

noisepage paper分享:基于column-storage实现的事务存储引擎
source link: https://zhuanlan.zhihu.com/p/351306672
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
noisepage paper分享:基于column-storage实现的事务存储引擎
这篇paper是CMU database group实现的self-driving database的系列paper的其中一篇,主要分享的是如何基于一个通用的列存格式来实现一个in-memory的HTAP系统。noisepage的前身是peloton,与monetdb(荷兰的CWI开发,open source),HyPer(德国慕尼黑TUM大学开发,已经被Tableau收购)齐名的列式数据库。
HTAP从工业界目前的实现来看,除了HANA比较另类,基本都是一个行存用来服务TP,一个列存用来服务AP,更细分有2种策略,内部实现行转列,典型的代表是TiDB,用户自己做ETL来实现行列转换,例如Greenplum,TBase。noisepage的实现算是一种学术界的探索,在列存的引擎上同时实现AP和TP。
因为作者在这篇paper中,基于arrow的in-memory的列存做的实现,所以在介绍TP能力实现之前,首先介绍一下arrow,arrow是为了AP的分析性能而生的一个全内存的列存储结构,它下面可以实现对AP或者大数据的各种存储格式,例如kudu,parquet。
arrow的存储可以适配打平的表结构,或者层次结构(典型的如树形结构),为了提升分析性能,对于下图的2个列的数据表,它在arrow中的存储格式如右图所示:
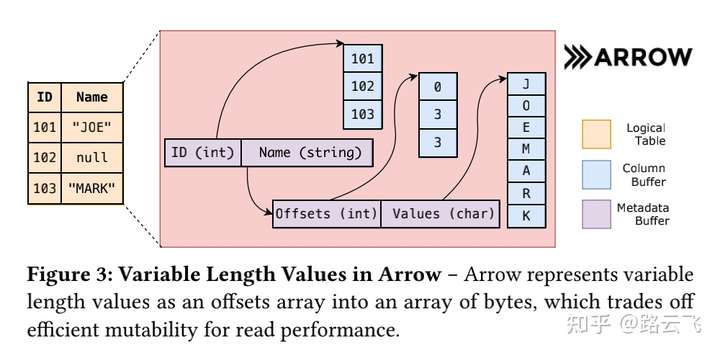
- 数据按列存储,并按照8字节对齐。例如上述的ID,metadata buffer直接指向存储id值得column buffer。
- 变长数据通过保存他们的offset数组来做跳转,长度需要计算得到,为当前行的offset与下一行的offset的差值。例如上图name列,包含一个offsets数组,和一个values的指针,offsets指向的数组是name列所在行在column buffer中的offset,第1行的offset为0,第2,3行的offset都是3.
- 使用一个额外的bitmap buffer来标识其中的null值。
2 系统概览
noisepage通过multi-versioned delta storage来实现事务引擎,其中事务版本信息与实际数据是分开存储,整体架构如下图:
- tuple的delta保存在本地事务的buffer中(不是arrow中),即上图的transaction context中的数据,buffer分成2种类似redo和undo,与mysql中的概念类似,redo是实际要修改后期望的值,用来回放,undo是写入(修改)前的值,当事务还没完成的时候用来提供给其他并发的时候提供读服务,在事务失败的时候用来回滚。
- 数据保存在data blocks中,data blocks即上述的arrow结构,并且这个table有一个额外的column用来保存该行的version chain指针,这一列对外部访问是不可见的,只是用来做可见性判断。
- 对于数据的读写,noisepage抽象除了一层data table layer,通过data table api对外提供数据存储引擎的读写服务,对于读操作,data table layer通过读version chain并找到正确的版本数据返回,对于写操作,data table layer在修改arrow中的数据之前,会先把数据拷贝出来到undo,并构建好对应的version chain。
- 以上图例如举例:transaction 2插入tuple (id=12, val=‘‘foo’’),首先redo里面会保存插入的tuple,由于之前没有数据,所以undo里面的valid为false,arrow的data blocks里面对应的version chain pointer指向undo;transaction 1修改id = 13,它会首先把这行修改前的值id = 12写入undo,然后修改arrow的data block中的值为id = 13,并把这条undo加入到version chain,这个时候的version chain是:data block(id = 13) -> transaction 1' undo(id = 12) -> transaction 2' undo( valid = false),从上图可以看到事务信息是ts和日志保存在一块。
- 为了处理数据大量写入的情况,undo buffer是固定大小的内存,不够的时候会动态申请,并且使用linked list来组织这些undo buffer。
2.1 OCC
noisepage这里使用的是optimistic concurrency control协议,即先写,提交的时候再检查是否冲突,冲突则回归,与之对应的是悲观事务,写之前先加锁,修改完之后再释放锁,其他事务等锁避免冲突回滚。OCC对于并发冲突严重的场景不友好,并发冲突会导致性能急剧下降,传统的TP系统都是使用悲观事务。
每个事务都有一个timestamp(后面简称为ts) pair(start,commit),commit的时间戳和start时间戳一样,只是commit的符号位取反用来标识该事务还没有提交。每次更新的时候,保存的是commit ts,读操作的时候,会获取当前的最新的ts(记为read ts),遍历version chain的时候,直到碰到一个ts比read ts还小,对比ts的时候,使用无符号对比,因为未提交的ts的符号位为1,所以未提交的ts都比read ts要大,所以会跳过,直到碰到一个ts小于read ts,那么该ts一定是已经committed,从而得到正确的版本。还是以上面的例子,例如使用ts=8去读,tansaction 1的undo的ts是-7,无符号对比的时候,比ts = 8要大,apply transaction 1的undo,并跳过到下一个版本,transaction 2的undo的ts是6,比8小,无需apply undo,最终得到正确的值id = 12。
当事务commit的时候,noisepage使用一个临界区得到一个commit ts来更新delta记录里面的commit ts,并把这个delta记录加入到log manage的队列中。在这个临界区中,不允许新的读,但是已经开始的事务可以继续执行。对于abort,noisepage使用undo log来替换在data block中的值,但是他不能从version chain中unlink出来,因为可能会出现脏读。例如一个活动事务在它abort的时候还没有把undo的记录更新回data block就拷贝了原来data block的数据作为一个新的版本,读的时候会顺着version chain把已经unlink的undo(这个undo)认为可见,相当于脏读,读到了未提交的数据。这个case的时序如下:
t1:txn1 更新data block(id = 2), txn1 undo (id = 1),version chain(->txn1 undo)
t2:txn2 更新data block(id = 3), txn2 undo(id = 2),version chain(->txn2 undo ->txn1 undo)
t3:txn1 abort,把txn 1 的undo从version chain中unlink
t4: txn2读到txn1修改的(id = 2)的记录。
t5:txn1 abort, apply txn1 undo,data block(id = 1)
2.2 abort的处理
abort的传统的做法是把undo的记录写回到data block中,并把version pointer重置回去,但是如果在读然后更新,例如典型的update id =1 where id > 10类似的sql,在读完后,再更新中间,有事务修改了数据并abort掉了,这个时候没法通过 简单判断version pointer是否一样来判断数据是否被修改过,即所谓的ABA问题,abort的时候,会把version pointer重置回去,但是data block中的值不一定修改回去了。
为了规避这个问题,作者的做法是不是通过把原来的version和值重置回去,而是把undo上的commit ts的符号位取反,即认为这个undo已经apply,这样做的问题是读的时候,需要多读一次这个undo上的记录,脏数据的回收在GC那一节会讲到。
PS:这部分的内容看了很久没思路,与
讨论后豁然开朗,非常感谢。2.3 blocks的数据组织
tuple数据和事务meta信息分开存储带来一个挑战,为了实现unique tuple,但是unique可能由多列组成,每列是分开存储的,没有存储在一块,逻辑上通过hash table来实现unique tuple,这个hash table可能成为系统的瓶颈,因为每次都需要2倍的内存访问,先访问hash table,得到行号,再读tuple值。为了解决这个问题,作者把每个block限制为1M,并使用一种“physiological scheme”来组织数据。
数据在每个block被组织成PAX(行列混存)格式,一个tuple的所有列的数据都在这个block,每个block有一个layout对象,由下面3个部分组成:
- block中slot的个数
- attribute (每行的列值)大小的数组
- 每列的offset。
每列和他的bitmap按照8字节对齐,系统在创建block的时候,会把这个layout计算出来。
每个tuple(行)通过一个TupleSlot来表示,TupleSlot由下面数据组成:
- tuple所在block的内存地址,起始地址
- attribute在block中的逻辑offset
为了把上述2种值用一个64位来表示,低20位用来表示offset,高42位用来保存block的物理地址。
2.4 GC的实现
GC的作用主要是用来删除version chain并释放对应的内存,对于被删除的tuple会在数据转成arrow的过程中处理,因为version chain相关的信息都保存在事务对应的buffer中,所以GC只需要扫描事务对应的buffer(上文提到的undo,redo),不需要去扫arrow格式中的数据。
开始扫描的时候,GC会首先检查事务引擎的得到最老的活动事务的start ts,比这个ts小的并且已经提交了的是可以安全清理的,GC会对每个事务的version chain做检测,并释放对应的version chain上的数据,直接从version chain上unlink对象并释放是不安全的,因为这个时候可能还有其它的事务正在读,为了处理这种情况,GC会从事务引擎获取一个自己的ts,标记为unlink ts,在这个时间之后的事务都不能访问这个unlink的记录,当正在运行的事务的start ts比unlink ts要大的时候,这个记录就可以被删除。(即保证未来的事务不会继续访问,已经访问的事务能够继续做完再清理)
2.5 logging和recovery
持久化的实现是通过WAL和checkpoints,每个事务维护一个redo buffer,提交的时候,会增加一个commit record到redo buffer,并把它放到flush 队列,日志管理器会异步把redo buffer写入磁盘并持久化,redo buffer也是由多个buffer segment组成,系统会在commit之前把redo 记录写入磁盘。如果事务还未提交就crash,而commit记录没有被写入磁盘,在recovery的过程中会忽略commit record。
当commit record添加到flush队列之后,系统就会认为这个事务被提交了,所有对这个事务的写操作集合的操作,都是一种“推测”,直到commit record被写入磁盘。系统会为commit record写入磁盘后调用一个callback,用来通知这个事务被持久化了,直到这个回调被调用,系统才向client发送 事务执行的结果。通过这种方式,即使有其他的事务因为上述的“推测”,即当前事务的comit record还没有被持久化,就开始通过读写这个事务修改的数据,从而做进一步的修改,也不会生效。callback的函数地址被编码到commit record里面,当log manger写commit record的时候,会把它加入回调队列,在fsync(这个函数才真正保证commit record被持久化到存储上)之后调用。系统要求对一个只读的事务也需要非持久化的commit record,用来保证上述所说的回调。
一般的数据库都是需要等这条日志被持久化之后 才认为事务提交,这里只要commit record加入到flush队列之后,就认为事务已经被“commit”,但是在commit record真正持久化之后,才向用户发送事务结果。而这个过程中,可能又有其他的事务基于之前被认为已经“commit”的记录,做了修改,显然这个时候,如果系统奔溃可能有2个时间点。
- 第一个事务的commit record还没有被持久化,recovery的时候,第一个和第二个事务的所有的修改都不可见,能保证系统的一致性。
- 第一个事务的commit record已经被持久化,但是第二个事务的修改commit record未被持久化。显然第一个事务的修改生效,第二个事务的修改不生效。也是能保证系统的一致性。
3 BLOCK TRANSFORMATION
arrow格式实现事务一个问题就是写放大,作者使用了一个灵活的arrow格式来实现高效的写入,当数据变冷(不再频繁做修改)的时候,通过一个轻量级的转换把一个block放入到arrow格式中。这个转换不是这篇paper的核心,所以细节不再复述。
这篇paper的核心是怎么基于arrow的列存格式,来实现一个TP的事务引擎,但是从他对事务协议OCC的选择,并不是面向典型的TP:高并发,且冲突严重的场景,作者还有其它的几篇paper,特别是执行引擎的优化,“Relaxed Operator Fusion for In-Memory Databases: Making Compilation, Vectorization, and Prefetching Work Together At Last”,典型的面向分析场景。综合来讲适合主要面向分析,但是具备完整事务能力的场景,这个定位与我们组当前的产品AnalyticDB PostgreSQL是吻合的,后续值得重点关注。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK