

Tensorflow深度学习算法整理(二)
source link: https://my.oschina.net/u/3768341/blog/5279935
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
循环神经网络
序列式问题
- 为什么需要循环神经网络
首先我们来看一下普通的神经网络的样子
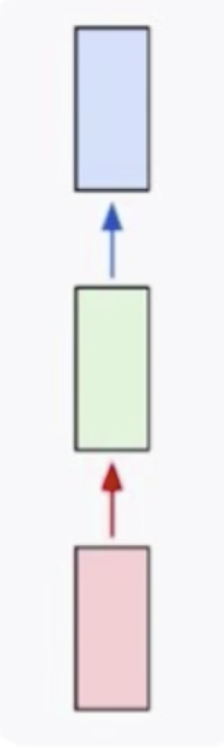
这里红色部分是输入,比如说图像;绿色部分是网络部分,比如说卷积部分和全连接部分;蓝色部分是输出,比如说最终得到的分类概率。这样的网络结构很适合做图像的分类,图像的检测,这种数据都是固定的数据。如果是变长的数据,比如说文本,它的长度是不一定的,这个时候我们该怎么做呢?
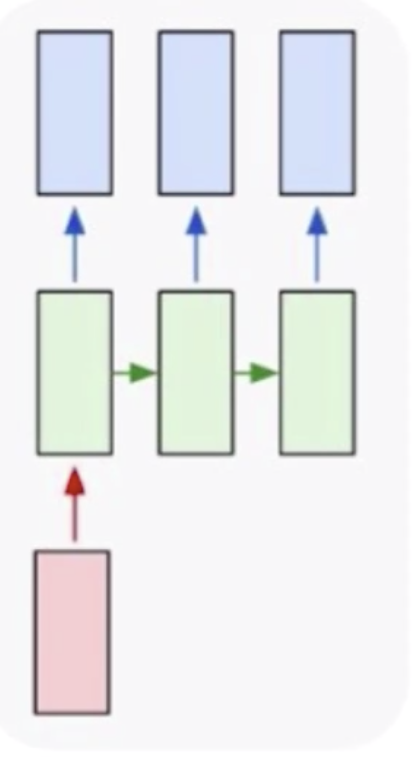
这个时候其实就需要循环神经网络,循环神经网络是专门用来处理序列式问题的。循环神经网络可以解决一对多问题,如上图所示,我们的数据集是一个输入,但是我们要形成多个输出,多个输出卷积神经网络是做不了的,它只能给出来一个输出。一个基本的场景就是给定一张图片,去生成一个描述,这个描述就是一个文本,文本是不定长的。我可以说这个图片风景优美,也可以说这个图片有一条小河,有一个孩童等等。
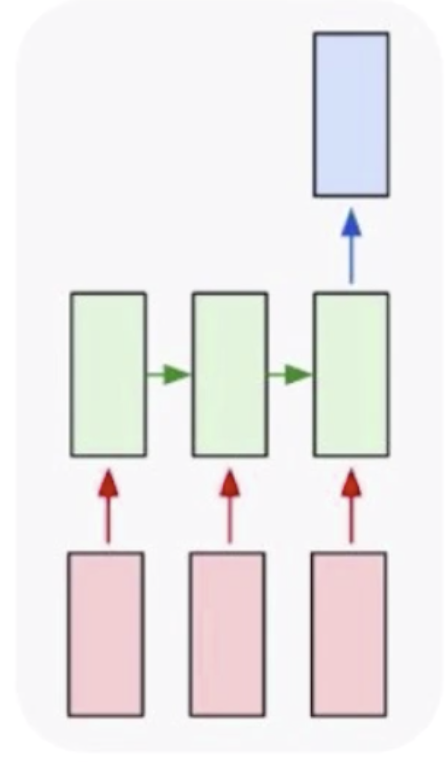
然后就是多对一的,多对一有一个很经典的问题就是文本分类(文本情感分析),分本分类的输出也只有一个,但是它的输入是不定长的。这种情况下卷积神经网络也无法处理。如果实在要处理的话,可以让输入强行变的对齐,这样才可以处理。但是在不定长情况下,只有循环神经网络可以做到。
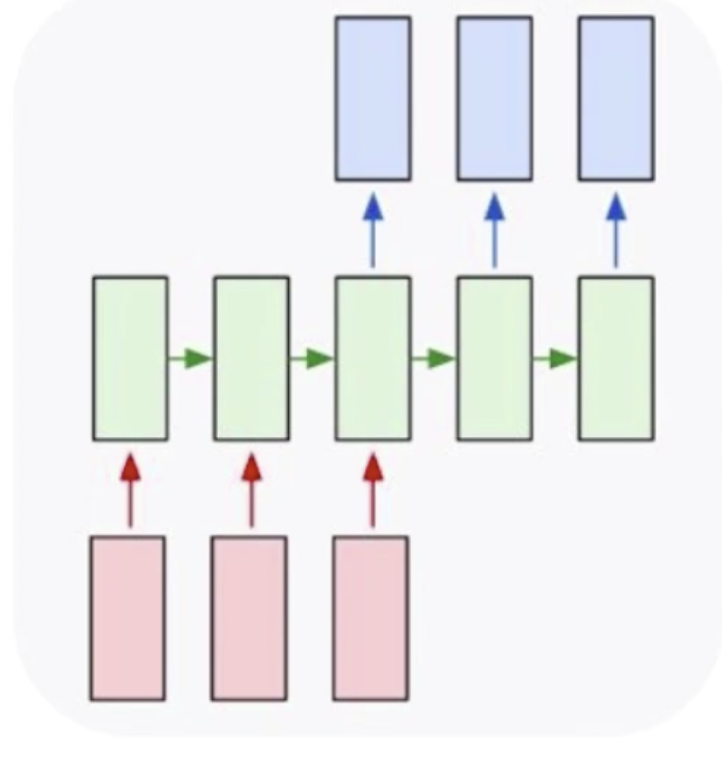
然后就是多对多,多对多有一个经典的问题就是机器翻译,比如说我知道一个中文的句子,想把它翻译成英文,在这个时候就需要用到循环神经网络去解决。可以通过把中文信息都编码到一个数据中去,再依据这个数据去生成新的英文句子。但是这种翻译不是一种实时翻译,实时翻译是一个词一个词的翻译。
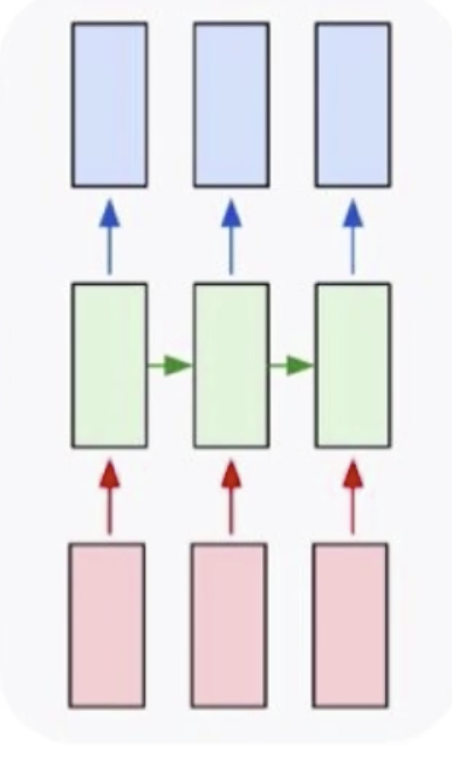
实时多对多,如视频解说。比如说世界杯解说,现在一般都是人力解说,但其实也可以用机器来解说,虽然用机器解说还不能达到生动有趣的效果,但是生成基本的描述是没有问题的。视频解说的输入是视频中一帧一帧的图片,每一个输出都是一个不定长的句子。这就达到了一个视频解说的目的。
循环神经网络
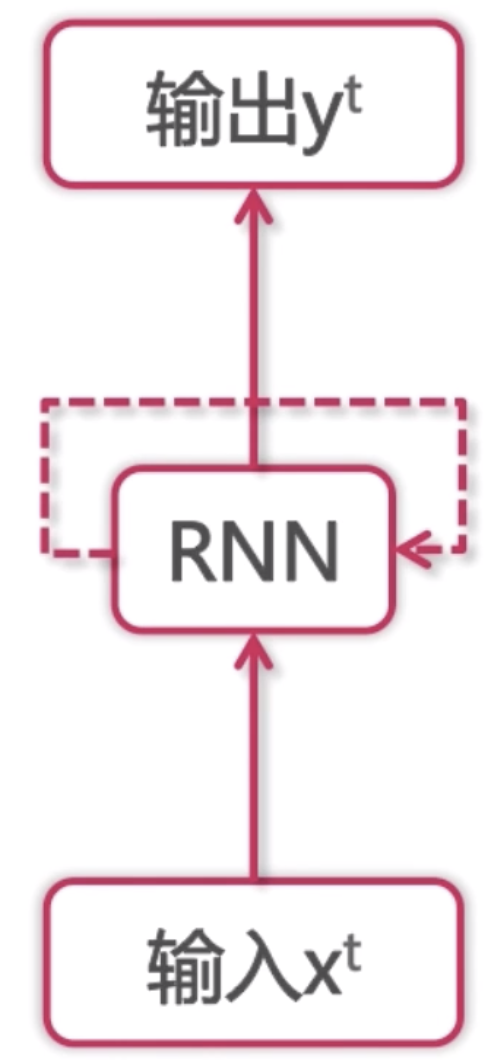
循环神经网络类似于之前的架构,但是它多了一个自我指向的路径。这条自我指向的路径表达的是,输入可能是多个,然后需要保存一个中间状态,这个中间状态可以帮我们了解之前的输入的情况。维护一个状态作为下一步的额外输入。首先我们有一个输入x0(表示第0步)到RNN中去得到一个状态s0,这个状态经过一个变化输出到y0。下一次,由于我们得到一个中间状态s0,s0可以和后面的x1一块输入到RNN中去,得到s1,之后再输出y1。这个是它的一个基本思想。
循环神经网络每一步使用同样的激活函数和参数。我们的输入可能有x0,x1,x2....,它每一步的参数是共享的。
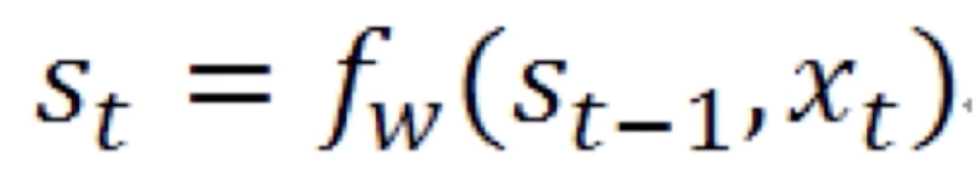
这里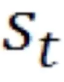 就是中间的状态,它等于上一步的状态
就是中间的状态,它等于上一步的状态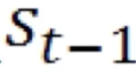 和当前的输入
和当前的输入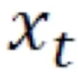 一起做一个拼接再经过一个变换就得到当前的状态。当前的状态再经过一个变换就能得到当前的输出
一起做一个拼接再经过一个变换就得到当前的状态。当前的状态再经过一个变换就能得到当前的输出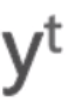 。这是最简单的循环神经网络。再将该公式展开就得到
。这是最简单的循环神经网络。再将该公式展开就得到
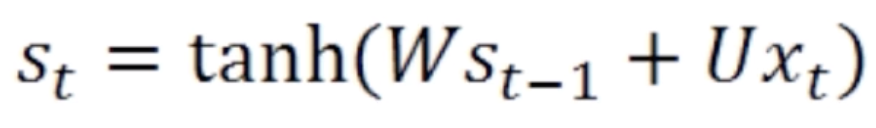
在这里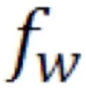 用了一个激活函数叫tanh。和是如何组合在一起的,在这里用了一个矩阵变换W和U,W和U都是矩阵参数。这两个矩阵参数分别对和做了变换之后再相加(关于矩阵变换的内容请参考线性代数整理(二) 中的线性变换)。然后再经过一个激活函数就得到了当前的状态值。
用了一个激活函数叫tanh。和是如何组合在一起的,在这里用了一个矩阵变换W和U,W和U都是矩阵参数。这两个矩阵参数分别对和做了变换之后再相加(关于矩阵变换的内容请参考线性代数整理(二) 中的线性变换)。然后再经过一个激活函数就得到了当前的状态值。
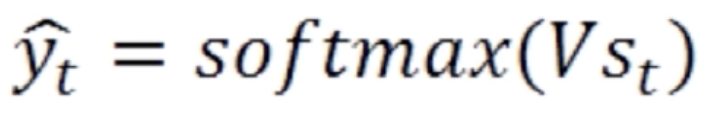
当前状态再经过一个变换V,再使用多分类归一化softmax,就得到了当前概率值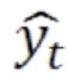
现在我们来看一个例子
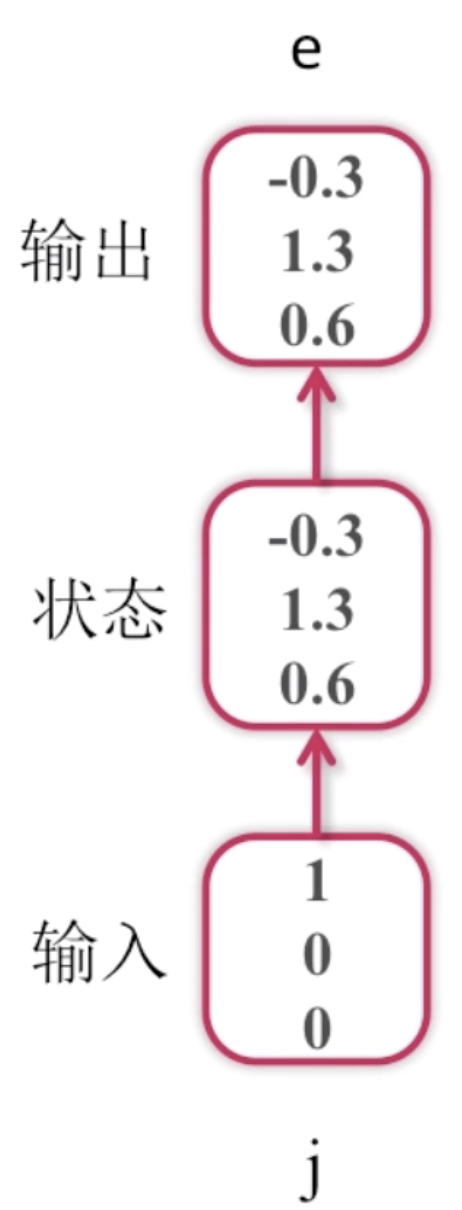
这是一个字符语言模型,它的目的是预测下一个字符,词典为[j, e, p],样本为jeep。语言模型是NLP(自然语言处理)领域里面常用的一个模型,它的模型的基本要素就是说我给定一个上下文context,我能预测下一个字或者词是什么。比如应用在输入法上的模型,它可以帮大家预测下一个要输入的词是什么。字符语言模型跟词语言模型不一样,词语言模型是预测下一个词是什么,字符语言模型是预测下一个字符是什么。比如说hello,我输入了he之后需要预测出下一个是l。
这里我们简化问题,字典里面只有j、e、p三个字符,首先我们的输入样本是j,此时我们并不知道后面的样本是什么。把j输入到循环神经网络中去,记录下一个状态,再经过一个变换,这里为了简化过程,我们就进行了等值变换,进入到输出,得到一组概率值。然后再计算概率分布。
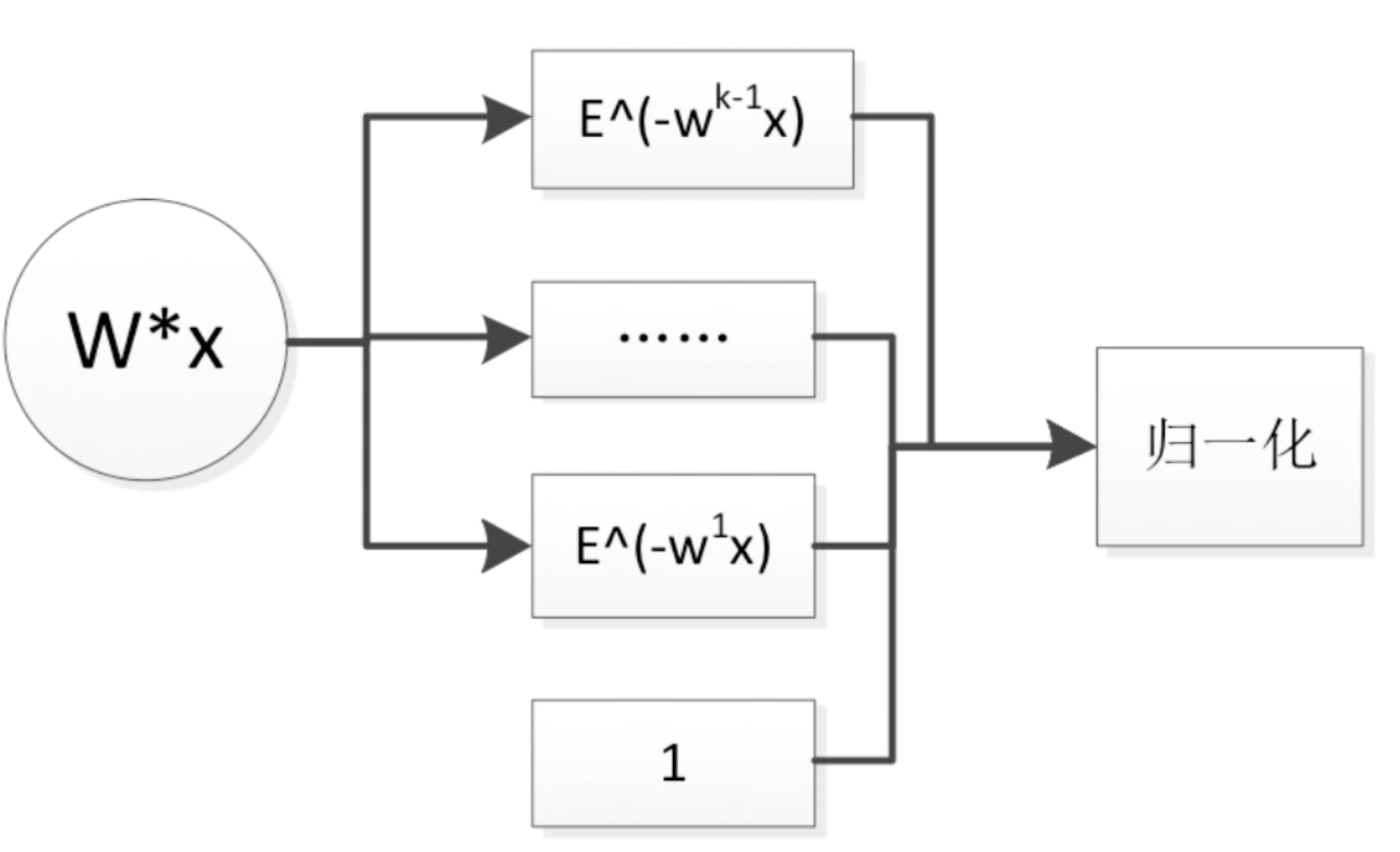
就是这个过程,这里概率分布中第1个位置的概率1.3是最大的,它代表是第1个位置,所以预测下一个字母是e(这里j排第0,e排第1,p排第2)。
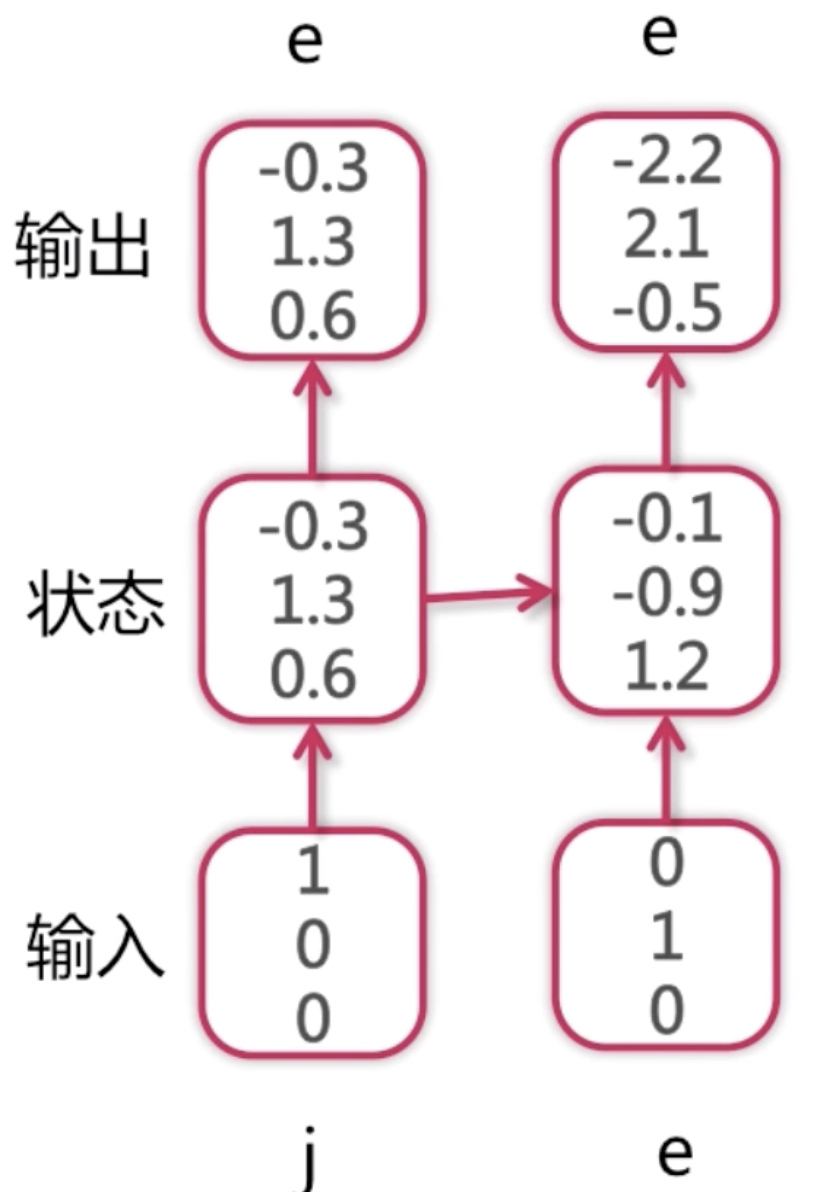
此时我们得到了第一个输出是e,再把e作为第二次输入,第一次输入j的时候得到了一个隐含状态,这个隐含状态和下一个e一块输入到下一个RNN中的深度神经单元中去,然后得到第二次的输出的概率分布。这个概率分布依然是第一个位置上的概率最大为2.1,所以第三个字符也是e。
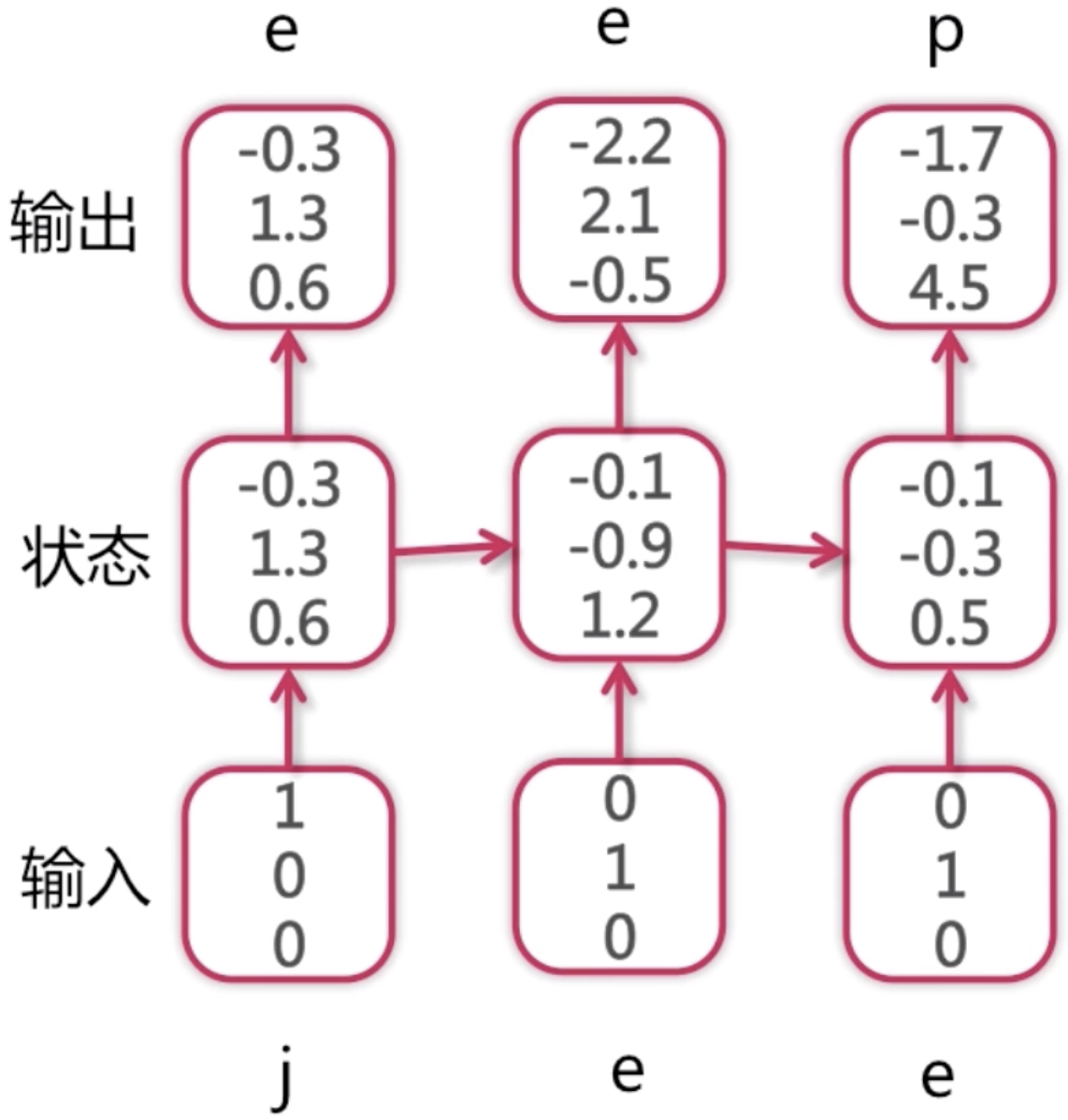
同理,我们把第二次的输出e作为第三次的输入,在此之前,我们第一次输入的j以及第二次作为输入预测出来的e,它们都有一个隐含状态,这两个隐含状态都连接到了第三次输入的RNN神经网络,再加上第二次预测的e一块输入进去,得到了第三次输出的概率分布,这次最大值为第3个位置的4.5,所以预测出来的字符为p。
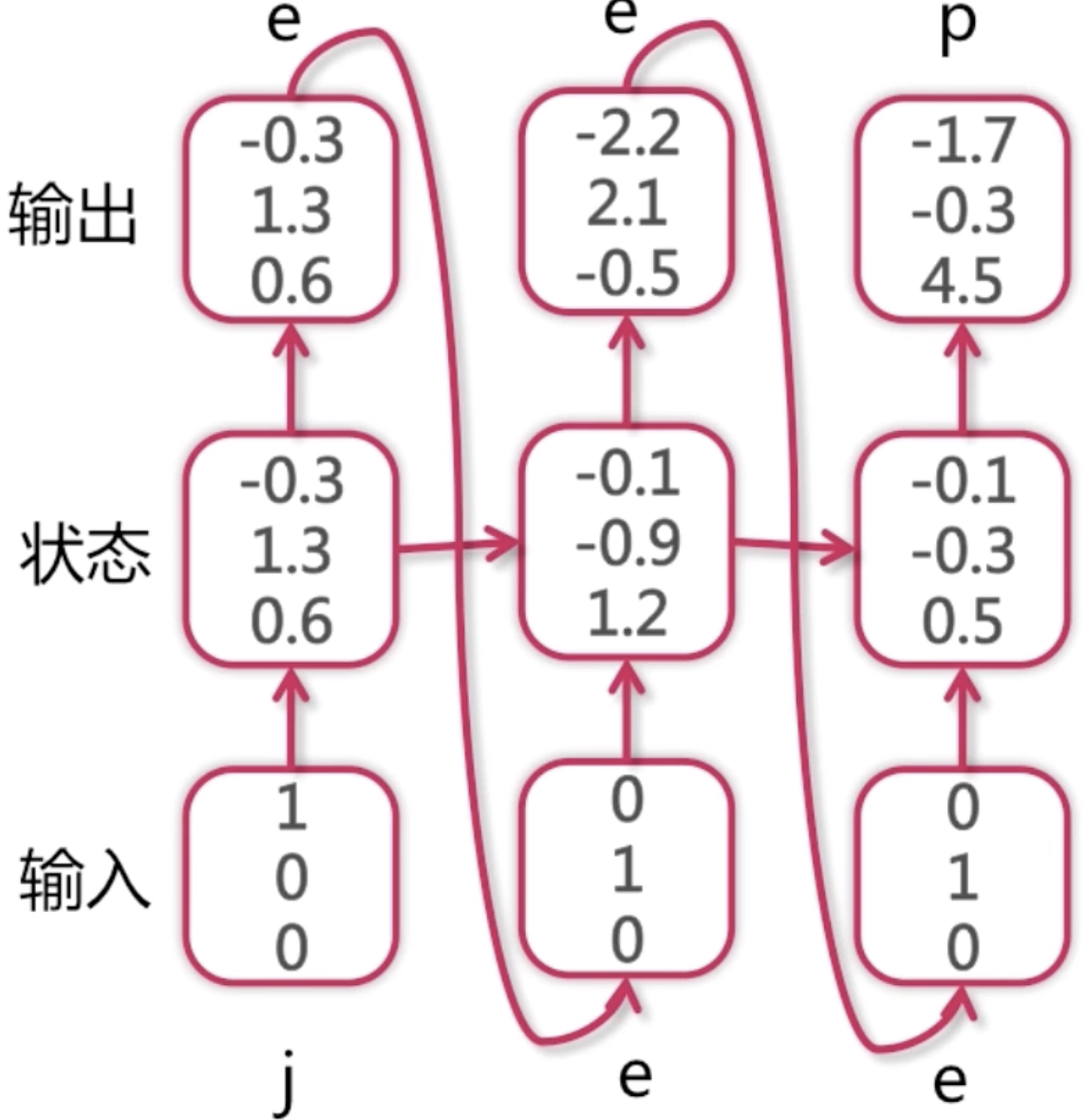
如果作为测试数据集,我们可能只知道第一个j,后面的字符都不知道。由于每一步的输入都依赖于上一步的预测值,如果中间的某个地方预测错了,那么很可能从中间到往后的预测值都是错的。如果模型训练的比较好的话,数据量比较大,它还是可以有一定的兼容性的,比如中间错了,但是后面的预测依然是对的。对于p来说,因为之前的状态都是加权过来的,越往前的状态值对最后结果的预测值就越没有影响力,当前的输入对当前的输出是有最大影响的,越往前的输入对最后的预测越没有影响。所以这种兼容性还是可以训练出来的。
循环神经网络的正向传播
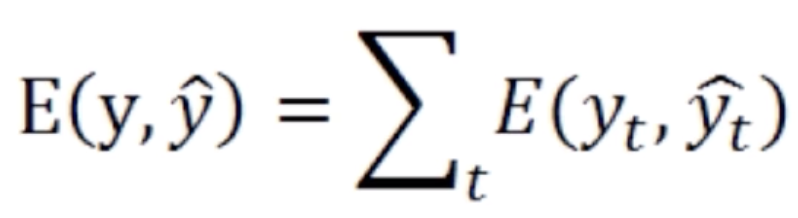
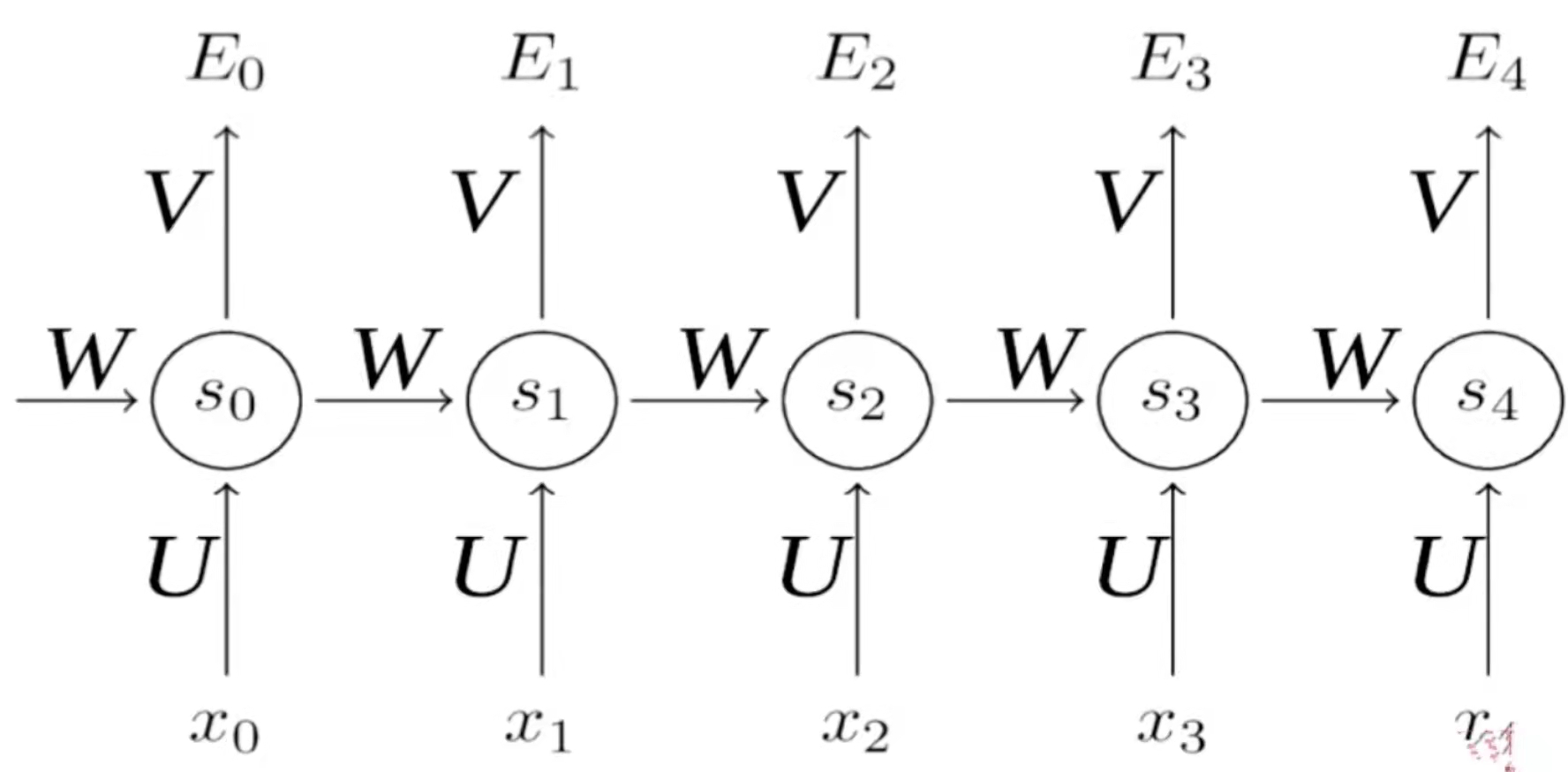
我们在讲普通的卷积神经网络的正向传播是先计算低层的,再计算高层的。但是在循环神经网络中只有一层,它的正向传播是序列式的,后输入的状态依赖于先输入的状态,所以它需要先计算第一个位置上的值,然后再去计算第二个位置上的值,然后再去计算第三个、第四个、第五个位置上的值。循环神经网络的正向传播就是序列式的,按照输入顺序去进行计算的一个过程。在每个位置上都得到了一个预测值之后,可以在每个位置上去计算损失函数。最后的损失函数是所有的中间步骤的损失函数的和。当然这个循环神经网络是最基础的循环神经网络,它是实时多对多的那个神经网络结构,后面可以做一些微小的变换,就可以使得它去面对多对一的问题或者一对多的问题以及不实时多对多的问题。如果要应对多对一的问题,那么只需要让前四步的输出都为0就可以了,就是前四步都不输出,只输出第五步的值,然后在第五步上去做损失函数,它也会反向传播去更新所有的W。
循环神经网络的反向传播
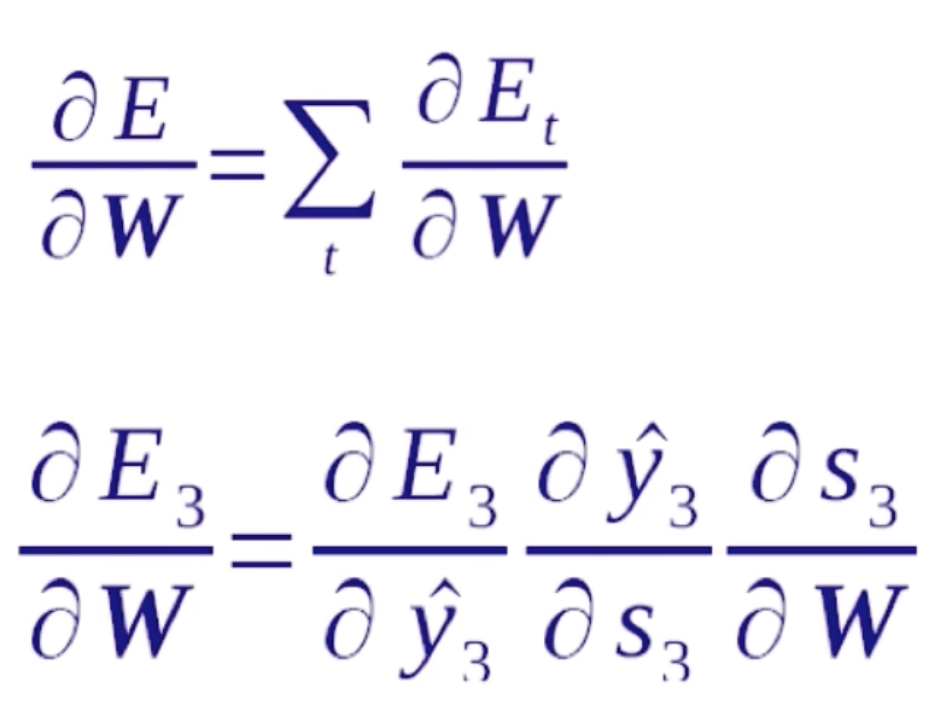
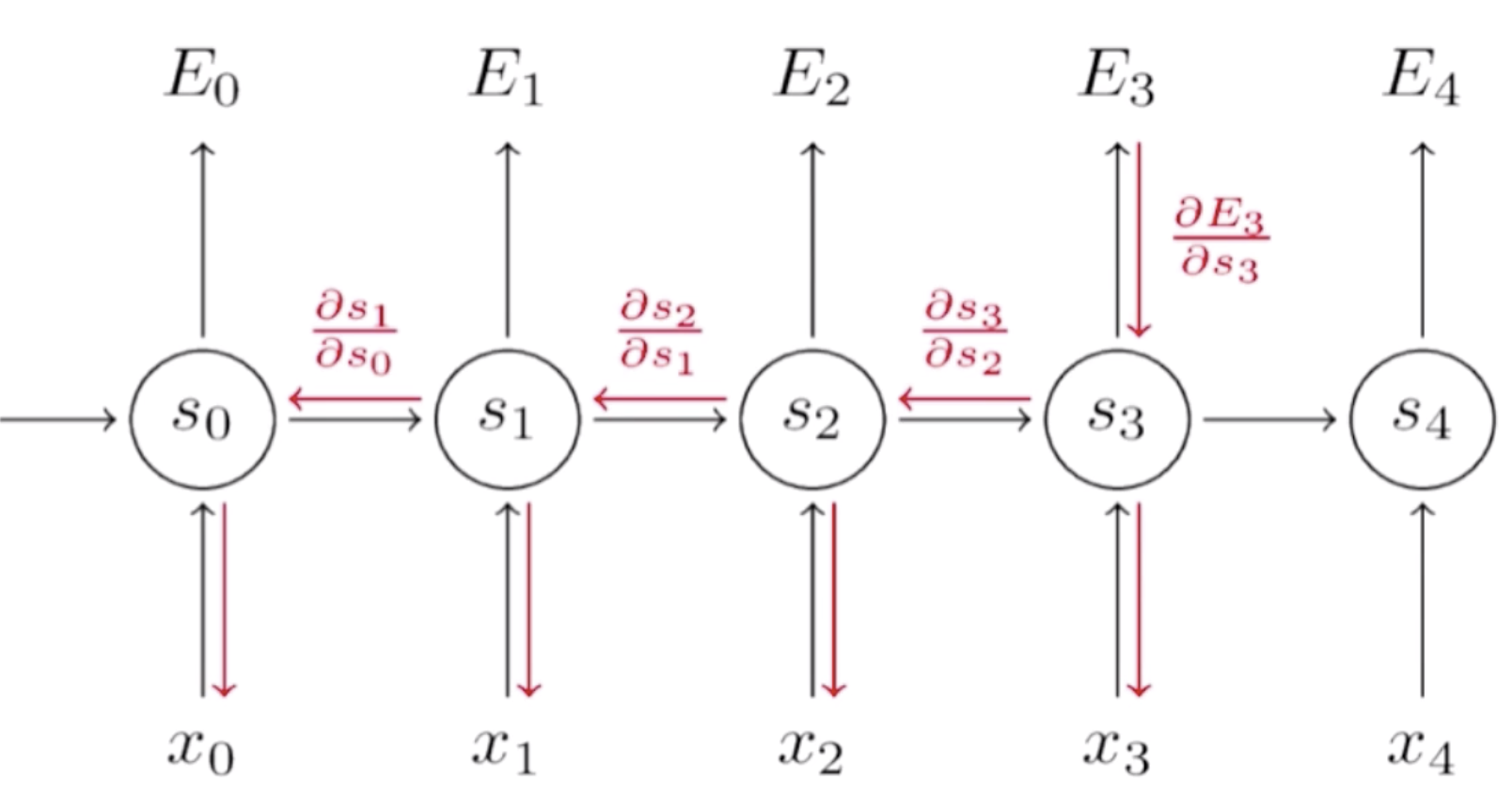
循环神经网络的反向传播也是依照序列来做的,正向传播是从序列的头到序列的尾,而反向传播是从序列的尾到序列的头。首先我们要明确一点,在正向传播中每一步用到的W、U、V都是一样的,所以我们在计算梯度的时候,在任何一步上计算梯度,它们的梯度是要相加起来统一去更新W,因为它们本质上就是一个变量。对于一个循环神经网络来说,它有一个递归性在里面,比如说在E3的位置去算W的梯度,它就等于E3就先对s3的一个梯度,s3是它的隐含状态值,这个隐含状态值经过一个变换就得到了y3,y3再经过变换就得到了E3。这里在s上存在循环性,所以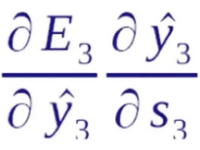 是可以直接计算出来的,而
是可以直接计算出来的,而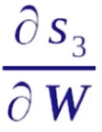 就比较复杂。因为s3对W是一个递归的过程。我们看一下它是如何递归的。
就比较复杂。因为s3对W是一个递归的过程。我们看一下它是如何递归的。
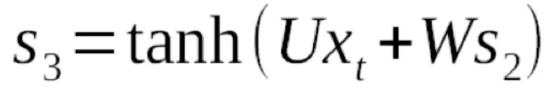
这里我们知道最新的状态值s3跟之前的状态值s2和最新的输入x3是这样一个关系。由于是对W求导,我们就可以把Ux3看成一个常数,剩下的就是Ws2,s2并不是一个常数,它跟W是有关系的,假设它的关系为v(W),那么求导就变成了两个函数相乘对W求导(可以参考高等数学整理 中的求导公式),这里W可以看成是它自身u(W)。
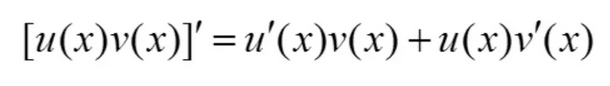
那么我们对做展开,首先我们知道s3是s2的函数,s2是s1的函数,s1是s0的函数,所以可得s3分别是s2、s1、s0的函数。根据上面的公式就有(这里的计算比较复杂,我们给出一个结果)
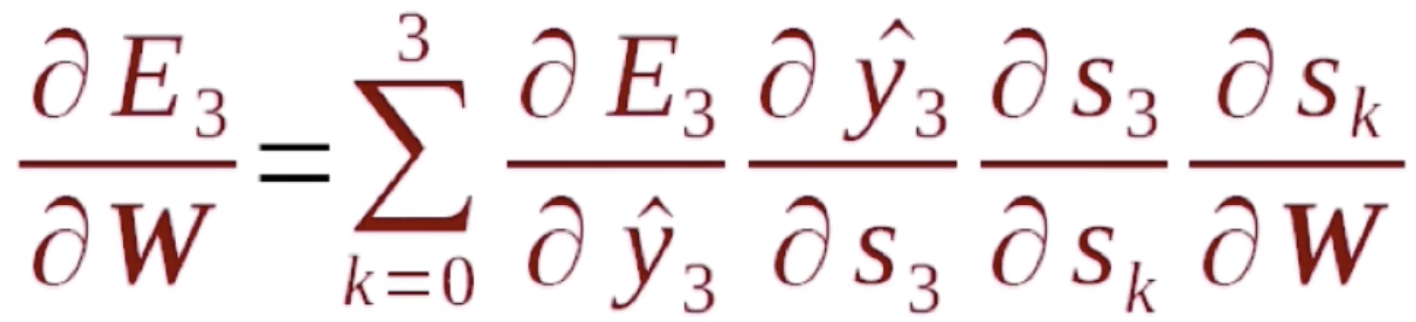
这里s3对sk的导数可以简化为
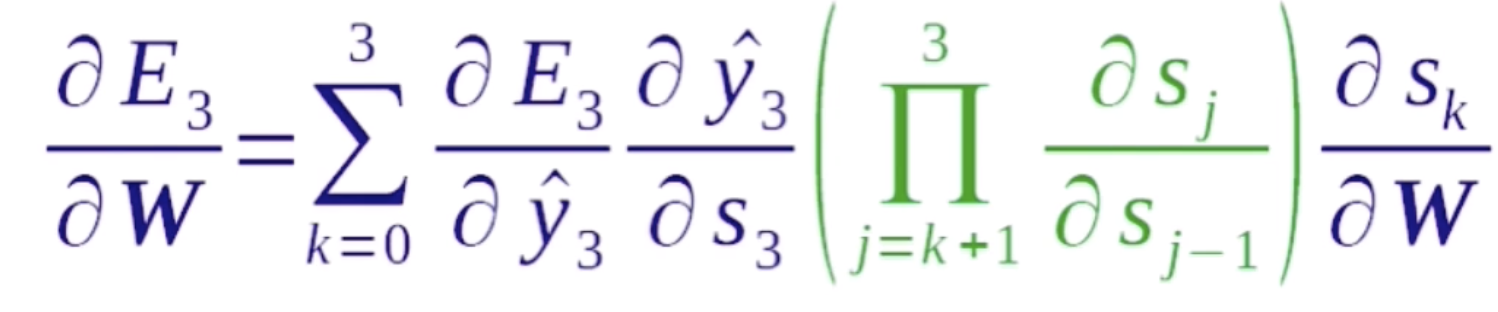
在这个做计算的过程中可以去简化计算步骤,比如s3对s2求了导数之后,在求s4的时候,我们可以复用这一效果。所以在这里做了一个拆分,s3对于s0的导数可以看成是s3对s2的导数乘以s2对s1的导数乘以s1对s0的导数。这个乘积的作用就是说可以复用中间的计算结果,因为这是一个递归的过程,如果能存下来中间的计算结果的话,那么可以很大的加快这一计算速度。这就循环神经网络反向传播的计算公式。
我们来看一下反向传播的特点,激活函数Tanh是一种S型函数,输出在-1和1之间,容易梯度消失。当输出值接近-1或者是1的时候,它的梯度值非常的小。当序列非常长的时候,从一个比较长的末端往前传梯度的时候,每次都需要乘一个(-1,1)之间的一个数,这个数就会导致梯度消失。因为乘以10个这样的数,就相当于整个值就变成了10^(-n),在这样一个级别下,梯度就消失了。所以说较远的步骤梯度贡献很小。基于这样的特点,我们需要在循环神经网络梯度下降的时候做一定的优化。比如说较远的步骤对当前梯度的贡献非常小,就可以把较远的步骤给忽略掉,节省很多的计算资源。切换其他激活函数后(不使用tanh,改成relu),可能也会导致梯度爆炸。因为梯度类似于卷积中的层次,它在循环神经网络反映出来是输入需要的长度,比如说一段文本有成百上千上万个词,如果切换了其他函数,而不是tanh之后,它每一步梯度可能会被放大,大于1的就会有放大的效果,就会导致比较后的步骤对于比较前的步骤的影响,每一步放大的话会导致梯度的爆炸,tanh是每一步梯度都会被缩小。
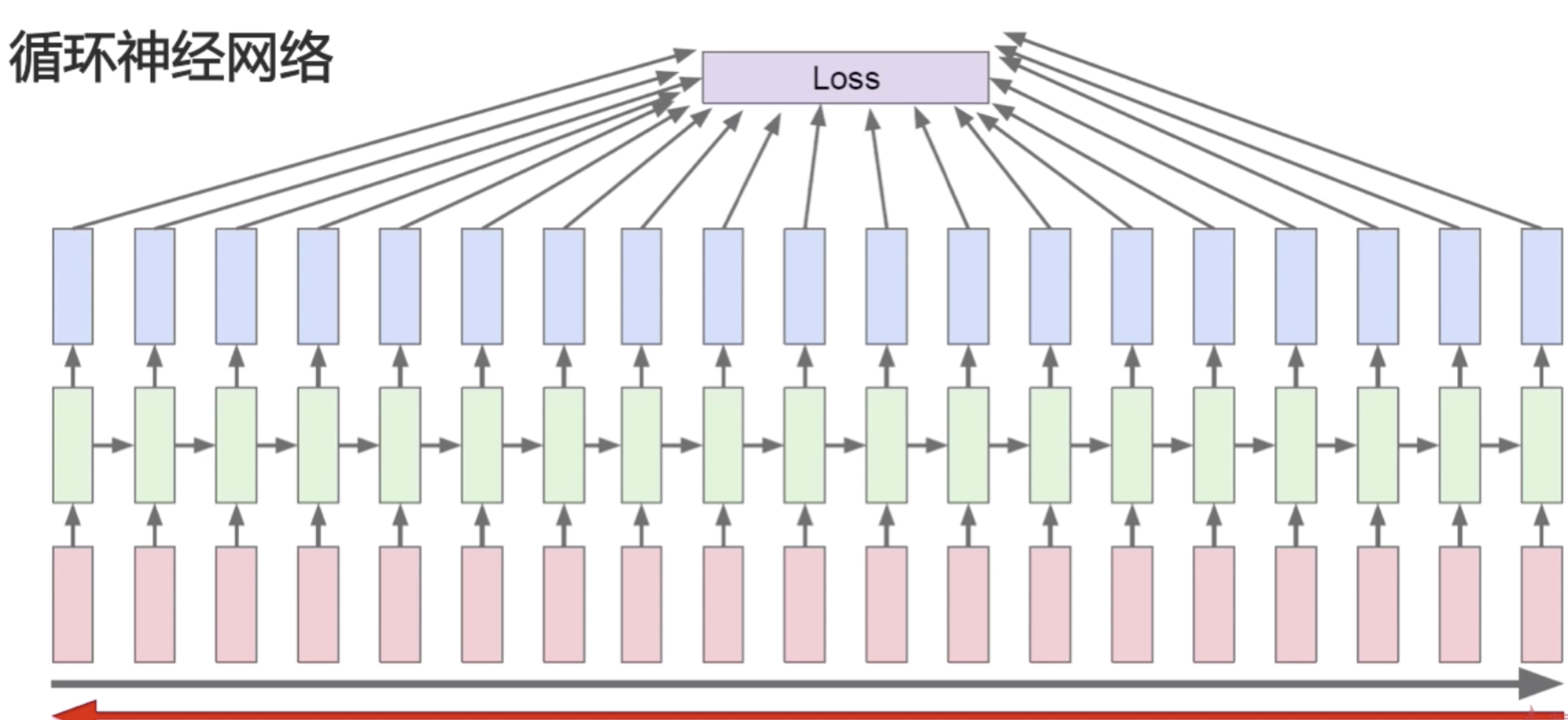
损失函数的计算是每一步的损失函数都加到最后的loss上来,然后去做梯度下降。
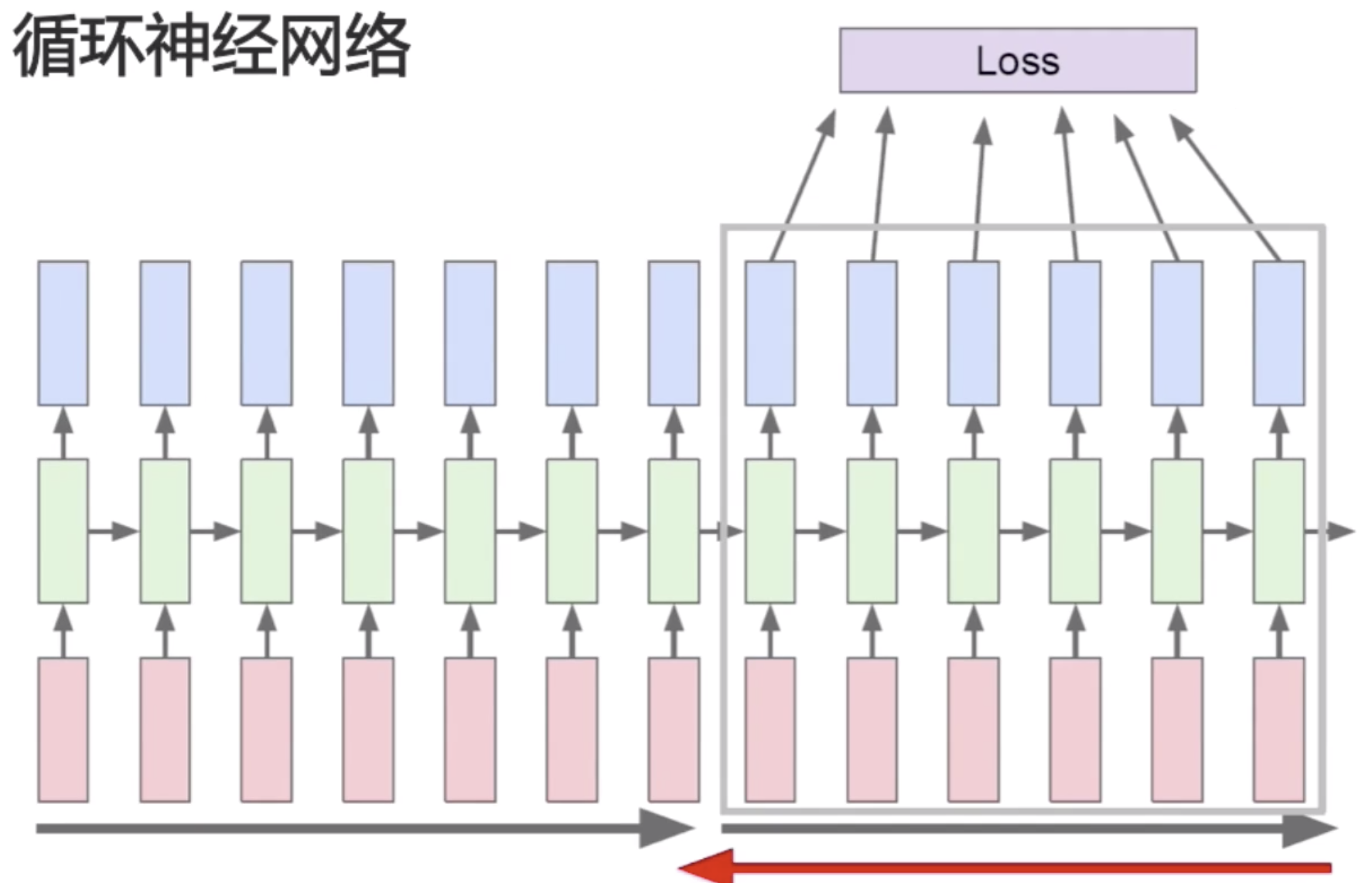
不过我们刚才也说了,因为较远的步骤,比如说第一的步骤,它可能对最后一步的梯度计算是很有限的,所以我们可以做一个优化,可以分区的去计算损失函数,把序列分成几个大的块,然后再分别去计算梯度。这一块计算完梯度之后,我们就认为它再往前的序列值就不会有影响。
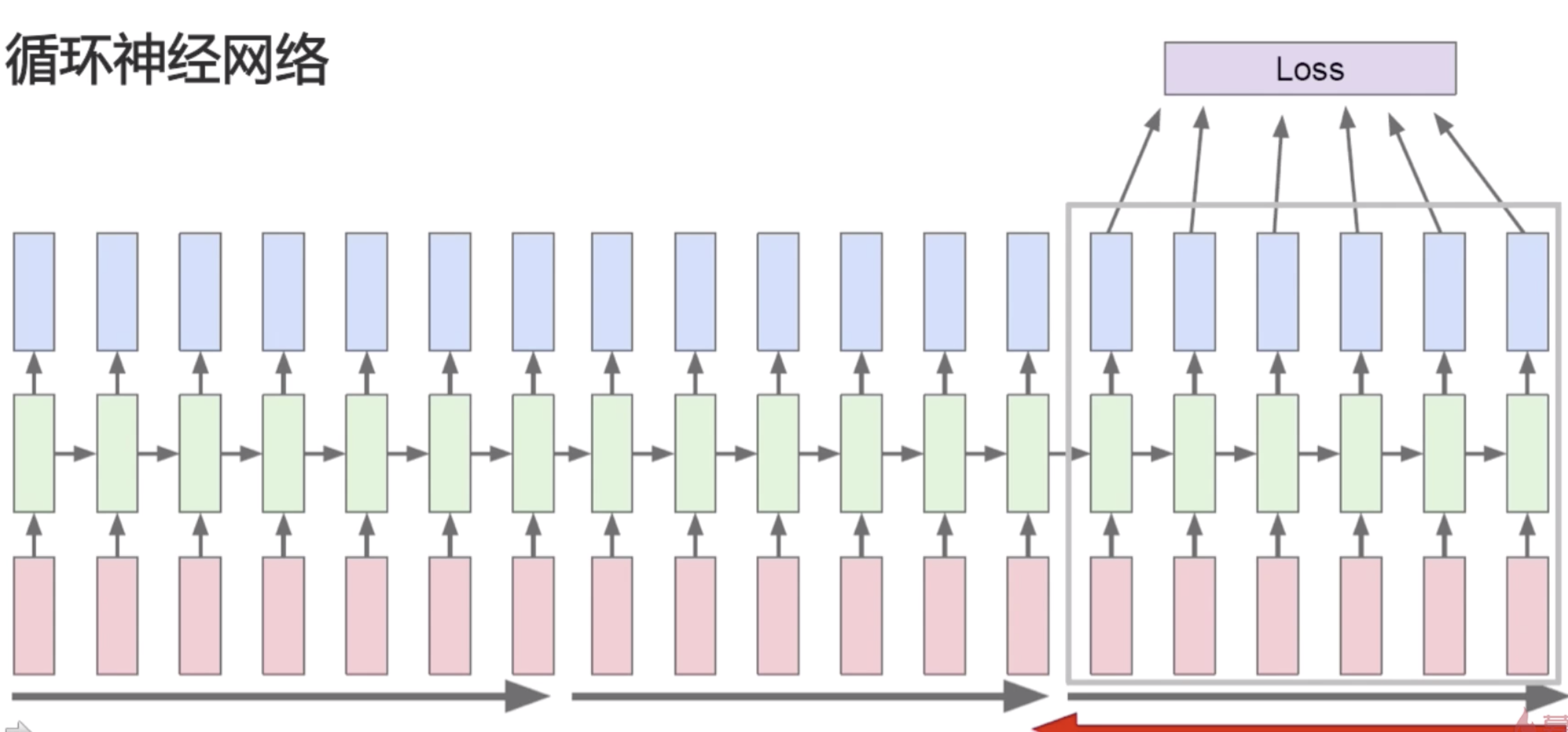
计算完一部分序列的梯度之后再去计算下一部分的梯度。
多层网络与双向网络
多层网络:底层输出作为高层输入
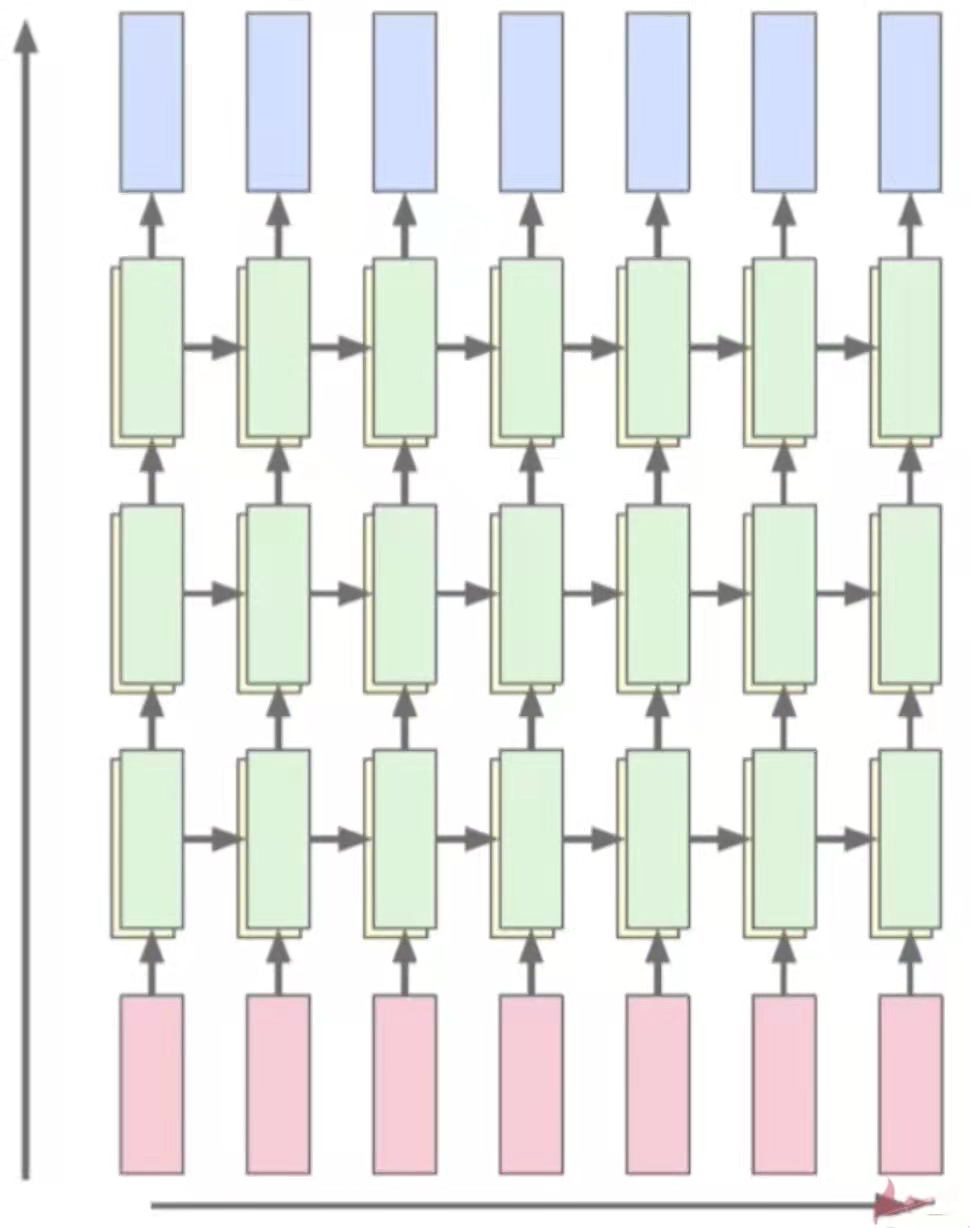
我们之前讲的都是单层的循环神经网络,在这里,我们可以像卷积神经网络一样,把层次都叠加在一起,形成一个多层的网络,底层作为高层的输入,同层之间依旧递归。增加网络拟合能力。和之前的卷积神经网络类似,加了多层之后,因为每一层都是非线性的变换,可以增加网络的拟合能力。一般隐层的维数是逐渐递增的,64 - 128 - 256.
RNN+残差链接
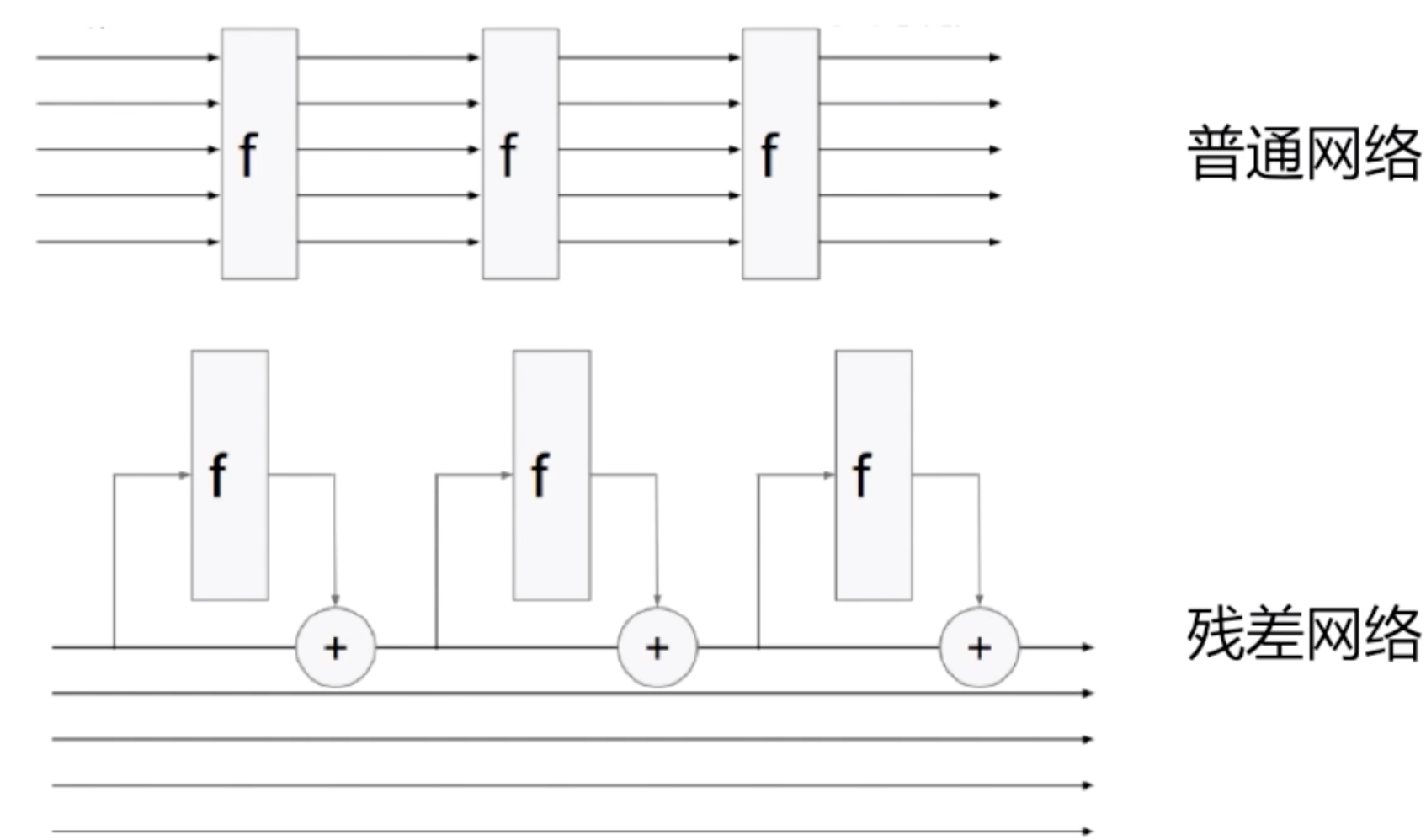
同样有了多层的循环神经网络,自然之前的卷积神经网络的设置也可以用到循环神经网络中,比如残差网络。我们让网络去学剩余的东西,而把原来的值给加到网络中来。
双向网络
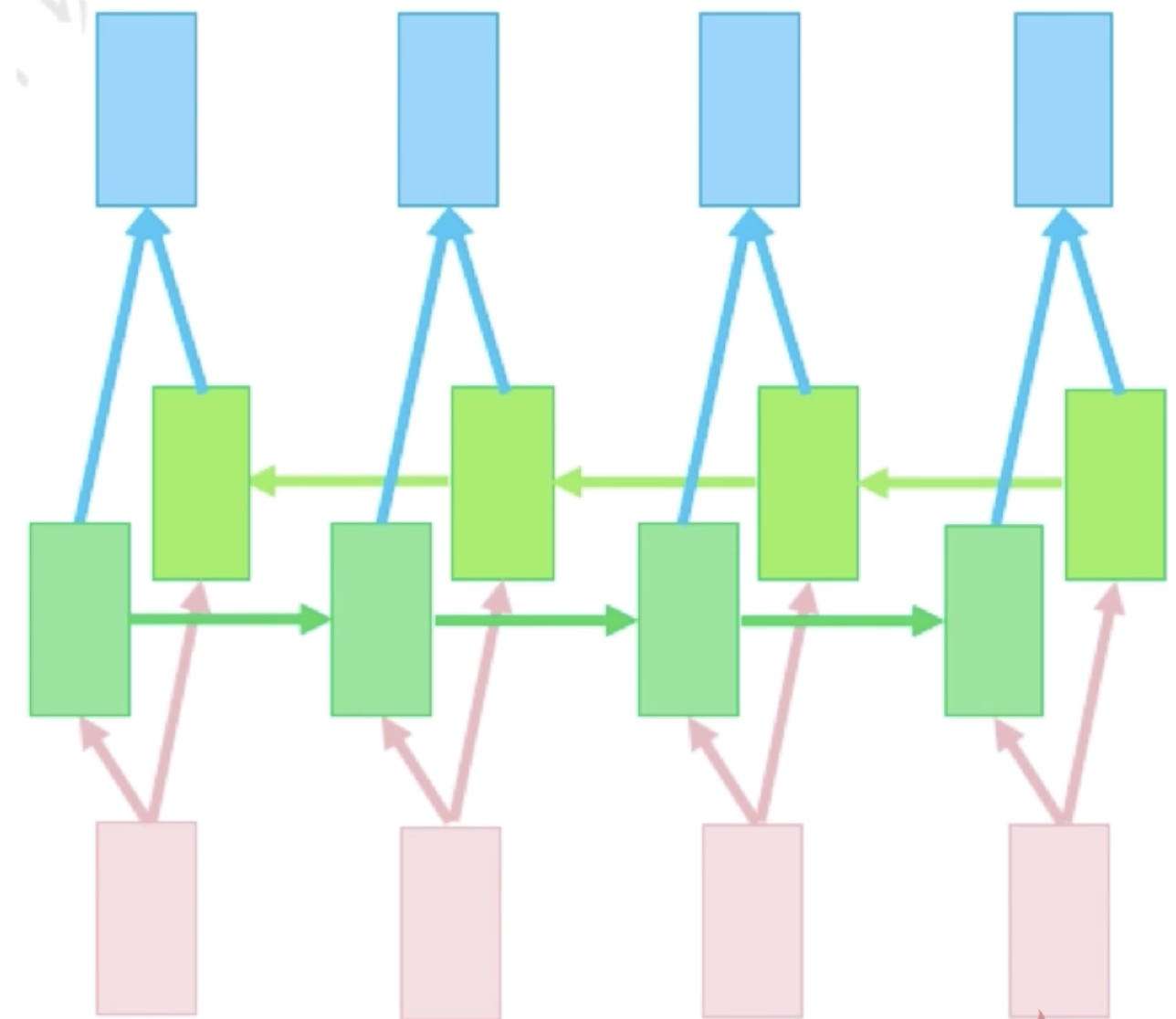
另一路以未来状态为输入。对于循环神经网络和卷积神经网络的不同在于它的输入是一个序列,一个序列可以正向的做输入,也可以反向去做输入。在上图中我们可以看到,深绿色的是一个正向的循环神经网络结构,而浅绿色是一个逆向的循环神经网络结构。这样的网络结构就可以使得它学到上下文的信息。对于正向循环神经网络结构,我可以学到上文的信息,对于还没有输入的肯定还不知道,加了另外一路连接之后,就可以用到下文的信息。两个状态拼接后进入输出层,进一步提高表达能力。但是这样就无法实时的输出结果了,双向网络运用的问题的空间会比较小。但是对于非实时的机器翻译,是可以使用双向神经网络结构的,而且会比单向获得更好的效果。
现在我们用tensorflow2来看一下一个RNN的例子,这是一个情感分析的二分类问题,对电影的评价进行好评还是差评进行分类。我们可以先来看一下它里面的句子中的单词
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers, optimizers, Sequential
from tensorflow.keras.datasets import imdb
if __name__ == "__main__":
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batchsz = 128
# 常见单词数量
total_words = 10000
max_review_len = 80
embedding_len = 100
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=total_words)
avg_len = list(map(len, X_train))
np.mean(avg_len)
word2index = imdb.get_word_index()
index2word = dict([(value, key) for (key, value) in word2index.items()])
for j in range(10):
decoded_review = [index2word.get(i - 3) for i in X_train[j]][1:]
print(decoded_review)
# 将每个句子的单词数限制为80
X_train = keras.preprocessing.sequence.pad_sequences(X_train, maxlen=max_review_len)
X_test = keras.preprocessing.sequence.pad_sequences(X_test, maxlen=max_review_len)
# 构建tensorflow数据集
db_train = tf.data.Dataset.from_tensor_slices((X_train, y_train))
# 将训练数据集乱序后取批次,每批128长度,并丢弃最后一个批次
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((X_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print(X_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print(X_test.shape)
['this', 'film', 'was', 'just', 'brilliant', 'casting', 'location', 'scenery', 'story', 'direction', "everyone's", 'really', 'suited', 'the', 'part', 'they', 'played', 'and', 'you', 'could', 'just', 'imagine', 'being', 'there', 'robert', None, 'is', 'an', 'amazing', 'actor', 'and', 'now', 'the', 'same', 'being', 'director', None, 'father', 'came', 'from', 'the', 'same', 'scottish', 'island', 'as', 'myself', 'so', 'i', 'loved', 'the', 'fact', 'there', 'was', 'a', 'real', 'connection', 'with', 'this', 'film', 'the', 'witty', 'remarks', 'throughout', 'the', 'film', 'were', 'great', 'it', 'was', 'just', 'brilliant', 'so', 'much', 'that', 'i', 'bought', 'the', 'film', 'as', 'soon', 'as', 'it', 'was', 'released', 'for', None, 'and', 'would', 'recommend', 'it', 'to', 'everyone', 'to', 'watch', 'and', 'the', 'fly', 'fishing', 'was', 'amazing', 'really', 'cried', 'at', 'the', 'end', 'it', 'was', 'so', 'sad', 'and', 'you', 'know', 'what', 'they', 'say', 'if', 'you', 'cry', 'at', 'a', 'film', 'it', 'must', 'have', 'been', 'good', 'and', 'this', 'definitely', 'was', 'also', None, 'to', 'the', 'two', 'little', "boy's", 'that', 'played', 'the', None, 'of', 'norman', 'and', 'paul', 'they', 'were', 'just', 'brilliant', 'children', 'are', 'often', 'left', 'out', 'of', 'the', None, 'list', 'i', 'think', 'because', 'the', 'stars', 'that', 'play', 'them', 'all', 'grown', 'up', 'are', 'such', 'a', 'big', 'profile', 'for', 'the', 'whole', 'film', 'but', 'these', 'children', 'are', 'amazing', 'and', 'should', 'be', 'praised', 'for', 'what', 'they', 'have', 'done', "don't", 'you', 'think', 'the', 'whole', 'story', 'was', 'so', 'lovely', 'because', 'it', 'was', 'true', 'and', 'was', "someone's", 'life', 'after', 'all', 'that', 'was', 'shared', 'with', 'us', 'all']
['big', 'hair', 'big', 'boobs', 'bad', 'music', 'and', 'a', 'giant', 'safety', 'pin', 'these', 'are', 'the', 'words', 'to', 'best', 'describe', 'this', 'terrible', 'movie', 'i', 'love', 'cheesy', 'horror', 'movies', 'and', "i've", 'seen', 'hundreds', 'but', 'this', 'had', 'got', 'to', 'be', 'on', 'of', 'the', 'worst', 'ever', 'made', 'the', 'plot', 'is', 'paper', 'thin', 'and', 'ridiculous', 'the', 'acting', 'is', 'an', 'abomination', 'the', 'script', 'is', 'completely', 'laughable', 'the', 'best', 'is', 'the', 'end', 'showdown', 'with', 'the', 'cop', 'and', 'how', 'he', 'worked', 'out', 'who', 'the', 'killer', 'is', "it's", 'just', 'so', 'damn', 'terribly', 'written', 'the', 'clothes', 'are', 'sickening', 'and', 'funny', 'in', 'equal', None, 'the', 'hair', 'is', 'big', 'lots', 'of', 'boobs', None, 'men', 'wear', 'those', 'cut', None, 'shirts', 'that', 'show', 'off', 'their', None, 'sickening', 'that', 'men', 'actually', 'wore', 'them', 'and', 'the', 'music', 'is', 'just', None, 'trash', 'that', 'plays', 'over', 'and', 'over', 'again', 'in', 'almost', 'every', 'scene', 'there', 'is', 'trashy', 'music', 'boobs', 'and', None, 'taking', 'away', 'bodies', 'and', 'the', 'gym', 'still', "doesn't", 'close', 'for', None, 'all', 'joking', 'aside', 'this', 'is', 'a', 'truly', 'bad', 'film', 'whose', 'only', 'charm', 'is', 'to', 'look', 'back', 'on', 'the', 'disaster', 'that', 'was', 'the', "80's", 'and', 'have', 'a', 'good', 'old', 'laugh', 'at', 'how', 'bad', 'everything', 'was', 'back', 'then']
['this', 'has', 'to', 'be', 'one', 'of', 'the', 'worst', 'films', 'of', 'the', '1990s', 'when', 'my', 'friends', 'i', 'were', 'watching', 'this', 'film', 'being', 'the', 'target', 'audience', 'it', 'was', 'aimed', 'at', 'we', 'just', 'sat', 'watched', 'the', 'first', 'half', 'an', 'hour', 'with', 'our', 'jaws', 'touching', 'the', 'floor', 'at', 'how', 'bad', 'it', 'really', 'was', 'the', 'rest', 'of', 'the', 'time', 'everyone', 'else', 'in', 'the', 'theatre', 'just', 'started', 'talking', 'to', 'each', 'other', 'leaving', 'or', 'generally', 'crying', 'into', 'their', 'popcorn', 'that', 'they', 'actually', 'paid', 'money', 'they', 'had', None, 'working', 'to', 'watch', 'this', 'feeble', 'excuse', 'for', 'a', 'film', 'it', 'must', 'have', 'looked', 'like', 'a', 'great', 'idea', 'on', 'paper', 'but', 'on', 'film', 'it', 'looks', 'like', 'no', 'one', 'in', 'the', 'film', 'has', 'a', 'clue', 'what', 'is', 'going', 'on', 'crap', 'acting', 'crap', 'costumes', 'i', "can't", 'get', 'across', 'how', None, 'this', 'is', 'to', 'watch', 'save', 'yourself', 'an', 'hour', 'a', 'bit', 'of', 'your', 'life']
['the', None, None, 'at', 'storytelling', 'the', 'traditional', 'sort', 'many', 'years', 'after', 'the', 'event', 'i', 'can', 'still', 'see', 'in', 'my', None, 'eye', 'an', 'elderly', 'lady', 'my', "friend's", 'mother', 'retelling', 'the', 'battle', 'of', None, 'she', 'makes', 'the', 'characters', 'come', 'alive', 'her', 'passion', 'is', 'that', 'of', 'an', 'eye', 'witness', 'one', 'to', 'the', 'events', 'on', 'the', None, 'heath', 'a', 'mile', 'or', 'so', 'from', 'where', 'she', 'lives', 'br', 'br', 'of', 'course', 'it', 'happened', 'many', 'years', 'before', 'she', 'was', 'born', 'but', 'you', "wouldn't", 'guess', 'from', 'the', 'way', 'she', 'tells', 'it', 'the', 'same', 'story', 'is', 'told', 'in', 'bars', 'the', 'length', 'and', None, 'of', 'scotland', 'as', 'i', 'discussed', 'it', 'with', 'a', 'friend', 'one', 'night', 'in', None, 'a', 'local', 'cut', 'in', 'to', 'give', 'his', 'version', 'the', 'discussion', 'continued', 'to', 'closing', 'time', 'br', 'br', 'stories', 'passed', 'down', 'like', 'this', 'become', 'part', 'of', 'our', 'being', 'who', "doesn't", 'remember', 'the', 'stories', 'our', 'parents', 'told', 'us', 'when', 'we', 'were', 'children', 'they', 'become', 'our', 'invisible', 'world', 'and', 'as', 'we', 'grow', 'older', 'they', 'maybe', 'still', 'serve', 'as', 'inspiration', 'or', 'as', 'an', 'emotional', None, 'fact', 'and', 'fiction', 'blend', 'with', None, 'role', 'models', 'warning', 'stories', None, 'magic', 'and', 'mystery', 'br', 'br', 'my', 'name', 'is', None, 'like', 'my', 'grandfather', 'and', 'his', 'grandfather', 'before', 'him', 'our', 'protagonist', 'introduces', 'himself', 'to', 'us', 'and', 'also', 'introduces', 'the', 'story', 'that', 'stretches', 'back', 'through', 'generations', 'it', 'produces', 'stories', 'within', 'stories', 'stories', 'that', 'evoke', 'the', None, 'wonder', 'of', 'scotland', 'its', 'rugged', 'mountains', None, 'in', None, 'the', 'stuff', 'of', 'legend', 'yet', None, 'is', None, 'in', 'reality', 'this', 'is', 'what', 'gives', 'it', 'its', 'special', 'charm', 'it', 'has', 'a', 'rough', 'beauty', 'and', 'authenticity', None, 'with', 'some', 'of', 'the', 'finest', None, 'singing', 'you', 'will', 'ever', 'hear', 'br', 'br', None, None, 'visits', 'his', 'grandfather', 'in', 'hospital', 'shortly', 'before', 'his', 'death', 'he', 'burns', 'with', 'frustration', 'part', 'of', 'him', None, 'to', 'be', 'in', 'the', 'twenty', 'first', 'century', 'to', 'hang', 'out', 'in', None, 'but', 'he', 'is', 'raised', 'on', 'the', 'western', None, 'among', 'a', None, 'speaking', 'community', 'br', 'br', 'yet', 'there', 'is', 'a', 'deeper', 'conflict', 'within', 'him', 'he', None, 'to', 'know', 'the', 'truth', 'the', 'truth', 'behind', 'his', None, 'ancient', 'stories', 'where', 'does', 'fiction', 'end', 'and', 'he', 'wants', 'to', 'know', 'the', 'truth', 'behind', 'the', 'death', 'of', 'his', 'parents', 'br', 'br', 'he', 'is', 'pulled', 'to', 'make', 'a', 'last', None, 'journey', 'to', 'the', None, 'of', 'one', 'of', None, 'most', None, 'mountains', 'can', 'the', 'truth', 'be', 'told', 'or', 'is', 'it', 'all', 'in', 'stories', 'br', 'br', 'in', 'this', 'story', 'about', 'stories', 'we', None, 'bloody', 'battles', None, 'lovers', 'the', None, 'of', 'old', 'and', 'the', 'sometimes', 'more', None, None, 'of', 'accepted', 'truth', 'in', 'doing', 'so', 'we', 'each', 'connect', 'with', None, 'as', 'he', 'lives', 'the', 'story', 'of', 'his', 'own', 'life', 'br', 'br', None, 'the', None, None, 'is', 'probably', 'the', 'most', 'honest', None, 'and', 'genuinely', 'beautiful', 'film', 'of', 'scotland', 'ever', 'made', 'like', None, 'i', 'got', 'slightly', 'annoyed', 'with', 'the', None, 'of', 'hanging', 'stories', 'on', 'more', 'stories', 'but', 'also', 'like', None, 'i', None, 'this', 'once', 'i', 'saw', 'the', None, 'picture', "'", 'forget', 'the', 'box', 'office', None, 'of', 'braveheart', 'and', 'its', 'like', 'you', 'might', 'even', None, 'the', None, 'famous', None, 'of', 'the', 'wicker', 'man', 'to', 'see', 'a', 'film', 'that', 'is', 'true', 'to', 'scotland', 'this', 'one', 'is', 'probably', 'unique', 'if', 'you', 'maybe', None, 'on', 'it', 'deeply', 'enough', 'you', 'might', 'even', 're', None, 'the', 'power', 'of', 'storytelling', 'and', 'the', 'age', 'old', 'question', 'of', 'whether', 'there', 'are', 'some', 'truths', 'that', 'cannot', 'be', 'told', 'but', 'only', 'experienced']
['worst', 'mistake', 'of', 'my', 'life', 'br', 'br', 'i', 'picked', 'this', 'movie', 'up', 'at', 'target', 'for', '5', 'because', 'i', 'figured', 'hey', "it's", 'sandler', 'i', 'can', 'get', 'some', 'cheap', 'laughs', 'i', 'was', 'wrong', 'completely', 'wrong', 'mid', 'way', 'through', 'the', 'film', 'all', 'three', 'of', 'my', 'friends', 'were', 'asleep', 'and', 'i', 'was', 'still', 'suffering', 'worst', 'plot', 'worst', 'script', 'worst', 'movie', 'i', 'have', 'ever', 'seen', 'i', 'wanted', 'to', 'hit', 'my', 'head', 'up', 'against', 'a', 'wall', 'for', 'an', 'hour', 'then', "i'd", 'stop', 'and', 'you', 'know', 'why', 'because', 'it', 'felt', 'damn', 'good', 'upon', 'bashing', 'my', 'head', 'in', 'i', 'stuck', 'that', 'damn', 'movie', 'in', 'the', None, 'and', 'watched', 'it', 'burn', 'and', 'that', 'felt', 'better', 'than', 'anything', 'else', "i've", 'ever', 'done', 'it', 'took', 'american', 'psycho', 'army', 'of', 'darkness', 'and', 'kill', 'bill', 'just', 'to', 'get', 'over', 'that', 'crap', 'i', 'hate', 'you', 'sandler', 'for', 'actually', 'going', 'through', 'with', 'this', 'and', 'ruining', 'a', 'whole', 'day', 'of', 'my', 'life']
['begins', 'better', 'than', 'it', 'ends', 'funny', 'that', 'the', 'russian', 'submarine', 'crew', None, 'all', 'other', 'actors', "it's", 'like', 'those', 'scenes', 'where', 'documentary', 'shots', 'br', 'br', 'spoiler', 'part', 'the', 'message', None, 'was', 'contrary', 'to', 'the', 'whole', 'story', 'it', 'just', 'does', 'not', None, 'br', 'br']
['lavish', 'production', 'values', 'and', 'solid', 'performances', 'in', 'this', 'straightforward', 'adaption', 'of', 'jane', None, 'satirical', 'classic', 'about', 'the', 'marriage', 'game', 'within', 'and', 'between', 'the', 'classes', 'in', None, '18th', 'century', 'england', 'northam', 'and', 'paltrow', 'are', 'a', None, 'mixture', 'as', 'friends', 'who', 'must', 'pass', 'through', None, 'and', 'lies', 'to', 'discover', 'that', 'they', 'love', 'each', 'other', 'good', 'humor', 'is', 'a', None, 'virtue', 'which', 'goes', 'a', 'long', 'way', 'towards', 'explaining', 'the', None, 'of', 'the', 'aged', 'source', 'material', 'which', 'has', 'been', 'toned', 'down', 'a', 'bit', 'in', 'its', 'harsh', None, 'i', 'liked', 'the', 'look', 'of', 'the', 'film', 'and', 'how', 'shots', 'were', 'set', 'up', 'and', 'i', 'thought', 'it', "didn't", 'rely', 'too', 'much', 'on', None, 'of', 'head', 'shots', 'like', 'most', 'other', 'films', 'of', 'the', '80s', 'and', '90s', 'do', 'very', 'good', 'results']
['the', None, 'tells', 'the', 'story', 'of', 'the', 'four', 'hamilton', 'siblings', 'teenager', 'francis', None, None, 'twins', None, 'joseph', None, None, None, None, 'the', None, 'david', 'samuel', 'who', 'is', 'now', 'the', 'surrogate', 'parent', 'in', 'charge', 'the', None, 'move', 'house', 'a', 'lot', None, 'is', 'unsure', 'why', 'is', 'unhappy', 'with', 'the', 'way', 'things', 'are', 'the', 'fact', 'that', 'his', "brother's", 'sister', 'kidnap', None, 'murder', 'people', 'in', 'the', 'basement', "doesn't", 'help', 'relax', 'or', 'calm', None, 'nerves', 'either', 'francis', None, 'something', 'just', "isn't", 'right', 'when', 'he', 'eventually', 'finds', 'out', 'the', 'truth', 'things', 'will', 'never', 'be', 'the', 'same', 'again', 'br', 'br', 'co', 'written', 'co', 'produced', 'directed', 'by', 'mitchell', None, 'phil', None, 'as', 'the', 'butcher', 'brothers', "who's", 'only', 'other', 'film', "director's", 'credit', 'so', 'far', 'is', 'the', 'april', None, 'day', '2008', 'remake', 'enough', 'said', 'this', 'was', 'one', 'of', 'the', None, 'to', 'die', None, 'at', 'the', '2006', 'after', 'dark', None, 'or', 'whatever', "it's", 'called', 'in', 'keeping', 'with', 'pretty', 'much', 'all', 'the', "other's", "i've", 'seen', 'i', 'thought', 'the', None, 'was', 'complete', 'total', 'utter', 'crap', 'i', 'found', 'the', "character's", 'really', 'poor', 'very', 'unlikable', 'the', 'slow', 'moving', 'story', 'failed', 'to', 'capture', 'my', 'imagination', 'or', 'sustain', 'my', 'interest', 'over', "it's", '85', 'a', 'half', 'minute', 'too', 'long', None, 'minute', 'duration', 'the', "there's", 'the', 'awful', 'twist', 'at', 'the', 'end', 'which', 'had', 'me', 'laughing', 'out', 'loud', "there's", 'this', 'really', 'big', None, 'build', 'up', 'to', "what's", 'inside', 'a', None, 'thing', 'in', 'the', None, 'basement', "it's", 'eventually', 'revealed', 'to', 'be', 'a', 'little', 'boy', 'with', 'a', 'teddy', 'is', 'that', 'really', 'supposed', 'to', 'scare', 'us', 'is', 'that', 'really', 'supposed', 'to', 'shock', 'us', 'is', 'that', 'really', 'something', 'that', 'is', 'supposed', 'to', 'have', 'us', 'talking', 'about', 'it', 'as', 'the', 'end', 'credits', 'roll', 'is', 'a', 'harmless', 'looking', 'young', 'boy', 'the', 'best', None, 'ending', 'that', 'the', 'makers', 'could', 'come', 'up', 'with', 'the', 'boring', 'plot', None, 'along', "it's", 'never', 'made', 'clear', 'where', 'the', None, 'get', 'all', 'their', 'money', 'from', 'to', 'buy', 'new', 'houses', 'since', 'none', 'of', 'them', 'seem', 'to', 'work', 'except', 'david', 'in', 'a', None, 'i', 'doubt', 'that', 'pays', 'much', 'or', 'why', 'they', "haven't", 'been', 'caught', 'before', 'now', 'the', 'script', 'tries', 'to', 'mix', 'in', 'every', 'day', 'drama', 'with', 'potent', 'horror', 'it', 'just', 'does', 'a', 'terrible', 'job', 'of', 'combining', 'the', 'two', 'to', 'the', 'extent', 'that', 'neither', 'aspect', 'is', 'memorable', 'or', 'effective', 'a', 'really', 'bad', 'film', 'that', 'i', 'am', 'struggling', 'to', 'say', 'anything', 'good', 'about', 'br', 'br', 'despite', 'being', 'written', 'directed', 'by', 'the', 'extreme', 'sounding', 'butcher', 'brothers', "there's", 'no', 'gore', 'here', "there's", 'a', 'bit', 'of', 'blood', 'splatter', 'a', 'few', 'scenes', 'of', 'girls', None, 'up', 'in', 'a', 'basement', 'but', 'nothing', 'you', "couldn't", 'do', 'at', 'home', 'yourself', 'with', 'a', 'bottle', 'of', None, None, 'a', 'camcorder', 'the', 'film', 'is', 'neither', 'scary', 'since', "it's", 'got', 'a', 'very', 'middle', 'class', 'suburban', 'setting', "there's", 'zero', 'atmosphere', 'or', 'mood', "there's", 'a', 'lesbian', 'suggest', 'incestuous', 'kiss', 'but', 'the', None, 'is', 'low', 'on', 'the', 'exploitation', 'scale', "there's", 'not', 'much', 'here', 'for', 'the', 'horror', 'crowd', 'br', 'br', 'filmed', 'in', None, 'in', 'california', 'this', 'has', 'that', 'modern', 'low', 'budget', 'look', 'about', 'it', "it's", 'not', 'badly', 'made', 'but', 'rather', 'forgettable', 'the', 'acting', 'by', 'an', 'unknown', 'to', 'me', 'cast', 'is', 'nothing', 'to', 'write', 'home', 'about', 'i', "can't", 'say', 'i', 'ever', 'felt', 'anything', 'for', 'anyone', 'br', 'br', 'the', None, 'commits', 'the', None, 'sin', 'of', 'being', 'both', 'dull', 'boring', 'from', 'which', 'it', 'never', None, 'add', 'to', 'that', 'an', 'ultra', 'thin', 'story', 'no', 'gore', 'a', 'rubbish', 'ending', "character's", 'who', 'you', "don't", 'give', 'a', 'toss', 'about', 'you', 'have', 'a', 'film', 'that', 'did', 'not', 'impress', 'me', 'at', 'all']
['just', 'got', 'out', 'and', 'cannot', 'believe', 'what', 'a', 'brilliant', 'documentary', 'this', 'is', 'rarely', 'do', 'you', 'walk', 'out', 'of', 'a', 'movie', 'theater', 'in', 'such', 'awe', 'and', None, 'lately', 'movies', 'have', 'become', 'so', 'over', 'hyped', 'that', 'the', 'thrill', 'of', 'discovering', 'something', 'truly', 'special', 'and', 'unique', 'rarely', 'happens', None, None, 'did', 'this', 'to', 'me', 'when', 'it', 'first', 'came', 'out', 'and', 'this', 'movie', 'is', 'doing', 'to', 'me', 'now', 'i', "didn't", 'know', 'a', 'thing', 'about', 'this', 'before', 'going', 'into', 'it', 'and', 'what', 'a', 'surprise', 'if', 'you', 'hear', 'the', 'concept', 'you', 'might', 'get', 'the', 'feeling', 'that', 'this', 'is', 'one', 'of', 'those', None, 'movies', 'about', 'an', 'amazing', 'triumph', 'covered', 'with', 'over', 'the', 'top', 'music', 'and', 'trying', 'to', 'have', 'us', 'fully', 'convinced', 'of', 'what', 'a', 'great', 'story', 'it', 'is', 'telling', 'but', 'then', 'not', 'letting', 'us', 'in', None, 'this', 'is', 'not', 'that', 'movie', 'the', 'people', 'tell', 'the', 'story', 'this', 'does', 'such', 'a', 'good', 'job', 'of', 'capturing', 'every', 'moment', 'of', 'their', 'involvement', 'while', 'we', 'enter', 'their', 'world', 'and', 'feel', 'every', 'second', 'with', 'them', 'there', 'is', 'so', 'much', 'beyond', 'the', 'climb', 'that', 'makes', 'everything', 'they', 'go', 'through', 'so', 'much', 'more', 'tense', 'touching', 'the', 'void', 'was', 'also', 'a', 'great', 'doc', 'about', 'mountain', 'climbing', 'and', 'showing', 'the', 'intensity', 'in', 'an', 'engaging', 'way', 'but', 'this', 'film', 'is', 'much', 'more', 'of', 'a', 'human', 'story', 'i', 'just', 'saw', 'it', 'today', 'but', 'i', 'will', 'go', 'and', 'say', 'that', 'this', 'is', 'one', 'of', 'the', 'best', 'documentaries', 'i', 'have', 'ever', 'seen']
['this', 'movie', 'has', 'many', 'problem', 'associated', 'with', 'it', 'that', 'makes', 'it', 'come', 'off', 'like', 'a', 'low', 'budget', 'class', 'project', 'from', 'someone', 'in', 'film', 'school', 'i', 'have', 'to', 'give', 'it', 'credit', 'on', 'its', None, 'though', 'many', 'times', 'throughout', 'the', 'movie', 'i', 'found', 'myself', 'laughing', 'hysterically', 'it', 'was', 'so', 'bad', 'at', 'times', 'that', 'it', 'was', 'comical', 'which', 'made', 'it', 'a', 'fun', 'watch', 'br', 'br', 'if', "you're", 'looking', 'for', 'a', 'low', 'grade', 'slasher', 'movie', 'with', 'a', 'twist', 'of', 'psychological', 'horror', 'and', 'a', 'dash', 'of', 'campy', None, 'then', 'pop', 'a', 'bowl', 'of', 'popcorn', 'invite', 'some', 'friends', 'over', 'and', 'have', 'some', 'fun', 'br', 'br', 'i', 'agree', 'with', 'other', 'comments', 'that', 'the', 'sound', 'is', 'very', 'bad', 'dialog', 'is', 'next', 'to', 'impossible', 'to', 'follow', 'much', 'of', 'the', 'time', 'and', 'the', 'soundtrack', 'is', 'kind', 'of', 'just', 'there']
(25000, 80) tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
(25000, 80)这里我们可以看到,无论是训练数据集还是测试数据集都有25000条句子,每个句子有80个单词。y=1的时候代表着好评,y=0的时候代表差评。现在我们来构建最普通的RNN模型来进行训练
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers, optimizers
if __name__ == "__main__":
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batchsz = 128
# 常见单词数量
total_words = 10000
max_review_len = 80
embedding_len = 100
(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# 将每个句子的单词数限制为80
X_train = keras.preprocessing.sequence.pad_sequences(X_train, maxlen=max_review_len)
X_test = keras.preprocessing.sequence.pad_sequences(X_test, maxlen=max_review_len)
# 构建tensorflow数据集
db_train = tf.data.Dataset.from_tensor_slices((X_train, y_train))
# 将训练数据集乱序后取批次,每批128长度,并丢弃最后一个批次
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((X_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print(X_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print(X_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# RNN的初始状态
self.state0 = [tf.zeros([batchsz, units])]
# 将文本的单词转化为100维向量,[b, 80] -> [b, 80, 100]
# 这里表示每个句子有80个单词,每个单词用100维向量表示
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# 建立一个序列式传递单元,传递序列数为units
# 它的最终输出是一个统计结果[b, 80, 100] -> [b, 64]
self.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.2)
# 建立一个全连接层,输出维度为1
self.fc = layers.Dense(1)
def call(self, inputs, training=None):
'''
:param inputs: 文本输入[b, 80]
:param training: 判断是训练模式还是测试模式
:return:
'''
X = inputs
X = self.embedding(X)
state0 = self.state0
# 遍历句子中的每一个单词向量
for word in tf.unstack(X, axis=1):
# 计算tanh(Ws+Ux),这里state1是新状态,out=state1,但是out不做更新
out, state1 = self.rnn_cell0(word, state0, training)
state0 = state1
# out:[b, 64]
X = self.fc(out)
prob = tf.sigmoid(X)
return prob
def main():
units = 64
epochs = 4
model = MyRNN(units)
# 创建一个梯度下降优化器
optimizer = optimizers.Adam(learning_rate=1e-3)
# 二分类损失函数
loss = tf.losses.BinaryCrossentropy()
model.compile(optimizer=optimizer, loss=loss,
metrics=['accuracy'], experimental_run_tf_function=False)
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
main()
(25000, 80) tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
(25000, 80)
Epoch 1/4
195/195 [==============================] - 44s 225ms/step - loss: 0.4856 - accuracy: 0.6881 - val_loss: 0.3793 - val_accuracy: 0.8349
Epoch 2/4
195/195 [==============================] - 31s 161ms/step - loss: 0.3023 - accuracy: 0.8679 - val_loss: 0.3819 - val_accuracy: 0.8321
Epoch 3/4
195/195 [==============================] - 32s 164ms/step - loss: 0.1812 - accuracy: 0.9251 - val_loss: 0.4525 - val_accuracy: 0.8210
Epoch 4/4
195/195 [==============================] - 31s 161ms/step - loss: 0.0834 - accuracy: 0.9692 - val_loss: 0.5541 - val_accuracy: 0.8152
195/195 [==============================] - 10s 49ms/step - loss: 0.5541 - accuracy: 0.8152这里我们可以看到它的训练数据集的分类准确度可以达到96.92%,而测试数据集的分类准确度只有81.52,说明这里存在一定的过拟合,现在我们来增加一层RNN网络,使它变为一个多层网络结构
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers, optimizers
if __name__ == "__main__":
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batchsz = 128
# 常见单词数量
total_words = 10000
max_review_len = 80
embedding_len = 100
(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# 将每个句子的单词数限制为80
X_train = keras.preprocessing.sequence.pad_sequences(X_train, maxlen=max_review_len)
X_test = keras.preprocessing.sequence.pad_sequences(X_test, maxlen=max_review_len)
# 构建tensorflow数据集
db_train = tf.data.Dataset.from_tensor_slices((X_train, y_train))
# 将训练数据集乱序后取批次,每批128长度,并丢弃最后一个批次
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((X_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print(X_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print(X_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# RNN的初始状态
self.state0 = [tf.zeros([batchsz, units])]
self.state1 = [tf.zeros([batchsz, units])]
# 将文本的单词转化为100维向量,[b, 80] -> [b, 80, 100]
# 这里表示每个句子有80个单词,每个单词用100维向量表示
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# 建立一个序列式传递单元,传递序列数为units
# 它的最终输出是一个统计结果[b, 80, 100] -> [b, 64]
self.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.5)
self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.5)
# 建立一个全连接层,输出维度为1
self.fc = layers.Dense(1)
def call(self, inputs, training=None):
'''
:param inputs: 文本输入[b, 80]
:param training: 判断是训练模式还是测试模式
:return:
'''
X = inputs
X = self.embedding(X)
state0 = self.state0
state1 = self.state1
# 遍历句子中的每一个单词向量
for word in tf.unstack(X, axis=1):
# 计算tanh(Ws+Ux),这里state1是新状态,out=state1,但是out不做更新
out0, state0 = self.rnn_cell0(word, state0, training)
out1, state1 = self.rnn_cell1(out0, state1, training)
# out:[b, 64]
X = self.fc(out1)
prob = tf.sigmoid(X)
return prob
def main():
units = 64
epochs = 4
model = MyRNN(units)
# 创建一个梯度下降优化器
optimizer = optimizers.Adam(learning_rate=1e-3)
# 二分类损失函数
loss = tf.losses.BinaryCrossentropy()
model.compile(optimizer=optimizer, loss=loss,
metrics=['accuracy'], experimental_run_tf_function=False)
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
main()
(25000, 80) tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
(25000, 80)
Epoch 1/4
195/195 [==============================] - 51s 260ms/step - loss: 0.5781 - accuracy: 0.5808 - val_loss: 0.3949 - val_accuracy: 0.8237
Epoch 2/4
195/195 [==============================] - 35s 181ms/step - loss: 0.3731 - accuracy: 0.8300 - val_loss: 0.3932 - val_accuracy: 0.8355
Epoch 3/4
195/195 [==============================] - 36s 184ms/step - loss: 0.3055 - accuracy: 0.8710 - val_loss: 0.3981 - val_accuracy: 0.8323
Epoch 4/4
195/195 [==============================] - 36s 187ms/step - loss: 0.2515 - accuracy: 0.8974 - val_loss: 0.4310 - val_accuracy: 0.8283
195/195 [==============================] - 11s 58ms/step - loss: 0.4310 - accuracy: 0.8283这里我们调大了dropout,使它每次经过网络层的时候随机去掉一半的神经元,最后我们可以看到对于测试数据集来说,它的准确度得到了提升
当然我们也可以直接使用tensorflow2的层堆叠模型来简化上面的代码
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers, optimizers, Sequential
if __name__ == "__main__":
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batchsz = 128
# 常见单词数量
total_words = 10000
max_review_len = 80
embedding_len = 100
(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# 将每个句子的单词数限制为80
X_train = keras.preprocessing.sequence.pad_sequences(X_train, maxlen=max_review_len)
X_test = keras.preprocessing.sequence.pad_sequences(X_test, maxlen=max_review_len)
# 构建tensorflow数据集
db_train = tf.data.Dataset.from_tensor_slices((X_train, y_train))
# 将训练数据集乱序后取批次,每批128长度,并丢弃最后一个批次
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((X_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print(X_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print(X_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# 将文本的单词转化为100维向量,[b, 80] -> [b, 80, 100]
# 这里表示每个句子有80个单词,每个单词用100维向量表示
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# 建立一个序列式传递单元,传递序列数为units
# 它的最终输出是一个统计结果[b, 80, 100] -> [b, 64]
self.rnn = Sequential([
layers.SimpleRNN(units, dropout=0.5, return_sequences=True, unroll=True),
layers.SimpleRNN(units, dropout=0.5, unroll=True),
layers.Dense(1, activation=tf.nn.sigmoid)
])
def call(self, inputs, training=None):
'''
:param inputs: 文本输入[b, 80]
:param training: 判断是训练模式还是测试模式
:return:
'''
X = inputs
X = self.embedding(X)
prob = self.rnn(X)
return prob
def main():
units = 64
epochs = 4
model = MyRNN(units)
# 创建一个梯度下降优化器
optimizer = optimizers.Adam(learning_rate=1e-3)
# 二分类损失函数
loss = tf.losses.BinaryCrossentropy()
model.compile(optimizer=optimizer, loss=loss,
metrics=['accuracy'], experimental_run_tf_function=False)
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
main()
(25000, 80) tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
(25000, 80)
Epoch 1/4
195/195 [==============================] - 80s 408ms/step - loss: 0.5744 - accuracy: 0.5817 - val_loss: 0.4574 - val_accuracy: 0.8075
Epoch 2/4
195/195 [==============================] - 61s 314ms/step - loss: 0.4095 - accuracy: 0.8231 - val_loss: 0.6226 - val_accuracy: 0.6567
Epoch 3/4
195/195 [==============================] - 61s 311ms/step - loss: 0.4267 - accuracy: 0.7309 - val_loss: 0.4312 - val_accuracy: 0.8227
Epoch 4/4
195/195 [==============================] - 64s 327ms/step - loss: 0.2970 - accuracy: 0.8645 - val_loss: 0.3935 - val_accuracy: 0.8310
195/195 [==============================] - 20s 103ms/step - loss: 0.3935 - accuracy: 0.8310长短期记忆网络
为什么需要LSTM
- 普通RNN的信息不能长久传播(存在于理论上)
循环网络只有一个隐含状态,然后一个隐含状态可以对待一个序列不停的往下面的步骤里传数据,传到最后,就可以保存上下文的信息。如果是单向的话,就只能保存上文的信息。对于这样一个网络,它的缺点就在于它对序列中的信息没有任何的甄别,而是要神经网络靠参数去进行甄别。而它的参数只有一个,在每一步的循环状态中,只有一个W,这相当于就是我们中间需要学很多的规则,比如新开了一句话,而之前有一句话,那么下面这句话换个主语,这个时候就需要知道需要把这个主语的上文信息给更换一下,把之前的忘掉,用这个新的。需要越来越多的这种规则。但是对于参数只有一个W,而这个W只是一个矩阵,它承载了太多,相当于在卷积神经网络中层次过多的时候,参数就会很多,容量就会很大,就会导致过拟合。但是在循环神经网络这个例子中,参数只有一个W,如果加多层就是多个W,但是需要学到的信息很多,对于一个特别长的句子,要删掉什么信息,要记住什么信息,要更新什么信息。这相当于是W过载了,它无法记住那么多的信息,所以就导致了普通RNN的信息只在理论上存在着可以长久传播的方法。不然的话,它还是只能记住最近的一些信息。
为了解决这个问题,引入了LSTM(长短期记忆网络),L是Long,S是Short,T是Term,M是Memory。它引入了选择性机制。
- 选择性输出
- 选择性输入
- 选择性遗忘
相当于在网络结构中对输入和输出都做了一个控制,如果一个输入没什么用的话,就不输入进来;如果当前信息还不需要输出出去,而需要记在当前状态里面,这个时候就控制不让它输出。比如换了一句新的主语,可以需要忘掉之前的主语,在这个时候选择性遗忘的机制就可以帮我们把之前的主语给忘掉。LSTM是普通循环神经网络的扩展,它把中间的RNN的单元给扩展了。对于一个多层网络上,它相当于是在每一层网络上都做了一个子结构的细分。这个子结构的细分就是引入了选择性的机制,这个机制的实现
选择性-> 门,Sigmoid函数[0,1],这个门的计算相当于从某个地方传过来一个值,这个值是0到1之间的一个数,因为是0到1的一个数,我们用σ函数去做最后的变换,0到1之间的就是它需要记住或者是需要遗忘的成分,比如说一个数是10,经过这个门之后,可能门里面的数是0,10*0,就需要把这个数给忘掉。如果门里面的数是1,10*1,就需要把这个数给记住。门里面的数是0.5,10*0.5,就只需要把这个数记住50%。这个门是用来实现选择性机制的。
LSTM模型结构Overview
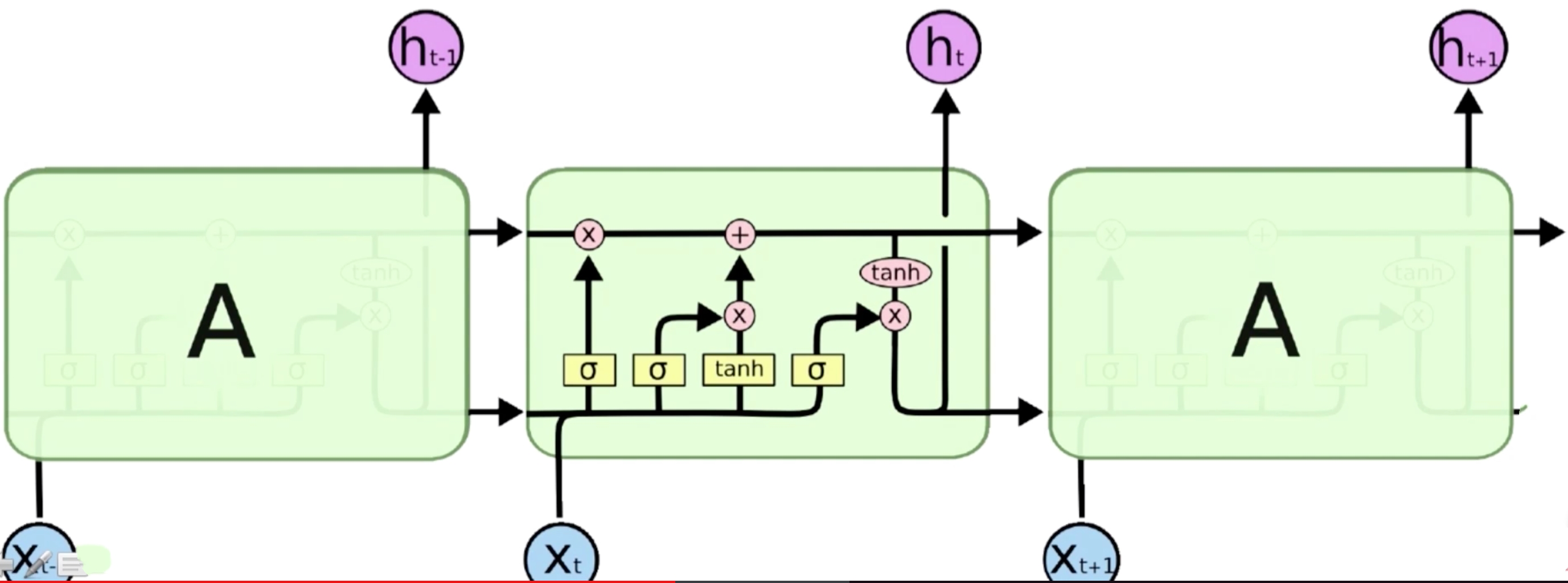
从上图可以看到,LSTM总体结构和RNN是一样的,下面的X都是输入,A是普通的RNN,我们把A变成LSTM的结构之后,它就是一个LSTM,LSTM也可以做多层网络,上下网络,残差网络,只不过是把中间的结构单元给替换掉了而已。我们可以看到在LSTM中有各种分支,它的输入会经过四个分支。一一去做处理。

- Cell的状态传递
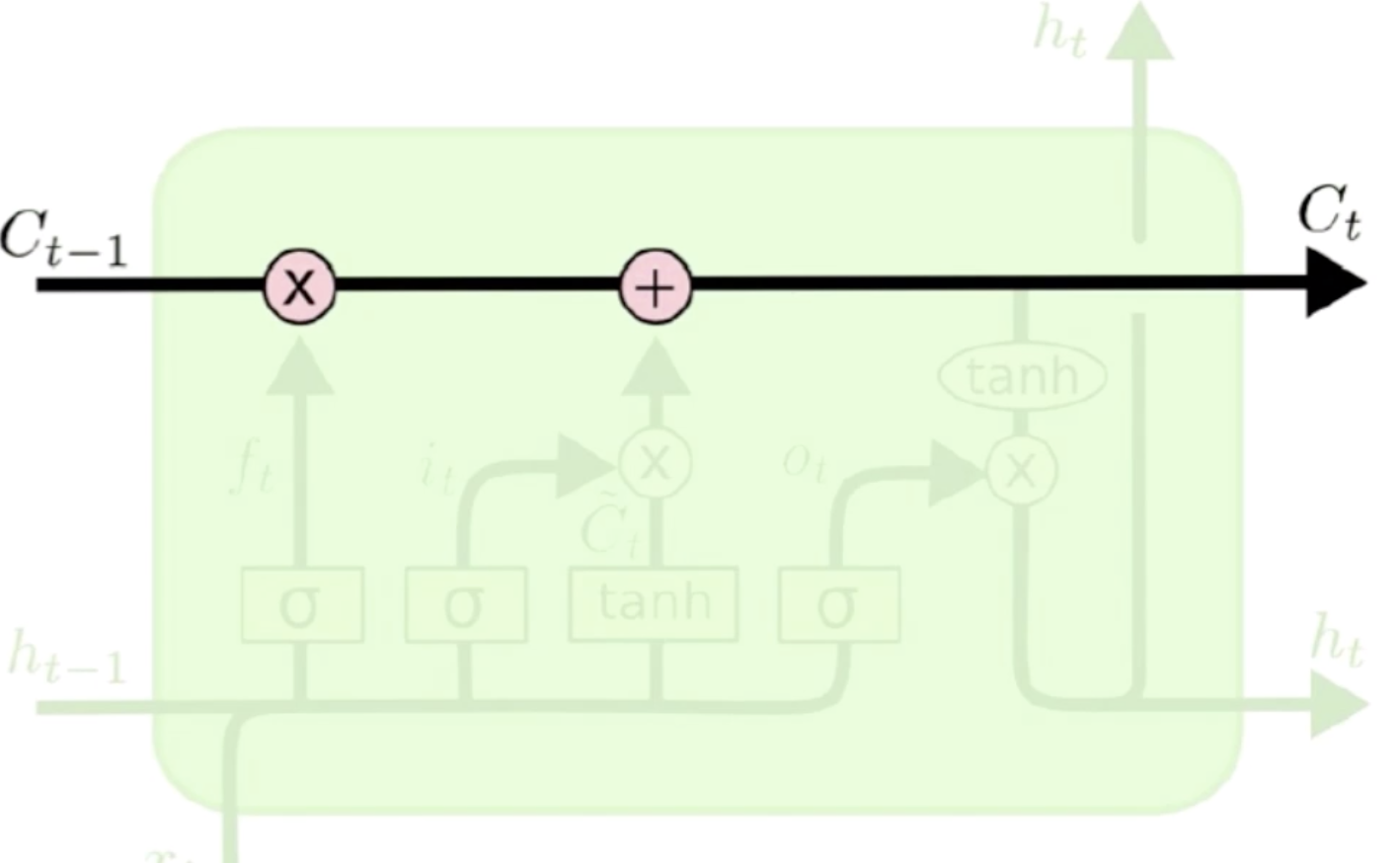
这是隐含状态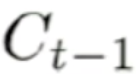 到
到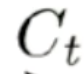 的一个过程,它经过LSTM的过程中需要做两个操作,第一个和某个东西去做点积,然后需要和网络神经去做加法。点积的作用是遗忘,加法就是和当前位置上的输入信息作一个合并。
的一个过程,它经过LSTM的过程中需要做两个操作,第一个和某个东西去做点积,然后需要和网络神经去做加法。点积的作用是遗忘,加法就是和当前位置上的输入信息作一个合并。
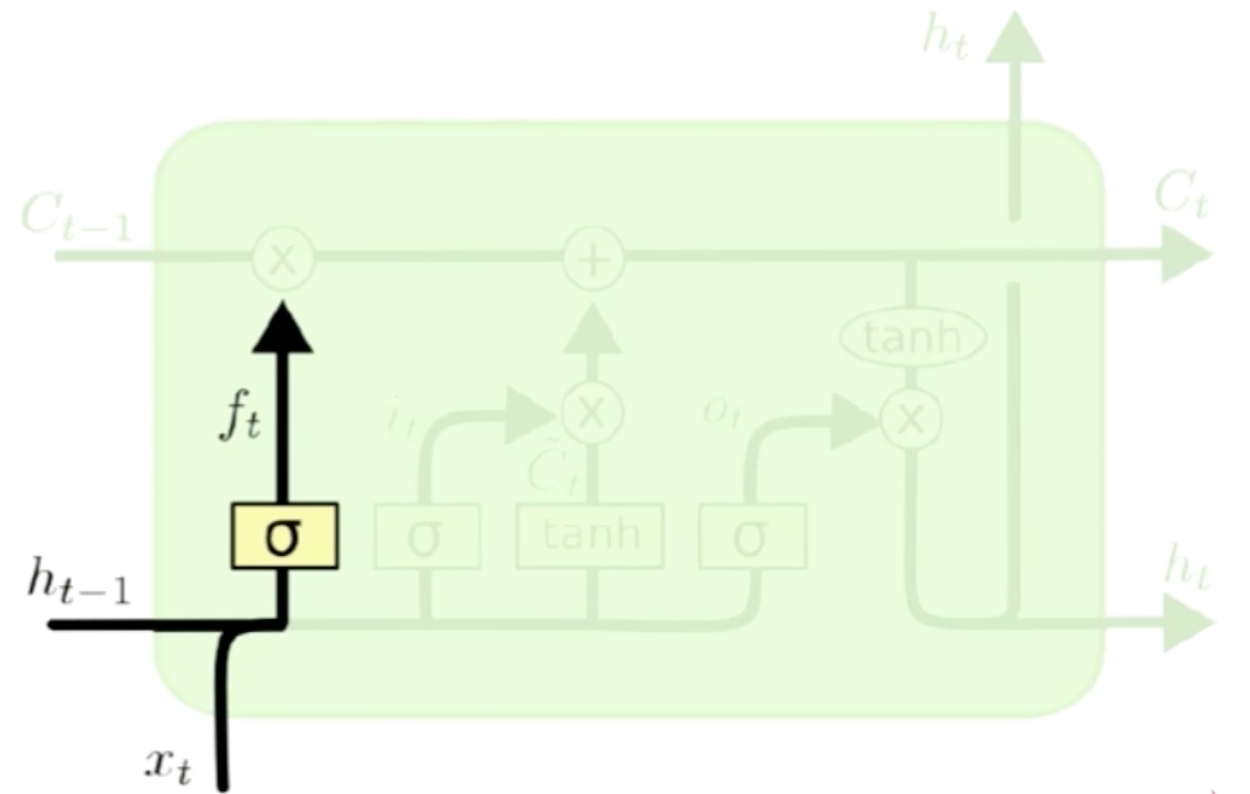
新的一句有新的主语,就应该把之前的主语忘掉。LSTM和普通的循环神经网络不一样的地方就在于它除了保存一个当前的隐含状态之外,它会把上一步的输出值 也会输入进来,上一步的输出值也就是当前输入的估计值和实际输入
也会输入进来,上一步的输出值也就是当前输入的估计值和实际输入 组成了当前值的信息。基于当前值的信息可以计算遗忘门的0-1之间的一个向量,然后这个向量就和隐含状态做点积,来让忘掉一些东西。
组成了当前值的信息。基于当前值的信息可以计算遗忘门的0-1之间的一个向量,然后这个向量就和隐含状态做点积,来让忘掉一些东西。
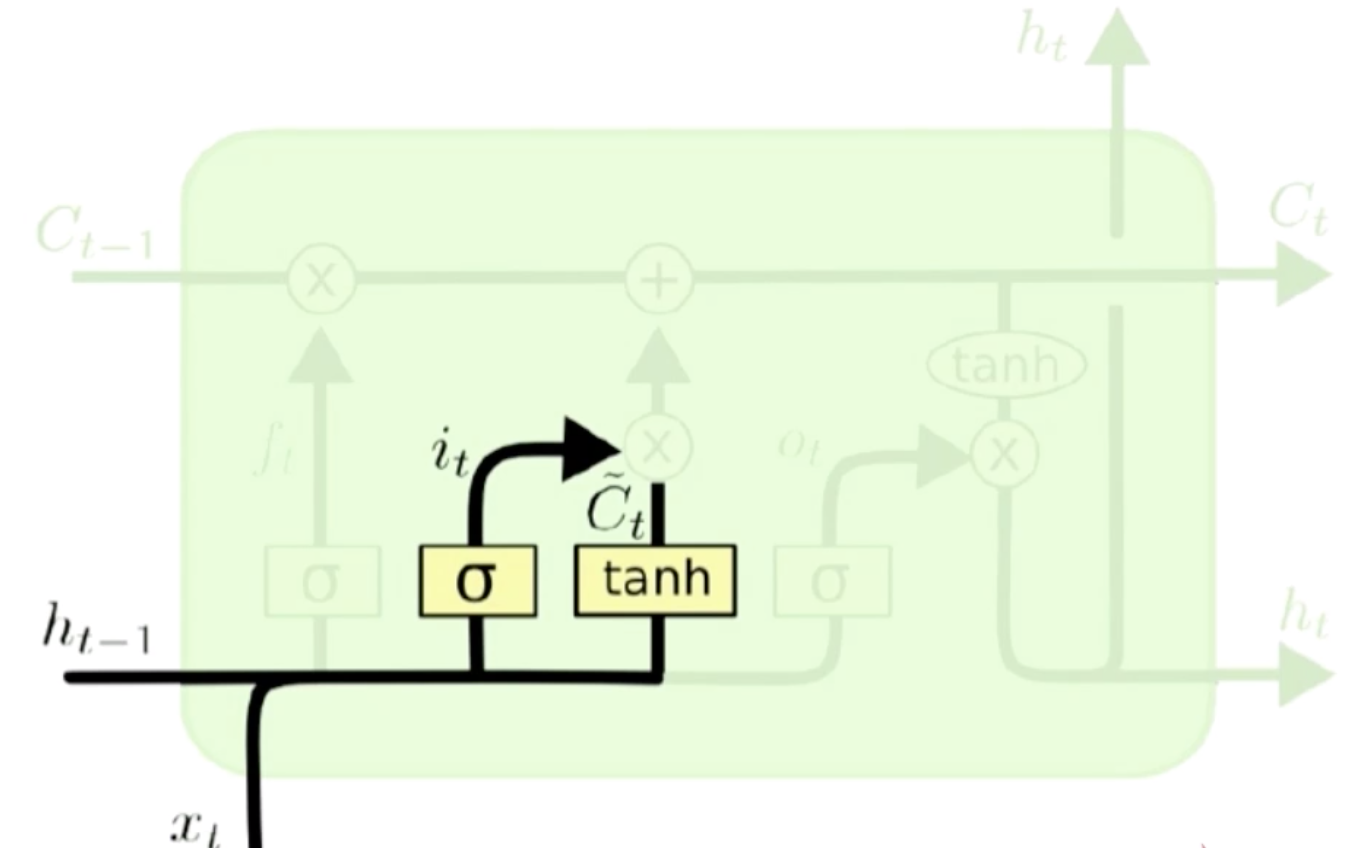
是不是要把主语的性别信息添加进来。传入门依然是基于和去计算的,计算出来遗忘门的门限之后,然后去做一个内积,因为这里是传入门,这个传入门的门限是要控制传入的信息,传入的信息仍然是和,这个输入的信息再去做tanh,这里其实就和普通循环神经网络是一样的,这里只不过把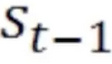 给换成了。计算出来的输出信息就是
给换成了。计算出来的输出信息就是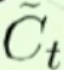 ,和输入门限
,和输入门限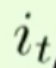 去做内积,就得到了这一次该输入什么。
去做内积,就得到了这一次该输入什么。
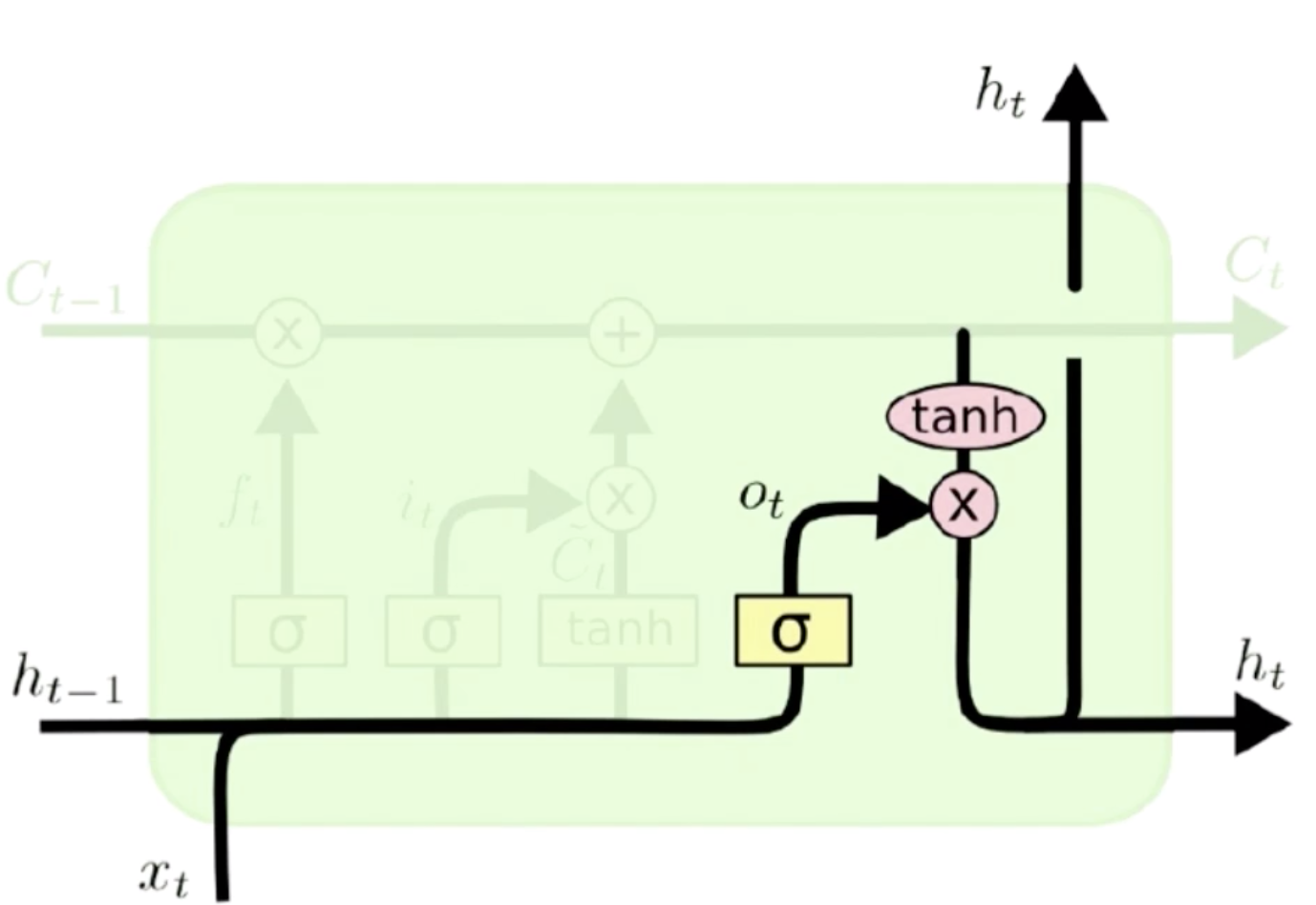
动词该用单数形式还是复数形式。输入门和经过遗忘门的状态做加法就形成了一个新的状态,这个新的状态再去和输出门去做一个内积。输出门同样依据当前的输入信息来计算的,计算完输出门之后和当前状态去做内积,就得到了一个当前的输出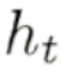 ,这样当前的输出就可以再次输出下一个状态了。
,这样当前的输出就可以再次输出下一个状态了。

经过遗忘门的上一状态,得到了遗忘后的信息,再经过传入门的输入状态,就得到了当前状态值。
现在我们把之前的代码改写成LSTM的
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers, optimizers
if __name__ == "__main__":
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batchsz = 128
# 常见单词数量
total_words = 10000
max_review_len = 80
embedding_len = 100
(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# 将每个句子的单词数限制为80
X_train = keras.preprocessing.sequence.pad_sequences(X_train, maxlen=max_review_len)
X_test = keras.preprocessing.sequence.pad_sequences(X_test, maxlen=max_review_len)
# 构建tensorflow数据集
db_train = tf.data.Dataset.from_tensor_slices((X_train, y_train))
# 将训练数据集乱序后取批次,每批128长度,并丢弃最后一个批次
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((X_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print(X_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print(X_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# RNN的初始状态,对于LSTM来说要传入两个状态
self.state0 = [tf.zeros([batchsz, units]), tf.zeros([batchsz, units])]
self.state1 = [tf.zeros([batchsz, units]), tf.zeros([batchsz, units])]
# 将文本的单词转化为100维向量,[b, 80] -> [b, 80, 100]
# 这里表示每个句子有80个单词,每个单词用100维向量表示
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# 建立一个序列式传递单元,传递序列数为units
# 它的最终输出是一个统计结果[b, 80, 100] -> [b, 64]
# self.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.5)
# self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.5)
self.rnn_cell0 = layers.LSTMCell(units, dropout=0.5)
self.rnn_cell1 = layers.LSTMCell(units, dropout=0.5)
# 建立一个全连接层,输出维度为1
self.fc = layers.Dense(1)
def call(self, inputs, training=None):
'''
:param inputs: 文本输入[b, 80]
:param training: 判断是训练模式还是测试模式
:return:
'''
X = inputs
X = self.embedding(X)
state0 = self.state0
state1 = self.state1
# 遍历句子中的每一个单词向量
for word in tf.unstack(X, axis=1):
# 计算tanh(Ws+Ux),这里state1是新状态,out=state1,但是out不做更新
out0, state0 = self.rnn_cell0(word, state0, training)
out1, state1 = self.rnn_cell1(out0, state1, training)
# out:[b, 64]
X = self.fc(out1)
prob = tf.sigmoid(X)
return prob
def main():
units = 64
epochs = 4
model = MyRNN(units)
# 创建一个梯度下降优化器
optimizer = optimizers.Adam(learning_rate=1e-3)
# 二分类损失函数
loss = tf.losses.BinaryCrossentropy()
model.compile(optimizer=optimizer, loss=loss,
metrics=['accuracy'], experimental_run_tf_function=False)
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
main()
(25000, 80) tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
(25000, 80)
Epoch 1/4
195/195 [==============================] - 124s 636ms/step - loss: 0.4788 - accuracy: 0.6687 - val_loss: 0.3647 - val_accuracy: 0.8374
Epoch 2/4
195/195 [==============================] - 84s 432ms/step - loss: 0.3124 - accuracy: 0.8593 - val_loss: 0.3598 - val_accuracy: 0.8414
Epoch 3/4
195/195 [==============================] - 100s 513ms/step - loss: 0.2564 - accuracy: 0.8930 - val_loss: 0.3966 - val_accuracy: 0.8359
Epoch 4/4
195/195 [==============================] - 92s 474ms/step - loss: 0.2205 - accuracy: 0.9141 - val_loss: 0.4069 - val_accuracy: 0.8329
195/195 [==============================] - 30s 155ms/step - loss: 0.4069 - accuracy: 0.8329当然我们也可以直接使用tensorflow2的层堆叠模型来简化上面的代码
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers, optimizers, Sequential
from tensorflow.keras.datasets import imdb
if __name__ == "__main__":
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batchsz = 128
# 常见单词数量
total_words = 10000
max_review_len = 80
embedding_len = 100
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=total_words)
# 将每个句子的单词数限制为80
X_train = keras.preprocessing.sequence.pad_sequences(X_train, maxlen=max_review_len)
X_test = keras.preprocessing.sequence.pad_sequences(X_test, maxlen=max_review_len)
# 构建tensorflow数据集
db_train = tf.data.Dataset.from_tensor_slices((X_train, y_train))
# 将训练数据集乱序后取批次,每批128长度,并丢弃最后一个批次
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((X_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print(X_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print(X_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# 建立一个序列式传递单元,传递序列数为units
# 它的最终输出是一个统计结果[b, 80, 100] -> [b, 64]
self.rnn = Sequential([
# 将文本的单词转化为100维向量,[b, 80] -> [b, 80, 100]
# 这里表示每个句子有80个单词,每个单词用100维向量表示
layers.Embedding(total_words, embedding_len,
input_length=max_review_len),
# layers.SimpleRNN(units, dropout=0.5, return_sequences=True, unroll=True),
# layers.SimpleRNN(units, dropout=0.5, unroll=True),
layers.LSTM(units, dropout=0.5, return_sequences=True, unroll=True),
layers.LSTM(units, dropout=0.5, unroll=True),
layers.Dense(1, activation=tf.nn.sigmoid)
])
def call(self, inputs, training=None):
'''
:param inputs: 文本输入[b, 80]
:param training: 判断是训练模式还是测试模式
:return:
'''
X = inputs
prob = self.rnn(X)
return prob
def main():
units = 64
epochs = 4
model = MyRNN(units)
# 创建一个梯度下降优化器
optimizer = optimizers.Adam(learning_rate=1e-3)
# 二分类损失函数
loss = tf.losses.BinaryCrossentropy()
model.compile(optimizer=optimizer, loss=loss,
metrics=['accuracy'], experimental_run_tf_function=False)
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
main()
(25000, 80) tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
(25000, 80)
Epoch 1/4
195/195 [==============================] - 199s 1s/step - loss: 0.4783 - accuracy: 0.6699 - val_loss: 0.3610 - val_accuracy: 0.8401
Epoch 2/4
195/195 [==============================] - 160s 821ms/step - loss: 0.3112 - accuracy: 0.8628 - val_loss: 0.3573 - val_accuracy: 0.8409
Epoch 3/4
195/195 [==============================] - 151s 774ms/step - loss: 0.2573 - accuracy: 0.8937 - val_loss: 0.4018 - val_accuracy: 0.8354
Epoch 4/4
195/195 [==============================] - 155s 795ms/step - loss: 0.2170 - accuracy: 0.9132 - val_loss: 0.4156 - val_accuracy: 0.8312
195/195 [==============================] - 54s 275ms/step - loss: 0.4156 - accuracy: 0.8312基于LSTM的文本分类模型(TextRNN与HAN)
文本分类
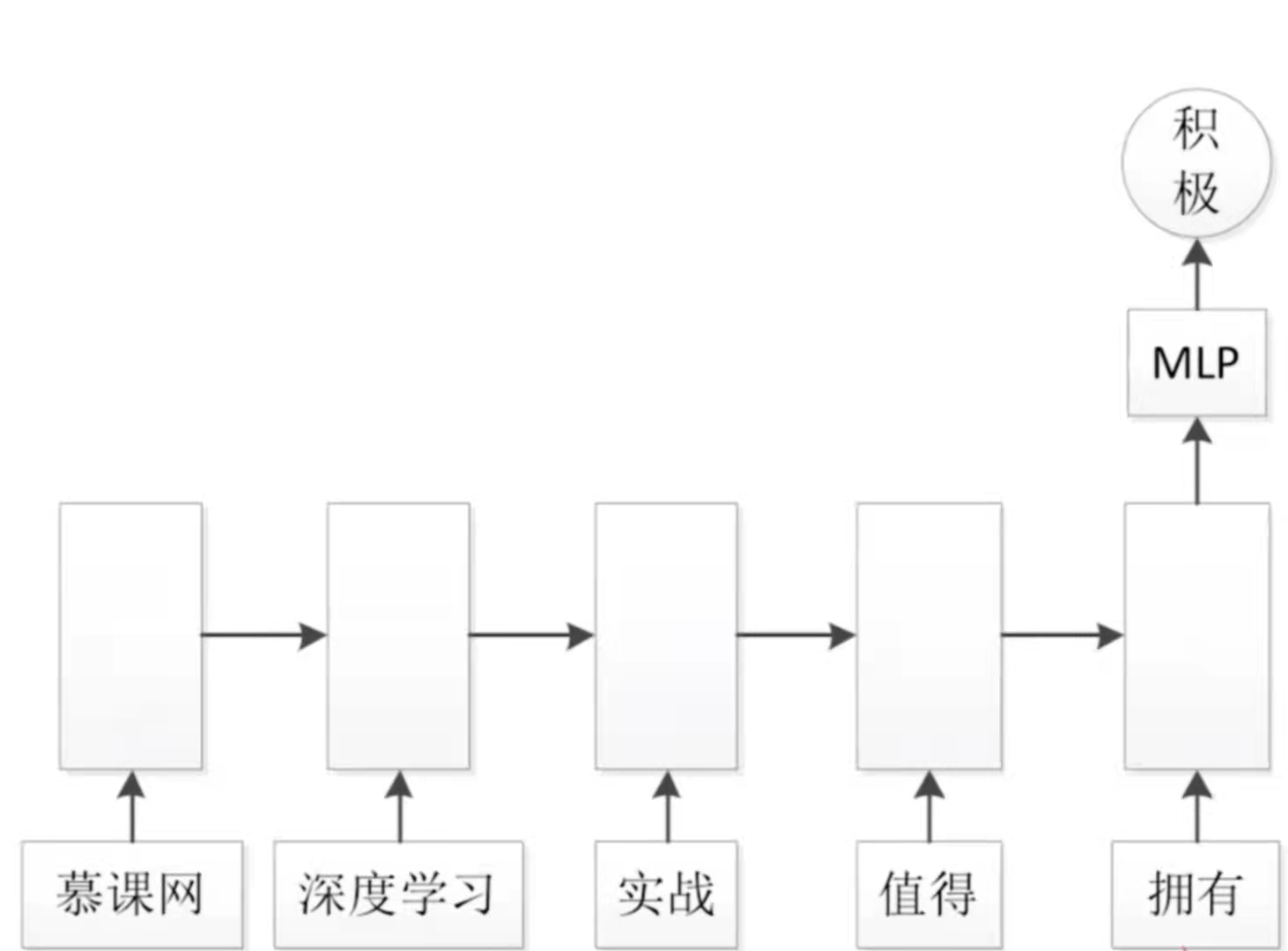
文本分类的意思就是说,我有很多的文本,我需要让网络去识别这些文本是什么类别。比如说一些互联网公司需要做一些舆情监测,邮件内容检测,商品评论分析等等。这是NLP领域处理的比较常用的问题。如上图所示,我们在这里使用一个循环神经网络,这个循环神经网络可以是一个普通的循环神经网络,也可以是一个LSTM网络,我们要输入的文本是中文的,所以我们需要对其进行分词,对于每一个词,我们需要应用embedding的形式对其进行编码(有关embedding的内容可以参考https://www.jianshu.com/p/2a76b7d3126b),编码成一个向量,这个向量就可以输入到RNN中去。当把句子输入完之后,在最后一个词之后,拿到最后一个词的输出,这个输出拥有了这个句子的所有信息,因为这是一个循环神经网络,它的每一个词的状态都会向下传递,一直传到最后的一个状态包含了整个句子的信息。然后再输出一个向量,再通过MLP(全连接层)得到一个分类,比如说是一个二分类,这个句子本身是一个评价,那么这个评价会有好和坏之分,或者是积极的和消极的之分。使用σ函数得到一个概率;如果是多分类,就使用softmax函数。这样就使用了一个RNN或者是LSTM去进行文本分类最基本的模型。
输入embedding
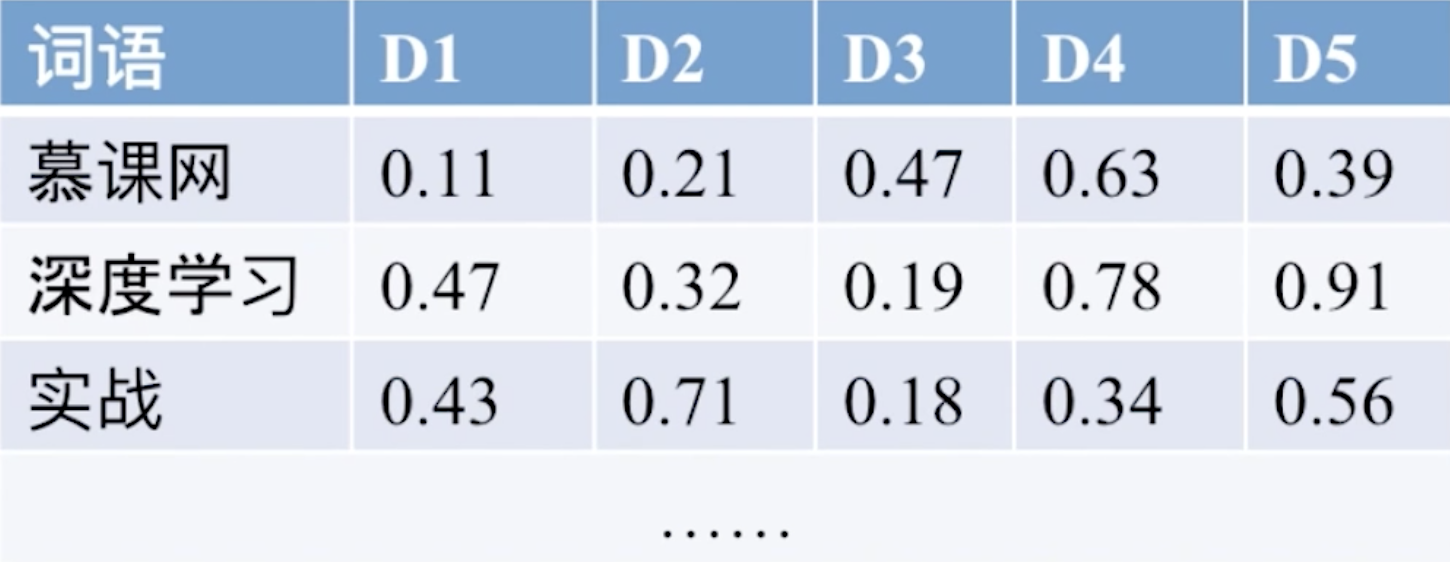
在深度学习领域,我们都使用embedding的形式对词语进行编码,在上图中,我们对每一个词去做一个长度为5的编码,也就是说把每一个词变成一个长度为5的向量,在这个向量中5个值都是一个浮点数,这个embedding都是一个变量,我们在循环神经网络去学习的过程中,这个embedding是要随着梯度下降去调整的,从而可以使得embedding的意思跟词更相关,从而才能得到一个正确的结果。所以在这里embedding是可训练的。经过RNN训练之后再输出全连接层。
双向LSTM解决信息瓶颈
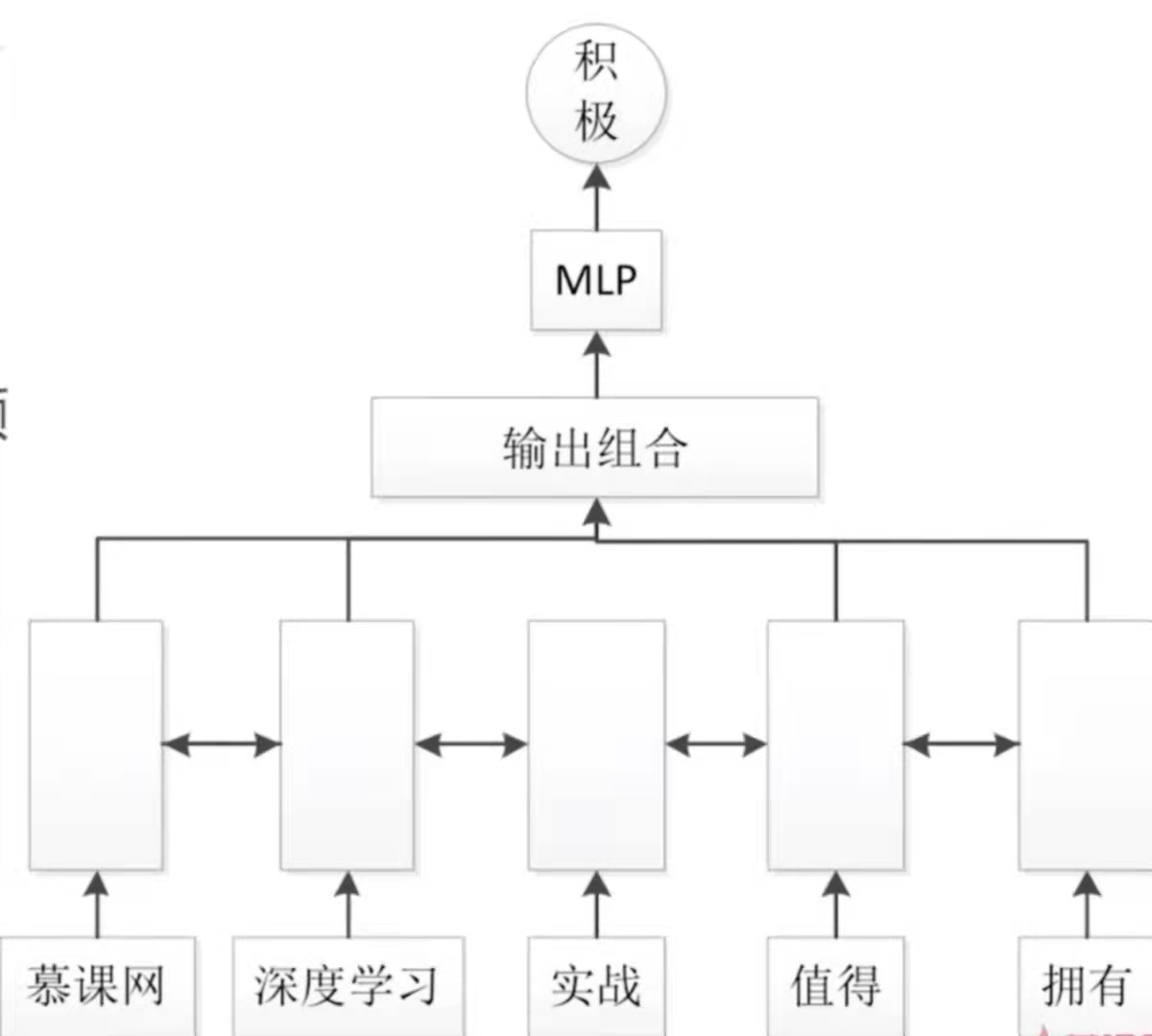
在文本分类的问题中,会遇到什么样的问题呢,答案就是信息瓶颈。在文本分类模型中,我们是使用最后一个输入的输出去输入到MLP中去,然后去进行分类。这样最后一个输出就包含了之前的所有的输入的信息。对于一个LSTM来说,虽然它能够有选择去保存信息,但是依然不可避免的会遇到一个问题,这个问题就是最后一个输出肯定是会跟最后一个输入或者是最后几个输入有更大的关系。而跟较远的输入的关联性会比较弱。这样就会形成一个瓶颈,就是说离最后一个输入比较远的这些输入的信息可能不会被保存下来,就会遇到了瓶颈。而解决的方法就是双向LSTM就可以解决信息瓶颈。
首先将序列的每一步由单向变成双向,然后每一步都会有一个输出,这个输出,我们会将它组合起来。在这里跟之前的模型有一个重大的不同之处就是把每一步的输出都进行了组合。组合的方法有3个
- 平均(Averge pooling)
- 最大化(max pooling)
在输出组合之后再输出到MLP中去进行分类的计算。
这里我们把之前的代码改成双向RNN
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers, optimizers, Sequential
from tensorflow.keras.datasets import imdb
if __name__ == "__main__":
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batchsz = 128
# 常见单词数量
total_words = 10000
max_review_len = 80
embedding_len = 100
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=total_words)
# 将每个句子的单词数限制为80
X_train = keras.preprocessing.sequence.pad_sequences(X_train, maxlen=max_review_len)
X_test = keras.preprocessing.sequence.pad_sequences(X_test, maxlen=max_review_len)
# 构建tensorflow数据集
db_train = tf.data.Dataset.from_tensor_slices((X_train, y_train))
# 将训练数据集乱序后取批次,每批128长度,并丢弃最后一个批次
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((X_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print(X_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print(X_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# 将文本的单词转化为100维向量,[b, 80] -> [b, 80, 100]
# 建立一个序列式传递单元,传递序列数为units
# 它的最终输出是一个统计结果[b, 80, 100] -> [b, 64]
self.rnn = Sequential([
layers.Embedding(total_words, embedding_len,
input_length=max_review_len),
# 双向RNN
layers.Bidirectional(layers.SimpleRNN(units, dropout=0.5, return_sequences=True, unroll=True)),
layers.Bidirectional(layers.SimpleRNN(units, dropout=0.5, unroll=True)),
layers.Dense(1, activation=tf.nn.sigmoid)
])
def call(self, inputs, training=None):
'''
:param inputs: 文本输入[b, 80]
:param training: 判断是训练模式还是测试模式
:return:
'''
X = inputs
# X = self.embedding(X)
prob = self.rnn(X)
return prob
def main():
units = 64
epochs = 4
model = MyRNN(units)
# 创建一个梯度下降优化器
optimizer = optimizers.Adam(learning_rate=1e-3)
# 二分类损失函数
loss = tf.losses.BinaryCrossentropy()
model.compile(optimizer=optimizer, loss=loss,
metrics=['accuracy'], experimental_run_tf_function=False)
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
main()
(25000, 80) tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
(25000, 80)
Epoch 1/4
195/195 [==============================] - 117s 598ms/step - loss: 0.5471 - accuracy: 0.6137 - val_loss: 0.3865 - val_accuracy: 0.8304
Epoch 2/4
195/195 [==============================] - 77s 396ms/step - loss: 0.3628 - accuracy: 0.8344 - val_loss: 0.3811 - val_accuracy: 0.8368
Epoch 3/4
195/195 [==============================] - 77s 395ms/step - loss: 0.2866 - accuracy: 0.8782 - val_loss: 0.4676 - val_accuracy: 0.8261
Epoch 4/4
195/195 [==============================] - 76s 389ms/step - loss: 0.2284 - accuracy: 0.9093 - val_loss: 0.4855 - val_accuracy: 0.8315
195/195 [==============================] - 27s 140ms/step - loss: 0.4855 - accuracy: 0.8315双向LSTM
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers, optimizers, Sequential
from tensorflow.keras.datasets import imdb
if __name__ == "__main__":
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batchsz = 128
# 常见单词数量
total_words = 10000
max_review_len = 80
embedding_len = 100
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=total_words)
# 将每个句子的单词数限制为80
X_train = keras.preprocessing.sequence.pad_sequences(X_train, maxlen=max_review_len)
X_test = keras.preprocessing.sequence.pad_sequences(X_test, maxlen=max_review_len)
# 构建tensorflow数据集
db_train = tf.data.Dataset.from_tensor_slices((X_train, y_train))
# 将训练数据集乱序后取批次,每批128长度,并丢弃最后一个批次
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((X_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print(X_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print(X_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# 它的最终输出是一个统计结果[b, 80, 100] -> [b, 64]
self.rnn = Sequential([
# 将文本的单词转化为100维向量,[b, 80] -> [b, 80, 100]
# 建立一个序列式传递单元,传递序列数为units
layers.Embedding(total_words, embedding_len,
input_length=max_review_len),
# 双向LSTM
layers.Bidirectional(layers.LSTM(units, dropout=0.5, return_sequences=True, unroll=True)),
layers.Bidirectional(layers.LSTM(units, dropout=0.5, unroll=True)),
layers.Dense(1, activation=tf.nn.sigmoid)
])
def call(self, inputs, training=None):
'''
:param inputs: 文本输入[b, 80]
:param training: 判断是训练模式还是测试模式
:return:
'''
X = inputs
prob = self.rnn(X)
return prob
def main():
units = 64
epochs = 4
model = MyRNN(units)
# 创建一个梯度下降优化器
optimizer = optimizers.Adam(learning_rate=1e-3)
# 二分类损失函数
loss = tf.losses.BinaryCrossentropy()
model.compile(optimizer=optimizer, loss=loss,
metrics=['accuracy'], experimental_run_tf_function=False)
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
main()
(25000, 80) tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)
(25000, 80)
Epoch 1/4
195/195 [==============================] - 280s 1s/step - loss: 0.4591 - accuracy: 0.6800 - val_loss: 0.3522 - val_accuracy: 0.8419
Epoch 2/4
195/195 [==============================] - 189s 969ms/step - loss: 0.2965 - accuracy: 0.8705 - val_loss: 0.3633 - val_accuracy: 0.8382
Epoch 3/4
195/195 [==============================] - 185s 948ms/step - loss: 0.2402 - accuracy: 0.9014 - val_loss: 0.4053 - val_accuracy: 0.8361
Epoch 4/4
195/195 [==============================] - 178s 913ms/step - loss: 0.1962 - accuracy: 0.9216 - val_loss: 0.4309 - val_accuracy: 0.8224
195/195 [==============================] - 57s 292ms/step - loss: 0.4309 - accuracy: 0.8224HAN文本分类
HAN文本分类的全称为Hierarchy attention network
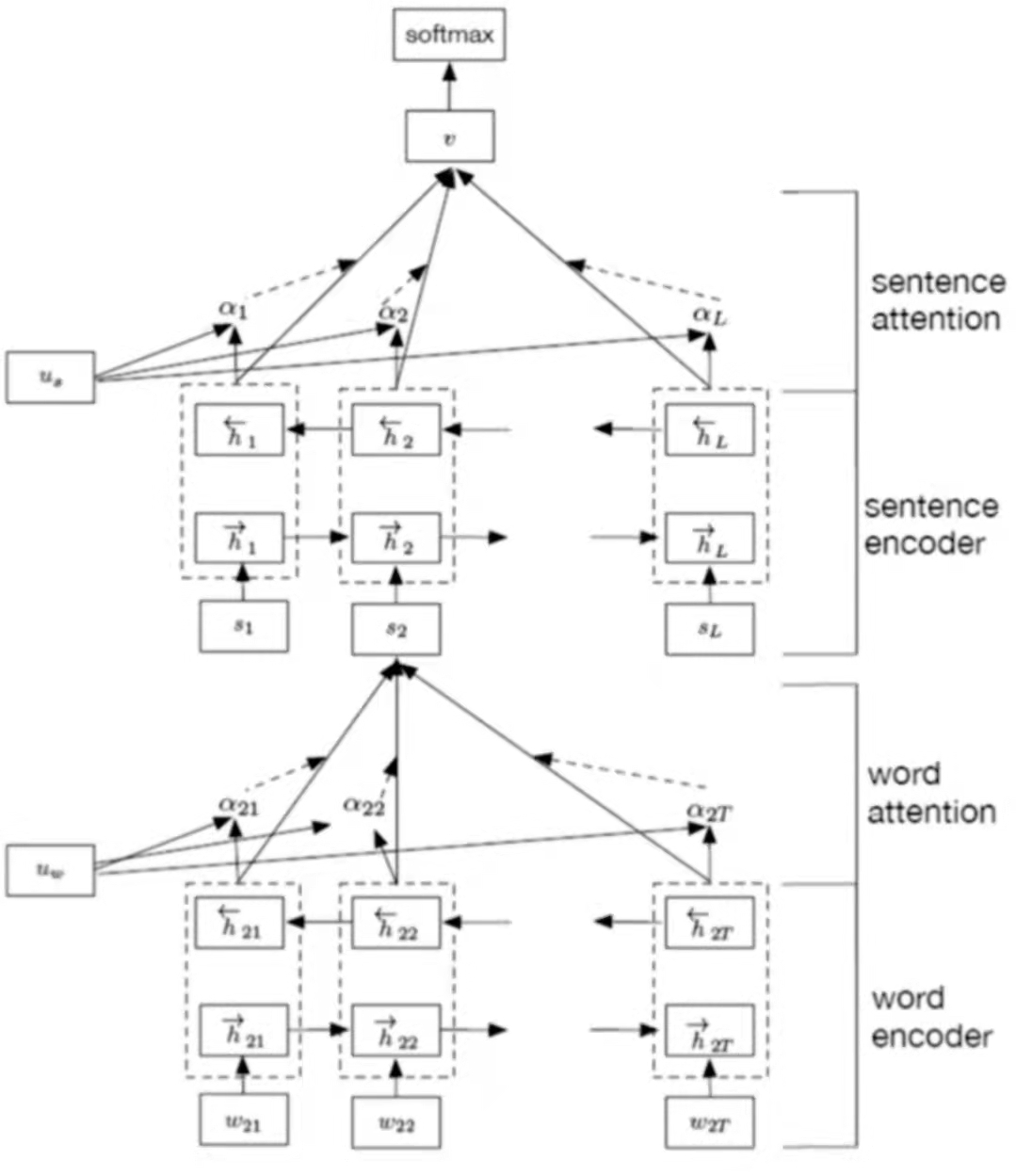
这种分类方式更符合人类的习惯,我们在读一篇文章,通常会划重点句子。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK