

读Pixel2Mesh- Generating 3D Mesh Models from Single RGB Images
source link: https://jyzhu.top/2021/10/19/Pixel2Mesh-Generating-3D-Mesh-Models-from-Single-RGB-Images/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
作者:Nanyang Wang, Yinda Zhang, Zhuwen Li, Yanwei Fu, Wei Liu, Yu-Gang Jiang
发表: ECCV 2018
学长@郑哲东 给我布置了任务,要求我读每一篇论文都要发一篇笔记,如此可以更快地成长。我在3D shape generation这方面还比较小白,在此贻笑大方了🙏。
这篇paper有关如何从2D转3D
如果你去做这个任务,会怎么做?作者做的方法和你想的有什么差异?
What:
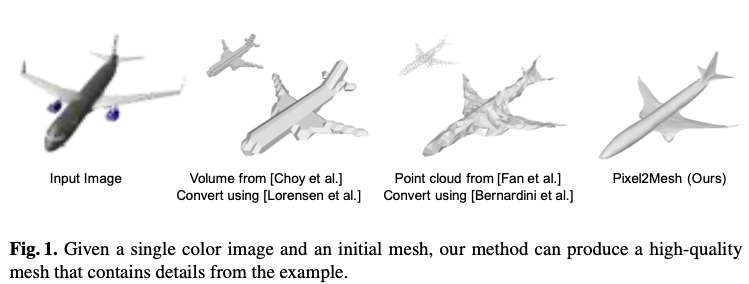 image-20211019142315766
image-20211019142315766- 提出一个端到端深度学习模型,从单张RGB图片生成3D的Mesh模型
- 用基于图的卷积神经网络生成3D Mesh,首先生成一个椭球体,然后模型根据从图片中提取的特征对椭球体塑形(deform)
- 采用了一种coarse-to-fine策略,结合了多种Mesh相关的loss function
- 这个方法生成的3D模型比其他已有方法更细节、更准确
- 之前的方法都用volume或者点云来表现3D形状,缺乏物体表面的细节信息
- volume或者点云模型不太能转换成Mesh模型
- 但是Mesh模型更有用,因为它轻量、细节、易用等等
- 模型把一个mean shape转化成目标形状,这样的好处在于:
- 深度网络更擅长预测残差,而不是一个具体的结构
- 对物体的变形可以一步一步来,把所有变形步骤加起来,慢慢抠细节
- 方便控制模型复杂度和精度的平衡
- 还可以encode一些先验知识,比如拓扑学
读前疑问:
- 二维图片顶多只有一个物体一个面的信息,怎样转换成3D物体呢,也只雕刻一个面吗?还是默认物体是对称的或者怎样?是只有一个面。
- 对输入的二维图片有要求吗?可以应用于真实图像,不过必须是跟椭球体一个拓扑学形状的物体。
- 怎么确定采用椭球体作为塑形前的形状,而不是别的形状?算是拿椭球体举例和铺路吧。
- 不太懂基于图的卷积网络在此是怎么应用的,把什么东西作为图呢?把3D Mesh模型中的顶点和边定义为图的节点和边。
- 对椭球体塑形的特征是什么形式呢,不同坐标的切割深度吗?主要是椭球体顶点的坐标,以及附属于每个顶点的特征。
- coarse-to-fine策略是什么(O_o)??首先生成顶点比较少的3D Mesh模型,然后通过几次unpooling逐渐增加顶点,也就增加了细节。
模型架构:
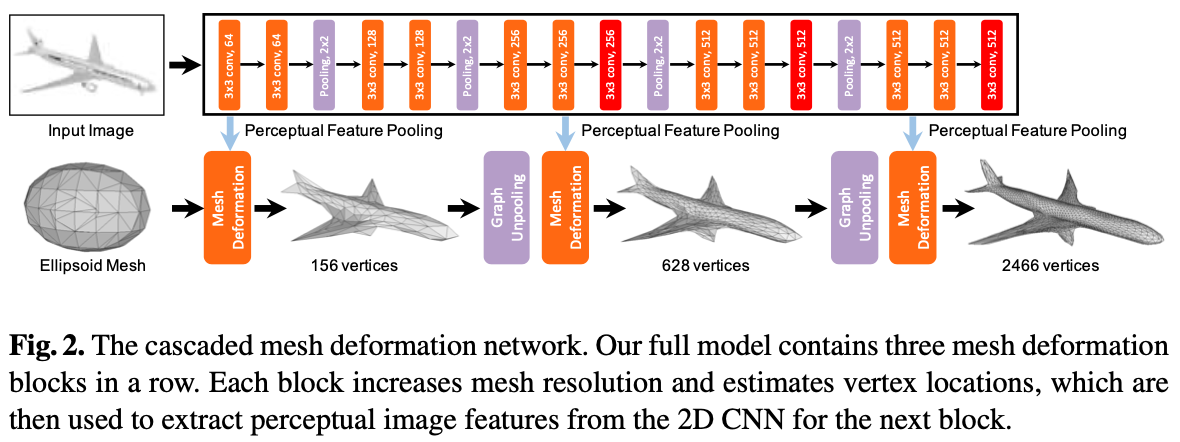
主要包括了处理2D图像的一个模型+处理3D形状的一个模型,以及中间用一种手段连接了这两部分。
- Image feature network 2D图像部分:用一个类似VGG-16的结构来提取特征
- Mesh deformation network 3D形状部分:是一个基于图的全连接网络(GCN),把Mesh模型的点和边直接表示为图中的节点和连接(妙啊,还可以这样)
- perceptual feature pooling layer 连接2D和3D两部分:对于3D模型的GCN中的每个节点,根据它在图片中的2D投影的位置,提取相应的百分比特征
- graph unpooling layer:让网络生成的3D模型中的节点逐渐增多
- shortcut connections 作为 backbone:可以更好地接收广域的背景信息
结合了多种 loss function,可以更好地规定3D形状:
Chamfer loss。倒角距离定义为:有两个集合(模型预测的Mesh集合和真实的Mesh集合),分别计算两个集合中每个点与另一个集合中距离最近的点的距离平方和,然后再加起来。公式如下: lc=∑pminq||p−q||22+∑qminp||p−q||22 这是一个经典常用的loss,但是仅仅采用这个loss的话,生成3D mesh的效果并不是特别好。
Surface normal loss。定义这个loss的目的是让生成的mesh模型表面更光滑。公式如下: ln=∑p∑q=argminq(||p−q||22)||<p−k,nq>||22,s.t.k∈N(p) 公式中,p是预测的点,q是真实的mesh集合中距离p最近的点(和Chamfer loss中p、q的含义一样),k是p的邻居点,nq是真实的mesh中q点对应的平面的法线向量。所以这个公式就是计算了 和每个点p相连的边 与 对应的真实表面的法线 的点积,的平方和。emmm,理解一下,两条线越接近垂直,点积越接近0,所以这个loss本质上就是要求预测出来的每一个切平面和真实结果的平面的法线相垂直,也就是说要求预测的切平面与真实平面平行,那就促进了平面的光滑。
Edge length regularization。这个 regularization 是为了防止点跑得太远。点跑得越远,就会导致边越长,所以这个 regularization 就是边长:lloc=∑p∑k∈N(p)||p−k||22。
Laplacian regularization。定义这个 regularization 是为了防止各个面重叠(self-intersection)。Laplaician 可以促进相邻的点采取相同的移动方式,这样的话模型的局部也不会产生很离谱的变形。公式定义如下: 对每一个点p,其 laplacian coordinate 为 δp=p−∑k∈N(p)1||N(p)||k 则 laplacian regularization 为 llap=∑p||δp′−δp||22δp′、δp′分别表示点p在一次塑形前后的 laplacian coordinate。
总的 loss 是上述4个 loss 的加权和,权重分别为 1、1.6e-4、0.3和0.1。
Graph-based Convolution的公式表示
- Mesh是点、线、面的集合,定义了一个三维物体的形状。
- M=(V,E,F),其中F是附属于每个vertices的特征向量的集合
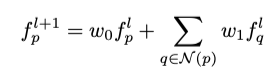 fpl、fpl+1是点p在卷积前后的附属的特征向量, N(p)是点p的邻居点,w是权重矩阵
fpl、fpl+1是点p在卷积前后的附属的特征向量, N(p)是点p的邻居点,w是权重矩阵- 本文中的fp具体包括了点p的三维坐标、三维形状特征和从输入的彩色图像学习到的特征
选择椭球型是因为这个paper是一篇pioneer study,所以就仅仅聚焦了方便用椭球型塑形出来的物体;而且实践表明了大部分常见物体都挺适合用椭球型塑形的。椭球型是一个固定形状、大小、包括156个顶点的Mesh形状。不需要任何先验知识。
模型组件之 Mesh deformation block:
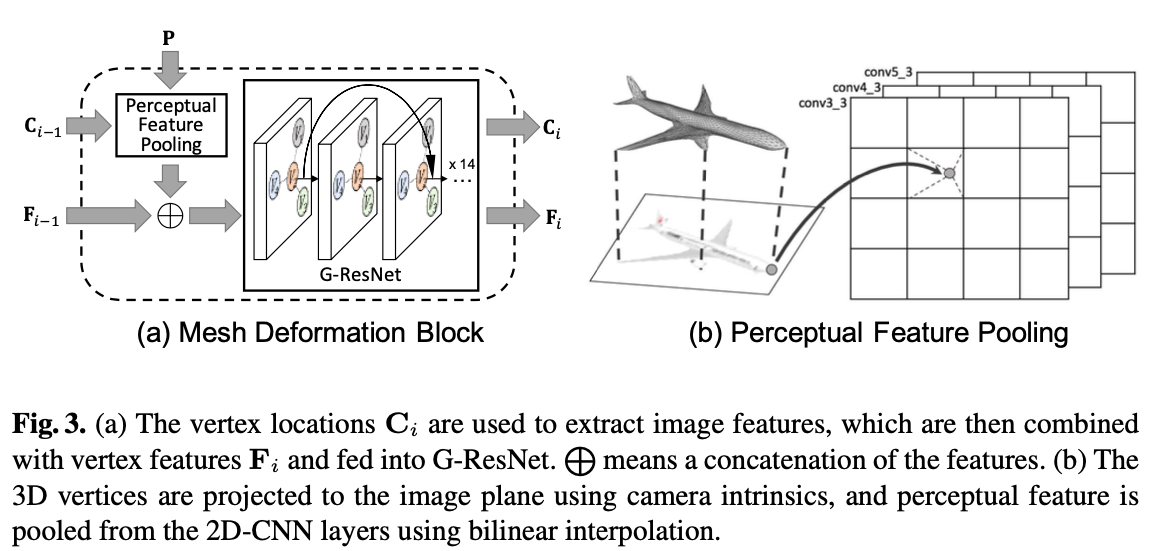
P是Image feature network从2D图像提取出来的特征,Ci−1是3D Mesh模型中vertex点的位置坐标;两者被输入perceptual feature pooling,3D点用camera intrinsics的方法投影到2D图像上,然后用bilinear interpolation方法从临近的4个像素提取特征。提取出来的特征和当前的3D形状特征Fi−1相连接,然后一起输入G-ResNet网络,最后输出新的位置坐标Ci和新的3D形状特征Fi。
G-ResNet 是一个很深的网络,有短路连接(shortcut connections),这样做的目的是让每个点的特征不局限于邻居点的影响,而可以学习到更广泛的信息。
模型组件之 Graph unpooling layer:
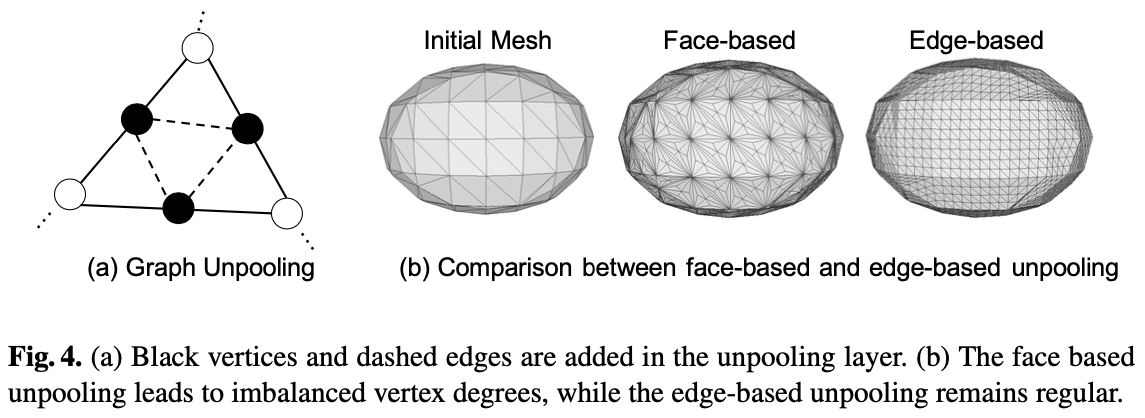
目的是为了增加3D Mesh模型中的点的数量,从而让模型更细节。最直观的Face-based方法是在每个三角形面的中心加一个vertex点,但是这样会导致点的度(degree)不均衡。所以这篇文章采用的是Edge-based方法,也很好理解,在每条边的中点增加一个vertex。
问题:边是怎么增加的呢?
在每条边的中点增加一个点之后,将增加的中点和原本这条边的两个顶点相连,作为新增的两条边。此外,在同一个三角形的三边上新增的点之间也会相连,形成一个新的三角形。也就是像图4.(a)那样,每个三角形经过unpooling会变成4个三角形。
问题:156 个点为啥 upsample是到 628 个点?
最初是156个顶点,每三个点相连形成一个三角形的面,根据图里的方式,每6个三角形共用一个顶点,组成一个椭球体的Mesh模型。那么最初是有 6 + (156 - 4) * 3 = 462 条边。upsample一次时,每条边上增加一个点,所以增加462个点,总共变成156+462=618 个点。好奇怪……为啥少了10个点??
跑了哪些数据集?使用的是Choy的3D-R2N2提供的 ShapeNet 数据集,包括属于13个类别的5万个模型的渲染图片。实验中,与3D-R2N2 PSG N3MR三个网络模型进行比较,对比了F-score、Chamfer Distance和Earth Mover’s Distance这几项指标。另外,这篇文章也模仿Choy,在Online Products dataset和网络图片上测试了模型在真实图片上的效果。
Future work:当前的模型仅仅局限在跟最初的椭球体拓扑形状类似的3D模型,未来可以拓展到更广泛的场景中,比如整个场景的3D重建,或者根据多视角的图片进行3D重建。
在真实图片上的效果,确实很好哈哈哈:
 image-20211019213432590
image-20211019213432590Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK