

关于缓存更新的一些可借鉴套路
source link: https://my.oschina.net/jiagoujingjin/blog/5302714
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

hello,大家好,我是张张,「架构精进之路」公号作者。
一、背景
目前随着缓存架构方案越来越成熟化,通常做法是引入「缓存」来提高读性能,架构模型就变成了这样:
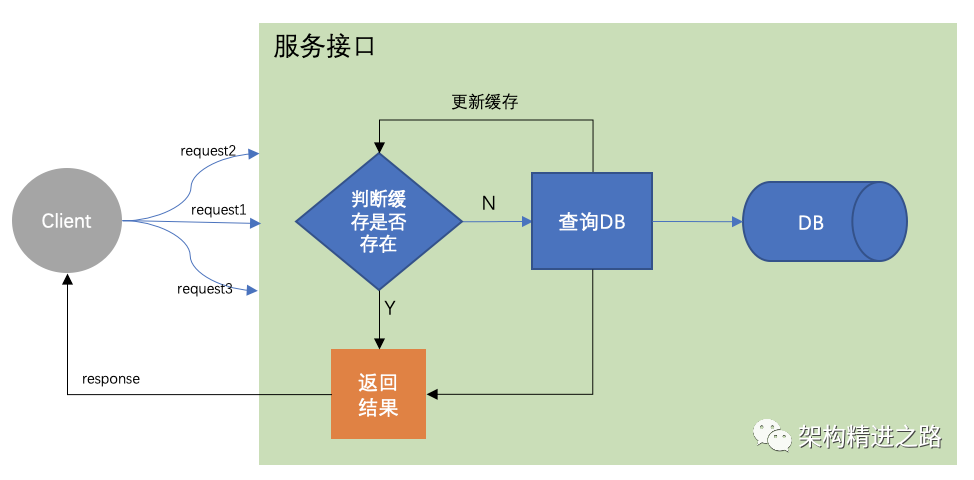
先来看一下什么时候创建缓存,前端请求的读操作先从缓存中查询数据,如果没有命中数据,则查询数据库,从数据库查询成功后,返回结果,同时更新缓存,方便下次操作。
在数据不发生变更的情况下,这种方式没有问题,如果数据发生了更新操作,就必须要考虑如何操作缓存,保证一致性。
如何保证缓存和数据库的一致性,这算得上是个老生常谈的话题啦,看到好多技术新人在写更新缓存数据代码,采用了非常复杂甚至“诡异”的方案,甚为不解。
今天就一起花点儿时间来聊聊吧~
二、缓存和数据库数据一致性问题
1)先更新缓存,后更新数据库
如果缓存更新成功了,但数据库更新失败,那么此时缓存中是最新值,但数据库中是「旧值」。
虽然此时读请求可以命中缓存,拿到正确的值,但是,一旦缓存「失效」,就会从数据库中读取到「旧值」,重建缓存也是这个旧值。
这时用户会发现自己之前修改的数据又「变回去」了,对业务造成影响。
2)先更新数据库,后更新缓存
如果数据库更新成功了,但缓存更新失败,那么此时数据库中是最新值,缓存中是「旧值」。
之后的读请求读到的都是旧数据,只有当缓存「失效」后,才能从数据库中得到正确的值。
这时用户会发现,自己刚刚修改了数据,但却看不到变更,一段时间过后,数据才变更过来,对业务也会有影响。
可见,上面两种情况,无论谁先谁后,但凡后者发生异常,就会对业务造成影响。那怎么解决这个问题呢?
三、缓存更新Design Pattern介绍几个也许有效的套路给大家吧~ 希望有帮助。
1)Cache Aside Pattern
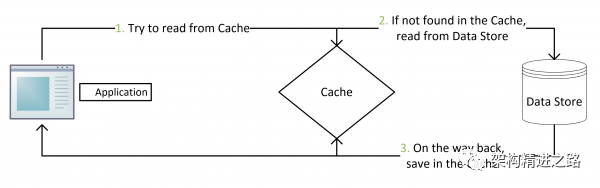

如上图所示,一个是查询操作,一个是更新操作的并发。
首先,没有了删除cache数据的操作了,而是先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。而不会像文章开头的那个逻辑产生的问题,后续的查询操作一直都在取旧数据。
那么,是不是Cache Aside这个就不会有并发问题了?
比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
2)Read/Write Through Pattern
Read Through
Read Through 套路就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或LRU换出),Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。
Write Through
Write Through 套路和Read Through相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作)
操作逻辑如下图所示:

3)Write Behind Caching Pattern
基本逻辑如下:
Write Behind 又叫 Write Back。
简单说就是,在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(直接操作内存的嘛 ),因为异步,write backg还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
但是,其带来的问题是,数据不是强一致性的,而且可能会丢失(我们知道Unix/Linux非正常关机会导致数据丢失,类似这种情况)。
另外,Write Back实现逻辑比较复杂,因为他需要track有哪些数据是被更新了的,需要刷到持久层上。操作系统的write back会在仅当这个cache需要失效的时候,才会被真正持久起来,比如,内存不够了,或是进程退出了等情况,这又叫lazy write。
四、总结
对于这个老生常谈的问题,分析起来其实并不简单。
额外分享几点自己心得给你:
1、性能和一致性不能同时满足,为了性能考虑,通常会采用「最终一致性」的方案;
2、掌握缓存和数据库一致性问题,核心问题有 3 点:缓存利用率、并发、缓存 + 数据库一起成功问题;
3、失败场景下要保证一致性,常见手段就是「重试」,同步重试会影响吞吐量,所以通常会采用异步重试的方案;
4、订阅变更日志的思想,本质是把权威数据源(例如 MySQL)当做 leader 副本,让其它异质系统(例如 Redis / Elasticsearch)成为它的 follower 副本,通过同步变更日志的方式,保证 leader 和 follower 之间保持一致。
🎉 福利:关注公众号回复关键字:Redis,即可免费获取《Redis设计与实现》电子书
·················· END ··················
关注公众号,免费领学习资料
十年研发路,大厂架构师,CSDN博客专家
专注架构技术学习及分享,职业与认知升级
坚持分享接地气儿的干货,期待与你一起成长

「架构精进之路」专注架构研究,技术分享
点“赞”和“在看”哦
Recommend
-
81
-
47
-
61
借鉴Uber路测教训 中国要求驾驶人须始终处于驾驶位
-
88
借鉴开源框架自研日志收集系统
-
79
项目背景公司项目需要将分布在多台机器中的日志统一收集管理。笔者先后使用logstash,flume等开源项目。并最终自研一套基于Java语言的日志收集系统 Bloodhound。以下从项目关注的角度对开源系统与自研进行分析。1…
-
53
导读 The Intercept 又爆料谷歌为了遵守中国方面的审查要求,一直在通过其中国网站 265.com 收集需要过滤的内容。 上周 The Intercept 爆料谷歌计划在中国大陆重启其搜索业务,目前谷歌还没有对此传闻做出正面回应,而 9 日,The Intercept 又...
-
6
从 CPU 缓存看缓存的套路 2020-09-24 ...
-
9
缓存更新的套路 缓存更新的套路 看到好些人在写更新缓存数据代码时,先删除缓存,然后再更新数据库,而后续...
-
8
本文记录一些代码审查套路,在看到小伙伴写出某些代码的时候可以告诉他这样写有锅 我在各个项目里面进行代码审查,我维护了很多个项目
-
6
V2EX › 职场话题 来日好几年了,讲一些黑公司常见套路 NPC666 · 15 小时 35 分钟前 · 3529 次...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK