

Optimising data retrieval using Realm Swift query
source link: https://blog.kiprosh.com/optimizing-data-retrieval-using-realm-swift-query/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Optimizing data retrieval using Realm Swift query
Realm is a fast database that allows inserting thousands of records in a second. But sometimes, it can be a bit tedious and time-consuming if the code is written inefficiently. Here in this article, we will look into how the Realm Swift query helps to optimize the data retrieval and hence speed up our application.
In one of my iOS applications, I recently came across a scenario, in which I had to perform insertion of a few contacts into my app's database, and by a few, I mean a few thousand! I was getting these records from an API and was saving them on the local to utilize offline. For that purpose, I needed to check whether a contact exists in the database before inserting it. This process was taking more time than expected as some users had more than 15000 contacts.
I need to create a function that checks if a contact is already present in the database or not. It should return all the contacts which are not present in the database in array format. For example, if I pass three contacts, Siri, Tom & Smith into function and Siri already exists in the database, it should return Tom & Smith.
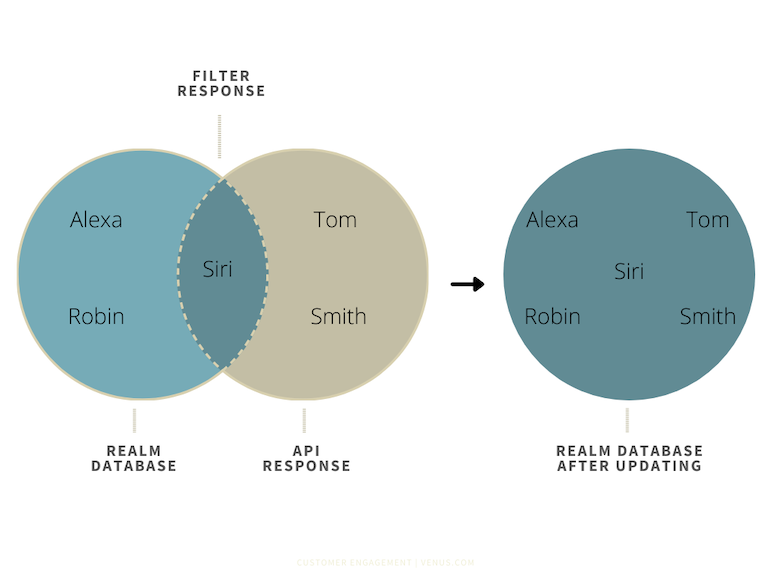
To achieve the above, consider the following two approaches:
Let’s consider a scenario where I am performing operations on a database that has 6500 records and trying to add 500 more records to it. Out of these 500, 499 records are already present in the database, i.e they are duplicates. So I need to filter out these 499 records and then insert that one unique record inside the database.
Approach 1
func nonExistingContactList(contacts: List<Contact>) -> [Contact] {
let realm = try! Realm()
let filteredContacts: [Contact] = contacts.filter { (contact) -> Bool in
let existContact = realm.objects(Contact.self).first(where: { (oldContact) -> Bool in
return oldContact.id == contact.id
})
return existContact == nil
}
return filteredContacts
}print("Contacts before filtering", contactList.count)
print(Date())
let filteredContacts = nonExistingContactList(contacts: contactList)
print(Date())
print("Contacts after filtering", filteredContacts.count)
Output:
Contacts before filtering 500
2021-08-11 13:00:08 +0000
2021-08-11 13:00:48 +0000
Contacts after filtering 1
It took around 48 seconds to filter contacts.
Approach 2
The most dangerous phrase in the language is "we've always done it this way"
As it was taking too much time, I tried various approaches, and then I finally found my hands-on Realm Extension Function.
extension List where Iterator.Element: Object {
/** Retrieves the list of a given object which does not contain any instance in the Realm database.
- returns: A list of object that has no instance of the given primary key.
*/
func excludedObjects() -> LazyFilterCollection<List> {
let realm = try! Realm()
let filteredList = filter { object in
let objectType = type(of: object)
let primaryKey = object.value(forKey: objectType.primaryKey() ?? String())
return realm.object(ofType: objectType, forPrimaryKey: primaryKey) == nil
}
return filteredList
}
}print("Contacts before filtering", contactList.count)
print(Date())
let filteredContacts = contactList.excludedObjects()
print(Date())
print("Contacts after filtering", filteredContacts.count)
Output:
Contacts before filtering 500
2021-08-11 13:03:41 +0000
2021-08-11 13:03:41 +0000
Contacts after filtering 1
It took around less than one second to filter contacts.
What did I do differently?
In the first approach, the conventional one, I fetched the contact object from the list, extracted its id which is of string type, and then compared this id with the id's of existing contact objects. This inefficiency was due to the process of first getting the contact object and then using its id for comparison.
In the second approach, I made use of the Realm extension function and eliminated the use of the contact object. The realm function is used in extension to filter details. It performs operations using the RLMRealm instance. This helped to reduce the time to filter out the existing & non-existing contacts from the list. That's what made the difference.
Realm is a zero-copy architecture database. It performs all operations using the RLMRealm instance. RLMRealm represents a Realm database and it's cached internally. That's why it completes complex queries in microseconds.
Hope the above examples helped you to understand how Realm functions can be used to optimize the queries.
References:-
Recommend
-
45
Neural Architecture Search Powered by Swarm Intelligence :ant: DeepSwarm DeepSwarm is an open-source li...
-
10
Introduction I really love reflection. Reflection is a technique used for obtaining type information at run-time. It’s not only that, with reflection is possible to examine and change information of objects, to generate (technical...
-
18
Optimising The Performance Of Power Query Merges In Power BI, Part 5: Cross Joins In a late addition to the series of posts that I started
-
8
Optimising The Performance Of Power Query Merges In Power BI, Part 4: Table.Join And Other Join Algorithms In the
-
9
Technical Articles
-
5
Using Realm and Charts with Swift 3 in iOS 10I have had few challenges when I was reading some tutorials of how to use Realm and Charts together. Mostly because all the tutorials that I have found was for Swift 2 and older...
-
11
Efficient storage and retrieval of two-dimensional data in the JVM database advertisements I need to store 2 di...
-
14
Realm is a mobile database that runs directly inside phones, tablets or wearables. This repository holds the source code for the iOS, macOS, tvOS & watchOS versions of Realm Swift & Realm Objective-C. Why Use Realm
-
7
Preface As a fellow member of this archiving project, I was given some challenging requirements to enhance the existing z-reports to provide the option to select the data from a)live b)archive. In this blog, I tried to document all the po...
-
6
Optimising the throughput of async sinks using a custom RateLimitingStrategy 25 Nov 2022 Hong Liang Teoh Introduction When designing a Flink data processing job, one of the key...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK