

Pytorch入门教程13-卷积神经网络的CIFAR-10的识别
source link: https://mathpretty.com/12551.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

摘要这一篇我们会使用Pytorch实现一个简单的卷积网络. 主要会介绍卷积神经网络在CIFAR-10数据集上的分类. 除了介绍完整的训练过程以外, 我们还会对卷积操作进行相应的介绍.
上一篇我们介绍了全连接网络在手写数字上的识别. 这一篇我们介绍卷积神经网络在CIFAR-10数据集上的分类. 除了介绍完整的训练过程以外, 我们还会对卷积操作进行相应的介绍.
卷积的一些介绍
关于通过卷积后图像的大小
首先我们说明一下通过卷积之后图像大小的变化. 假设有以下的参数:
- 原始图像的大小是, (N_h, N_w);
- 卷积核大小是, (K_h, K_w);
那么此时output的大小如下:
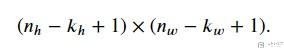
接着我们加上padding, 此时在行的padding是P_h, 在列的padding是P_w, 此时的output的大小是:
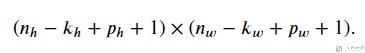
与上面相比, 只是单纯的在height和width上加上了P_h和P_w. 通常情况下, 我们会进行如下的设置:
- P_h = K_h - 1
- P_w = K_w - 1
这样输出图形的大小和输入图像的大小是一样的. 于是, 当我们将kernel size的大小选择为奇数的时候, 最后padding是偶数, 这样就可以在图像上下(或是左右)进行平均分配.
我们看下面的例子, 为了简单起见, 我们将input channel和output channel都设置为1. kernel size=(5,3), 这时候我们按照上面的式子进行设置, padding应该是(4,2). 但是实际上我们4的话需要左右平分, 所以最后padding是(2,1), 这样可以保持输入图形大小和输出图形大小是一样的. 下面是详细的代码.
- conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
- X = torch.rand(size=(8, 8))
- conv2d(X.reshape(1,1,8,8)).shape
- torch.Size([1, 1, 8, 8])
这个时候如果我们再加上stride, 例如在height上stride是S_h, 在width上的stride是S_w. 此时输出大小是:
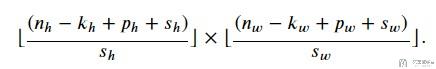
下面看一个比较复杂的例子, 此时:
- input size, 8*8 (H*W)
- kernel size, 5*6
- padding, 0*1, 注意这里padding的只代表一侧的, 比如说此时W是1, 表示是在侧面加1, 因为有左右, 实际上padding=2
- stride, 3*4
于是我们按照上面的公式进行计算, 得到下面的式子.
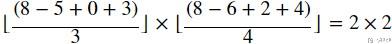
我们使用Pytorch做一下相应的实验, 结果也是和我们预期是一样的.
- conv2d = nn.Conv2d(1, 1, kernel_size=(5, 6), padding=(0, 1), stride=(3, 4))
- X = torch.rand(size=(8, 8))
- conv2d(X.reshape(1,1,8,8)).shape
- torch.Size([1, 1, 2, 2])
关于多通道的说明
当input data有多个channel的时候, 例如此时是channel=c, 那么此时kernel也是拥有相应数量的通道, 是c. 我们可以将kernel想成一个立方体. 下面看一个例子.
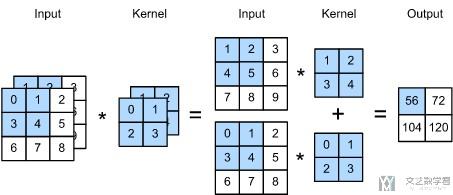
此时原始数据是双通道的, 于是kernel也是双通道的. 我们就可以把其看成一个222的正方体. 比如说上图中的运算, 就是在每一个channel分别计算, 最后相加有下面的式子:
- (1*1+2*2+3*4+5*4)+(0*0+1*1+3*2+4*3)=56.
我们使用Pytorch实现以上面的操作, 看一下最终结果是否可以预期的是一样的. 可以看到最终输出的结果与上面图中是一样的.
- # 得到模拟的训练样本
- X = torch.tensor([[[0, 1, 2], [3, 4, 5], [6, 7, 8]],
- [[1, 2, 3], [4, 5, 6], [7, 8, 9]]], dtype=torch.float32)
- conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=2, bias=False)
- # 初始化kernel的系数
- conv2d.weight.data = torch.tensor([[[0, 1], [2, 3]], [[1, 2], [3, 4]]], dtype=torch.float32).unsqueeze_(0)
- conv2d(X.unsqueeze_(0))
- tensor([[[[ 56., 72.],
- [104., 120.]]]], grad_fn=<MkldnnConvolutionBackward>)
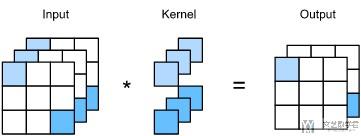
接下来讨论当output有多个channels的时候. (通常情况下, 每一个channel都会表示不同的特征.) 于是, 这里output有多个channel的时候, 相当于有多个立方体, 每一个立方体输出是一个channel.
下面我们来看一下11的卷积, 来看一下有多个input channel和多个output channel下的情况. 11的卷积只会计算channel与channel之间的关系. 例如下图展示了input channel=3, output channel=2的情况. 这个时候1个output channel就是对应一个113的立方体, 这里因为output channel=2, 共有两个这样的立方体.
关于池化(Pooling)的一些说明
池化是为了解决图像对于位置敏感的问题. 例如现在有一个像素点是在x[i,j]的位置, 可能在别的图片中进行了位移, 在x[i+k, j+k]的位置, 如果是池化的化, 这一片输出值是相同的.
同时, 我们需要注意池化层是没有参数的, 常见的池化操作有max和average. 同时对于多通道的数据进行池化操作, 就是对每个channel进行单独操作, 并不会像卷积操作那样, 不同channel之间会有运算. 且池化操作, 输入的channel和输出的channel是相同的. 下面来看一个例子.
现在我们有如下的数据, 是一个两通道的数据.
- X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
- X = torch.cat((X, X + 1), dim=1)
- tensor([[[[ 0., 1., 2., 3.],
- [ 4., 5., 6., 7.],
- [ 8., 9., 10., 11.],
- [12., 13., 14., 15.]],
- [[ 1., 2., 3., 4.],
- [ 5., 6., 7., 8.],
- [ 9., 10., 11., 12.],
- [13., 14., 15., 16.]]]])
我们对其进行最大池化, 最终的结果也是2个channel, 最终结果如下所示.
- pool2d = nn.MaxPool2d(3, padding=0, stride=1)
- pool2d(X)
- tensor([[[[10., 11.],
- [14., 15.]],
- [[11., 12.],
- [15., 16.]]]])
例如输出的14, 就是max(4,5,6,8,9,10,12,13,14)=14, 其余位置的计算均类似.
CIFAR-10数据集介绍
CIFAR-10数据集有10个类, 每类6000个332*32的彩色图像, 共60000个32x32 的彩色图像组成. 下面是从每一类挑出10张照片:

这10类图片分别是:
- airplane, 飞机
- automobile, 汽车
- bird, 小鸟
- cat, 小猫
- deer, 小鹿
- dog, 小狗
- frog, 青蛙
- horse, 小马
- ship, 小船
- trunk, 卡车
这10类中, 每一类有6000张照片, 其中有5000张在训练集中, 1000张在测试集中. 所以训练集有500010=50000张图片; 测试集中有100010=10000张图片.
卷积网络在CIFAR-10的识别
这次的数据量还是比较大的, 我们使用GPU来进行训练.
- import torch
- import torch.nn as nn
- import torchvision
- import torchvision.transforms as transforms
- import torch.nn.functional as F
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib inline
- # Device configuration
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- device
- device(type='cuda')
接着我们定义一下数据集中的10个类别和他们对应的名字.
- # 定义class
- classes = ('plane', 'car', 'bird', 'cat',
- 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
数据加载与数据预处理
我们使用CIFAR-10数据集, 该数据集可以使用torchvision.datasets.CIFAR10获得. 这一阶段的任务如下所示:
- 创建dataset
- 加载CIFAR10数据
- 进行数据预处理, (转换为tensor, 进行标准化)
- 下面简单说明以下为什么标准化里的参数都是0.5, 这可以保证标准化之后的图像的像素值在-1到1之间. 这是因为: For example, the minimum value 0 will be converted to (0-0.5)/0.5=-1, the maximum value of 1 will be converted to (1-0.5)/0.5=1.
- 创建dataloader
- 将dataset传入dataloader, 设置batchsize
首先我们创建dataset, 同时进行数据预处理(数据预处理有两个步骤, 如上面所介绍的).
- # 将数据集合下载到指定目录下,这里的transform表示,数据加载时所需要做的预处理操作
- transform = transforms.Compose(
- [transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
- # 加载训练集合(Train)
- train_dataset = torchvision.datasets.CIFAR10(root='./data',
- train=True,
- transform=transform,
- download=True)
- # 加载测试集合(Test)
- test_dataset = torchvision.datasets.CIFAR10(root='./data',
- train=False,
- transform=transform,
- download=True)
接着设置dataloader, 设置batchsize的大小. 这里的dataloader就是训练的时候会用到的.
- batch_size = 10
- # 根据数据集定义数据加载器
- train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
- batch_size=batch_size,
- shuffle=True)
- test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
- batch_size=batch_size,
- shuffle=False)
最后查看一下样例数据(样例图像), 注意如何查看dataloader中的数据(这里查看的时候, 我们要对图像进行反归一化):
- def imshow(img):
- img = img / 2 + 0.5 # unnormalize
- npimg = img.numpy()
- plt.imshow(np.transpose(npimg, (1, 2, 0)))
- plt.show()
- # get some random training images
- dataiter = iter(train_loader)
- images, labels = dataiter.next()
- # show images
- imshow(torchvision.utils.make_grid(images, nrow=5))
- # print labels
- print(' '.join('%5s' % classes[labels[j]] for j in range(10)))

卷积网络的构建
接下来我们定义卷积网络, 我们测试一下浅层的卷积网络.
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- self.conv1 = nn.Conv2d(3, 6, 5)
- self.pool = nn.MaxPool2d(2, 2)
- self.conv2 = nn.Conv2d(6, 16, 5)
- self.fc1 = nn.Linear(16 * 5 * 5, 120)
- self.fc2 = nn.Linear(120, 84)
- self.fc3 = nn.Linear(84, 10)
- def forward(self, x):
- x = self.pool(F.relu(self.conv1(x))) # n*6*14*14
- x = self.pool(F.relu(self.conv2(x))) # n*16*5*5
- x = x.view(-1, 16 * 5 * 5) # n*400
- x = F.relu(self.fc1(x)) # n*120
- x = F.relu(self.fc2(x)) # n*84
- x = self.fc3(x) # n*10
- return x
- net = Net().to(device)
- print(net)
- (conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
- (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
- (fc1): Linear(in_features=400, out_features=120, bias=True)
- (fc2): Linear(in_features=120, out_features=84, bias=True)
- (fc3): Linear(in_features=84, out_features=10, bias=True)
网络定义好之后, 为了测试是否可以使用, 我们用数据集简单测试一下.
- # 简单测试模型的输出
- examples = iter(test_loader)
- example_data, _ = examples.next()
- net(example_data.to(device)).shape
- torch.Size([10, 10])
定义损失函数和优化器
这一步没有什么特殊的, 损失函数为交叉熵损失, 优化器为SGD优化器.
- criterion = nn.CrossEntropyLoss()
- optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
模型的训练与测试
接下来就是模型的训练和测试. 这一部分的代码和前面全连接部分是差不多的.
- num_epochs = 10
- n_total_steps = len(train_loader)
- LossList = [] # 记录每一个epoch的loss
- AccuryList = [] # 每一个epoch的accury
- for epoch in range(num_epochs):
- # -------
- # 开始训练
- # -------
- net.train() # 切换为训练模型
- totalLoss = 0
- for i, (images, labels) in enumerate(train_loader):
- images = images.to(device) # 图片大小转换
- labels = labels.to(device)
- # 正向传播以及损失的求取
- outputs = net(images)
- loss = criterion(outputs, labels)
- totalLoss = totalLoss + loss.item()
- # 反向传播
- optimizer.zero_grad() # 梯度清空
- loss.backward() # 反向传播
- optimizer.step() # 权重更新
- if (i+1) % 1000 == 0:
- print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, n_total_steps, totalLoss/(i+1)))
- LossList.append(totalLoss/(i+1))
- # ---------
- # 开始测试
- # ---------
- net.eval()
- with torch.no_grad():
- correct = 0
- total = 0
- for images, labels in test_loader:
- images = images.to(device)
- labels = labels.to(device)
- outputs = net(images)
- _, predicted = torch.max(outputs.data, 1) # 预测的结果
- total += labels.size(0)
- correct += (predicted == labels).sum().item()
- acc = 100.0 * correct / total # 在测试集上总的准确率
- AccuryList.append(acc)
- print('Accuracy of the network on the {} test images: {} %'.format(total, acc))
- print("模型训练完成")
- Accuracy of the network on the 10000 test images: 62.8 %
- Epoch [9/10], Step [1000/5000], Loss: 0.8864
- Epoch [9/10], Step [2000/5000], Loss: 0.8912
- Epoch [9/10], Step [3000/5000], Loss: 0.9013
- Epoch [9/10], Step [4000/5000], Loss: 0.9046
- Epoch [9/10], Step [5000/5000], Loss: 0.9081
- Accuracy of the network on the 10000 test images: 62.28 %
- Epoch [10/10], Step [1000/5000], Loss: 0.8363
- Epoch [10/10], Step [2000/5000], Loss: 0.8451
- Epoch [10/10], Step [3000/5000], Loss: 0.8562
- Epoch [10/10], Step [4000/5000], Loss: 0.8617
- Epoch [10/10], Step [5000/5000], Loss: 0.8699
- Accuracy of the network on the 10000 test images: 62.26 %
- 模型训练完成
可以看到, 这里模型最终的准确率在60%左右. 这可能是因为模型不够复杂, 无法解决现有的问题. (关于loss和accurcy的变化, 可以查看原始notebook, 卷积神经网络的CIFAR_10的识别.ipynb)
分析每一类的准确率
上面我们获得了模型的一个总的准确率, 下面我们看一下模型对于每一小类的准确率.
- class_correct = list(0. for i in range(10)) # 每一类预测正确的个数
- class_total = list(0. for i in range(10)) # 每一类的总个数
- with torch.no_grad():
- for images, labels in test_loader:
- images = images.to(device)
- labels = labels.to(device)
- outputs = net(images)
- _, predicted = torch.max(outputs, 1)
- c = (predicted == labels).squeeze()
- for i in range(10): # 一个batch中的个数
- label = labels[i]
- class_correct[label] += c[i].item()
- class_total[label] += 1
- for i in range(10):
- print('Accuracy of %5s : %2d %%' % (
- classes[i], 100 * class_correct[i] / class_total[i]))
- Accuracy of plane : 65 %
- Accuracy of car : 81 %
- Accuracy of bird : 43 %
- Accuracy of cat : 25 %
- Accuracy of deer : 60 %
- Accuracy of dog : 66 %
- Accuracy of frog : 73 %
- Accuracy of horse : 67 %
- Accuracy of ship : 73 %
- Accuracy of truck : 65 %
到这里, 我们简单看了一下如何使用Pytorch实现卷积网络, 并完成在CIFAR10数据集上的分类. 但是可以看到, 最终的分类结果不是很理想, 下面我们尝试将网络变深, 来看一下准确率的变化.
VGG16测试
下面的代码和上面是差不多的, 唯一的不同就是把网络的结构变得更加复杂了. 其他的训练方法, 测试方法都是一模一样的.
下面就贴一下模型的代码, 训练部分查看notebook, 卷积神经网络的CIFAR_10的识别.ipynb.
- class VGG16(nn.Module):
- def __init__(self, num_classes=10):
- super(VGG16, self).__init__()
- self.features = nn.Sequential(
- nn.Conv2d(3, 64, kernel_size=3, padding=1),
- nn.BatchNorm2d(64),
- nn.ReLU(True),
- nn.Conv2d(64, 64, kernel_size=3, padding=1),
- nn.BatchNorm2d(64),
- nn.ReLU(True),
- nn.MaxPool2d(kernel_size=2, stride=2),
- nn.Conv2d(64, 128, kernel_size=3, padding=1),
- nn.BatchNorm2d(128),
- nn.ReLU(True),
- nn.Conv2d(128, 128, kernel_size=3, padding=1),
- nn.BatchNorm2d(128),
- nn.ReLU(True),
- nn.MaxPool2d(kernel_size=2, stride=2),
- nn.Conv2d(128, 256, kernel_size=3, padding=1),
- nn.BatchNorm2d(256),
- nn.ReLU(True),
- nn.Conv2d(256, 256, kernel_size=3, padding=1),
- nn.BatchNorm2d(256),
- nn.ReLU(True),
- nn.Conv2d(256, 256, kernel_size=3, padding=1),
- nn.BatchNorm2d(256),
- nn.ReLU(True),
- nn.MaxPool2d(kernel_size=2, stride=2),
- nn.Conv2d(256, 512, kernel_size=3, padding=1),
- nn.BatchNorm2d(512),
- nn.ReLU(True),
- nn.Conv2d(512, 512, kernel_size=3, padding=1),
- nn.BatchNorm2d(512),
- nn.ReLU(True),
- nn.Conv2d(512, 512, kernel_size=3, padding=1),
- nn.BatchNorm2d(512),
- nn.ReLU(True),
- nn.MaxPool2d(kernel_size=2, stride=2),
- nn.Conv2d(512, 512, kernel_size=3, padding=1),
- nn.BatchNorm2d(512),
- nn.ReLU(True),
- nn.Conv2d(512, 512, kernel_size=3, padding=1),
- nn.BatchNorm2d(512),
- nn.ReLU(True),
- nn.Conv2d(512, 512, kernel_size=3, padding=1),
- nn.BatchNorm2d(512),
- nn.ReLU(True),
- nn.MaxPool2d(kernel_size=2, stride=2),
- nn.AvgPool2d(kernel_size=1, stride=1),
- self.classifier = nn.Sequential(
- nn.Linear(512, 4096),
- nn.ReLU(True),
- nn.Dropout(),
- nn.Linear(4096, 4096),
- nn.ReLU(True),
- nn.Dropout(),
- nn.Linear(4096, num_classes),
- #self.classifier = nn.Linear(512, 10)
- def forward(self, x):
- out = self.features(x)
- out = out.view(out.size(0), -1)
- out = self.classifier(out)
- return out
- # 定义当前设备是否支持 GPU
- net = VGG16().to(device)
- # 定义损失函数和优化器
- criterion = nn.CrossEntropyLoss()
- optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
最终的模型的准确率在80%左右, 可以看到在模型变深, 变复杂之后, 在测试集上的准确率得到了上升.

关于每一类的准确率, 请查看notebook, 卷积神经网络的CIFAR_10的识别.ipynb.
Recommend
-
27
1. 前言 深度学习在移动端的应用越来越广泛,而移动端相对于GPU服务来讲算力较低并且存储空间也相对较小。基于这一点我们需要为移动端定制一些深度学习网络来满足我们的日常续需求,例如SqueezeNet,MobileNet...
-
15
C++实现一个识别MNIST数字的卷积神经网络 新的一个财年加入了新的组,从事机器学习相关的工作。由于之前做的一直是iOS(略微底层)方面的事情,初来乍到,对很多东西不熟悉,在超级大神ZB的建议下,用C++实现一个多层前馈神经网...
-
7
文 / 李锡涵,Google Developers Expert 本文节选自《简单粗暴 TensorFlow 2.0》 在
-
9
分享一个CNN模型的pytorch实现集锦,并根据以下文章进行了改进,希望这些工作能对大家所帮助! Awesome CIFAR Zoo 作者:BIGBALLON 来源:https://github.com/BIGBALLON/CIFAR-ZOO...
-
11
一、前期工作 本文将实现灵笼中人物角色的识别。较上一篇文章,这次我采用了VGG-19结构,并增加了预测与保存and加载模型两个部分。 我的环境: 语言环境:Python3.6.5编译器:jupyt...
-
9
TensorFlow 2.0 (五) - mnist手写数字识别(CNN卷积神经网络) 源代码/数据集已上传到
-
3
有人声称「解决了」MNIST与CIFAR 10,实现了100%准确率-51CTO.COM 有人声称「解决了」MNIST与CIFAR 10,实现了100%准确率 作者:机器之心 2022-04-22 10:29:46 MNIST 被认为是机器学习的 Hello W...
-
5
This article was published as a part of the Data Science Blogathon. Introduction In today’s world, the demand for machine learning and artificial intelli...
-
5
在树莓派上实现numpy的conv2d卷积神经网络做图像分类,加载pytorch的模型参数,推理mnist手写数字识别,并使用多进程加速 ...
-
9
[译] 以图像识别为例,关于卷积神经网络(CNN)的直观解释(2016) Published at 2023-06-11 | Last Update 2023-06-11 本文翻译自 2016 年的一篇文章:
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK