
3

爬虫系列:数据采集
source link: https://segmentfault.com/a/1190000040830878
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
爬虫系列:数据采集
发布于 34 分钟前
在上一期,主要讲解了:连接网站与解析 HTML
上一期只是一个简单的例子,获取了网站的一小部分内容,本期开始讲解需要获取网站的所有文章列表。
在开始以前,还是要提醒大家:在网络爬虫的时候,你必须非常谨慎地考虑需要消耗多少网络流量,还要尽力思考能不能让采集目标的服务器负载更低一点。
本次示例采集The ScrapingBee Blog博客的文章。
在做数据采集以前,对网站经行分析,看看代码结构。
需要采集的部分是一个个的小 card 组成,截图如下:
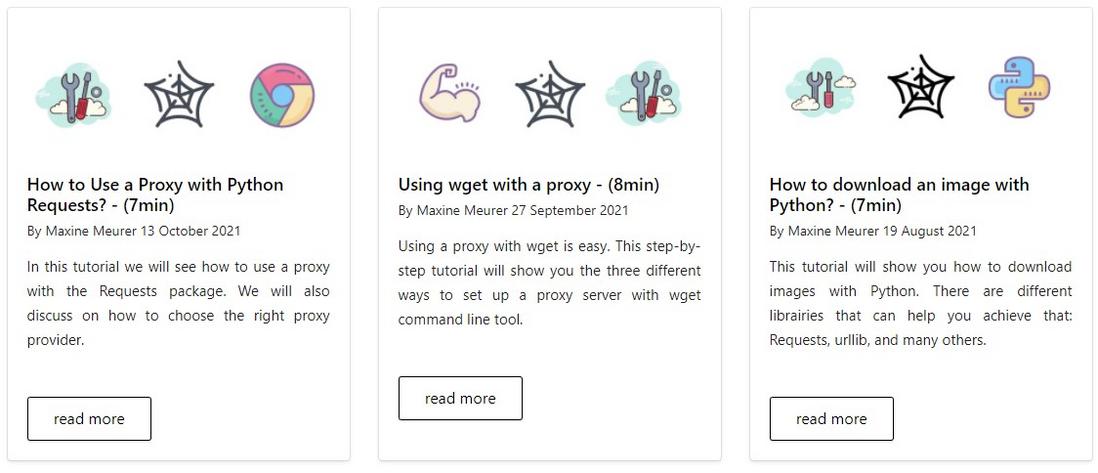
获取所有卡片的父标签之后,循环单个卡片的内容:
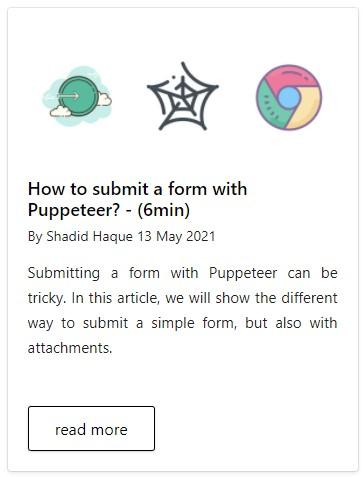
单个卡片的内容,就是我们需要的内容,整理完思路之后,开始完成代码:
首先我们还是复用上一期网站连接的代码:
def __init__(self):
self._target_url = 'https://www.scrapingbee.com/blog/'
self._init_connection = connection_util.ProcessConnection()
以上代码定义了一个被采集的网址,同时复用上一期的网站连接代码。
# 连接目标网站,获取内容
get_content = self._init_connection.init_connection(self._target_url)
连接到上面定义的目标网站,并获取网站的内容。
if get_content:
parent = get_content.findAll("section", {"class": "section-sm"})[0]
get_row = parent.findAll("div", {"class": "col-lg-12 mb-5 mb-lg-0"})[0]
如果存在内容,对网站内容的标签经行查找,以上是获取所有 card 的父标签,获取具体网站结构可以自己查看网站的完整内容。
get_child_item = get_row.findAll("div", {"class": "col-md-4 mb-4"})
获取所有小卡片。
for item in get_child_item:
# 获取标题文字
get_title = item.find("a", {"class": "h5 d-block mb-3 post-title"}).get_text()
# 获取发布时间
get_release_date = item.find("div", {"class": "mb-3 mt-2"}).findAll("span")[1].get_text()
# 获取文章描述
get_description = item.find("p", {"class": "card-text post-description"}).get_text()
之后对获取的小卡片经行遍历,获取每个卡片的文章的标题,发布时间,文章描述。
以上从网站结构开始分析,到具体代码实现,这是爬虫抽取网站内容的一个基本思路。
每个网站不同,结构也会有所不同,所以要针对性的编写代码。
以上代码已托管在 Github,地址:https://github.com/sycct/Scra...
文章来源:爬虫识别 - 爬虫系列:数据采集
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK