

闯过八关,做一份出色的数据分析报告
source link: https://www.yunyingpai.com/data/702793.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

无论是运营还是产品经理们在面对数据分析报告的时候,常常手足无措,不知道如何下手。该怎么将自己所做的“好”直接地表达与呈现出来,让他人明白?作者分享了完成一份数据分析报告需要闯过的八关,我们一起来看看。

- 为什么运营要亲自写数据分析报告?
- 为什么产品经理抓着数据报告改来改去?
相当多的情况是:这帮人不是真想分析问题,而是变着法地证明自己做得好!而恰恰这一个“好”字,难倒了无数人。因为真想让数据分析师说一声“好”,至少得闯过八大关卡。
第一关:有个标准
在数据分析中,一个基本原则是:数字本身不表明好坏,数字+标准才表明好坏。举个简单的例子:运营开展一个拉新活动,通过活动页面注册了10000个用户。
这个10000用户并不能说明好坏,只有说:我们计划通过页面注册5000个,实际注册10000个,才能说明好坏。
这一步看似简单,可已经能难倒很多人了。比如:
- 运营做活动,提升哪个指标,从多少提升到多少,自己说不清楚,一张嘴就是:“反正就是提升呀,我看别人都这么做。”
- 产品做改版,改进方向、改进程度、影响指标通通不清楚,张嘴就是“老板让这么改,我就这么改咯。”
这种情况,事后再抓住数据分析问:“分析下到底好不好”,铁定分析不出来。
第二关:标准得事前定
听起来很搞笑,标准不都是事前定的吗?现实很残忍:相当多的人,事先不定目标,事后跑来:“通过人工智能大数据,先计算出最科学的,最合理的,最权威的,自然增长是多少,剩下的不就是我带来的了……”
然后你会发现,他们心目中最科学的,最合理的,最权威的自然增长率永远是负数,这样无论如何都能证明他们的工作成效显著,力挽狂澜。
第三关:标准事后不能改
听起来又很搞笑,标准改来改去还叫标准吗?现实又是很残忍的,相当多的人看到考核指标不涨,第一件想起来的事就是改标准,还美其名曰:“通过人工智能大数据,计算出标准定高了多少,给一个最科学的,最合理的,最权威的修正值……”
对这种情况就一个字回复:呸!
第四关:标准是可量化的
这个问题相对小众,因为大部分销售/运营/产品的指标都是可量化的。
但是还是有少部分喜欢浑水摸鱼的人,在2021年了,还把满意度/体验指数/NPS/ROS这些上世纪90年代的古董搬出来糊弄人。
这些基于外部的、调研的、小样本抽样的结果,根本无法解释某个活动/产品/功能对内部指标的影响。
因此碰到这种人,直接不予理会,要求其关联到一个可以采集完整数据的内部指标。
第五关:标准要分级别
这个问题相当普遍。原则上,通过业务行动,直接促成的结果,才能算结果。和业务行动没有关联的就不能算。
- 拉新活动,要考核的结果,应该是从活动页面的注册人数。
- 促销活动,要考核的结果,应该是促销商品的销售情况。
- 产品改版,要考核的结果,应该是哪个页面/流程改了,就考核这一个页面/流程。
BUT!很多人喜欢把非直接促成的也写进来。比如活动期间,业绩大盘整体都在涨,丫就写上“活动带动了大盘上涨”。比如页面改版了,产品整体活跃率提升,丫就写上“页面改版带动产品整体上涨”。
特别是在,这些人负责的活动/页面表现平平的时候,就尤其喜欢拿大盘上涨来说事。更讨厌的是,这些人在吹完牛逼以后会加一句:“请用人工智能大数据,精准分析出来,到底DAU涨了100万,有几万是我这个页面涨的……”
有没有一个活动,一次改版带动大盘的情况?有!就是类似双十一,这种全公司全力以赴的大活动,和全新改版这种大改版。普通的小型活动、局部改版根本扯不上什么“带动大盘”“交叉因素”“深远影响”。
因此考核标准要分级别。建议:
- 公司级大型活动,才会重点盯大盘
- 部门级,针对全体人的小型活动,关注活动自身小目标
- 部门级,针对部分人的精准活动,直接上参照组,做ABtest
这是解决事后扯皮的终极策略。
注意:闯过了前五关,我们就得到了一个有节操的考核标准,只要有个考核标准,那么我们就能得出一个“很好”的结论,开头提的问题已经解决了80%。
但是这个结论,仍然可能被人推翻,他们会说:“这是应试教育的结果,其实结果没那么好!”想要顶住这种攻击,还得再过三关。
第六关:结果要稳定
所谓稳定,指的是考核结果要稳定地表现为“好”。举个简单的例子,做一个促活的活动,理论上,最好的结果是下图1所示,上线后,活跃率稳定的高。下图2、3、4,都是所谓的“不稳定”场景。
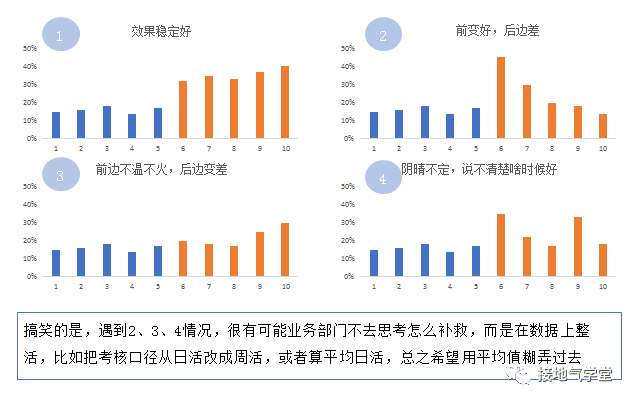
不然的话,人们很容易攻击:
- 这不是做得好,而是运气好
- 这不是做得好,是自然波动
- 这不是做得好,是昙花一现
- 这不是做得好,水涨船高而已
需注意的是,这种指标稳定,主要靠的是业务干出来的!遇到不稳定情况,不去思考业务上怎么补救,光让数据分析:“你再深入分析分析”,可是稳定不了指标的哦。
第七关:结果要对得起投入
- 有可能考核标准没有面面俱到,没涉及成本。
- 有可能业务行动是尝鲜性质,没有考虑成本。
- 有可能短期内并不缺钱,没有在意成本。
但人们总会在某个时间点,想起来还有成本,还有投入产出。这时候就会:翻旧账,把之前“做得好”的结论推翻。
- 这不是做得好,这就是烧钱打激素。
- 这不是做得好,这就是花钱买虚假繁荣。
- 这不是做得好,明明有更低成本法子可以用。
当人们翻旧账的时候,想再反抗已经来不及来了。
所以应对此问题最好的办法,就是事先不要抱侥幸心理,想着拆东墙补西墙,砸点钱把指标拉起来完事。而是真正站在解决问题角度,设计一些能逐步改进,能通过迭代提升效率的办法。
第八关:结果要对得起大盘
如果自己单点活动做得很好,但是大盘指标一直在下滑,到底算不算好?客观地讲,应该是算好的。但是越是高层领导,越不关心细节,越关心大盘走势。
所以你很难杜绝高管们这么思考:
- 大盘跌,这个小活动却在涨,说明它方向错了
- 大盘跌,这个小活动却在涨,是不是它带歪了整体节奏
- 大盘跌,这个小活动却在涨,是不是它分流了别人的效益
这是对效果考核的终极挑战了。因为本质上,这个问题问的是:到底做哪些策略组合,才能对大盘有用。策略组合里的几个子策略,会不会相互干扰。单纯站在一个项目的角度,很难扯清楚这些关联,只能交给诸如战略发展部这样的统筹部门,才能纵观全局说清楚。
从本质上看,说“做得好”很难,难在:
- 业务上,对待结果要有节操,不投机,不粉饰太平;
- 业务上,要有整体思考和部署,每个任务有明确定位和目标;
- 业务上,要在设计落地方案的时候多考虑一些可能性,找到真正驱动的因素
- 数据上,不要迷信“人工智能大数据”能取代以上1、2、3点工作
- 数据上,帮助业务业务理清1、2、3点,而不是认为自己掐指一算就尽在掌握
这样大家通力合作,才能真正把事情做好。最终好不好,从来都不是算出来的,而是努力做出来的,与大家共勉。
作者:【接地气的陈老师】
来源:微信公众号“接地气学堂(ID:gh_ff21afe83da7)”
本文由 @【接地气学堂】 原创发布于运营派,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
Recommend
-
105
珍贵的十一黄金周可谓转瞬即逝,而我们也不情愿的回归到了一如既往的繁忙学习工作之中。虽然过去八天价格大战的硝烟已经逐渐散去,但十一过后,市场也依然有不少机型值得我们重点关注。下面新浪手机就为大家介绍几款十一后最值得关注手机,希望能够对有购机计
-
85
我们在上个月已经见过了使用高通 Snapdragon 芯片的华硕、HP 笔记本,到了 CES 2018,Lenovo 的同类产品终于也正式登场了。上图中这款 12.3 吋的 Miix 630 就是他们新打造的「随时连网」(always connected)笔记本,初看好像跟 HP 的新品差别不大,但动手试过之后...
-
82
如何设计出一款出色的结账表单
-
76
介绍艺术领域中常用的的 4 项设计原则:一致 & 协调、平衡、相衬、重点突出,并把它们应用到 API 设计中。
-
52
对于互联网公司而言,程序员的重要性不言而喻,因为大部分互联网公司都是虚拟资产,比如各种各样的程序等,而这些都是程序员研发的成果,可谓牵一发而动全身。
-
42
一、前期准备: 在做任何一份竞品报告之前,都应当问明白自己三个问题: 这份报告为什么做? 这份报告为什么做即这份报告的目的,如果是竞品分析的话,那么分析竞品的目的是什么?是有一个问题点需要改善却想不到对策打算看看竞争对手怎么做的?还是为产品迭代过程...
-
7
导语:竞品分析几乎是每一个互联网从业者的噩梦,无奈的是,大家几乎都被上级要求写过竞品分析。本篇文章将与大家分享如何解决竞品分析报告的难题。
-
10
7 个步骤帮你编写一份好的数据分析报告 编写数据分析报...
-
5
微软收购动视暴雪又闯过一关国家市场监督管理总局无条件放行
-
5
一份优秀的竞品分析报告(以网易云音乐和QQ音乐竞品分析为例)
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK