

实战!《长津湖》为什么这么火爆?我用 Python 来分析猫眼影评
source link: https://blog.csdn.net/weixin_38037405/article/details/120688529
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
实战!《长津湖》为什么这么火爆?我用 Python 来分析猫眼影评
作者:周萝卜 链接:长津湖猫眼影评
欢迎关注 ,专注Python、数据分析、数据挖掘、好玩工具!
对于这个十一黄金周的电影市场,绝对是《长津湖》的天下,短短几天,票房就已经突破36亿,大有奋起直追《战狼2》的尽头。而且口碑也是相当的高,猫眼评分高达9.5,绝对的票房口碑双丰收啊

下面我们就通过爬取猫眼的电影评论,进行相关的可视化分析,看看为什么这部电影是如此的受欢迎,最后还进行了简单的票房预测,你一定不能错过哦,欢迎收藏学习,点赞支持,喜欢技术交流的可以文末技术交流群。
猫眼评论爬取,还是那么老一套,直接构造 API 接口信息即可
url = "https://m.maoyan.com/mmdb/comments/movie/257706.json?v=yes&offset=30"
payload={}
headers = {
'Cookie': '_lxsdk_cuid=17c188b300d13-0ecb2e1c54bec6-a7d173c-100200-17c188b300ec8; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1633622378; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; __mta=87266087.1633622378325.1633622378325.1633622378325.1; uuid_n_v=v1; iuuid=ECBA18D0278711EC8B0DFD12EB2962D2C4A641A554EF466B9362A58679FDD6CF; webp=true; ci=55%2C%E5%8D%97%E4%BA%AC; ci=55%2C%E5%8D%97%E4%BA%AC; ci=55%2C%E5%8D%97%E4%BA%AC; featrues=[object Object]; _lxsdk=92E6A4E0278711ECAE4571A477FD49B513FE367C52044EB5A6974451969DD28A; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1633622806',
'Host': 'm.maoyan.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'
}
response = requests.request("GET", url, headers=headers, data=payload)
print(response.json())
这么几行代码,我们就可以得到如下结果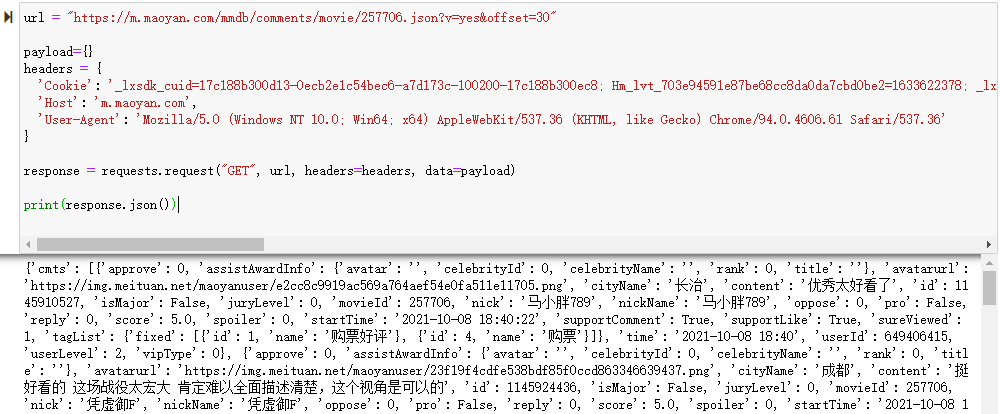
获取到数据后,我们就可以解析返回的 json 数据,并保存到本地了
先写一个保存数据的函数
def save_data_pd(data_name, list_info):
if not os.path.exists(data_name + r'_data.csv'):
# 表头
name = ["comment_id","approve","reply","comment_time","sureViewed","nickName",
"gender","cityName","userLevel","user_id","score","content"]
# 建立DataFrame对象
file_test = pd.DataFrame(columns=name, data=list_info)
# 数据写入
file_test.to_csv(data_name + r'_data.csv', encoding='utf-8', index=False)
else:
with open(data_name + r'_data.csv', 'a+', newline='', encoding='utf-8') as file_test:
# 追加到文件后面
writer = csv.writer(file_test)
# 写入文件
writer.writerows(list_info)
直接通过 Pandas 来保存数据,可以省去很多数据处理的事情
接下来编写解析 json 数据的函数
def get_data(json_comment):
list_info = []
for data in json_comment:
approve = data["approve"]
comment_id = data["id"]
cityName = data["cityName"]
content = data["content"]
reply = data["reply"]
# 性别:1男,2女,0未知
if "gender" in data:
gender = data["gender"]
else:
gender = 0
nickName = data["nickName"]
userLevel = data["userLevel"]
score = data["score"]
comment_time = data["startTime"]
sureViewed = data["sureViewed"]
user_id = data["userId"]
list_one = [comment_id, approve, reply, comment_time, sureViewed, nickName, gender, cityName, userLevel,
user_id, score, content]
list_info.append(list_one)
save_data_pd("maoyan", list_info)
我们把几个主要的信息提取出来,比如用户的 nickname,评论时间,所在城市等等
最后把上面的代码整合,并构造爬取的 url 即可
def fire():
tmp = "https://m.maoyan.com/mmdb/comments/movie/257706.json?v=yes&offset="
payload={}
headers = {
'Cookie': '_lxsdk_cuid=17c188b300d13-0ecb2e1c54bec6-a7d173c-100200-17c188b300ec8; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1633622378; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; __mta=87266087.1633622378325.1633622378325.1633622378325.1; uuid_n_v=v1; iuuid=ECBA18D0278711EC8B0DFD12EB2962D2C4A641A554EF466B9362A58679FDD6CF; webp=true; ci=55%2C%E5%8D%97%E4%BA%AC; ci=55%2C%E5%8D%97%E4%BA%AC; ci=55%2C%E5%8D%97%E4%BA%AC; featrues=[object Object]; _lxsdk=92E6A4E0278711ECAE4571A477FD49B513FE367C52044EB5A6974451969DD28A; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1633622806',
'Host': 'm.maoyan.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'
}
for i in range(0, 3000, 15):
url = tmp + str(i)
print(url)
response = requests.request("GET", url, headers=headers, data=payload)
comment = response.json()
if not comment.get("hcmts"):
break
hcmts = comment['hcmts']
get_data(hcmts)
cmts = comment['cmts']
get_data(cmts)
time.sleep(10)
爬取过程如下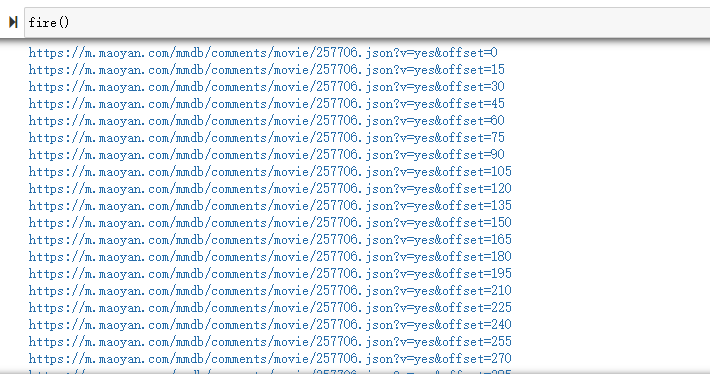
保存到本地的数据如下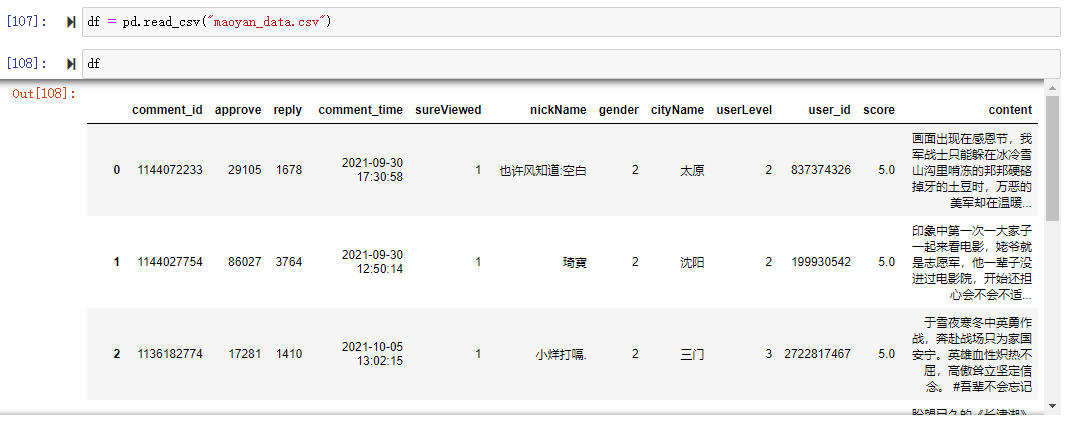
下面我们就可以进行相关的可视化分析了
可视化分析
1 数据清洗
我们首先根据 comment_id 来去除重复数据
df_new = df.drop_duplicates(['comment_id'])
对于评论内容,我们进行去除非中文的操作
def filter_str(desstr,restr=''):
#过滤除中文以外的其他字符
res = re.compile("[^\u4e00-\u9fa5^,^,^.^。^【^】^(^)^(^)^“^”^-^!^!^?^?^]")
# print(desstr)
res.sub(restr, desstr)
2 评论点赞及回复榜
我们先来看看哪些评论是被点赞最多的
approve_sort = df_new.sort_values(by=['approve'], ascending=False)
approve_sort = df_new.sort_values(by=['approve'], ascending=False)
x_data = approve_sort['nickName'].values.tolist()[:10]
y_data = approve_sort['approve'].values.tolist()[:10]
b = (Bar()
.add_xaxis(x_data)
.add_yaxis('',y_data)
.set_global_opts(title_opts = opts.TitleOpts(title='评论点赞前十名'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
.reversal_axis()
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()

可以看到位于榜首的是一个叫“琦寶”的观众写的评论,点赞量高达86027
再来看看评论回复的情况
reply_sort = df_new.sort_values(by=['reply'], ascending=False)
x_data = reply_sort['nickName'].values.tolist()[:10]
y_data = reply_sort['reply'].values.tolist()[:10]
b = (Bar()
.add_xaxis(x_data)
.add_yaxis('',y_data)
.set_global_opts(title_opts = opts.TitleOpts(title='评论回复前十名'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
.reversal_axis()
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()

回复量最高的同样是“琦寶”的评论,很好奇,他到底写了什么呢,快来看看
df_new[df_new['nickName'].str.contains('琦寶')]['content'].values.tolist()[0]
Output:
'印象中第一次一大家子一起来看电影,姥爷就是志愿军,他一辈子没进过电影院,开始还担心会不会不适应,感谢影院工作人员的照顾,
姥爷全程非常投入,我坐在旁边看到他偷偷抹了好几次眼泪,刚才我问电影咋样,一直念叨“好,好哇,我们那时候就是那样的,就是那样的……”\n忽然觉得历史长河与我竟如此之近,刚刚的三个小时我看到的是遥远的70年前、是教科书里的战争,更是姥爷的19岁,是真真切切的、他的青春年代!'
还真的是非常走心的评论,而且自己的家人就有经历过长津湖战役的经历,那么在影院观影的时候,肯定会有不一样的感受!
当然我们还可以爬取每条评论的reply信息,通过如下接口
https://i.maoyan.com/apollo/apolloapi/mmdb/replies/comment/1144027754.json?v=yes&offset=0
只需要替换 json 文件名称为对应的 comment_id 即可,这里就不再详细介绍了,感兴趣的朋友自行探索呀
下面我们来看一下整体评论数据的情况
3 各城市排行
来看看哪些城市的评论最多呢
result = df_new['cityName'].value_counts()[:10].sort_values()
x_data = result.index.tolist()
y_data = result.values.tolist()
b = (Bar()
.add_xaxis(x_data)
.add_yaxis('',y_data)
.set_global_opts(title_opts = opts.TitleOpts(title='评论城市前十'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
.reversal_axis()
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()

一线大城市纷纷上榜,看来这些城市的爱国主义教育做的还是要好很多呀
再来看看城市的全国地图分布
result = df_new['cityName'].value_counts().sort_values()
x_data = result.index.tolist()
y_data = result.values.tolist()
city_list = [list(z) for z in zip(x_data, y_data)]

可以看到,这个评论城市的分布,也是与我国总体经济的发展情况相吻合的
4 性别分布
再来看看此类电影,对什么性别的观众更具有吸引力
attr = ["其他","男","女"]
b = (Pie()
.add("", [list(z) for z in zip(attr, df_new.groupby("gender").gender.count().values.tolist())])
.set_global_opts(title_opts = opts.TitleOpts(title='性别分布'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()

在填写了性别的数据当中,女性竟然多一些,这还是比较出乎意料的
5 是否观看
猫眼是可以在没有观看电影的情况下进行评论的,我们来看看这个数据的情况
result = df_new["sureViewed"].value_counts()[:10].sort_values().tolist()
b = (Pie()
.add("", [list(z) for z in zip(["未看过", "看过"], result)])
.set_global_opts(title_opts = opts.TitleOpts(title='是否观看过'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()

大部分人都是在观看了之后才评论的,这要在一定程度上保证了评论和打分的可靠性
6 评分分布
猫眼页面上是10分制,但是在接口当中是5分制
result = df_new["score"].value_counts().sort_values()
x_data = result.index.tolist()
y_data = result.values.tolist()
b = (Bar()
.add_xaxis(x_data)
.add_yaxis('',y_data)
.set_global_opts(title_opts = opts.TitleOpts(title='评分分布'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
.reversal_axis()
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()

可以看到5-4.5评论占据了大部分,口碑是真的好啊
7 评论时间分布
对于评论时间,我这里直接使用了原生的 echarts 来作图
from collections import Counter
result = df_new["comment_time"].values.tolist()
result = [i.split()[1].split(":")[0] + "点" for i in result]
result_dict = dict(Counter(result))
result_list = []
for k,v in result_dict.items():
tmp = {}
tmp['name'] = k
tmp['value'] = v
result_list.append(tmp)
children_dict = {"children": result_list}
示例地址:https://echarts.apache.org/examples/zh/editor.html?c=treemap-sunburst-transition

能够看出,在晚上的19点和20点,都是大家写评论的高峰期,一天的繁忙结束后,写个影评放松下
8 每天评论分布
接下来是每天的评论分布情况
result = df_new["comment_time"].values.tolist()
result = [i.split()[0] for i in result]
result_dict = dict(Counter(result))
b = (Pie()
.add("", [list(z) for z in zip(result_dict.keys(), result_dict.values())])
.set_global_opts(title_opts = opts.TitleOpts(title='每天评论数量'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()

就目前来看,几乎所有的评论都集中在10月8号,难道是上班第一天,不想上班,只想摸鱼?😂
9 用户等级分布
来看下猫眼评论用户的等级情况,虽然不知道这个等级有啥用😀
result = df_new['userLevel'].value_counts()[:10].sort_values()
x_data = result.index.tolist()
y_data = result.values.tolist()
b = (Bar()
.add_xaxis(x_data)
.add_yaxis('',y_data)
.set_global_opts(title_opts = opts.TitleOpts(title='用户等级'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
.reversal_axis()
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()

大家基本都是 level2,哈哈哈哈,普罗大众嘛
10 主创提及次数
我们再来看看在评论中,各位主创被提及的次数情况
name = ["吴京",
"易烊千玺",
"段奕宏",
"朱亚文",
"李晨",
"胡军",
"王宁",
"刘劲",
"卢奇",
"曹阳",
"李军",
"孙毅",
"易",
"易烊",
"千玺"
]
def actor(data, name):
counts = {}
comment = jieba.cut(str(data), cut_all=False)
# 去停用词
for word in comment:
if word in name:
if word == "易" or word == "千玺" :
word = "易烊千玺"
counts[word] = counts.get(word,0)+1
return counts
counts = actor(','.join(df_comment.values.tolist()), name)

毫无疑问,易烊千玺高举榜首,可能妈妈粉比较多吧,不过人家演技确实也在线
11 评论词云
最后来看看评论的词云情况吧
font = r'C:\Windows\Fonts\FZSTK.TTF'
STOPWORDS = {"回复", "@", "我", "她", "你", "他", "了", "的", "吧", "吗", "在", "啊", "不", "也", "还", "是",
"说", "都", "就", "没", "做", "人", "赵薇", "被", "不是", "现在", "什么", "这", "呢", "知道", "邓", "我们", "他们", "和", "有", "", "",
"要", "就是", "但是", "而", "为", "自己", "中", "问题", "一个", "没有", "到", "这个", "并", "对"}
def wordcloud(data, name, pic=None):
comment = jieba.cut(str(data), cut_all=False)
words = ' '.join(comment)
img = Image.open(pic)
img_array = np.array(img)
wc = WordCloud(width=2000, height=1800, background_color='white', font_path=font, mask=img_array,
stopwords=STOPWORDS, contour_width=3, contour_color='steelblue')
wc.generate(words)
wc.to_file(name + '.png')

明日票房预测
这里我们使用线性回归来进行简单的票房预测,毕竟票房是一个超级复杂的事物,没有办法完全准确的进行预估计
我们先通过 AKShare 库来获取这几天《长津湖》的票房情况
movie_boxoffice_daily_df = ak.movie_boxoffice_daily(date="20211008")
print(movie_boxoffice_daily_df)
movie_boxoffice_daily_df[movie_boxoffice_daily_df['影片名称'].str.contains('长津湖')]['单日票房'].values.tolist()[0]

接下来画散点图,看下趋势情况
def scatter_base(choose, values, date) -> Scatter:
c = (
Scatter()
.add_xaxis(choose)
.add_yaxis("%s/每天票房" % date, values)
.set_global_opts(title_opts=opts.TitleOpts(title=""),
# datazoom_opts=opts.DataZoomOpts(),
yaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter="{value} /万")
)
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
return c
date_list = create_assist_date("20211001", "20211008")
value_list = get_data("长津湖", date_list)
scatter_base(date_list, value_list, '长津湖').render_notebook()

可以看到,从一号开始,单日票房逐步增长,7号达到最高峰,8号开始回落
下面我们来进行数据拟合,使用 sklearn 提供的 linear_model 来进行
date_list = create_assist_date("20211001", "20211008")
value_list = get_data("长津湖", date_list)
X = np.array([1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008])
X = X.reshape(-1, 1)
y = value_list
model = pl.make_pipeline(
sp.PolynomialFeatures(5), # 多项式特征拓展器
lm.LinearRegression() # 线性回归器
)
# 训练模型
model.fit(X, y)
# 求预测值y
pred_y = model.predict(X)
print(pred_y)
# 绘制多项式回归线
px = np.linspace(X.min(), X.max(), 1000)
px = px.reshape(-1, 1)
pred_py = model.predict(px)
# 绘制图像
mp.figure("每天票房数据", facecolor='lightgray')
mp.title('每天票房数据 Regression', fontsize=16)
mp.tick_params(labelsize=10)
mp.grid(linestyle=':')
mp.xlabel('x')
mp.ylabel('y')
mp.scatter(X, y, s=60, marker='o', c='dodgerblue', label='Points')
mp.plot(px, pred_py, c='orangered', label='PolyFit Line')
mp.tight_layout()
mp.legend()
mp.show()

再根据拟合的结果,我们来预测下明天的票房情况

好啦,坐等明天开奖!
本文版权归原作者所有,如有内容版权等问题请联系我,本文仅供交流学习使用
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK