

OPPO大数据离线计算平台架构演进
source link: https://my.oschina.net/u/4273516/blog/5288175
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

OPPO大数据离线计算平台架构演进 - OPPO数智技术的个人空间 - OSCHINA - 中文开源技术交流社区
1 前言
OPPO的大数据离线计算发展,经历了哪些阶段?在生产中遇到哪些经典的大数据问题?我们是怎么解决的,从中有哪些架构上的升级演进?未来的OPPO离线平台有哪些方向规划?今天会给大家一一揭秘。
2 OPPO大数据离线计算发展历史
2.1 大数据行业发展阶段
一家公司的技术发展,离不开整个行业的发展背景。我们简短回归一下大数据行业的发展,通过谷歌的BigData搜索热度我们大概分一下大数据的近十几年的进程。
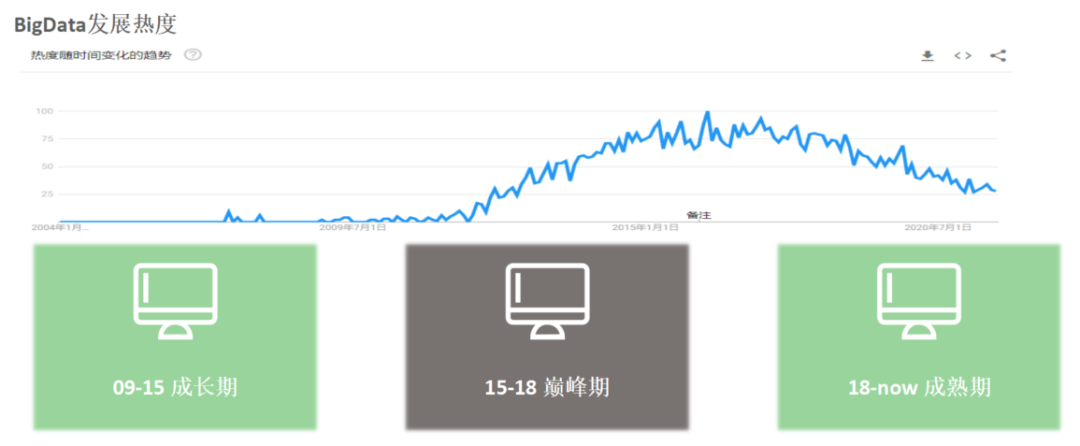 图1:google bigdata 关键词搜索热度
上面的热度曲线来看,大数据发展大概可以分成三个阶段:
成长期
(2009-2015),这段时期主要代表是Hadoop1.0以及相关生态的快速成长;
巅峰期
(2015-2018),这段时期主要代表是Hadoop2.0以及Spark迅速成为大数据基础架构和计算引擎的行业事实基础底座;
成熟期
(2018-now),这段时间主要代表是Spark、Flink等计算引擎以及OLAP引擎的繁荣;
从这个热度曲线看,有一个小疑问,近两年大数据热度迅速下降,那么什么技术在近几年成为热度最大的技术?
2.2 OPPO 大数据发展阶段
OPPO大数据起步比整个行业稍晚,我们先看一下发展时间轴:
图1:google bigdata 关键词搜索热度
上面的热度曲线来看,大数据发展大概可以分成三个阶段:
成长期
(2009-2015),这段时期主要代表是Hadoop1.0以及相关生态的快速成长;
巅峰期
(2015-2018),这段时期主要代表是Hadoop2.0以及Spark迅速成为大数据基础架构和计算引擎的行业事实基础底座;
成熟期
(2018-now),这段时间主要代表是Spark、Flink等计算引擎以及OLAP引擎的繁荣;
从这个热度曲线看,有一个小疑问,近两年大数据热度迅速下降,那么什么技术在近几年成为热度最大的技术?
2.2 OPPO 大数据发展阶段
OPPO大数据起步比整个行业稍晚,我们先看一下发展时间轴:
 2013年,大数据巅峰期之初,OPPO开始搭建大数据集群和团队,使用Hadoop 0.20版本(Hadoop1.0)。
2015年,使用CDH服务,集群初具规模。
2018年,自建集群,已经达到中等规模,使用Hive作为计算引擎。
2020年,开始大规模从Hive向Spark计算引擎迁移SQL作业。
2021年,从大数据资源层和计算层升级改造。
OPPO的大数据发展可以总结成两个阶段:
发展期:2013-2018年,OPPO大数据从无到有,慢慢成长,计算节点规模从0扩展到中等规模;
繁荣期:2018-现在,三年大数据快速发展,技术上从hadoop1.0升级到hadoop2.0,计算引擎由hive升级到spark;自研技术以及架构升级解决集群规模膨胀后常见问题;
3 大数据计算领域常见问题
大数据领域有很多经典的问题,我们这里选取了生产环境遇到五种典型的问题来说明;我们将围绕这五种问题展开,介绍OPPO大数据离线计算的架构演进。
2013年,大数据巅峰期之初,OPPO开始搭建大数据集群和团队,使用Hadoop 0.20版本(Hadoop1.0)。
2015年,使用CDH服务,集群初具规模。
2018年,自建集群,已经达到中等规模,使用Hive作为计算引擎。
2020年,开始大规模从Hive向Spark计算引擎迁移SQL作业。
2021年,从大数据资源层和计算层升级改造。
OPPO的大数据发展可以总结成两个阶段:
发展期:2013-2018年,OPPO大数据从无到有,慢慢成长,计算节点规模从0扩展到中等规模;
繁荣期:2018-现在,三年大数据快速发展,技术上从hadoop1.0升级到hadoop2.0,计算引擎由hive升级到spark;自研技术以及架构升级解决集群规模膨胀后常见问题;
3 大数据计算领域常见问题
大数据领域有很多经典的问题,我们这里选取了生产环境遇到五种典型的问题来说明;我们将围绕这五种问题展开,介绍OPPO大数据离线计算的架构演进。

3.1 Shuffle问题 Shuffle是大数据计算的关键一环,shuffle 对任务的性能和稳定性都产生重要的影响。有以下几点因素,导致shuffle性能变慢和稳定性变差: spill&merge :多次磁盘io;map在写shuffle数据的过程中,会将内存的数据按照一定大小刷到磁盘,最后做sort和merge,会产生多次磁盘io. 磁盘随机读 :每个reduce只读取每个map输出的部分数据,导致在map端磁盘随机读。 过多的RPC连接 :假设有M个map,N个reduce,shuffle过程要建立MxN个RPC连接(考虑多个map可能在同一台机器,这个MxN是最大连接数)。 Shuffle问题不仅会影响任务的性能和稳定性,同时在大数据任务上云的过程中,shuffle数据的承接也成为上云的阻碍。云上资源的动态回收,需要等待下游读取上游的shuffle数据之后才能安全的释放资源,否则会导致shuffle失败。 3.2 小文件问题 小文件问题几乎是大数据平台必须面对的问题,小文件主要有两点危害: 1)小文件过多对HDFS存储的NameNode节点产生比较大的压力。 2)小文件过多,会对下游任务并发度产生影响,每个小文件生成一个map任务读数据,造成过多的任务生成,同时会有过多的碎片读。 小文件问题产生的原因有哪些? 1)任务数据量小同时写入的并发又比较大,比较典型的场景是动态分区。 2)数据倾斜,数据总量可能比较大,但是有数据倾斜,只有部分文件比较大,其他的文件都比较小。 3.3 多集群资源协调问题 随着业务发展,集群迅速扩张,单个集群的规模越来越大,同时,集群数量也扩展到多个。面对多集群的环境如何做好资源协调是我们面临的一个挑战。 首先看下多集群的优劣势: 优势:各个集群资源隔离,风险隔离,部分业务独享资源。 劣势:资源隔离,形成资源孤岛,失去大集群优势,资源利用率不均匀。 例如,对比我们线上集群 vcore资源使用情况:
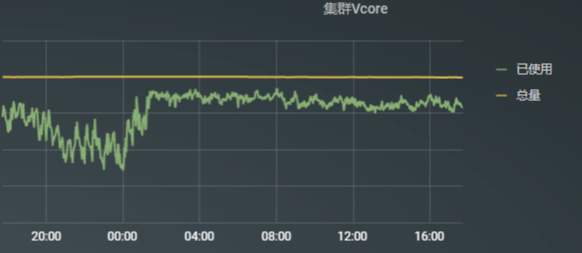 图4:
集群1 24小时资源使用情况
图4:
集群1 24小时资源使用情况
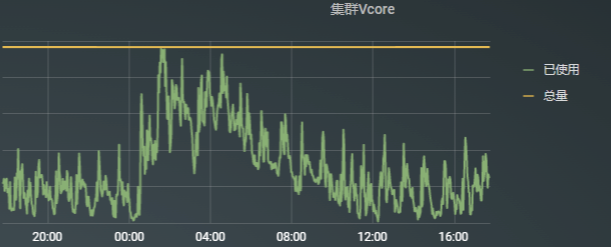 图5:集群2 24小时资源使用情况
从资源使用情况看,集群2的资源利用率明显低于集群1,这就造成集群之间负载不均匀,资源利用率低下,资源浪费。
3.4 元数据扩展问题
由于历史原因,元数据在集群搭建初期选取单个MySQL实例存储。随着业务数据快速增长的同时,元数据也在飞快增长。这种单点的元数据存储,已经成为整个大数据系统的稳定性和性能的最大的隐患。同时,在过去的一年,我们的集群因为元数据服务问题,曾经出现两次比较大的故障。在此背景下,对元数据的扩展,成为紧急且重要的事项。
问题来了,选择什么样的扩展方案?
调研业界的几种方案,包括:
1)使用TiDB等分布式数据库;
2)从新规划元数据的分布,拆分到不同的MySQL;
3)使用Waggle-Dance作为元数据的路由层;
在选型的过程中,我们考虑尽可能对用户影响最小,做到对用户透明,平滑扩展;
3.5 计算统一入口
在我们将sql任务从hive迁移到spark引擎的同时,我们遇到的首要问题是:SparkSQL 任务能不能像HiveSQL一样很方便的通过beeline或者jdbc提交?原生的spark是通过spark自带的submit脚本提交任务,这种方式显然不适合大规模生产应用。
所以,我们提出统一计算入口的目标。
不仅统一SparkSQL任务提交,同时 jar包任务也要统一起来。
以上五个问题是我们在生产环境不断的碰壁,不断的探索,总结出来的典型的问题。当然,大数据计算领域还有更多的典型问题,限于文章篇幅,这里仅针对这五个问题探讨。
4 OPPO离线计算平台解决之道
针对前面提到的五个问题,我们介绍一下OPPO的解决方案,同时也是我们的离线计算平台的架构演进历程。
4.1 OPPO Remote Shuffle Service
图5:集群2 24小时资源使用情况
从资源使用情况看,集群2的资源利用率明显低于集群1,这就造成集群之间负载不均匀,资源利用率低下,资源浪费。
3.4 元数据扩展问题
由于历史原因,元数据在集群搭建初期选取单个MySQL实例存储。随着业务数据快速增长的同时,元数据也在飞快增长。这种单点的元数据存储,已经成为整个大数据系统的稳定性和性能的最大的隐患。同时,在过去的一年,我们的集群因为元数据服务问题,曾经出现两次比较大的故障。在此背景下,对元数据的扩展,成为紧急且重要的事项。
问题来了,选择什么样的扩展方案?
调研业界的几种方案,包括:
1)使用TiDB等分布式数据库;
2)从新规划元数据的分布,拆分到不同的MySQL;
3)使用Waggle-Dance作为元数据的路由层;
在选型的过程中,我们考虑尽可能对用户影响最小,做到对用户透明,平滑扩展;
3.5 计算统一入口
在我们将sql任务从hive迁移到spark引擎的同时,我们遇到的首要问题是:SparkSQL 任务能不能像HiveSQL一样很方便的通过beeline或者jdbc提交?原生的spark是通过spark自带的submit脚本提交任务,这种方式显然不适合大规模生产应用。
所以,我们提出统一计算入口的目标。
不仅统一SparkSQL任务提交,同时 jar包任务也要统一起来。
以上五个问题是我们在生产环境不断的碰壁,不断的探索,总结出来的典型的问题。当然,大数据计算领域还有更多的典型问题,限于文章篇幅,这里仅针对这五个问题探讨。
4 OPPO离线计算平台解决之道
针对前面提到的五个问题,我们介绍一下OPPO的解决方案,同时也是我们的离线计算平台的架构演进历程。
4.1 OPPO Remote Shuffle Service
为了解决shuffle的性能和稳定性问题,同时,为大数据任务上云做铺垫,我们自研了OPPO Remote Shuffle Service(ORS2)。
4.1.1 ORS2在大数据平台整体架构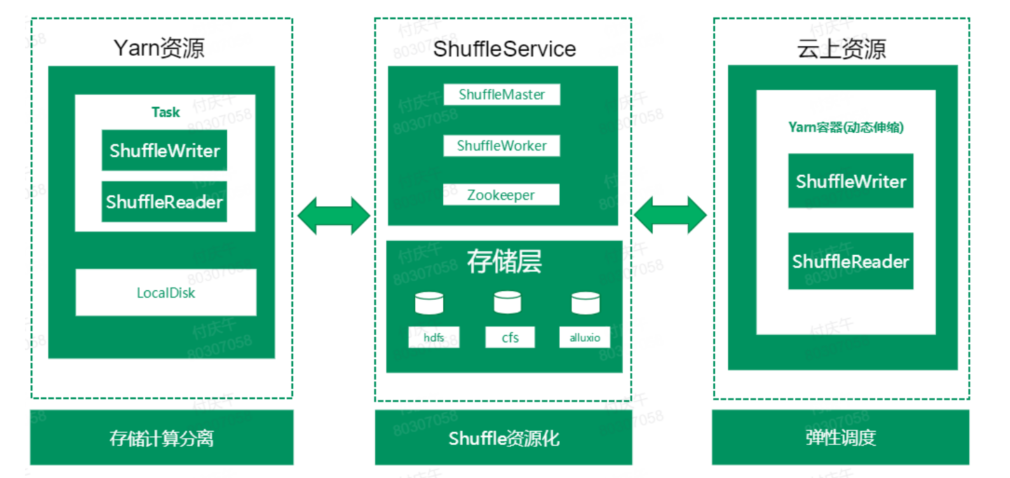 图6:ORS2在云数融合架构图
有了ORS2,不仅将spark任务的shuffle过程从本地磁盘解耦,同时承接了云上资源的大数据计算任务的shuffle数据。
从ShuffleService本身来说,独立出来一个service角色,负责整合计算任务的shuffle数据。同时,ShuffleService本身可以部署到云上资源,动态扩缩容,将shuffle资源化。整体架构上看,ShuffleService 分成两层,上面Service层,主要有ShuffleMaster和ShuffleWorker两种角色。
ShuffleMaster负责ShuffleWorker的管理,监控,分配。ShuffleWorker将自身的相关信息上报给ShuffleMaster,master对worker的健康做管理;提供worker加黑放黑、punish等管理操作。分配策略可定制,比如:Random策略、Roundrobin策略、LoadBalance策略。
ShuffleWorker负责汇集数据,将相同分区的数据写入到一个文件,Reduce读分区数据的过程变成顺序读,避免了随机读以及MxN次的RPC通信。
在存储层,我们的ShuffleService可以灵活选取不同的分布式存储文件系统,分区文件的管理以及稳定性保障交由分布式文件系统保障。目前支持HDFS、CFS、Alluxio三种分布式文件系统接口。可以根据不同的需求使用不同的存储介质,例如,小任务作业或者对性能要求比较高的作业,可以考虑使用内存shuffle;对于稳定性要求比较高,作业重要性也比较高的作业,可以选取ssd;对性能要求不高的低级别作业,可以选取SATA存储;在性能和成本之间寻求最佳的平衡。
4.1.2 ORS2的核心架构
图6:ORS2在云数融合架构图
有了ORS2,不仅将spark任务的shuffle过程从本地磁盘解耦,同时承接了云上资源的大数据计算任务的shuffle数据。
从ShuffleService本身来说,独立出来一个service角色,负责整合计算任务的shuffle数据。同时,ShuffleService本身可以部署到云上资源,动态扩缩容,将shuffle资源化。整体架构上看,ShuffleService 分成两层,上面Service层,主要有ShuffleMaster和ShuffleWorker两种角色。
ShuffleMaster负责ShuffleWorker的管理,监控,分配。ShuffleWorker将自身的相关信息上报给ShuffleMaster,master对worker的健康做管理;提供worker加黑放黑、punish等管理操作。分配策略可定制,比如:Random策略、Roundrobin策略、LoadBalance策略。
ShuffleWorker负责汇集数据,将相同分区的数据写入到一个文件,Reduce读分区数据的过程变成顺序读,避免了随机读以及MxN次的RPC通信。
在存储层,我们的ShuffleService可以灵活选取不同的分布式存储文件系统,分区文件的管理以及稳定性保障交由分布式文件系统保障。目前支持HDFS、CFS、Alluxio三种分布式文件系统接口。可以根据不同的需求使用不同的存储介质,例如,小任务作业或者对性能要求比较高的作业,可以考虑使用内存shuffle;对于稳定性要求比较高,作业重要性也比较高的作业,可以选取ssd;对性能要求不高的低级别作业,可以选取SATA存储;在性能和成本之间寻求最佳的平衡。
4.1.2 ORS2的核心架构
 图7:ORS2 核心架构图
从ShuffleService的核心架构来看,分为三个阶段:
ShuffleWriter:
Map任务使用ShuffleWriter完成数据的聚集和发送,采用多线程异步发送;使用堆外内存,内存管理统一交由spark原生内存管理系统,避免额外内存开销,降低OOM风险。为了提高发送数据的稳定性,我们设计了中间切换目的ShuffleWorker的共,当正在发送的ShuffleWorker出现故障,Writer端可以立即切换目的Worker,继续发送数据。
ShuffleWorker:
图7:ORS2 核心架构图
从ShuffleService的核心架构来看,分为三个阶段:
ShuffleWriter:
Map任务使用ShuffleWriter完成数据的聚集和发送,采用多线程异步发送;使用堆外内存,内存管理统一交由spark原生内存管理系统,避免额外内存开销,降低OOM风险。为了提高发送数据的稳定性,我们设计了中间切换目的ShuffleWorker的共,当正在发送的ShuffleWorker出现故障,Writer端可以立即切换目的Worker,继续发送数据。
ShuffleWorker:
Shuffle负责将数据汇集,同时将数据落到分布式文件系统中。ShuffleWorker的性能和稳定性,我们做了很多设计,包括流量控制,定制的线程模型,消息解析定制,checksum机制等。 ShuffleReader: ShuffleReader直接从分布式文件系统读取数据,不经过ShuffleWorker。为匹配不同的存储系统读数据的特性,Reader端我们做了Pipeline read优化。 经过以上的多种优化,我们使用线上大作业测试,ShuffleService能够加速30%左右。 4.2 OPPO小文件解决方案 小文件问题的解决,我们希望对用户是透明的,不需要用户介入,引擎侧通过修改配置即可解决。在了解了Spark写入文件的机制后,我们自研了透明的解决小文件方案。 Spark任务在最后写入数据的过程,目前有三种 Commit方式: (V1,V2,S3 commit),我们以V1版本的Commit方式介绍一下我们的小文件解决方案。
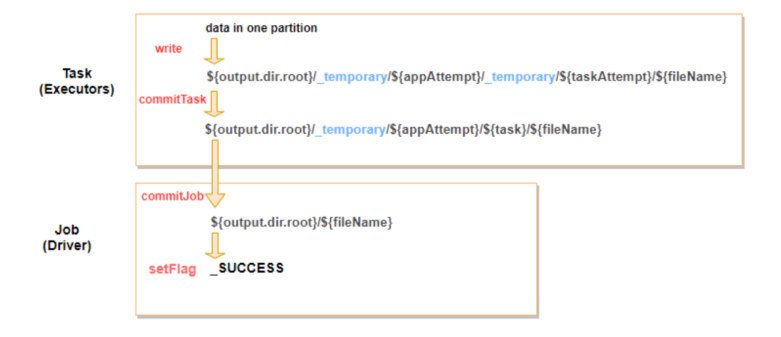
图8:Spark Commit V1 示意图
Spark的V1版本Commit,分为两个阶段,Task侧的commit和Driver侧的commit。Task侧的commit,负责将该Task本身产生的文件挪到Task级的临时目录;Driver侧的commit将整所有的Task commit的临时目录挪到最终的目录,最后创建_SUCCESS文件,标志作业运行成功。 我们实现了自己的CommitProtocol,在Driver commit阶段的前段加入合并小文件的操作,扫描: output.dir.roottemporary/output.dir.roottemporary/{appAttempt}/ 目录下面的小文件,然后生成对应的合并小文件作业。合并完小文件,再调用原来的commit,将合并后的文件挪到${output.dir.root}/ 目录下。 图9:Spark Commit 阶段合并小文件示意图
这种方式巧妙的避免显性的提交额外的作业对结果数据合并,同时,在Driver commit挪动结果文件的时候挪动的文件数成数量级的降低,减少文件挪动的时间消耗。目前,我们已经在国内和海外环境全部上线小文件合并。
4.3 OPPO Yarn Router-多集群资源协调
前面我们提到多集群的主要的缺点是导致资源孤岛,集群的负载不均衡,整体资源利用率低。下面我们抽象出简单的示意图:
图9:Spark Commit 阶段合并小文件示意图
这种方式巧妙的避免显性的提交额外的作业对结果数据合并,同时,在Driver commit挪动结果文件的时候挪动的文件数成数量级的降低,减少文件挪动的时间消耗。目前,我们已经在国内和海外环境全部上线小文件合并。
4.3 OPPO Yarn Router-多集群资源协调
前面我们提到多集群的主要的缺点是导致资源孤岛,集群的负载不均衡,整体资源利用率低。下面我们抽象出简单的示意图:
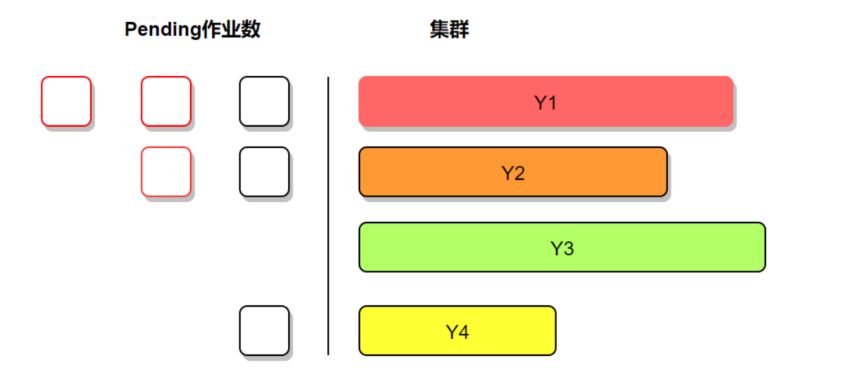 图10:多集群资源使用不均衡示意图
从示意图上看,左边代表pending作业,右边代表集群资源情况;长度代表资源量多少,颜色代表资源负载,越深代表负载越高。很明显可以看出来,目前的各个集群资源负载不均衡,同时pending作业情况也跟集群的资源使用比成比例,比如Y1集群的资源负载很高,但是pending作业也很高,Y3集群资源很空闲,但是这个集群没有作业pending。
这种问题,我们如何解决?
我们引入了社区的Yarn Router功能,用户提交的任务到router,router再分配到各个yarn集群,实现联邦调度。
社区版本的Router策略比较单一,只能通过简单的比例分配路由到不同的集群。这种方式只能简单实现路由作业的功能,对集群的资源使用和作业运行情况没有感知,所以,做出来的决策依然会导致集群负载不均匀,例如:
图10:多集群资源使用不均衡示意图
从示意图上看,左边代表pending作业,右边代表集群资源情况;长度代表资源量多少,颜色代表资源负载,越深代表负载越高。很明显可以看出来,目前的各个集群资源负载不均衡,同时pending作业情况也跟集群的资源使用比成比例,比如Y1集群的资源负载很高,但是pending作业也很高,Y3集群资源很空闲,但是这个集群没有作业pending。
这种问题,我们如何解决?
我们引入了社区的Yarn Router功能,用户提交的任务到router,router再分配到各个yarn集群,实现联邦调度。
社区版本的Router策略比较单一,只能通过简单的比例分配路由到不同的集群。这种方式只能简单实现路由作业的功能,对集群的资源使用和作业运行情况没有感知,所以,做出来的决策依然会导致集群负载不均匀,例如:

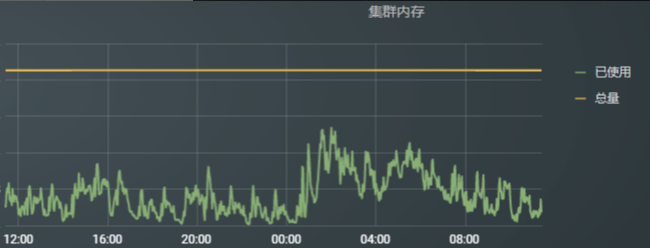
 图13:OPPO Yarn Router
总体上看,有了一个全局视野的Router角色,多集群场景下,充分发挥多集群的优势,同时避免多集群的不足。未来,我们计划赋予Router更多的能力,不仅用来解决作业pending,提升资源利用率。还将从作业运行效率方面做更多的工作,让作业和计算、存储资源做更好的匹配,让计算更有价值。
4.4 元数据扩展利器——Waggle Dance
Waggle Dance为Hive MetaStore提供路由代理,是Apache 开源项目。Waggle Dance完全兼容HiveMetaStore原生接口,无缝接入现有系统,实现对用户透明升级,这也是我们选择该技术方案的主要原因。
Waggle Dance的工作原理是将现有的Hive数据库按照库名分别路由到不同组的Metastore,每一组Metastore对应独立的MySQL DB 实例,实现从物理上隔离元数据。
图13:OPPO Yarn Router
总体上看,有了一个全局视野的Router角色,多集群场景下,充分发挥多集群的优势,同时避免多集群的不足。未来,我们计划赋予Router更多的能力,不仅用来解决作业pending,提升资源利用率。还将从作业运行效率方面做更多的工作,让作业和计算、存储资源做更好的匹配,让计算更有价值。
4.4 元数据扩展利器——Waggle Dance
Waggle Dance为Hive MetaStore提供路由代理,是Apache 开源项目。Waggle Dance完全兼容HiveMetaStore原生接口,无缝接入现有系统,实现对用户透明升级,这也是我们选择该技术方案的主要原因。
Waggle Dance的工作原理是将现有的Hive数据库按照库名分别路由到不同组的Metastore,每一组Metastore对应独立的MySQL DB 实例,实现从物理上隔离元数据。
 图14:Waggle-Dance元数据切分示意图
上面的示意图,左边是原始的HiveMetastore架构,从架构图本身来看,整体架构存在明显的单点问题,同时数据交换流程不够优美。使用Waggle Dance升级后,整体架构更加清晰,更加优美。Waggle Dance作为元数据交换的“总线”,将上层计算引擎的请求按照库名路由到对应的Metastore。
图14:Waggle-Dance元数据切分示意图
上面的示意图,左边是原始的HiveMetastore架构,从架构图本身来看,整体架构存在明显的单点问题,同时数据交换流程不够优美。使用Waggle Dance升级后,整体架构更加清晰,更加优美。Waggle Dance作为元数据交换的“总线”,将上层计算引擎的请求按照库名路由到对应的Metastore。
我们在做线上切分元数据实际操作过程中,总体Metastore停机时间在10分钟以内。我们对Waggle Dance做了定制优化,加了数据缓存层,提升路由效率;同时,将Waggle Dance与我们的内部管理系统整合,提供界面话的元数据管理服务。 4.5 计算统一入口——Olivia 为了解决Spark任务提交入口的问题,我们还是将目光投向了开源社区,发现Livy可以很好的解决SparkSQL的任务提交。 Livy是一个提交Spark任务的REST服务,可以通过多种途径向Livy提交作业,比如我们常用的是beeline提交sql任务,还有其他的比如网络接口提交; 任务提交到Livy后,Livy向Yarn集群提交任务,Livy client生成Spark Context,拉起Driver。Livy可以同时管理多个Spark Context,支持batch和interactive两种提交模式,功能基本类似HiveServer。
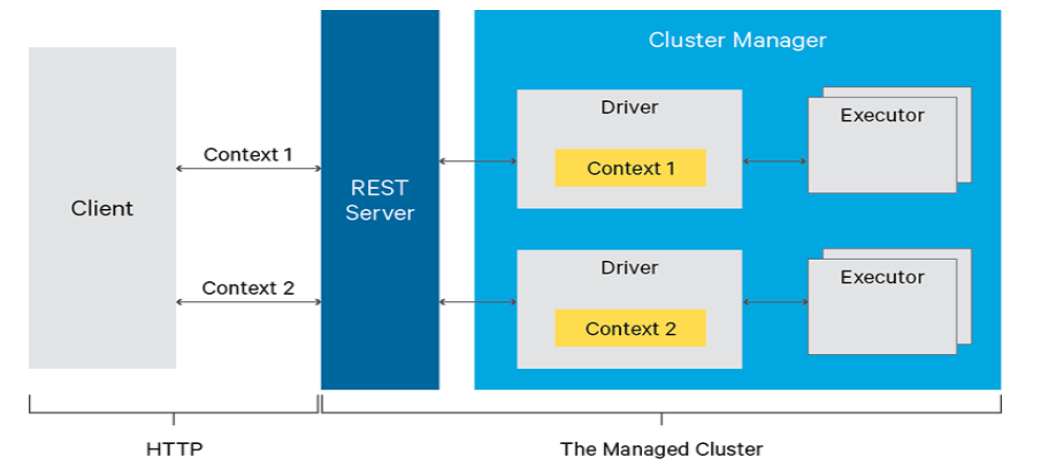 图15:Livy架构示意图(引自官网)
Livy能满足我们的需求吗?我们先看Livy本身有哪些问题。
我们总结的Livy主要有三个缺陷:
缺乏高可用:Livy Server进程重启或者服务掉线,上面管理的Spark Context session将会失控,导致任务失败。
缺乏负载均衡:Livy Server的任务分配是一个随机过程,随机选取zk命名空间的一个Livy Server,这种随机过程会导致一组Livy Server负载不均衡。
对spark submit作业支持不足:对于spark submit提交的jar包任务,目前支持的不完善。
图15:Livy架构示意图(引自官网)
Livy能满足我们的需求吗?我们先看Livy本身有哪些问题。
我们总结的Livy主要有三个缺陷:
缺乏高可用:Livy Server进程重启或者服务掉线,上面管理的Spark Context session将会失控,导致任务失败。
缺乏负载均衡:Livy Server的任务分配是一个随机过程,随机选取zk命名空间的一个Livy Server,这种随机过程会导致一组Livy Server负载不均衡。
对spark submit作业支持不足:对于spark submit提交的jar包任务,目前支持的不完善。
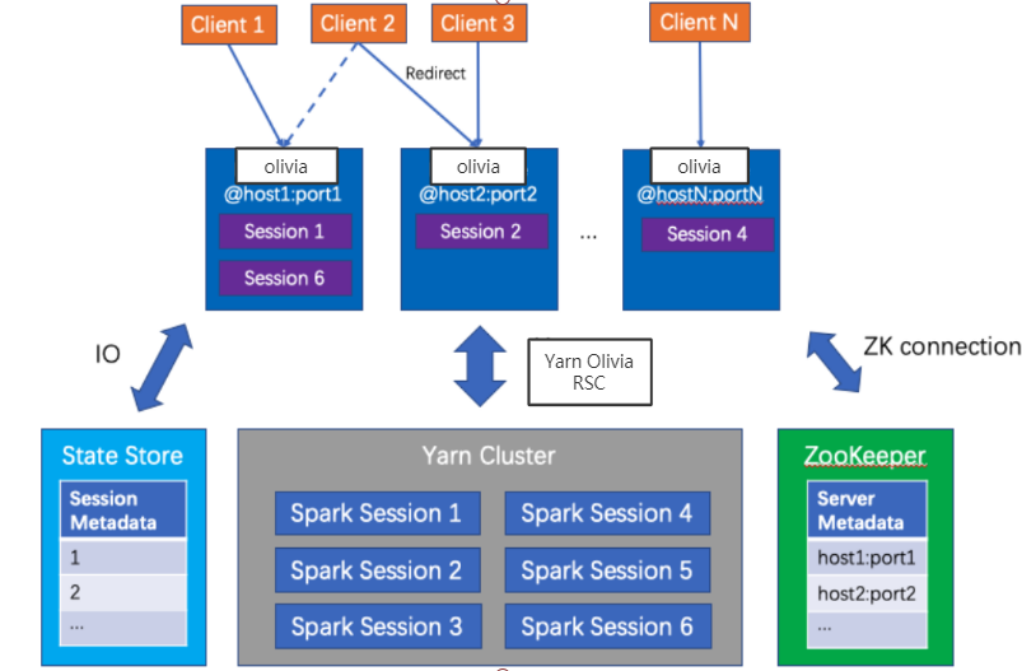 图16:Olivia 架构示意图
针对上面的几个问题,我们基于Livy自研了Olivia,是一种高可用、负载均衡、同时支持spark submit jar包任务以及python脚本的计算统一入口。
Olivia使用域名提交作业,用户不用感知具体是哪台Server支持作业提交和管理。后台使用一致性Hash实现负载均衡,如果有Server上下线,也会自动完成负载均衡。对于故障转移,我们使用zk存储spark session信息,某个server出现问题,对应管理的session会自动转移到其他的server管理。对于Spark submit任务的支持,我们新增一个Olivia client角色,该client会自动将jar包以及python脚本上传到集群,方便Olivia Server提交作业。
4.6 总揽
前面介绍了我们对五种问题的解决方案,串联起来就是我们今天的主题:大数据离线计算平台的演进。
在这一章的最后,我们从整理看一下目前的离线计算架构视图。
图16:Olivia 架构示意图
针对上面的几个问题,我们基于Livy自研了Olivia,是一种高可用、负载均衡、同时支持spark submit jar包任务以及python脚本的计算统一入口。
Olivia使用域名提交作业,用户不用感知具体是哪台Server支持作业提交和管理。后台使用一致性Hash实现负载均衡,如果有Server上下线,也会自动完成负载均衡。对于故障转移,我们使用zk存储spark session信息,某个server出现问题,对应管理的session会自动转移到其他的server管理。对于Spark submit任务的支持,我们新增一个Olivia client角色,该client会自动将jar包以及python脚本上传到集群,方便Olivia Server提交作业。
4.6 总揽
前面介绍了我们对五种问题的解决方案,串联起来就是我们今天的主题:大数据离线计算平台的演进。
在这一章的最后,我们从整理看一下目前的离线计算架构视图。
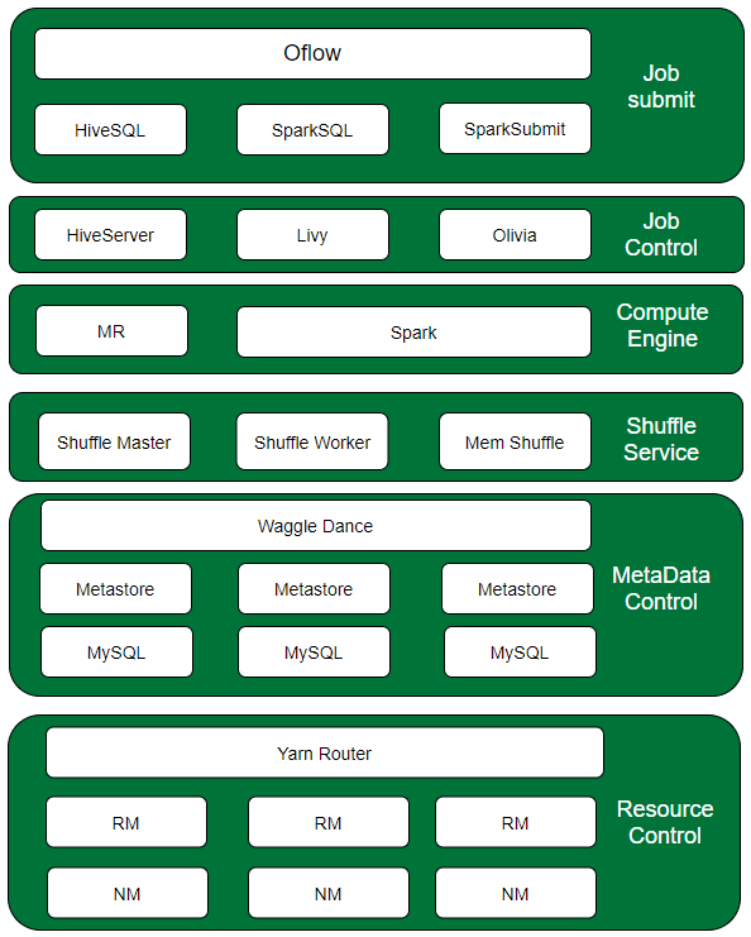 图17:OPPO 大数据平台架构示意图
由上到下,我们可以抽象出六层,分别是:
图17:OPPO 大数据平台架构示意图
由上到下,我们可以抽象出六层,分别是:
Job Submit:这层主要是我们的离线作业调度Oflow,完成任务的定时调度,dag 管理,作业运行管理;核心功能就是实现了任务的提交。 Job Control:这层主要有HiveServer、Livy、Olivia这些任务控制组件,负责任务向集群提交和管控。 Compute Engine:引擎层主要使用Spark和MR。 Shuffle Service:这层是为Spark引擎提供shuffle 服务,后续Shuffle Service也将承接Flink引擎的 shuffle 数据。 MetaData Control:Waggle Dance和MetaStore以及底层的MySQL形成我们的元数据控制层,使用了Waggle Dance是我们的元数据管理更灵活。 Resource Control:资源控制层,就是我们的计算资源,主要由Yarn Router来控制各个集群的作业路由,各个Yarn集群完成资源的管理和作业运行。我们不仅在Router上有自研的策略,我们在RM资源调度上也探索了更多的调度模式,比如:动态标签、资源限售、更智能的抢占调度。 5 OPPO离线计算平台发展展望 技术的发展演进一直在进行,OPPO的离线计算未来是什么样子,这也是我们一直在思索的命题。我们考虑从纵向和横向两个方向都要兼顾。
5.1 横向思索 横向上,考虑与其他资源和计算模式打通融合。 我们正在与弹性计算团队合作,将大数据与云上资源打通,利用线上服务和大数据计算两种模式的错峰特性,充分利用公司现有资源,实现在离线混合调度。 同时,我们跟实时计算团队合作,探索更适合实时计算的调度模式。 5.2 纵向思索 纵向上,我们思考如何将现有架构做的更深入,更精细化。 大HBO概念:我们在探索一种大HBO概念的架构升级,从Oflow 到 yarn调度,再到spark引擎以及OLAP引擎的HBO优化。核心是提供更快、更自动、成本更低的计算。 Shuffle的继续演进,思考后续Shuffle的演进,与引擎作业调度更加融合,提供spark 批计算的Pipeline计算形式。同时,考虑在 Shuffle Service加入Shuffle Sorter角色,将sort过程挪到Shuffle Service层,将spark sort算子并行化,加速sort操作。 最后,感谢大家的关注,欢迎大家多多交流大数据计算的技术思考。 作者简介 David OPPO高级数据平台工程师 主要负责OPPO大数据离线计算方向架构设计开发,曾在国内一线大厂参与自研大数据计算引擎开发。对大数据平台建设有比较丰富的经验。 本文版权归OPPO公司所有,如需转载请在后台留言联系。
本文分享自微信公众号 - OPPO互联网技术(OPPO_tech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
-
50
-
44
本文根据DBAplus社群第153期线上分享整理而成, 文末还有好书送哦~ 讲师介绍...
-
12
本文根据贝壳找房资深工程师肖赞老师在 2020 年"面向 AI 技术的工程架构实践"大会上的演讲速记整理而成。 1 贝壳 OLAP 平台架的构演化历程
-
21
贝壳找房小程序至今为止已经拥有了近2亿的用户,团队正在在朝着贝壳人的宗旨迈进,给这个行业创造更多的价值,努力成为一个能够服务2亿家...
-
4
演进式架构支持跨多个维度的引导性增量变更。 ——《演进式架构》 这是《演进式架构》这本书第一章第一节对“演进式架构”的作用做出的简洁定义,也就是说演进式架构便是持续架构,因为在架构这件事上没有最终状态,它会随着软件开发体系的不...
-
2
云上应用系统数据存储架构演进发布于 1 分钟前简介: 回顾过去二十年的技术发展,整个应用形态和技术架构发生了很大的升级换代,而任何技术的发展都与几个重要的变...
-
4
OPPO大数据计算集群资源调度架构演进 - OPPO数智技术的个人空间 - OSCHINA - 中文开源技术交流社区 OSCHINA 2021 中国开源开发者问卷 >>>&...
-
4
本文根据Li Qingxin老师在“2021 vivo开发者大会"现场演讲内容整理而成。公众号回复【2021VDC】获取互联网技术分会场议题相关资料。一、vivo推送平台介绍1.1 从产品和技术角度了解...
-
9
Markdown Revision 1; Date: 2018/11/11 Editor: 梁志成 Co...
-
8
汽车之家电商系统架构演进与平台化架构实践 原创 作者: ...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK