
0

一日一技:谁说 Scrapy 不能爬 HTTP/2?
source link: https://www.kingname.info/2021/10/21/scrapy-http2/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一日一技:谁说 Scrapy 不能爬 HTTP/2?

之前有一位爬虫大佬写了一篇文章,说 HTTP/2协议天然就能防大部分的爬虫。Python 无论是 requests 还是 Scrapy 都不支持 HTTP/2协议。
Go + HTTP/2这个网站可以检测你是否使用 HTTP/2协议进行请求。当我们直接使用浏览器访问的时候,页面长这样:
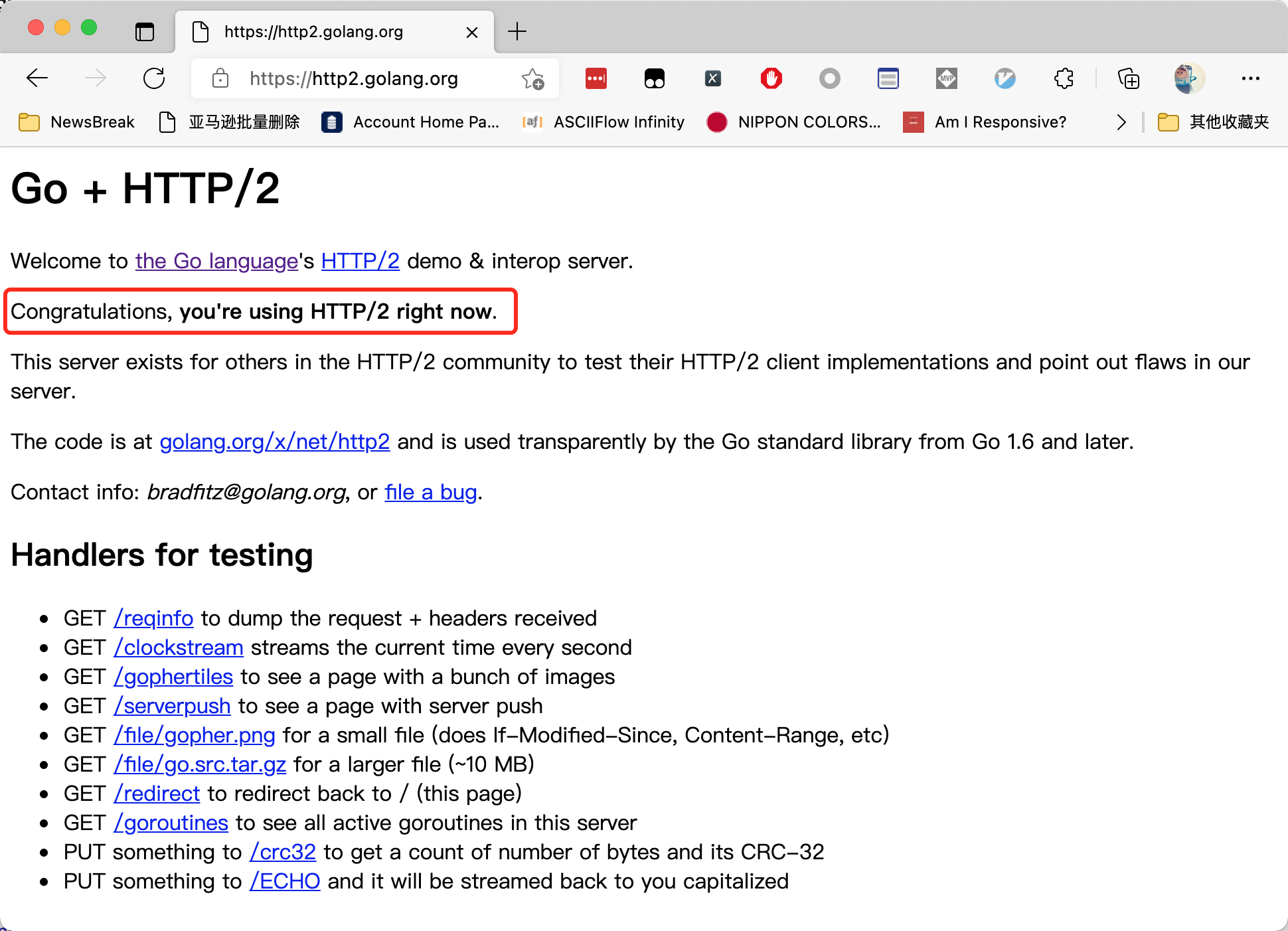
但如果我们直接使用 Scrapy 访问这个页面,并打印源代码,返回的 HTML 长这样:
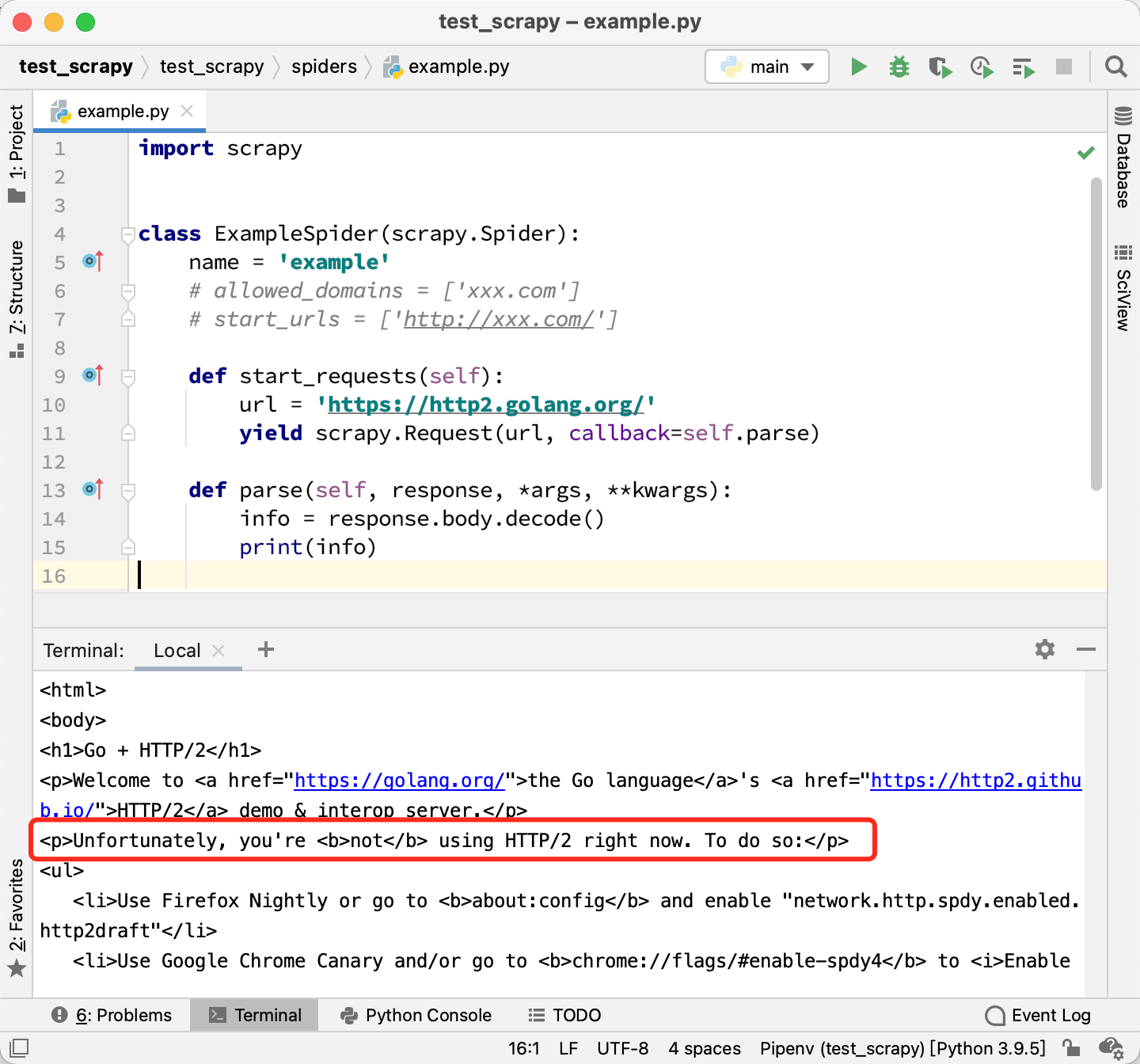
这样看起来,似乎Scrapy 确实不支持HTTP/2协议?
但我为什么总是一直强调要读官方文档,不要去搜索一些垃圾博客呢。因为官方文档里面,已经明确告诉你Scrapy 不仅原生支持 HTTP/2,而且只需要改一个配置就可以了:Settings — Scrapy 2.5.0 documentation。
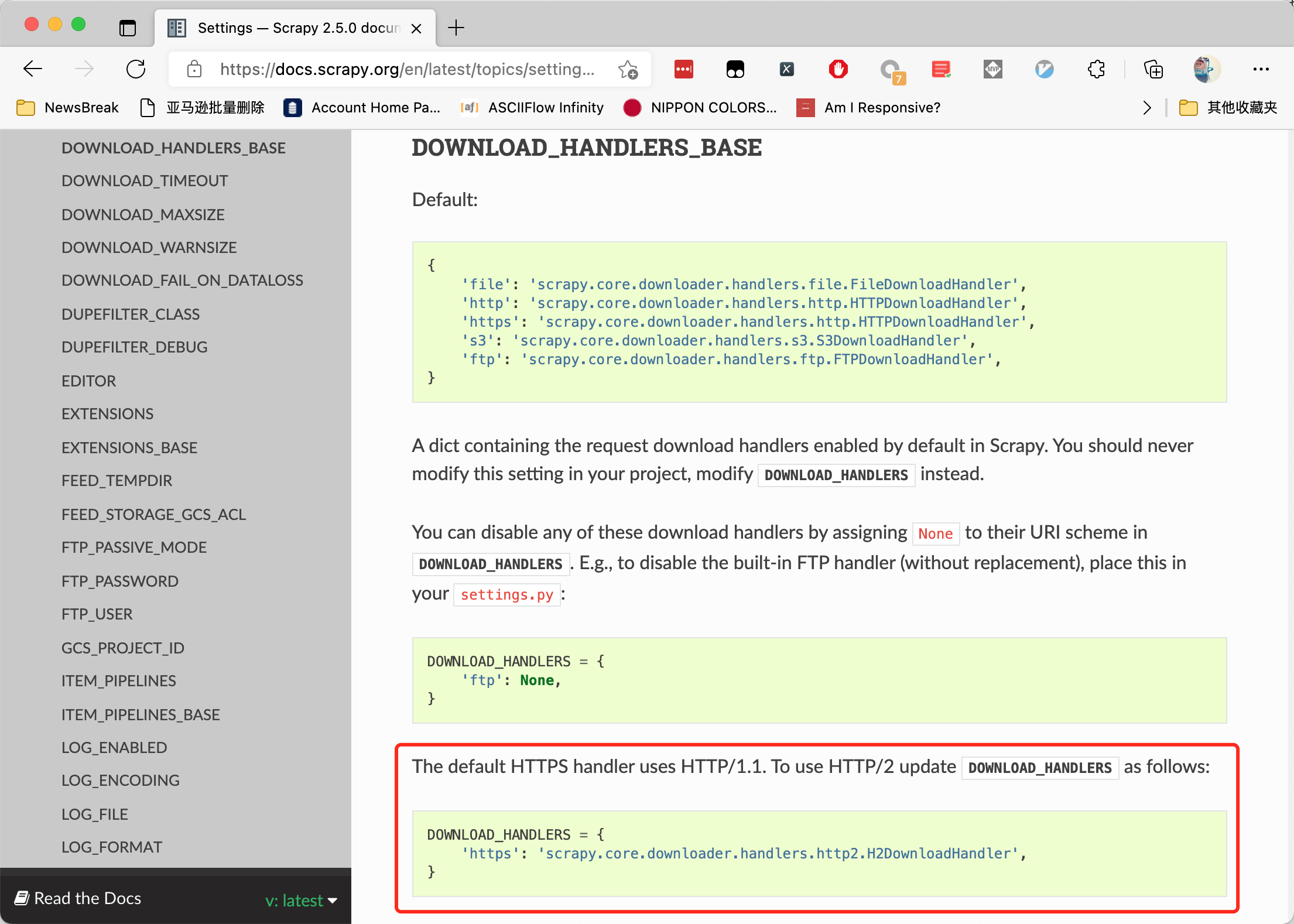
请大家注意上图中标红色方框的地方。根据它的描述,我只需要在settings.py文件中,更新下载器句柄(handlers)就可以了。我们来测试一下。把下面这段代码直接复制到 Scrapy 爬虫中:
DOWNLOAD_HANDLERS = {
'https': 'scrapy.core.downloader.handlers.http2.H2DownloadHandler',
}
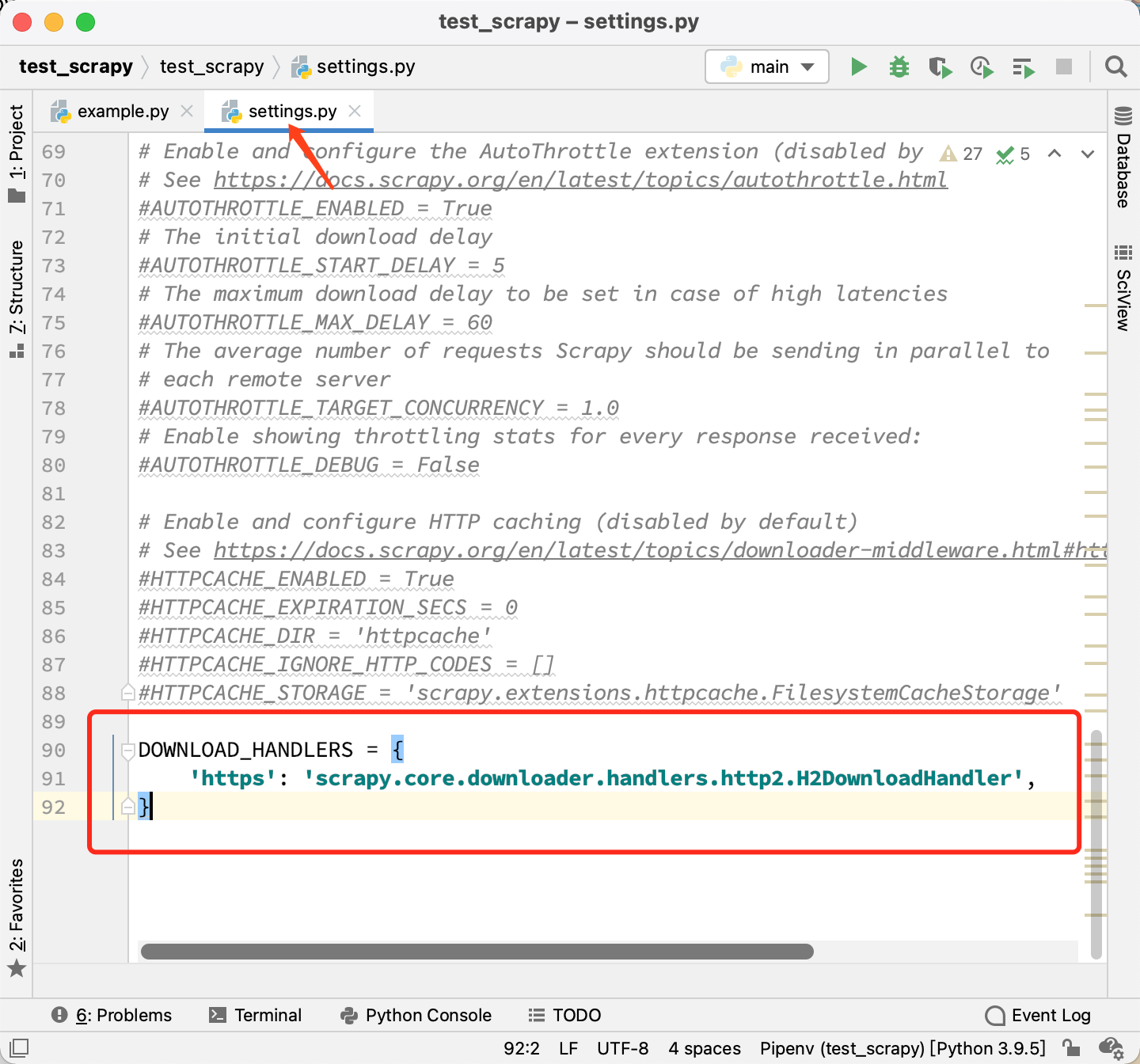
改好以后,重新运行爬虫,打印出来的源代码如下图所示:
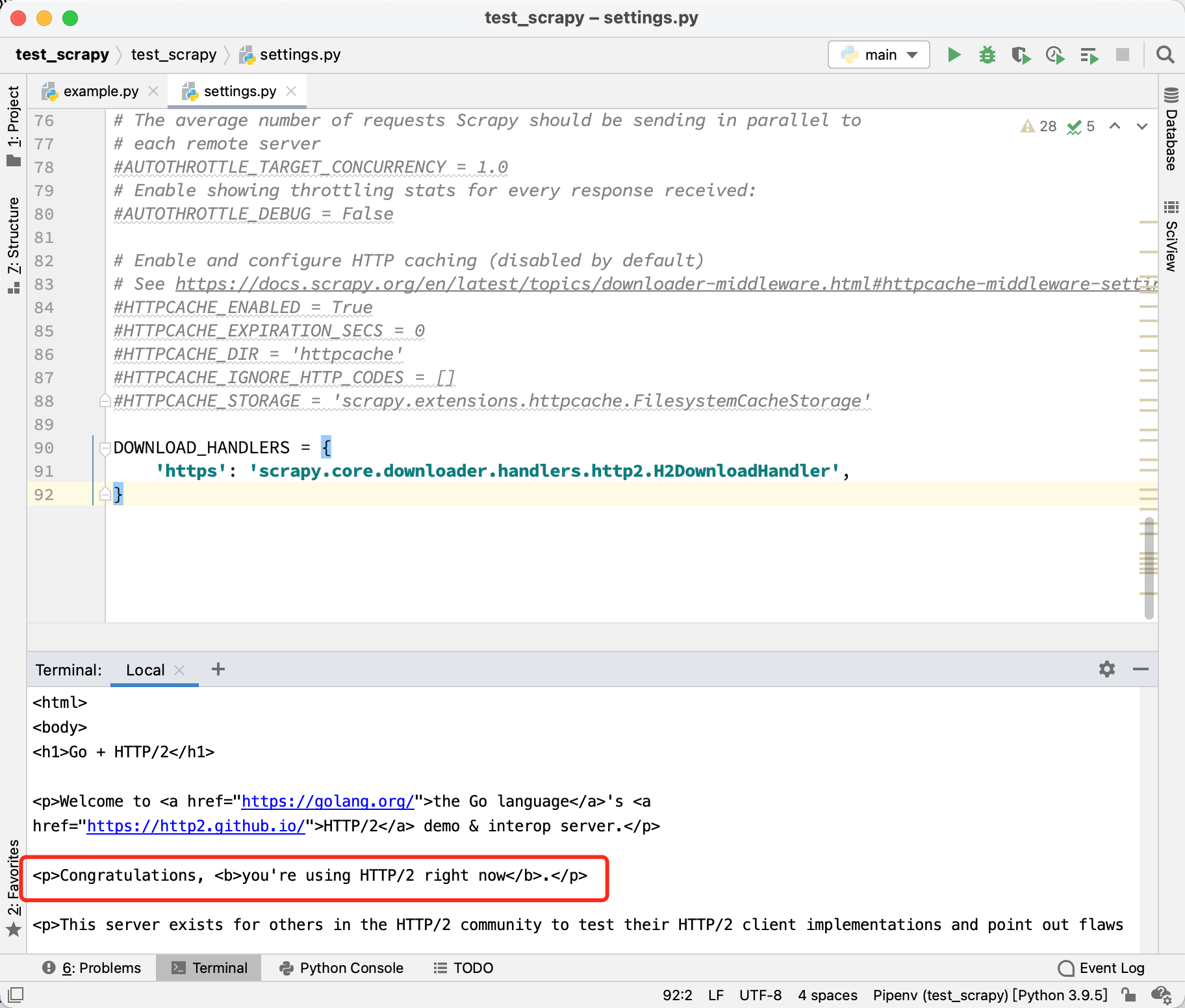
可以看到,不需要安装任何额外的库。Scrapy 原生就支持 HTTP/2了。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK