

Troubleshooting Apache Spark Applications with OverOps
source link: https://www.overops.com/blog/troubleshooting-apache-spark-applications-with-overops/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Troubleshooting Apache Spark Applications with OverOps
6 min read
Chris Caspanello, avid Spark developer, demonstrates how you can use OverOps to find errors on your Spark application. As Chris states, “configuration issues, format issues, data issues, and outdated code can all wreak havoc on a Spark job. In addition, operational challenges be it size of cluster or access make it hard to debug production issues. OverOps’ ability to detect precisely why something broke and to see variable state is invaluable in a distributed compute environment. It makes detecting and resolving critical exceptions quick and easy.”
If you are a Spark developer and have encountered the above or similar issues, OverOps can be a game changer. Try OverOps free for 14 days now.
GitHub Files: https://github.com/ccaspanello/overops-spark-blog
Data path not configured property
When developing transformations, most customers would use HDFS to read files from. This would be a URL like `hdfs://mycluster/path/to/data`. However, some customers would reference files local to the nodes and would use a URL like `file://path/to/data`. Unfortunately this is incorrect. The format for a URL is [schema]://[host]/[path]. If you drop the host, you will need `file:///path/to/data` with 3 forward slashes. When the Spark job is submitted to the cluster, the job will die a horrible death with little to no indication of what happened. This was fixed with upfront path validation, but finding the root cause was not easy and very time consuming (more on that later). If I only had OverOps, I could quickly and easily understand why it broke. I could look at the continuous reliability console and see where the error occurred and what the error is, along with the variable state coming into the function.
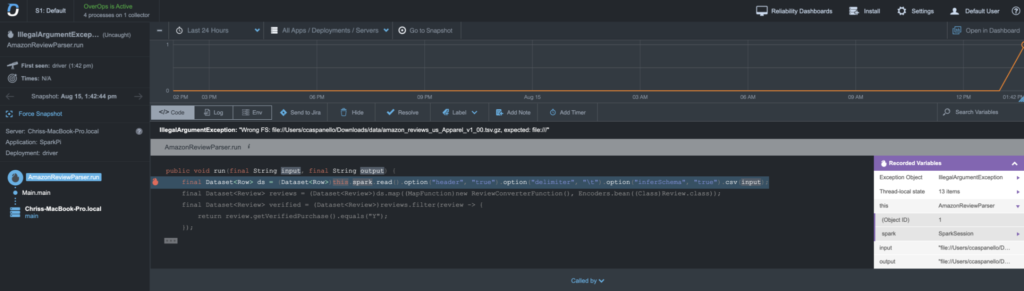
The Spark UI is great . . . when it is running
In the previous example I mentioned that finding the root cause of a Spark job failure is not easy and time-consuming. The reason for this has to do with how the Spark UI works. The Spark UI consists of many parts: Master, Worker, and Job screens. The Master and Worker screens are up for the entire time and contain details on stats of each service. While the Spark job is running, the Job screens are available and look like this:
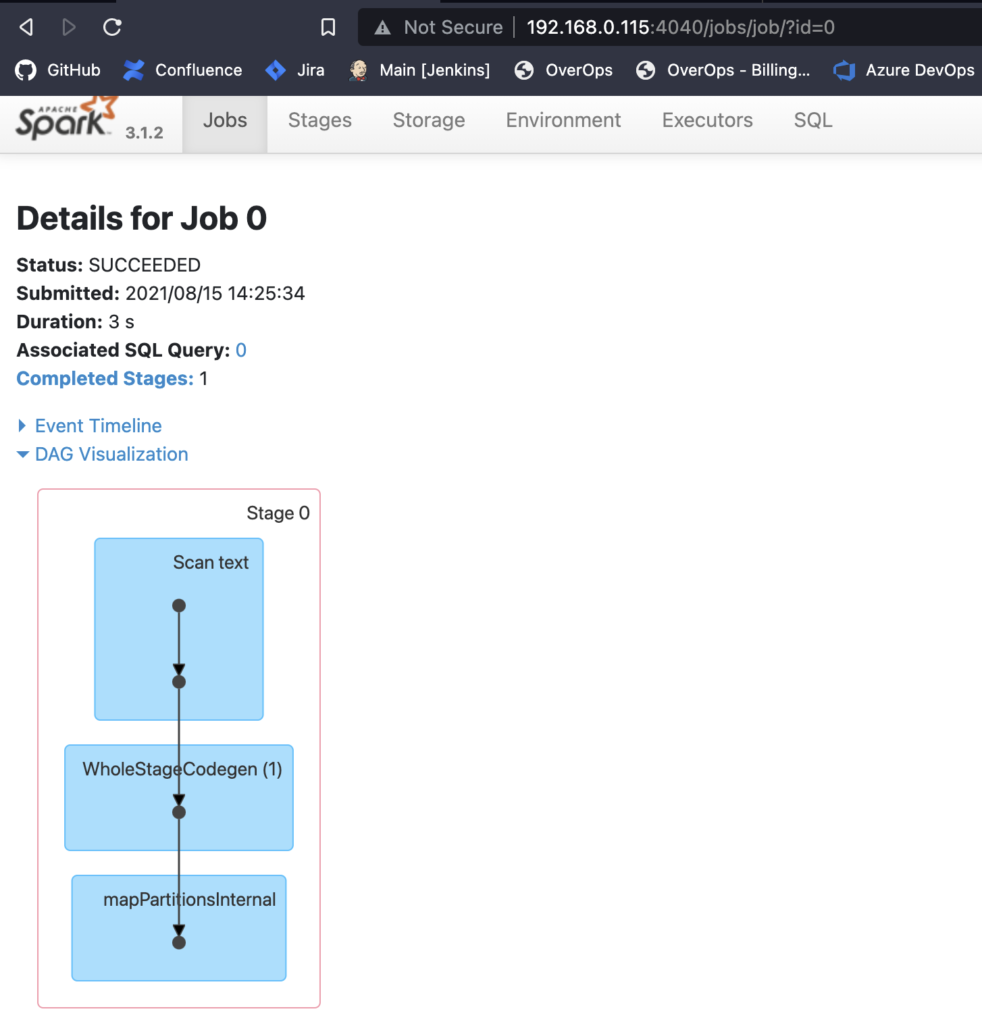
Here you can see what stages are being run and get logs for running / failed stages. These logs can be useful for finding failures. Unfortunately, when the Job finishes or fails, the service dies and you can no longer access the logs through the web UI. Since OverOps detected the event, I was able to see it there along with the entire variable state.
Missing headers on some files
In this example, I wrote a Spark application and tested it locally on a sample file. Everything worked fine. However, I then ran the job in my cluster against a real dataset and it failed with the following error:
IllegalArgumentException: ‘marketplace does not exist. Available: US, 16132861, . . .’
As you can see, the exception had row data which is good. But that alone is not enough to let us know what was going on. Since OverOps captures variable state at the time the exception happens, I was able to see that the schema was essentially empty. The root cause was because I did not have a header row for every part file.
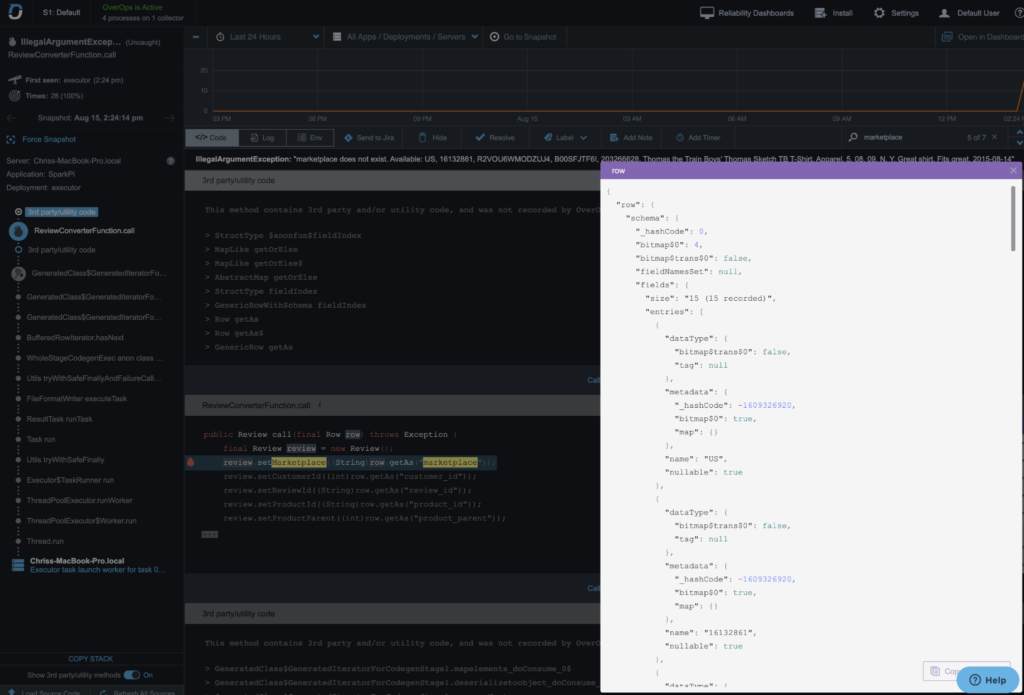
Invalid Delimiter
In this example, there is an error similar to the one above.
IllegalArgumentException: “id does not exist. Available: id,first_name,last_name,email,gender,ip_address”
But in this case I did have a column header on my files. What’s going on then? Looking at the variable state in OverOps, I can see that my schema has one column named:
id,first_name,last_name,email,gender,ip_address. This tells me that my delimiter is bad.

Scaling up with unknown data
Oftentimes big data developers will test on a small subset of data .limit(200) . But what happens when unexpected data comes into the system? Do you crash the application? Or do you swallow the error and move on? That is always a hot topic, but either way OverOps can find the exact place where the data could not be parsed.
In this example the original application was coded to accept a Gender of MALE/FEMALE. Now a new valid gender value is seen. In our scenario, we should update our application to include POLYGENDER as well.

Operational Challenges
Aside from coding issues there are also operational challenges:
- On large Spark clusters with 100s of nodes, finding the right work in order to find the right log is a very tough task. This is where a Spark History server is useful, but sometimes cluster admins lock this down and the developer may not even have permission.
- OverOps gives us a central place to go for any errors that occur.
- Running a job on massive datasets may take hours (hence why sometimes records are ignored or redirected).
- OverOps can detect anomalies as they occur so we could kill our job sooner and adjust code.
- This can be a double cost saving measure: reduced developer time and reduced cloud resources spent running a bad job.
- Sometimes Logs are turned off to increase speed / conserve resources
- Even if logs are turned off in the application, log events and exceptions can still be captured
Summary
As you can see, there are configuration issues, format issues, data issues, and outdated code that can all wreak havoc on a Spark job. In addition, operational challenges be it size of cluster or access make it hard to debug production issues. OverOps ability to detect precisely why something broke and to see variable state is invaluable in a distributed compute environment. It makes detecting and resolving critical exceptions quick and easy. So if you are a Spark developer and have encountered the above or similar issues, you might want to give OverOps a try.
Try OverOps with a 14-Day Free Trial
So if you are a Spark developer and have encountered the above or similar issues, you might want to give OverOps a try. Get started for free now.
Recommend
-
115
Almost every Java application uses some native (off-heap) memory. For most apps, this amount is relatively modest. However, in some situations, you may discover that your app's RSS (total memory used by the process) is mu...
-
63
Realtime predictions with Apache Spark/Pyspark and Python There are many blogs that talk about Apache spark and how scalable it is to build Machine Learning models using Big data. But, there are few blogs that...
-
66
Editor’s Note: Alastair Green (Neo4j Query Languages Lead) and Martin Junghanns (Neo4j Cypher for Apache Spark project) will be
-
27
What is Apache Spark? Apache Spark is an in-memory distributed data processing engine that is used for processing and analytics of large data-sets. Spark presents a simpl...
-
46
New deployment scores and release certification help QA, DevOps and SRE teams detect anomalies across versions in pre-production and production to proactively prevent Sev1 issues
-
40
Spark , The word itself is enough to generate a spark in every Hadoop engineer’s mind. A n in-memory processing tool
-
2
What does OverOps do? Daniel Bechtel ● 07th...
-
7
Summary Forge mods are a fun way to enhance your Minecraft playing experience. With OverOps, you can remove the headaches that can come with debugging on a Minecraft Server. So, if you are a Forge mod developer, you should give O...
-
8
Apache Hive 2.1 Installation with TroubleShooting Reading Time: 3 minutesApache Hive is considered the defacto stan...
-
6
Apache PDFBox is a popular open-source library that facilitates Java applications to work with PDF documents. Recently, we encountered a deadlock that surfaced in this library. In this post, we have shared how we troubleshooted and identifie...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK