

疯狂试探mysql单表insert极限:已实现每秒插入8.5w条数据
source link: https://blog.csdn.net/qq_33709582/article/details/121745749
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
疯狂试探mysql单表insert极限:已实现每秒插入8.5w条数据
很多同学都有这样的困扰:
- 工作中项目的数据量不大,遇不到sql优化的场景:单表就几万,我优化个der啊;
- 业务对性能要求不高,远远没达到性能瓶颈:咱这项目又不是不能跑,优化个der啊;
确实,如果你的项目体量不大,不管是数据层还是应用层,都很难接触到性能优化
我们可以自己造数据啊
今天我带来了一个demo,不仅让你能把多线程运用到实际项目中,还能用它往数据库造测试数据,让你体验下大数据量的表优化
定个小目标,今天造它一亿条数据
首先搞清楚,不要为了用技术而用技术,技术一定是为了实现需求:
- 插入一亿条数据,这是需求;
- 为了提高效率,运用多线程异步插入,这是方案;
1、为了尽可能模拟真实场景,我们new个对象
靠phone和createTime俩字段,能大大降低数据重复度,抛开别的字段不说,这俩字段基本能保证没有重复数据,所以我们最终的数据很真实,没有一条是重复的,而且,最后还能通过createTime来统计每秒插入条数,nice~
public class Person {
private Long id;
private String name;//姓名
private Long phone;//电话
private BigDecimal salary;//薪水
private String company;//公司
private Integer ifSingle;//是否单身
private Integer sex;//性别
private String address;//住址
private LocalDateTime createTime;
private String createUser;
}
2、想要插的更快,我们得使用MyISAM引擎,并且要主键自增(不知道为什么的兄弟私聊我或者评论区留言,咱们今天主题不是讲数据库本身)
CREATE TABLE `person` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`phone` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`salary` decimal(10,2) NOT NULL,
`company` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`if_single` tinyint NOT NULL,
`sex` tinyint NOT NULL,
`address` varchar(225) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`create_time` datetime NOT NULL,
`create_user` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=30170001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
3、为了模拟真实数据,我们得用到一些枚举值和随机算法
部分属性枚举值:
private String[] names = {"黄某人", "负债程序猿", "谭sir", "郭德纲", "蔡徐鸡", "蔡徐老母鸡", "李狗蛋", "铁蛋", "赵铁柱"};
private String[] addrs = {"二仙桥", "成华大道", "春熙路", "锦里", "宽窄巷子", "双子塔", "天府大道", "软件园", "熊猫大道", "交子大道"};
private String[] companys = {"京东", "腾讯", "百度", "小米", "米哈游", "网易", "字节跳动", "美团", "蚂蚁", "完美世界"};
随机获取person
private Person getPerson() {
Person person = Person.builder()
.name(names[random.nextInt(names.length)])
.phone(18800000000L + random.nextInt(88888888))
.salary(new BigDecimal(random.nextInt(99999)))
.company(companys[random.nextInt(companys.length)])
.ifSingle(random.nextInt(2))
.sex(random.nextInt(2))
.address("四川省成都市" + addrs[random.nextInt(addrs.length)])
.createUser(names[random.nextInt(names.length)]).build();
return person;
}
5、orm层用的mybatis
<insert id="insertList" parameterType="com.example.demos.entity.Person">
insert into person (name, phone, salary, company, if_single, sex, address, create_time, create_user)
values
<foreach collection="list" item="item" separator=",">
(#{item.name}, #{item.phone}, #{item.salary}, #{item.company}, #{item.ifSingle}, #{item.sex},
#{item.address}, now(), #{item.createUser})
</foreach>
</insert>
准备工作完成,开始写核心逻辑
思路:
1、想要拉高插入效率,肯定不能够一条一条插了,必须得foreach批量插入,经测试,单次批量3w条以下时性价比最高,并且不用修改mysql配置
2、文章开头说了,得开多个线程异步插入,我们先把应用层效率拉满,mysql顶不顶得住
3、我们不可能单次提交一亿次insert,这谁顶得住,而且大量插入操作会很耗时,短时间内完不成,我们不可能一直守着,我的方案是用定时任务
。。。
算了屁话不多说,直接上demo
@Component
public class PersonService {
private static final int THREAD_COUNT = 10;
@Autowired
private PersonMapper personMapper;
@Autowired
private ThreadPoolExecutor executor;
private AtomicInteger integer = new AtomicInteger();
private Random random = new Random();
private String[] names = {"黄某人", "负债程序猿", "谭sir", "郭德纲", "蔡徐鸡", "蔡徐母鸡", "李狗蛋", "铁蛋", "赵铁柱"};
private String[] addrs = {"二仙桥", "成华大道", "春熙路", "锦里", "宽窄巷子", "双子塔", "天府大道", "软件园", "熊猫大道", "交子大道"};
private String[] companys = {"京东", "腾讯", "百度", "小米", "米哈游", "网易", "字节跳动", "美团", "蚂蚁", "完美世界"};
@Scheduled(cron = "0/15 * * * * ?")
public void insertList() {
System.out.println("本轮任务开始,总任务数:" + THREAD_COUNT);
long start = System.currentTimeMillis();
AtomicLong end = new AtomicLong();
for (int i = 0; i < THREAD_COUNT; i++) {
Thread thread = new Thread(() -> {
try {
for (int j = 0; j < 20; j++) {
personMapper.insertList(getPersonList(5000));
}
end.set(System.currentTimeMillis());
System.out.println("本轮任务耗时:" + (end.get() - start) + "____已执行" + integer.addAndGet(1) + "个任务" + "____当前队列任务数" + executor.getQueue().size());
} catch (Exception e) {
e.printStackTrace();
}
});
try {
executor.execute(thread);
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
private ArrayList<Person> getPersonList(int count) {
ArrayList<Person> persons = new ArrayList<>(count);
for (int i = 0; i < count; i++) {
persons.add(getPerson());
}
return persons;
}
private Person getPerson() {
Person person = Person.builder()
.name(names[random.nextInt(names.length)])
.phone(18800000000L + random.nextInt(88888888))
.salary(new BigDecimal(random.nextInt(99999)))
.company(companys[random.nextInt(companys.length)])
.ifSingle(random.nextInt(2))
.sex(random.nextInt(2))
.address("四川省成都市" + addrs[random.nextInt(addrs.length)])
.createUser(names[random.nextInt(names.length)]).build();
return person;
}
}
我的线程池配置,我电脑配置比较拉跨,只有12个线程…
@Configuration
public class ThreadPoolExecutorConfig {
@Bean
public ThreadPoolExecutor threadPoolExecutor() {
ThreadPoolExecutor executor = new ThreadPoolExecutor(10, 12, 5, TimeUnit.SECONDS, new ArrayBlockingQueue<>(100));
executor.allowCoreThreadTimeOut(true);
return executor;
}
}
测试
现在表是空的
项目跑起来

已经在开始插了,挂在后台让它自己跑吧。。。
25 minutes later ~
看下数据库
已经插入了1.04亿条数据,需求完成
第一条数据是15:54:15开始的,耗时大概25min
再来从数据库中看下一秒插入多少条,直接count某秒即可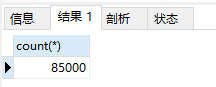
一秒8.5w,嘎嘎快
来说下demo中核心的几个点:
- 关于线程:我的cpu只有十二个线程,所以核心线程设置的10,留两个线程打杂;
- 关于线程中的逻辑:每个线程有20次循环,每次循环插入5000条;
- 关于获取随机对象:我没有统计创建对象的耗时,因为即使是创建100w个对象,但是这都是内存操作,跟insert这种io操作比起来,耗时几乎可以忽略,我就不测试了,你可以自己试试;
- 关于效率:你们看到的版本(10 * 20 * 5000)是我只优化过几次的半成品,这种搭配最终的效率是100w条耗时12.5s,效率肯定不是最高的,但基本够用了;
可以看看之前的测试效率记录
10 * 100 * 1000:22-23s
10 * 50 * 2000:19-20s
10 * 10 * 10000 :18-20s
可以参考记录进行深度调优
哦对了,想效率更快的话,表不要建索引,insert时维护索引也是一笔不小的开销
完整demo给你们放码云了
博主贼贴心,clone下来改下jdbc就能跑,记得建表~
ok我话说完
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK