

B-Tree
source link: https://medium.com/@amitdavidson234/all-about-b-trees-and-databases-8c0697856189
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
All About B Trees and Databases
How B-Trees power your database in handling data-intensive workloads.
Recently, I’ve been reading Database Internals (Alex Petrov, 2019). An excellent book covering the implementation of database storage engines — the component of databases that stores and retrieves data from the disk in an efficient and reliable way. A significant part of this book discusses the implementation and optimization of various B-Tree data structures.
B-Trees are the most prominent data structures employed by databases. Most notable examples are Postgres, Mysql, and Oracle Database. Before diving into B-Trees, we should focus first on binary search trees.
Binary Tree
A binary tree is a data structure used for storing data in an ordered way. Each node in the tree is identified by a key, a value associated with this key, and two pointers (hence the name binary) for the child nodes. The rule is that the left child node must be less than all of its ancestors, and the right child node must be greater than all its ancestors.
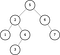
This way, we can easily find elements by looking at each node’s value and descent accordingly. If the searched value is smaller than the current value, descend to the left child; if it’s greater, descend to the right.
Rebalancing
When inserting a new element, we need to find the right position and insert a new node there. This might lead the tree to get out of balance. In the worst case, it might look like the case on the right, resembling a linked list instead of a tree.
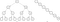
In an ideal case, following the right or left node reduces the search complexity in half on average by avoiding checking the unchosen path. When having an unbalanced tree, more nodes have to be traversed, which significantly slows down searches.
Mathematically speaking, when looking for an element, it has a complexity of O(log₂ N) on the tree form, and O(N) on the linked list form. The shallower the tree is, the faster searches will be.
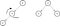
Instead of adding new elements to one of the tree branches and making it longer while the other remains empty, the tree will be rebalanced. As shown below, it’s done by rotating nodes around, to the right or the left. The rule of having smaller items on the left and greater on the right is preserved, but the height gets smaller, making searches faster.
On-Disk Limitations
The storage engine must commit the tree to disk to make database systems durable for crashes and power outages.
Data is stored on the disk in page frames. The data is laid contiguously on the disk and is usually 4KiB in size (defined by the underlying CPU architecture). That is the smallest amount of data that can be written or read programmatically.
Balanced search trees aren’t suitable for maintaining on disk:
- One reason is locality. Elements are entered in random order, so there’s no guarantee that nodes reside close to one another and may spread across different pages, causing excessive disk accesses.
- The second reason is tree height. Since binary tree nodes only have 2 children, the height of the tree increases relatively fast. For each level, we have to compare and descend to the node below, and in turn, additional disk access.
Disk accesses are costly, so when designing a data structure that resides on the disk, they have to be kept to a minimum.
B-Tree
B-Tree is a self-balancing tree data structure that maintains sorted data and allows searches, but it generalizes the binary search tree, allowing for nodes with more than two children.
More formally, each node has between k to 2k key-value pairs and k+1 to 2k+1 child pointers except the root node with as few as 2 children even when k is a high number.

B-Trees are suited for storage systems by solving the 2 problems from earlier.
- Each node is the size of a disk page. The total size of the keys, values and pointers matches 4KiB. The locality is increased as keys and values reside next to each other on the same disk page, so fewer disk accesses are required.
- The tree's height gets smaller by having more children in each node (also called higher fanout).
Searching, Inserting, and Deleting
Searching
Searching a B-Tree is done using a binary search. The algorithm starts with the root node and traverses all the keys until it finds the first key greater than the searched value. Then, we descend toward the relevant subtree using the corresponding child pointer and repeat the process until the value is found.

Range scans are also possible by finding the starting key of the scan and following sibling pointers until the last node is found. This is not optimal as values are spread across many nodes. A better approach is using a B+ tree, a modification of B-Tree.
Insertion
Insertion is done by performing a search and inserting the value at the correct index. Insertion might cause the tree to get out of balance if a node has too many values (n>2k).
In that case, the tree will be balanced using node split. Splitting is done by allocating a new node, transferring half of the key-value pairs there, and adding its first key and a pointer to that node to the parent node. If it’s a non-leaf node, then all the child pointers after the splitting point will be moved as well.
The first key and a corresponding pointer are moved to the parent, thus increasing its occupancy. This might result in overflow again, so rebalancing has to be repeated recursively all the way up the tree.

Deleting
When deleting, the target node and the deletion index are located. After removing, a node can get out of balance by having too few values (n<k). It can be solved either by merging nodes or by rotating.
Rotation can be done to the right or the left, depending on which node has an item to spare. A right rotation, for example, is done by copying the separator key from the parent to the start of the underflow node and replacing the separator key with the last element of its left sibling. When rotating a non-leaf node, the last child pointer of the left sibling is moved to the start of the unbalanced one. A similar approach is made when performing a left rotation.

If no sibling can spare an element (has k elements), the deficient node must be merged with a sibling. The merge causes the parent to lose a separator element, so the parent may become deficient and need rebalancing. Rebalancing may continue all the way to the root.
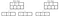
Summary
This post covered how data structures should accommodate on-disk storage. We started with an explanation about binary trees and how they fall short of being suitable for disk due to having few children and low locality. On the other hand, B-tree solves it by having more items in each node, making keys and values nearby on disk, and the tree shallower.
Then we covered how to implement find, insert and delete operations and rebalance them when they get out of balance using split, merge, and rebalancing, so the tree depth is kept to a minimum.
Big credit to Alex Petrov and his book Database Internals. The images and most of my knowledge about B Trees are from his book.
This post was inspired by my in-memory B Tree implementation written in Go. You can check it out GitHub.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK