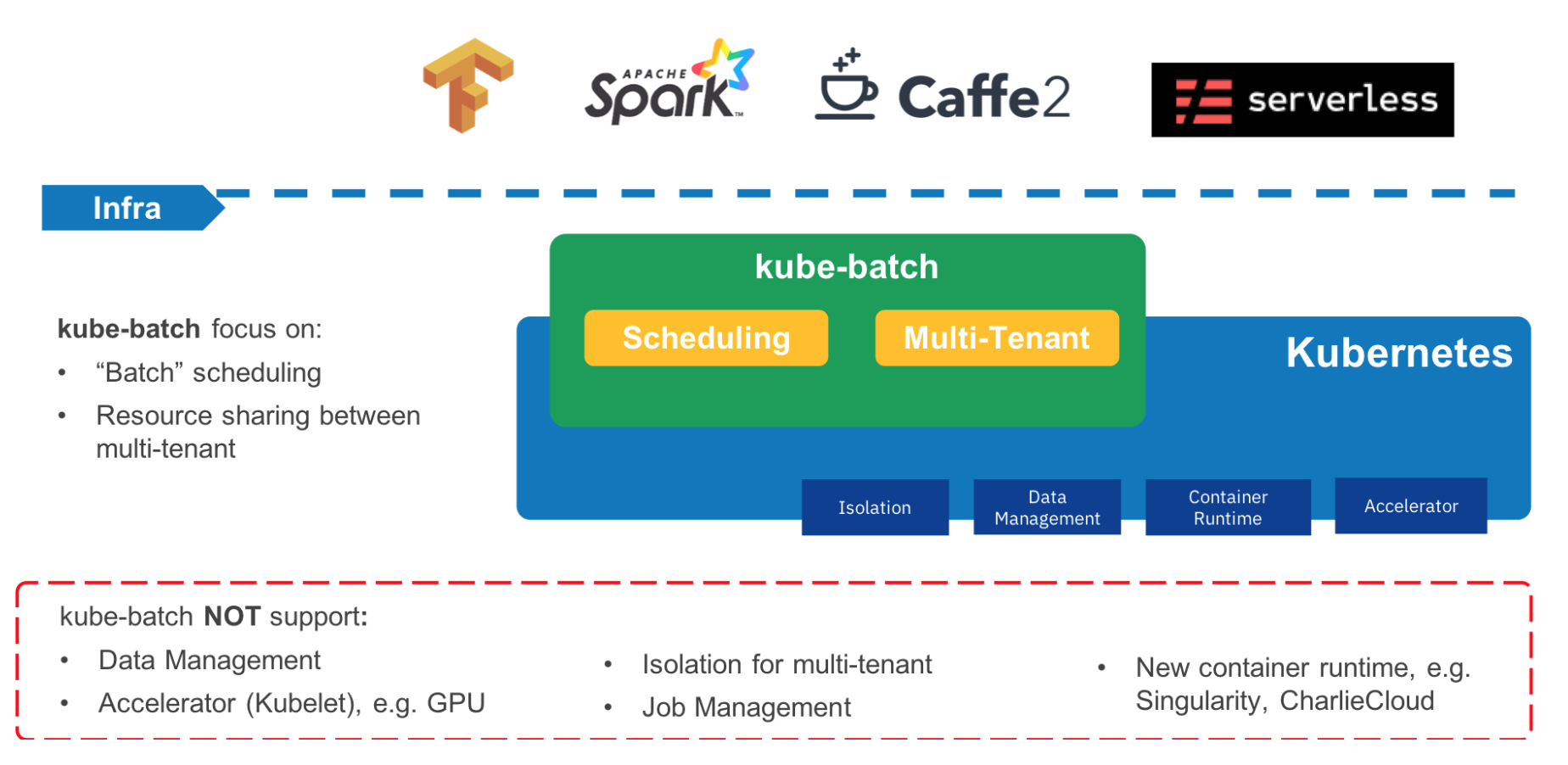
为了使用gang-scheduling,需要在kubernetes集群提前安装kube-batch调度器。具体的安装步骤查看官方教程: kube-batch install
安装完成kube-batch并且测试没有问题,便可以在基于Kubeflow的分布式训练中指定该调度器(kube-batch)。
注意:
Take tf-operator for example, enable gang-scheduling in tf-operator by setting true to --enable-gang-scheduling flag.
好了,所有的准备工作做完之后,可以使用kube-batch去调度一个任务,为了让任务使用kube-batch,还需要在yaml文件中指定schedulerName参数为kube-batch。下面是详细的例子:
apiVersion: "kubeflow.org/v1beta1"
kind: "TFJob"
metadata:
name: "tfjob-gang-scheduling"
spec:
tfReplicaSpecs:
Worker:
replicas: 1
template:
spec:
schedulerName: kube-batch
containers:
- args:
- python
- tf_cnn_benchmarks.py
- --batch_size=32
- --model=resnet50
- --variable_update=parameter_server
- --flush_stdout=true
- --num_gpus=1
- --local_parameter_device=cpu
- --device=gpu
- --data_format=NHWC
image: gcr.io/kubeflow/tf-benchmarks-gpu:v20171202-bdab599-dirty-284af3
name: tensorflow
resources:
limits:
nvidia.com/gpu: 1
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
restartPolicy: OnFailure
PS:
replicas: 1
template:
spec:
schedulerName: kube-batch
containers:
- args:
- python
- tf_cnn_benchmarks.py
- --batch_size=32
- --model=resnet50
- --variable_update=parameter_server
- --flush_stdout=true
- --num_gpus=1
- --local_parameter_device=cpu
- --device=cpu
- --data_format=NHWC
image: gcr.io/kubeflow/tf-benchmarks-cpu:v20171202-bdab599-dirty-284af3
name: tensorflow
resources:
limits:
cpu: '1'
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
restartPolicy: OnFailure
在设计AI Paas平台时,除了功能跑起来只是一个开始,在测试过程中随之而来的,网络,存储,调度等等用影响性能的问题,都需要花费大量的精力去解决,基于kube-batch便可以基本解决在调度过程中,kubernetes默认调度器的不足,来达到all or nothing的目的。
Recommend
-
31
空心菜 读完需要 7 速读仅需 3 分钟 /Docker 怎么用 / Docker 不是万能的,我们不能够期盼在 Docker 容器中运行所有的东西。符合 Heroku 公司 12...
-
7
原文链接:https://lwn.net/Articles/799454/ 本文记录了2019年的 Linux Plumbers 会议上针对核调度(core scheduling)的一些讨论,涉及实现、使用场景、优劣势,以及一些未来可能的改进方向。 一些内核的新特性会非常受社区欢迎,另一些则不然。...
-
5
邬贺铨:5G to C 架构并不都适合5G to B场景_5G 大家说_中国IDC圈 邬贺铨:5G to C 架构并不都适合5G to B场景 6月17日,在未来网络大会上,中国工程院院士邬贺铨讲道,传统基于现场级工控设备的工业互联网层级多、标准...
-
9
Kubernetes的应用场景以及适合哪些企业 责任编辑:cres 作者:Rudy De Busscher | 2021-08-06 10:38:05 原创文章 企业网D1Net 人们需要了解什么是Kubernetes,以及它是否真的是一种最佳选择,还要...
-
6
KubeSphere 3.2.0 发布:带来面向 AI 场景的 GPU 调度与更灵活的网关发布于 6 分钟前现如今最热门的服务器端技术是什么?答案大概就是云原生!Kub...
-
6
查询快到起飞的 ES,真的适合你的应用场景吗? 李猛 2022-01-04 10:04:39 作者介绍...
-
6
什么场景(不)适合使用Lambda-51CTO.COM 什么场景(不)适合使用Lambda 作者:Thoughtworks洞见 2022-03-23 09:52:28 开发 Lambda并非...
-
11
多活数据中心链路智能调度场景 1.背景与挑战
-
7
我们一直提到,每一个线程都有一个线程栈,也称为系统栈;协程g0就运行在这个栈上,而且协程g0执行的就是调度逻辑schedule。Go语言调度器是如何管理以及调度这些成千上万个协程呢?和操作系统一样,维护着可运行队列和阻塞队列吗,有没有所谓的按照时间片或者是优...
-
4
关于Linux中作业调度 crond 和 systemd.timer 使用场景的一些笔记 我们承受所有的不幸,皆因我们无法独处 ——叔本华 分享一些 systemd.timer 相关的笔记 博文内容涉及: system...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK