

The Curious History of the Schwartz-Zippel Lemma
source link: https://rjlipton.wpcomstaging.com/2009/11/30/the-curious-history-of-the-schwartz-zippel-lemma/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

The Curious History of the Schwartz-Zippel Lemma
On the discovery that randomness helps exponentially for identity testing
Jack Schwartz was one of most famous mathematicians who worked in the theory of linear operators, his three volume series with Nelson Dunford is a classic. Yet he found the time, the creative energy, and the problem solving ability to make seminal contributions to many diverse areas of science—not just mathematics or theory—but science in general. He worked on, for example: parallel computers, the design of new programming languages, fundamental questions of computational theory, and many more wonderful problems from a wide range of areas. He is greatly missed by our community as well as all of science.
Today I want to talk about the Schwartz-Zippel Lemma. Or the Schwartz-Zippel-DeMillo-Lipton Lemma. Or the Schwartz Lemma. The whole point is to discuss the curious history of this simple, but very useful result.
First, I thought that I would give one short story that shows somethings about the character of Jack. When he was working on a problem, that problem was the most important thing in the world. He had tremendous ability to focus. He also was often ahead of his time with the problems he worked on; his important work on parallel computers was way before it was the critical problem it is today.
Once at a POPL meeting Jack Schwartz was scheduled to talk right before lunch. His talk was on his favorite topic at the time: the programming language SETL. He loved to talk about SETL, I think it was one of his favorite topics of all times—but that is just my opinion.
In those days there were no parallel sessions, and the speaker right before Jack gave a very short talk. That left almost a double period before lunch. Right after being introduced, Schwartz said with a smile,
“well I guess I have almost an hour then
”
There was a slight sigh in the room—it was clear that most people would have preferred a short break before lunch.
And he took it. But Jack’s talk was wonderful, and we soon forgot about lunch, and learned the cool ideas that had gone into his latest creation. I never used SETL, but I could see the importance of the ideas. Like his work on parallel computations it was perhaps ahead of the field. SETL was a very high level language compared with the popular ones of then, and seemed almost too big a jump.
SETL was, as you might have guessed, a set based language that had an important influence over later languages. Guido van Rossum, considered the principal author of Python, said of SETL:
Python’s predecessor, ABC, was inspired by SETL — Lambert Meertens spent a year with the SETL group at NYU before coming up with the final ABC design!
Thus, SETL is the grand parent of Python, which shows the importance of the ideas that Jack had years earlier. By the way many others worked on SETL and I do not wish to minimize their contributions—perhaps I will discuss that another day.
Let’s now turn to the history of probably one of simplest results Schwartz ever published—but perhaps in the top few of his most cited papers.
Identity Testing
The fundamental question of identity testing is: given a polynomial 


total points.
About thirty years ago, the idea arose to a number of people that perhaps a random algorithm could do much better. Indeed randomness helps exponentially here.
The intuition is really simple: Suppose that you envision 


The issue, as computer scientists, is of course that we cannot pick points from the cube; we can only pick points from a discrete set, and the cube is continuous. Said another way: we cannot pick points of infinite precision, we must pick points of finite precision. Now the intuition is still correct, but one needs to prove it. This is a classic theme that recurs throughout theory: often pure mathematical results must be “improved” to be of use to our community.
The key lemmas that were proved were all of the following form:
Lemma: Suppose that
is a non-zero polynomial of degree
over a field and
is a non-empty subset of the field. Then,
where
are random elements from
is a function.
![\displaystyle \mathsf{Pr}[P(r_{1},\dots,r_{n})=0] \le \delta(n,d,|S|)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathsf%7BPr%7D%5BP%28r_%7B1%7D%2C%5Cdots%2Cr_%7Bn%7D%29%3D0%5D+%5Cle+%5Cdelta%28n%2Cd%2C%7CS%7C%29&bg=e8e8e8&fg=000000&s=0&c=20201002)
The question is what 
- The Strong Bound is,
;
- The Weak Bound is,
.
Schwartz’s Paper
Schwartz published his work in JACM in 1980. His actual paper is quite long and covers many other aspects of identity testing. His main result is the famous test for identity, which in our terms is the Strong Bound for Identity Testing.
He was also very interested in applications: plane geometry for example. He also discussed real variable versions and other extensions. An earlier conference version is in the Proceedings of the International Symposium on Symbolic and Algebraic Computation in 1979.
Zippel’s Paper
Zippel proved a more complex bound than Schwartz in his paper. That his result is at least as strong as the Weak Bound, is immediate. Part of the difficulty is that Zippel had a different model: he used the maximum degree of each variable, rather than the total degree. Thus, it is a bit difficult to compare Zippel’s result with the other two, since he has a somewhat different model.
His paper was published at the same conference as Schwartz in 1979, where he spoke right after Jack—according to the program. Zippel was driven by the work of actual symbolic systems and he gave timings of a real implementation of his identity testing algorithm. It is nice to see that the methods really work.
DeMillo-Lipton’s Paper
We published our paper in Information Processing Letters in 1978: it was a technical report in 1977.
Our paper was driven by an application to program testing, which was something we worked on at the time. We actually proved what we are calling the Weak Bound. Our paper was strange: we did not actually state a lemma, but gave our result as a free flowing statement. The reason we did this was because our audience was software engineers, and we felt that a very formal looking paper would not be one that they would look at carefully.
The reason we got the Weak Bound is instructive. We tried to bound the probability that the polynomial would be non-zero at a random point. This yields
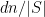
and not

It is interesting that all three papers had the same two ideas:
- A polynomial of one variable of degree
- A polynomial of
variables.
The respective proofs then follow by an induction of some type.
Like Zippel, our audience was not theorists. For us the audience was, as I just stated, software engineers—especially those working on program testing. The main point of our paper was that identities could be tested in far fewer evaluations than

We did not implement our algorithm, but did include an entire half page of data to show how efficient the random algorithm would be for various parameters.
Comparison
I am part of this so it is impossible to be unbiased, but here are some of the key points that I think are clear:
Who was first? This is unclear, if by first you mean something that is not written down in some manner. Schwartz’s Technical report is from 1978, ours is from 1977. But who knows.
Who was first published in a journal? We were the first here: 1978 in Information Processing Letters.
Who was last? Schwartz was the last to discover this great result. His publication in the JACM in 1980 ended all the discoveries. One point from the history of science that is that the credit for a result often, not always, goes to the last person who discovers it.
Who had the weak result? All the players knew that only a polynomial, not an exponential number of evaluations, were enough to check any identity.
Who had the Strong result? Schwartz clearly, I believe, is the only one who had the Strong Bound. I cannot believe that we missed the bound—it is so simple. But Zippel also missed the Strong Bound. I think part of the reason is that Rich, Zippel, and I were thinking of practical applications; thus, the the exact polynomial bound was unimportant to us.
Why Schwartz-Zippel?
The result is usually called the Schwartz-Zippel lemma. Sometimes we are cited too. Mostly not. Oh well.
I can see calling it just the Schwartz Lemma: he was the only one with the Strong Bound. But since most applications need only the weaker results, I can see why Zippel is added. I do not get why we are usually left out. I think there could be two reasons: First, Schwartz and Zippel gave their respective papers at the same conference on symbolic computation in 1979—perhaps that is why they get cited together. Perhaps.
Second, DeMillo and I never pointed out our earlier paper to Schwartz. When Schwartz’s JACM paper came out, I quickly saw there was no reference to us. But I did nothing. Perhaps the lesson today is to immediately say something. Perhaps another lesson is that of Gian-Carlo Rota:
Publish the Same Result Several Times.
Open Problems
What should this result be called? What do you think? Some researchers have told me that they usually refer to all three papers, but they point out that the general idea that identity checking is easy with random points is an “old” idea in the coding theory community. Oh well.
Perhaps, more important is the real open problem that I will discuss another day: can we derandomize identity testing for arithmetic circuits? There have been some exciting partial results and I will discuss those soon.

Finally, I would like to thank Ken Regan for his tremendous help, especially in explaining to me the differences among the three papers. As usual all, errors are mine. Ken promises to add a detailed comment on his thoughts. Again, thanks Ken.
Like this:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK