

高并发异步解耦利器:RocketMQ究竟强在哪里?
source link: https://www.cnblogs.com/arthinking/p/15590677.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
高并发异步解耦利器:RocketMQ究竟强在哪里?

上篇文章消息队列那么多,为什么建议深入了解下RabbitMQ?我们讲到了消息队列的发展史:
并且详细介绍了RabbitMQ,其功能也是挺强大的,那么,为啥又要搞一个RocketMQ出来呢?是重复造轮子吗?本文我们就带大家来详细探讨RocketMQ究竟好在哪里。
RocketMQ是一个分布式消息中间件,具有低延迟、高性能和可靠性、万亿级别的容量和灵活的可扩展性。它是阿里巴巴于2012年开源的第三代分布式消息中间件。
随着阿里巴巴的电商业务不断发展,需要一款更高性能的消息中间件,RocketMQ就是这个业务背景的产物。RocketMQ是一个分布式消息中间件,具有低延迟、高性能和可靠性、万亿级别的容量和灵活的可扩展性,它是阿里巴巴于2012年开源的第三代分布式消息中间件。RocketMQ经历了多年双十一的洗礼,在可用性、可靠性以及稳定性等方面都有出色的表现。值得一提的是,RocketMQ最初就是借鉴了Kafka进行改造开发而来的,所以熟悉Kafka的朋友,会发现RocketMQ的原理和Kafka有很多相似之处。
RocketMQ前身叫做MetaQ,在MeataQ发布3.0版本的时候改名为RocketMQ,其本质上的设计思路和Kafka类似,因为最初就是基于Kafka改造而来,经过不断的迭代与版本升级,2016年11月21日,阿里巴巴向Apache软件基金会捐赠了RocketMQ 。近年来被越来越多的国内企业使用。
本文带大家从以下几个方面详细了解RocketMQ:
- RocketMQ如何保证消息存储的可靠性?
- RocketMQ如何保证消息队列服务的高可用?
- 如何构建一个高可用的RocketMQ双主双从最小集群?
- RocketMQ消息是如何存储的?
- RocketMQ是如何保证存取消息的效率的?
- 如何实现基于Message Key的高效查询?
- 如何实现基于Message Id的高效查询?
- RocketMQ的Topic在集群中是如何存储的?
- Broker自动创建Topic会有什么问题?
- RocketMQ如何保证消息投递的顺序性?
- RocketMQ如何保证消息消费的顺序性?
- 实现分布式事务的手段有哪些?
- RocketMQ如何实现事务消息?
- RocketMQ事务消息是如何存储的?
1. RocketMQ技术架构
RocketMQ的架构主要分为四部分,如下图所示:
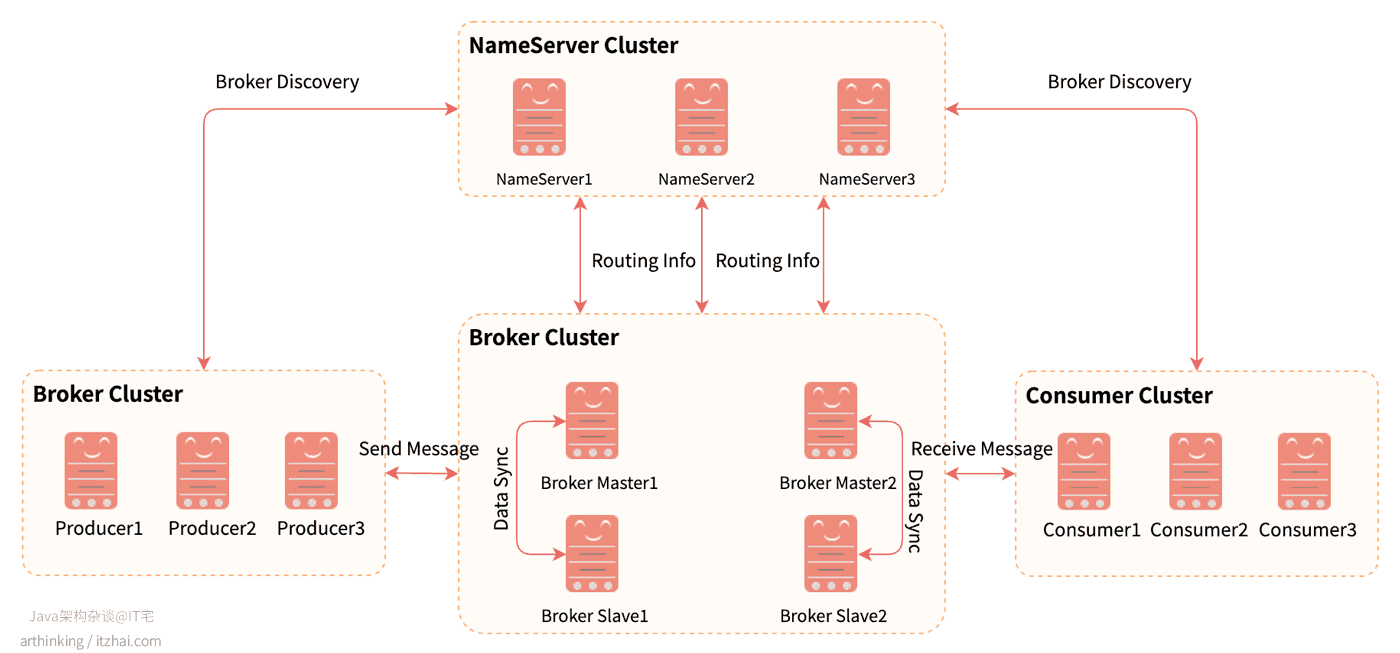
Producer:消息生产者,支持集群方式部署;Consumer:消息消费者,支持集群方式部署,支持pull,push模式获取消息进行消费,支持集群和广播方式消费;NameServer:Topic路由注册中心,类似于Dubbo中的zookeeper,支持Broker的动态注册与发现;- 提供心跳检测机制,检查Broker是否存活;
- 接收Broker集群的注册信息,作为路由信息的基本数据;
- NameServier各个实例不相互进行通信,每个NameServer都保存了一份完整的路由信息,这与zookeeper有所区别,不用作复杂的节点数据同步与选主过程;
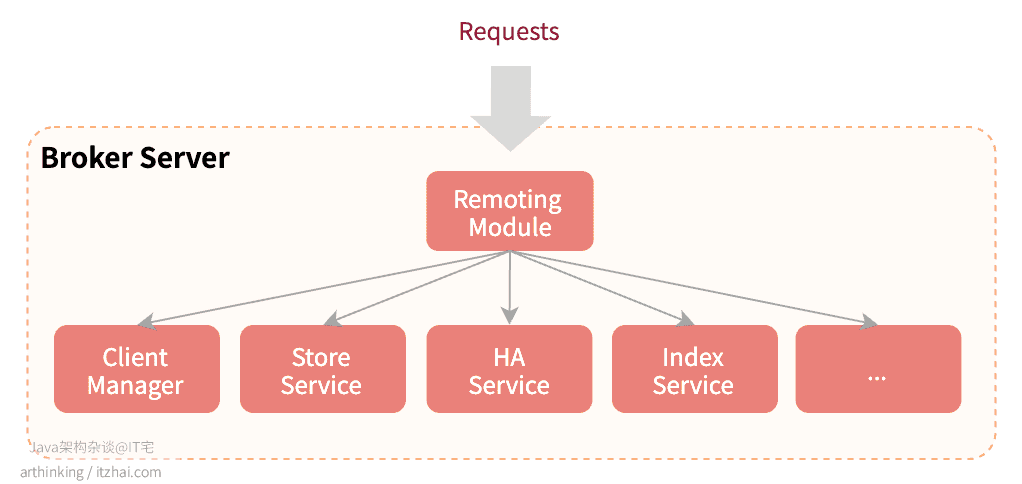
BrokerServer:主要负责消息的存储、投递和查询,以及服务高可用保证。BrokerServer包含以下几个重要的子模块:- Remoting Module:整个Broker的实体,负责处理来自clients端的请求;
- Client Manager:负责管理客户端(Producer/Consumer)和维护Consumer的Topic订阅信息;
- StoreService:提供方便简单的API接口处理消息存储到物理硬盘和查询功能;
- HA Service:高可用服务,提供Master Broker 和 Slave Broker之间的数据同步功能;
- Index Service:根据特定的Message key对投递到Broker的消息进行索引服务,以提供消息的快速查询。
2. RocketMQ执行原理
RocketMQ执行原理如下图所示:
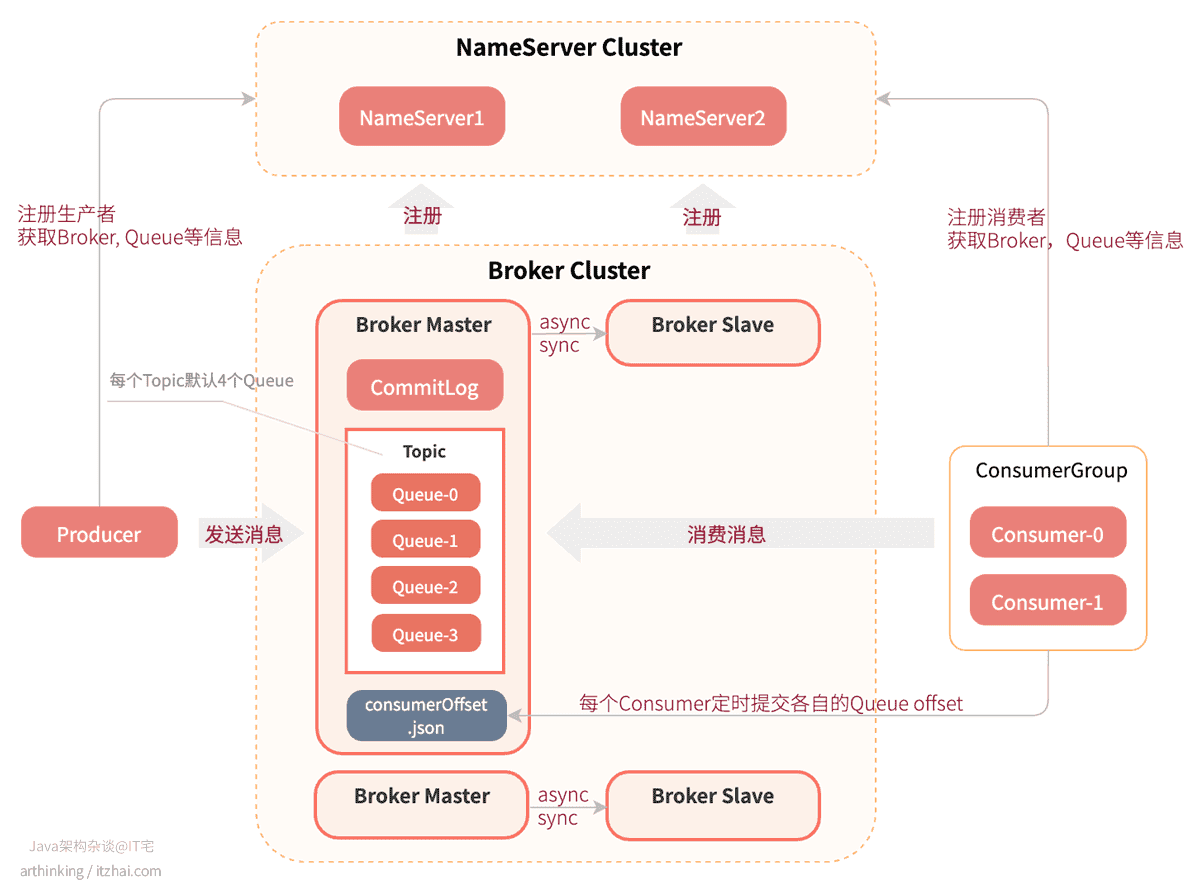
- 首先,启动每个NameServer节点,共同构成一个NameServer Cluster。NameServer启动后,监听端口,等待Broker、Producer、Consumer的连接;
- 然后启动Broker的主从节点,这个时候Broker会与所有的NameServer建立并保持长连接,定时发送心跳包,把自己的信息(IP+端口号)以及存储的所有Topic信息注册到每个NameServer中。这样NameServer集群中就有Topic和Broker的映射关系了;
- 收发消息前,先创建Topic,创建Topic时需要指定该Topic要存储在哪些Broker上,也可以在发送消息时自动创建Topic,每个Topic默认会分配4个Queue;
- 启动生产者,这个时候生产者会把信息注册到NameServer中,并且从NameServer获取Broker服务器,Queue等信息;
- 启动消费者,这个时候消费者会把信息注册到NameServer中,并且从NameServer获取Broker服务器,Queue等信息;
- 生产者发送消息到Broker集群中的时候,会从所有的Master节点的对应Topic中选择一个Queue,然后与Queue所在的Broker建立长连接从而向Broker投递消息。消息实际上是存储在了CommitLog文件中,而Queue文件里面存储的实际是消息在CommitLog中的存储位置信息;
- 消费者从Broker集群中消费消息的时候,会通过特定的负载均衡算法,绑定一个消息队列进行消费;
- 消费者会定时(或者kill阶段)把Queue的消费进度offset提交到Broker的consumerOffset.json文件中记录起来;
- 主节点和从节点之间可以是同步或者异步的进行数据复制,相关配置参数:
brokerRole,可选值:ASYNC_MASTER:异步复制方式(异步双写),生产者写入消息到Master之后,无需等到消息复制到Slave即可返回,消息的复制由旁路线程进行异步复制;SYNC_MASTER:同步复制方式(同步双写),生产者写入消息到Master之后,需要等到Slave复制成功才可以返回。如果有多个Slave,只需要有一个Slave复制成功,并成功应答,就算复制成功了。这里是否持久化到磁盘依赖于另一个参数:flushDiskType;SLAVE:从节点
3. RocketMQ集群
本节我们来看看一个双主双从的RocketMQ是如何搭建的。
集群配置参数说明:
在讨论集群前,我们需要了解两个关键的集群配置参数:brokerRole,flushDiskType。brokerRole在前一节已经介绍了,而flushDiskType则是刷盘方式的配置,主要有:
- ASYNC_FLUSH: 异步刷盘
- SYNC_FLUSH: 同步刷盘
3.1 如何保证消息存储的可靠性?
brokerRole确定了主从同步是异步的还是同步的,flushDiskType确定了数据刷盘的方式是同步的还是异步的。
如果业务场景对消息丢失容忍度很低,可以采用SYNC_MASTER + ASYNC_FLUSH的方式,这样只有master和slave在刷盘前同时挂掉,消息才会丢失,也就是说即使有一台机器出故障,仍然能保证数据不丢;
如果业务场景对消息丢失容忍度比较高,则可以采用ASYNC_MASTER + ASYNC_FLUSH的方式,这样可以尽可能的提高消息的吞吐量。
3.2 如何保证消息队列服务的高可用?
消费端的高可用
Master Broker支持读和写,Slave Broker只支持读。
当Master不可用的时候,Consumer会自动切换到Slave进行读,也就是说,当Master节点的机器出现故障后,Consumer仍然可以从Slave节点读取消息,不影响消费端的消费程序。
生产端的高可用
集群配置参数说明:
- brokerName: broker的名称,需要把Master和Slave节点配置成相同的名称,表示他们的主从关系,相同的brokerName的一组broker,组成一个broker组;
- brokerId: broker的id,0表示Master节点的id,大于0表示Slave节点的id。
在RocketMQ中,机器的主从节点关系是提前配置好的,没有类似Kafka的Master动态选主功能。
如果一个Master宕机了,要让生产端程序继续可以生产消息,您需要部署多个Master节点,组成多个broker组。这样在创建Topic的时候,就可以把Topic的不同消息队列分布在多个broker组中,即使某一个broker组的Master节点不可用了,其他组的Master节点仍然可用,保证了Producer可以继续发送消息。
3.3 如何构建一个高可用的RocketMQ双主双从最小集群?
为了尽可能的保证消息不丢失,并且保证生产者和消费者的可用性,我们可以构建一个双主双从的集群,搭建的架构图如下所示:
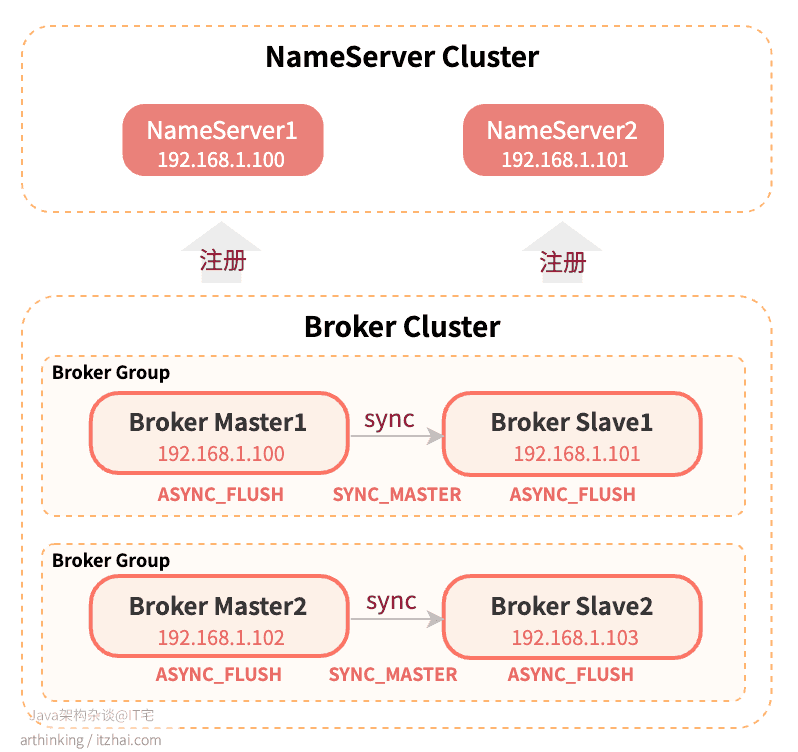
部署架构说明:
- 两个Broker组,保证了其中一个Broker组的Master节点挂掉之后,另一个Master节点仍然可以接受某一个Topic的消息投递;
- 主从同步采用SYNC_MASTER,保证了生产者写入消息到Master之后,需要等到Slave也复制成功,才返回消息投递成功。这样即使主节点或者从节点挂掉了,也不会导致丢数据;
- 由于主节点有了从节点做备份,所以,落盘策略可以使用ASYNC_FLUSH,从而尽可能的提高消息的吞吐量;
- 如果只提供两台服务器,要部署这个集群的情况下,可以把Broker Master1和Broker Slave2部署在一台机器,Broker Master2和Broker Slave1部署在一台机器。
关键配置参数
以下是关键的配置参数:
Broker Master1
# NameServer地址 namesrvAddr=192.168.1.100:9876;192.168.1.101:9876 # 集群名称 brokerClusterName=itzhai-com-cluster # brokerIP地址 brokerIP1=192.168.1.100 # broker通信端口 listenPort=10911 # broker名称 brokerName=broker‐1 # 0表示主节点 brokerId=0 # 2点进行消息删除 deleteWhen=02 # 消息在磁盘上保留48小时 fileReservedTime=48 # 主从同步复制 brokerRole=SYNC_MASTER # 异步刷盘 flushDiskType=ASYNC_FLUSH # 自动创建Topic autoCreateTopicEnable=true # 消息存储根目录 storePathRootDir=/data/rocketmq/store‐mBroker Slave1
# NameServer地址 namesrvAddr=192.168.1.100:9876;192.168.1.101:9876 # 集群名称 brokerClusterName=itzhai-com-cluster # brokerIP地址 brokerIP1=192.168.1.101 # broker通信端口 listenPort=10911 # broker名称 brokerName=broker‐1 # 非0表示从节点 brokerId=1 # 2点进行消息删除 deleteWhen=02 # 消息在磁盘上保留48小时 fileReservedTime=48 # 从节点 brokerRole=SLAVE # 异步刷盘 flushDiskType=ASYNC_FLUSH # 自动创建Topic autoCreateTopicEnable=true # 消息存储根目录 storePathRootDir=/data/rocketmq/store‐sBroker Master2
# NameServer地址 namesrvAddr=192.168.1.100:9876;192.168.1.101:9876 # 集群名称 brokerClusterName=itzhai-com-cluster # brokerIP地址 brokerIP1=192.168.1.102 # broker通信端口 listenPort=10911 # broker名称 brokerName=broker‐2 # 0表示主节点 brokerId=0 # 2点进行消息删除 deleteWhen=02 # 消息在磁盘上保留48小时 fileReservedTime=48 # 主从同步复制 brokerRole=SYNC_MASTER # 异步刷盘 flushDiskType=ASYNC_FLUSH # 自动创建Topic autoCreateTopicEnable=true # 消息存储根目录 storePathRootDir=/data/rocketmq/store‐mBroker Slave2
# NameServer地址 namesrvAddr=192.168.1.100:9876;192.168.1.101:9876 # 集群名称 brokerClusterName=itzhai-com-cluster # brokerIP地址 brokerIP1=192.168.1.103 # broker通信端口 listenPort=10911 # broker名称 brokerName=broker‐2 # 非0表示从节点 brokerId=1 # 2点进行消息删除 deleteWhen=02 # 消息在磁盘上保留48小时 fileReservedTime=48 # 从节点 brokerRole=SLAVE # 异步刷盘 flushDiskType=ASYNC_FLUSH # 自动创建Topic autoCreateTopicEnable=true # 消息存储根目录 storePathRootDir=/data/rocketmq/store‐s写了那么多顶层架构图,不写写底层内幕,就不是IT宅(itzhai.com)的文章风格,接下来,我们就来看看底层存储架构。
4. RocketMQ存储架构
我们在broker.conf文件中配置了消息存储的根目录:
# 消息存储根目录 storePathRootDir=/data/rocketmq/store‐m进入这个目录,我们可以发现如下的目录结构:
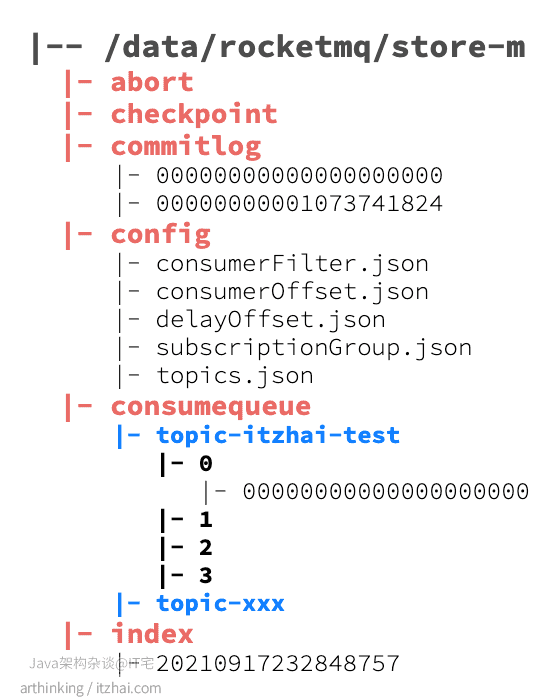
- abort:该文件在broker启动时创建,关闭时删除,如果broker异常退出,则文件会存在,在下次启动时会走修复流程;
- checkpoint:检查点,主要存放以下内容:
- physicMsgTimestamp:commitlog文件最后一次落盘时间;
- logicsMsgTimestamp:consumequeue最后一次落盘时间;
- indexMsgTimestamp:索引文件最后一次落盘时间;
- commitlog:存放消息的完整内容,所有的topic消息都会通过文件追加的形式写入到该文件中;
- config:消息队列的配置文件,包括了topic配置,消费的偏移量等信息。其中consumerOffset.json文件存放消息队列消费的进度;
- consumequeue:topic的逻辑队列,在消息存放到commitlog之后,会把消息的存放位置记录到这里,只有记录到这里的消息,才能被消费者消费;
- index:消息索引文件,通过Message Key查询消息时,是通过该文件进行检索查询的。
4.1 RocketMQ消息是如何存储的
下面我们来看看关键的commitlog以及consumequeue:
消息投递到Broker之后,是先把实际的消息内容存放到CommitLog中的,然后再把消息写入到对应主题的ConsumeQueue中。其中:
CommitLog:消息的物理存储文件,存储实际的消息内容。每个Broker上面的CommitLog被该Broker上所有的ConsumeQueue共享。
单个文件大小默认为1G,文件名长度为20位,左边补零,剩余为起始偏移量。预分配好空间,消息顺序写入日志文件。当文件满了,则写入下一个文件,下一个文件的文件名基于文件第一条消息的偏移量进行命名;
ConsumeQueue:消息的逻辑队列,相当于CommitLog的索引文件。RocketMQ是基于Topic主题订阅模式实现的,每个Topic下会创建若干个逻辑上的消息队列ConsumeQueue,在消息写入到CommitLog之后,通过Broker的后台服务线程(ReputMessageService)不停地分发请求并异步构建ConsumeQueue和IndexFile(索引文件,后面介绍),然后把每个ConsumeQueue需要的消息记录到各个ConsumeQueue中。
ConsumeQueue主要记录8个字节的commitLogOffset(消息在CommitLog中的物理偏移量), 4个字节的msgSize(消息大小), 8个字节的TagHashcode,每个元素固定20个字节。
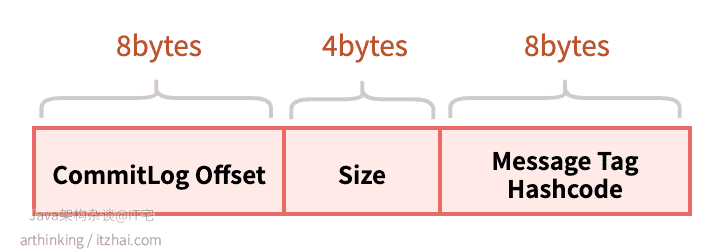
ConsumeQueue相当于CommitLog文件的索引,可以通过ConsumeQueue快速从很大的CommitLog文件中快速定位到需要的消息。
ConsumeQueue的存储结构
主题消息队列:在consumequeue目录下,按照topic的维度存储消息队列。
重试消息队列:如果topic中的消息消费失败,则会把消息发到重试队列,重新队列按照消费端的GroupName来分组,命名规则:%RETRY%ConsumerGroupName
死信消息队列:如果topic中的消息消费失败,并且超过了指定重试次数之后,则会把消息发到死信队列,死信队列按照消费端的GroupName来分组,命名规则:%DLQ%ConsumerGroupName
假设我们现在有一个topic:itzhai-test,消费分组:itzhai_consumer_group,当消息消费失败之后,我们查看consumequeue目录,会发现多处了一个重试队列:

我们可以在RocketMQ的控制台看到这个重试消息队列的主题和消息:
如果一直重试失败,达到一定次数之后(默认是16次,重试时间:1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h),就会把消息投递到死信队列:

4.2 RocketMQ是如何保证存取消息的效率的
4.2.1 如何保证高效写
每条消息的长度是不固定的,为了提高写入的效率,RocketMQ预先分配好1G空间的CommitLog文件,采用顺序写的方式写入消息,大大的提高写入的速度。
RocketMQ中消息刷盘主要可以分为同步刷盘和异步刷盘两种,通过flushDiskType参数进行配置。如果需要提高写消息的效率,降低延迟,提高MQ的性能和吞吐量,并且不要求消息数据存储的高可靠性,可以把刷盘策略设置为异步刷盘。
4.2.2 如何保证高效读
为了提高读取的效率,RocketMQ使用ConsumeQueue作为消费消息的索引,使用IndexFile作为基于消息key的查询的索引。下面来详细介绍下。
4.2.2.1 ConsumeQueue
读取消息是随机读的,为此,RocketMQ专门建立了ConsumeQueue索引文件,每次先从ConsumeQueue中获取需要的消息的地址,消息大小,然后从CommitLog文件中根据地址直接读取消息内容。在读取消息内容的过程中,也尽量利用到了操作系统的页缓存机制,进一步加速读取速度。
ConsumeQueue由于每个元素大小是固定的,因此可以像访问数组一样访问每个消息元素。并且占用空间很小,大部分的ConsumeQueue能够被全部载入内存,所以这个索引查找的速度很快。每个ConsumeQueue文件由30w个元素组成,占用空间在6M以内。每个文件默认大小为600万个字节,当一个ConsumeQueue类型的文件写满之后,则写入下一个文件。
4.2.2.2 IndexFile为什么按照Message Key查询效率高?
我们在RocketMQ的store目录中可以发现有一个index目录,这个是一个用于辅助提高查询消息效率的索引文件。通过该索引文件实现基于消息key来查询消息的功能。
物理存储结构
IndexFile索引文件物理存储结构如下图所示:
- Header:索引头文件,40 bytes,包含以下信息:
beginTimestamp:索引文件中第一个索引消息存入Broker的时间戳;endTimestamp:索引文件中最后一个索引消息存入Broker的时间戳beginPHYOffset:索引文件中第一个索引消息在CommitLog中的偏移量;endPhyOffset:索引文件中最后一个索引消息在CommitLog中的偏移量;hashSlotCount:构建索引使用的slot数量;indexCount:索引的总数;
- Slot Table:槽位表,类似于Redis的Slot,或者哈希表的key,使用消息的key的hashcode与slotNum取模可以得到具体的槽的位置。每个槽位占4 bytes,一个IndexFile可以存储500w个slot;
- Index Linked List:消息的索引内容,如果哈希取模后发生槽位碰撞,则构建成链表,一个IndexFile可以存储2000w个索引:
Key Hash:消息的哈希值;Commit Log Offset:消息在CommitLog中的偏移量;Timestamp:消息存储的时间戳;Next Index Offset:下一个索引的位置,如果消息取模后发生槽位槽位碰撞,则通过此字段把碰撞的消息构成链表。
每个IndexFile文件的大小:40b + 4b * 5000000 + 20b * 20000000 = 420000040b,约为400M。
逻辑存储结构
IndexFile索引文件的逻辑存储结构如下图所示:
IndexFile逻辑上是基于哈希表来实现的,Slot Table为哈希键,Index Linked List中存储的为哈希值。
4.2.2.3 为什么按照MessageId查询效率高?
RocketMQ中的MessageId的长度总共有16字节,其中包含了:消息存储主机地址(IP地址和端口),消息Commit Log offset。“
按照MessageId查询消息的流程:Client端从MessageId中解析出Broker的地址(IP地址和端口)和Commit Log的偏移地址后封装成一个RPC请求后通过Remoting通信层发送(业务请求码:VIEW_MESSAGE_BY_ID)。Broker端走的是QueryMessageProcessor,读取消息的过程用其中的 commitLog offset 和 size 去 commitLog 中找到真正的记录并解析成一个完整的消息返回。
4.3 RocketMQ集群是如何做数据分区的?
我们继续看看在集群模式下,RocketMQ的Topic数据是如何做分区的。IT宅(itzhai.com)提醒大家,实践出真知。这里我们部署两个Master节点:
4.3.1 RocketMQ的Topic在集群中是如何存储的
我们通过手动配置每个Broker中的Topic,以及ConsumeQueue数量,来实现Topic的数据分片,如,我们到集群中手动配置这样的Topic:
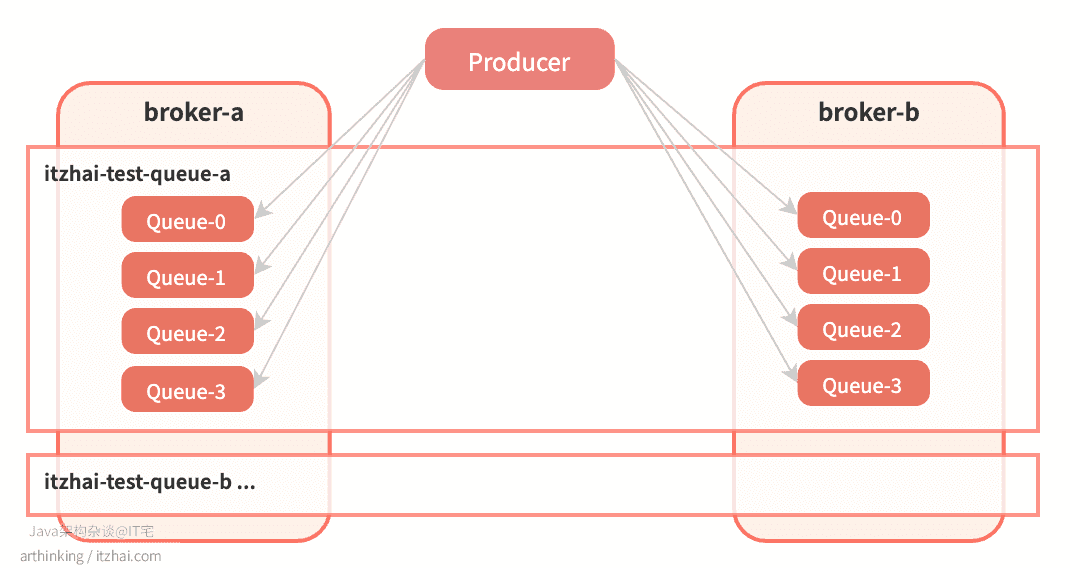
broker-a创建itzhai-com-test-1,4个队列;broker-b创建itzhai-com-test-1,2个队列。
创建完成之后,Topic分片集群分布如下:
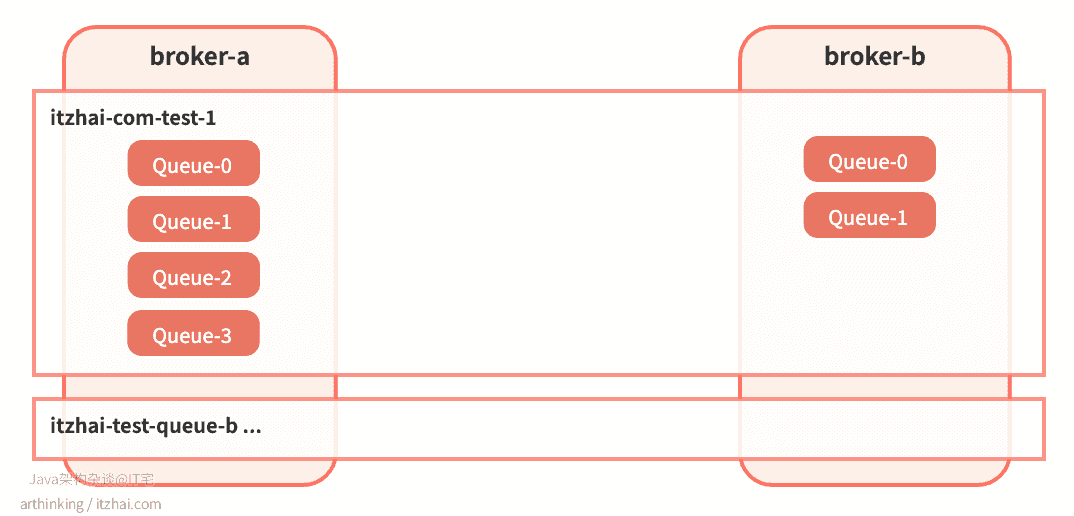
可以发现,RocketMQ是把Topic分片存储到各个Broker节点中,然后在把Broker节点中的Topic继续分片为若干等分的ConsumeQueue,从而提高消息的吞吐量。ConsumeQueue是作为负载均衡资源分配的基本单元。
这样把Topic的消息分区到了不同的Broker上,从而增加了消息队列的数量,从而能够支持更块的并发消费速度(只要有足够的消费者)。
4.3.2 Broker自动创建Topic会有什么问题?
假设设置为通过Broker自动创建Topic(autoCreateTopicEnable=true),并且Producer端设置Topic消息队列数量设置为4,也就是默认值:
producer.setDefaultTopicQueueNums(4);尝试往一个新的 topic itzhai-test-queue-1连续发送10条消息,发送完毕之后,查看Topic状态:
我们可以发现,在两个broker上面都创建了itzhai-test-queue-a,并且每个broker上的消息队列数量都为4。怎么回事,我配置的明明是期望创建4个队列,为什么加起来会变成了8个?如下图所示:
由于时间关系,本文我们不会带大家从源码方面去解读为啥会出现这种情况,接下来我们通过一种更加直观的方式来验证下这个问题:继续做实验。
我们继续尝试往一个新的 topic itzhai-test-queue-10发送1条消息,注意,这一次不做并发发送了,只发送一条,发送完毕之后,查看Topic状态:
可以发现,这次创建的消息队列数量又是对的了,并且都是在broker-a上面创建的。接下来,无论怎么并发发送消息,消息队列的数量都不会继续增加了。
其实这也是并发请求Broker,触发自动创建Topic的bug。
为了更加严格的管理Topic的创建和分片配置,一般在生产环境都是配置为手动创建Topic,通过提交运维工单申请创建Topic以及Topic的数据分配。
接下来我们来看看RocketMQ的特性。更多其他技术的底层架构内幕分析,请访问我的博客IT宅(itzhai.com)或者关注Java架构杂谈公众号。
5. RocketMQ特性
5.1 生产端
5.1.1 消息发布
RocketMQ中定义了如下三种消息通信的方式:
public enum CommunicationMode { SYNC, ASYNC, ONEWAY, }SYNC:同步发送,生产端会阻塞等待发送结果;- 应用场景:这种方式应用场景非常广泛,如重要业务事件通知。
ASYNC:异步发送,生产端调用发送API之后,立刻返回,在拿到Broker的响应结果后,触发对应的SendCallback回调;- 应用场景:一般用于链路耗时较长,对 RT 较为敏感的业务场景;
ONEWAY:单向发送,发送方只负责发送消息,不等待服务器回应且没有回调函数触发,即只发送请求不等待应答。 此方式发送消息的过程耗时非常短,一般在微秒级别;- 应用场景:适用于耗时非常短,对可靠性要求不高的场景,如日志收集。
SYNC和ASYNC关注发送结果,ONEWAY不关注发送结果。发送结果如下:
public enum SendStatus { SEND_OK, FLUSH_DISK_TIMEOUT, FLUSH_SLAVE_TIMEOUT, SLAVE_NOT_AVAILABLE, }SEND_OK:消息发送成功。SEND_OK并不意味着投递是可靠的,要确保消息不丢失,需要开启SYNC_MASTER同步或者SYNC_FLUSH同步写;FLUSH_DISK_TIMEOUT:消息发送成功,但是刷盘超时。如果Broker的flushDiskType=SYNC_FLUSH,并且5秒内没有完成消息的刷盘,则会返回这个状态;FLUSH_SLAVE_TIMEOUT:消息发送成功,但是服务器同步到Slave时超时。如果Broker的brokerRole=SYNC_MASTER,并且5秒内没有完成同步,则会返回这个状态;SLAVE_NOT_AVAILABLE:消息发送成功,但是无可用的Slave节点。如果Broker的brokerRole=SYNC_MASTER,但是没有发现SLAVE节点或者SLAVE节点挂掉了,那么会返回这个状态。
源码内容更精彩,欢迎大家进一步阅读源码详细了解消息发送的内幕:
- 同步发送:org.apache.rocketmq.client.producer.DefaultMQProducer#send(org.apache.rocketmq.common.message.Message)
- 异步发送:org.apache.rocketmq.client.producer.DefaultMQProducer#send(org.apache.rocketmq.common.message.Message, org.apache.rocketmq.client.producer.SendCallback)
- 单向发送:org.apache.rocketmq.client.producer.DefaultMQProducer#sendOneway(org.apache.rocketmq.common.message.Message)
5.1.2 顺序消费
消息的有序性指的是一类消息消费的时候,可以按照发送顺序来消费,比如:在Java架构杂谈茶餐厅吃饭产生的消息:进入餐厅、点餐、下单、上菜、付款,消息要按照这个顺序消费才有意义,但是多个顾客产生的消息是可以并行消费的。顺序消费又分为全局顺序消费和分区顺序消费:
全局顺序:同一个Topic下的消息,所有消息按照严格的FIFO顺序进行发布和消费。适用于:性能要求不高,所有消息严格按照FIFO进行发布和消费的场景;分区顺序:同一个Topic下,根据消息的特定业务ID进行sharding key分区,同一个分区内的消息按照严格的FIFO顺序进行发布和消费。适用于:性能要求高,在同一个分区中严格按照FIFO进行发布和消费的场景。
一般情况下,生产者是会以轮训的方式把消息发送到Topic的消息队列中的:
在同一个Queue里面,消息的顺序性是可以得到保证的,但是如果一个Topic有多个Queue,以轮训的方式投递消息,那么就会导致消息乱序了。
为了保证消息的顺序性,需要把保持顺序性的消息投递到同一个Queue中。
5.1.2.1 如何保证消息投递的顺序性
RocketMQ提供了MessageQueueSelector接口,可以用来实现自定义的选择投递的消息队列的算法:
for (int i = 0; i < orderList.size(); i++) { String content = "Hello itzhai.com. Java架构杂谈," + new Date(); Message msg = new Message("topic-itzhai-com", tags[i % tags.length], "KEY" + i, content.getBytes(RemotingHelper.DEFAULT_CHARSET)); SendResult sendResult = producer.send(msg, new MessageQueueSelector() { @Override public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) { Long orderId = (Long) arg; // 订单号与消息队列个数取模,保证让同一个订单号的消息落入同一个消息队列 long index = orderId % mqs.size(); return mqs.get((int) index); } }, orderList.get(i).getOrderId()); System.out.printf("content: %s, sendResult: %s%n", content, sendResult); }如上图,我们实现了MessageQueueSelector接口,并在实现的select方法里面,指定了选择消息队列的算法:订单号与消息队列个数取模,保证让同一个订单号的消息落入同一个消息队列:
有个异常场景需要考虑:假设某一个Master节点挂掉了,导致Topic的消息队列数量发生了变化,那么继续使用以上的选择算法,就会导致在这个过程中同一个订单的消息会分散到不同的消息队列里面,最终导致消息不能顺序消费。
为了避免这种情况,只能选择牺牲failover特性了。
现在投递到消息队列中的消息保证了顺序,那如何保证消费也是顺序的呢?
5.1.2.2 如何保证消息消费的顺序性?
RocketMQ中提供了MessageListenerOrderly,该对象用于有顺序收异步传递的消息,一个队列对应一个消费线程,使用方法如下:
consumer.registerMessageListener(new MessageListenerOrderly() { // 消费次数,用于辅助模拟各种消费结果 AtomicLong consumeTimes = new AtomicLong(0); @Override public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) { context.setAutoCommit(true); System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs); this.consumeTimes.incrementAndGet(); if ((this.consumeTimes.get() % 2) == 0) { return ConsumeOrderlyStatus.SUCCESS; } else if ((this.consumeTimes.get() % 3) == 0) { return ConsumeOrderlyStatus.ROLLBACK; } else if ((this.consumeTimes.get() % 4) == 0) { return ConsumeOrderlyStatus.COMMIT; } else if ((this.consumeTimes.get() % 5) == 0) { context.setSuspendCurrentQueueTimeMillis(3000); return ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT; } return ConsumeOrderlyStatus.SUCCESS; } });如果您使用的是MessageListenerConcurrently,表示并发消费,为了保证消息消费的顺序性,需要设置为单线程模式。
使用
MessageListenerOrderly的问题:如果遇到某条消息消费失败,并且无法跳过,那么消息队列的消费进度就会停滞。
5.1.3 延迟队列(定时消息)
定时消费是指消息发送到Broker之后不会立即被消费,而是等待特定的时间之后才投递到Topic中。定时消息会暂存在名为SCHEDULE_TOPIC_XXXX的topic中,并根据delayTimeLevel存入特定的queue,queueId=delayTimeLevel-1,一个queue只存相同延迟的消息,保证具有相同延迟的消息能够顺序消费。比如,我们设置1秒后把消息投递到topic-itzhai-comtopic,则存储的文件目录如下所示:

Broker会调度地消费SCHEDULE_TOPIC_XXXX,将消息写入真实的topic。
定时消息的副作用:定时消息会在第一次写入Topic和调度写入实际的topic都会进行计数,因此发送数量,tps都会变高。
使用延迟队列的场景:提交了订单之后,如果等待超过约定的时间还未支付,则把订单设置为超时状态。
RocketMQ提供了以下几个固定的延迟级别:
public class MessageStoreConfig { ... // 10个level,level:1~18 private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h"; ... }level = 0 表示不使用延迟消息。
另外,消息消费失败也会进入延迟队列,消息发送时间与设置的延迟级别和重试次数有关。
以下是发送延迟消息的代码:
public class ScheduledMessageProducer { public static void main(String[] args) throws Exception { DefaultMQProducer producer = new DefaultMQProducer("TestProducerGroup"); producer.start(); int totalMessagesToSend = 100; for (int i = 0; i < totalMessagesToSend; i++) { Message message = new Message("TestTopic", ("Hello scheduled message " + i).getBytes()); // 指定该消息在10秒后被消费者消费 message.setDelayTimeLevel(3); producer.send(message); } producer.shutdown(); } }5.1.4 数据完整性与事务消息
通过消息对系统进行解耦之后,势必会遇到分布式系统数据完整性的问题。
5.1.4.1 实现分布式事务的手段有哪些?
我们可以通过以下手段解决分布式系统数据最终一致性问题:
- 数据库层面的
2PC(Two-phase commit protocol),二阶段提交,同步阻塞,效率低下,存在协调者单点故障问题,极端情况下存在数据不一致的风险。对应技术上的XA、JTA/JTS。这是分布式环境下事务处理的典型模式; - 数据库层面的
3PC,三阶段提交,引入了参与者超时机制,增加了预提交阶段,使得故障恢复之后协调者的决策复杂度降低,但整体的交互过程变得更长了,性能有所下降,仍旧会存在数据不一致的问题; - 业务层面的TCC ,
Try - Confirm - Cancel。对业务的侵入较大,和业务紧耦合,对于每一个操作都需要定义三个动作分别对应:Try - Confirm - Cancel,将资源层的两阶段提交协议转换到业务层,成为业务模型中的一部分; - 本地消息表;
- 事务消息;
RocketMQ事务消息(Transactional Message)则是通过事务消息来实现分布式事务的最终一致性。下面看看RocketMQ是如何实现事务消息的。
5.1.4.2 RocketMQ如何实现事务消息?
事务消息有两个流程:
- 事务消息发送及提交:
- 发送half消息;
- 服务端响应half消息写入结果;
- 根据half消息的发送结果执行本地事务。如果发送失败,此时half消息对业务不可见,本地事务不执行;
- 根据本地事务状态执行Commit或者Rollback。Commit操作会触发生成ConsumeQueue索引,此时消息对消费者可见;
- 补偿流程:
5. 对于没有Commit/Rollback的事务消息,会处于pending状态,这对这些消息,MQ Server发起一次回查;
6. Producer收到回查消息,检查回查消息对应的本地事务的转塔体;
7. 根据本地事务状态,重新执行Commit或者Rollback。
补偿阶段主要用于解决消息的Commit或者Rollback发生超时或者失败的情况。
half消息:并不是发送了一半的消息,而是指消息已经发送到了MQ Server,但是该消息未收到生产者的二次确认,此时该消息暂时不能投递到具体的ConsumeQueue中,这种状态的消息称为half消息。
5.1.4.3 RocketMQ事务消息是如何存储的?
发送到MQ Server的half消息对消费者是不可见的,为此,RocketMQ会先把half消息的Topic和Queue信息存储到消息的属性中,然后把该half消息投递到一个专门的处理事务消息的队列中:RMQ_SYS_TRANS_HALF_TOPIC,由于消费者没有订阅该Topic,所以无法消息half类型的消息。
生产者执行Commit half消息的时候,会存储一条专门的Op消息,用于标识事务消息已确定的状态,如果一条事务消息还没有对应的Op消息,说明这个事务的状态还无法确定。RocketMQ会开启一个定时任务,对于pending状态的消息,会先向生产者发送回查事务状态请求,根据事务状态来决定是否提交或者回滚消息。
当消息被标记为Commit状态之后,会把half消息的Topic和Queue相关属性还原为原来的值,最终构建实际的消费索引(ConsumeQueue)。
RocketMQ并不会无休止的尝试消息事务状态回查,默认查找15次,超过了15次还是无法获取事务状态,RocketMQ默认回滚该消息。并打印错误日志,可以通过重写AbstractTransactionalMessageCheckListener类修改这个行为。
可以通过Broker的配置参数:transactionCheckMax来修改此值。
5.1.5 消息重投
如果消息发布方式是同步发送会重投,如果是异步发送会重试。
消息重投可以尽可能保证消息投递成功,但是可能会造成消息重复。
什么情况会造成重复消费消息?
- 出现消息量大,网络抖动的时候;
- 生产者主动重发;
- 消费负载发生变化。
可以使用的消息重试策略:
retryTimesWhenSendFailed:设置同步发送失败的重投次数,默认为2。所以生产者最多会尝试发送retryTimesWhenSendFailed+1次。- 为了最大程度保证消息不丢失,重投的时候会尝试向其他broker发送消息;
- 超过重投次数,抛出异常,让客户端自行处理;
- 触发重投的异常:RemotingException、MQClientException和部分MQBrokerException;
retryTimesWhenSendAsyncFailed:设置异步发送失败重试次数,异步重试不会选择其他Broker,不保证消息不丢失;retryAnotherBrokerWhenNotStoreOK:消息刷盘(主或备)超时或slave不可用(返回状态非SEND_OK),是否尝试发送到其他broker,默认false。重要的消息可以开启此选项。
oneway发布方式不支持重投。
5.1.6 批量消息
为了提高系统的吞吐量,提高发送效率,可以使用批量发送消息。
批量发送消息的限制:
- 同一批批量消息的topic,waitStoreMsgOK属性必须保持一致;
- 批量消息不支持延迟队列;
- 批量消息一次课发送的上限是4MB。
发送批量消息的例子:
String topic = "itzhai-test-topic"; List<Message> messages = new ArrayList<>(); messages.add(new Message(topic, "TagA", "OrderID001", "Hello world itzhai.com 0".getBytes())); messages.add(new Message(topic, "TagA", "OrderID002", "Hello world itzhai.com 1".getBytes())); messages.add(new Message(topic, "TagA", "OrderID003", "Hello world itzhai.com 2".getBytes())); producer.send(messages);如果发送的消息比较多,会增加复杂性,为此,可以对大消息进行拆分。以下是拆分的例子:
public class ListSplitter implements Iterator<List<Message>> { // 限制最大大小 private final int SIZE_LIMIT = 1024 * 1024 * 4; private final List<Message> messages; private int currIndex; public ListSplitter(List<Message> messages) { this.messages = messages; } @Override public boolean hasNext() { return currIndex < messages.size(); } @Override public List<Message> next() { int startIndex = getStartIndex(); int nextIndex = startIndex; int totalSize = 0; for (; nextIndex < messages.size(); nextIndex++) { Message message = messages.get(nextIndex); int tmpSize = calcMessageSize(message); if (tmpSize + totalSize > SIZE_LIMIT) { break; } else { totalSize += tmpSize; } } List<Message> subList = messages.subList(startIndex, nextIndex); currIndex = nextIndex; return subList; } private int getStartIndex() { Message currMessage = messages.get(currIndex); int tmpSize = calcMessageSize(currMessage); while(tmpSize > SIZE_LIMIT) { currIndex += 1; Message message = messages.get(curIndex); tmpSize = calcMessageSize(message); } return currIndex; } private int calcMessageSize(Message message) { int tmpSize = message.getTopic().length() + message.getBody().length(); Map<String, String> properties = message.getProperties(); for (Map.Entry<String, String> entry : properties.entrySet()) { tmpSize += entry.getKey().length() + entry.getValue().length(); } tmpSize = tmpSize + 20; // Increase the log overhead by 20 bytes return tmpSize; } } // then you could split the large list into small ones: ListSplitter splitter = new ListSplitter(messages); while (splitter.hasNext()) { try { List<Message> listItem = splitter.next(); producer.send(listItem); } catch (Exception e) { e.printStackTrace(); // handle the error } }5.1.7 消息过滤
RocketMQ的消费者可以根据Tag进行消息过滤来获取自己感兴趣的消息,也支持自定义属性过滤。
Tags是Topic下的次级消息类型/二级类型(注:Tags也支持TagA || TagB这样的表达式),可以在同一个Topic下基于Tags进行消息过滤。
消息过滤是在Broker端实现的,减少了对Consumer无用消息的网络传输,缺点是增加了Broker负担,实现相对复杂。
5.2 消费端
5.2.1 消费模型
消费端有两周消费模型:集群消费和广播消费。
集群消费模式下,相同Consumer Group的每个Consumer实例平均分摊消息。
广播消费模式下,相同Consumer Group的每个Consumer实例都接收全量的消息。
5.2.2 消息重试
RocketMQ会为每个消费组都设置一个Topic名称为%RETRY%consumerGroupName的重试队列(这里需要注意的是,这个Topic的重试队列是针对消费组,而不是针对每个Topic设置的),用于暂时保存因为各种异常而导致Consumer端无法消费的消息。
考虑到异常恢复起来需要一些时间,会为重试队列设置多个重试级别,每个重试级别都有与之对应的重新投递延时,重试次数越多投递延时就越大。
RocketMQ对于重试消息的处理是先保存至Topic名称为SCHEDULE_TOPIC_XXXX的延迟队列中,后台定时任务按照对应的时间进行Delay后重新保存至%RETRY%consumerGroupName的重试队列中。
比如,我们设置1秒后把消息投递到topic-itzhai-comtopic,则存储的文件目录如下所示:
5.2.3 死信队列
当一条消息初次消费失败,消息队列会自动进行消息重试;达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息,此时,消息队列不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。
RocketMQ将这种正常情况下无法被消费的消息称为死信消息(Dead-Letter Message),将存储死信消息的特殊队列称为死信队列(Dead-Letter Queue)。
在RocketMQ中,可以通过使用console控制台对死信队列中的消息进行重发来使得消费者实例再次进行消费。
由于RocketMQ是使用Java写的,所以它的代码特别适合拿来阅读消遣,我们继续来看看RocketMQ的源码结构...
不不,还是算了,一下子又到周末晚上了,时间差不多了,今天就写到这里了。有空再聊。
我精心整理了一份Redis宝典给大家,涵盖了Redis的方方面面,面试官懂的里面有,面试官不懂的里面也有,有了它,不怕面试官连环问,就怕面试官一上来就问你Redis的Redo Log是干啥的?毕竟这种问题我也不会。

在Java架构杂谈公众号发送Redis关键字获取pdf文件:
本文作者: arthinking
博客链接: https://www.itzhai.com/articles/deep-understanding-of-rocketmq.html
高并发异步解耦利器:RocketMQ究竟强在哪里?
版权声明: 版权归作者所有,未经许可不得转载,侵权必究!联系作者请加公众号。
References
apache/rocketmq. Retrieved from https://github.com/apache/rocketmq
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK