

懒人畅听网,有声小说类目数据采集,多线程速采案例,Python爬虫120例之23例 - InfoQ...
source link: https://xie.infoq.cn/article/f60922d5aa9e2bfd48e9c46eb
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

懒人畅听网,有声小说类目数据采集,多线程速采案例,Python 爬虫 120 例之 23 例
- 2021 年 11 月 14 日
本文字数:1706 字
阅读完需:约 6 分钟
多线程在 Python 爬虫学习过程中应用落地,提速,提速,再提速。
目标站点分析
本次要抓取的目标为懒人畅听网,其中我随机选择了一个分类,有声小说频道,其余频道可使用雷同的办法抓取,增加遍历之后,可以对全站进行抓取。
列表页分页规则如下本次依旧只对列表页数据进行提取,只增加多线程模块 threading 的应用,提高采集效率。
http://www.lrts.me/book/category/1/recommend/1/20http://www.lrts.me/book/category/1/recommend/2/20
提取规则模板如下:
http://www.lrts.me/book/category/1/recommend/页码/20全站页码数,可以直接人眼读取,如果增加动态获取,提取读取一下分页处数据即可。
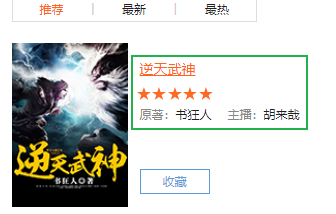
提取最终的数据源如下图所示,包括书名,作者,主播三部分内容。
本次案例中对于多线程部分,除共享全局变量外,增加信号量机制,即限制线程并发数量。
信号量机制的简单 Demo 如下所示:
import threadingimport timedef run(n, semaphore):# 加锁semaphore.acquire()time.sleep(2)print(f'正在运行线程{n}')# 释放锁semaphore.release()if __name__ == '__main__':num = 0# 最多允许 3 个线程同时运行semaphore = threading.BoundedSemaphore(3)for i in range(10):t = threading.Thread(target=run, args=(f'线程号:{i}', semaphore))t.start()while threading.active_count() != 1:passelse:print('所有线程运行完毕')
运行代码,会发现先运行 3 个线程,再运行 3 个线程,当然同时运行的线程之间是没有先后顺序的。
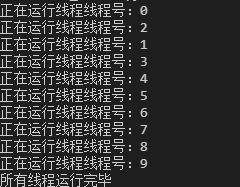
信号量,即使用 threading 模块的 BoundedSemaphore 类,该类可以设置允许一定数量的线程更改数据,即最多可同时运行几个线程。
代码完整案例如下所示
import threadingfrom threading import Lock,Threadimport random,requestsfrom lxml import etreedef get_headers():uas = ["Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)",]ua = random.choice(uas)headers = {"user-agent": ua,"referer": "https://www.baidu.com/"}return headersdef run(url,semaphore):headers = get_headers()semaphore.acquire() #加锁res = requests.get(url,headers=headers,timeout=5)if res:text = res.textelement = etree.HTML(text)titles = element.xpath('//a[@class="book-item-name"]/text()')authors = element.xpath('//a[@class="author"]/text()')weakens = element.xpath('//a[@class="g-user-shutdown"]/text()')save(url,titles,authors,weakens)semaphore.release() #释放def save(url,titles,authors,weakens):data_list = zip(titles,authors,weakens)for item in data_list:with open("./data.csv","a+",encoding="utf-8") as f:f.write(f"{item[0]},{item[1]},{item[2]}\n")print(url,"该URL地址数据写入完毕")if __name__== '__main__':lock = Lock()url_format = 'https://www.lrts.me/book/category/1/recommend/{}/20'# 拼接URL,全局共享变量urls = [url_format.format(i) for i in range(1, 1372)]l = []semaphore = threading.BoundedSemaphore(5) # 最多允许5个线程同时运行for url in urls:t = threading.Thread(target=run,args=(url,semaphore))t.start()while threading.active_count() !=1:passelse:print('所有线程运行完毕')
代码中 threading.active_count() 部分,用于检测是否存在活跃线程,如无,程序结束。
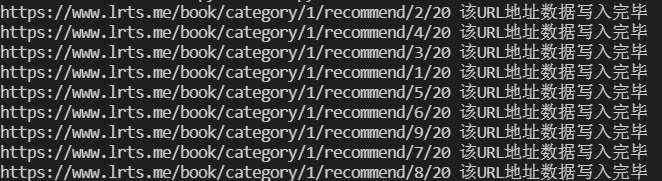
运行代码,得到如下结果,至此第 23 例已经学习完毕。
代码仓库地址:https://codechina.csdn.net/hihell/python120,去给个关注或者 Star 吧。
来都来了,不发个评论,点个赞,收个藏吗?
今天是持续写作的第 203/ 365 天。可以关注我,点赞我、评论我、收藏我啦。
版权声明: 本文为 InfoQ 作者【梦想橡皮擦】的原创文章。
原文链接:【https://xie.infoq.cn/article/f60922d5aa9e2bfd48e9c46eb】。文章转载请联系作者。

梦想橡皮擦
爬虫 100 例作者,蓝桥签约作者,博客专家 2021.02.06 加入
6 年产品经理+教学经验,3 年互联网项目管理经验; 互联网资深爱好者; 沉迷各种技术无法自拔,导致年龄被困在 25 岁; CSDN 爬虫 100 例作者。 个人公众号“梦想橡皮擦”。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK