

MapReduce 示例:减少 Hadoop MapReduce 中的侧连接
source link: https://my.oschina.net/u/4526289/blog/5264086
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
摘要:在排序和reducer 阶段,reduce 侧连接过程会产生巨大的网络I/O 流量,在这个阶段,相同键的值被聚集在一起。
本文分享自华为云社区《MapReduce 示例:减少 Hadoop MapReduce 中的侧连接》,作者:Donglian Lin。
在这篇博客中,将使用 MapReduce 示例向您解释如何在 Hadoop MapReduce 中执行缩减侧连接。在这里,我假设您已经熟悉 MapReduce 框架并知道如何编写基本的 MapReduce 程序。本博客中讨论的主题如下:
- 什么是加入?
- MapReduce 中的连接
- 什么是 Reduce 侧连接?
- 减少侧连接的 MapReduce 示例
什么是联接?
join操作用于基于外键将两个或多个数据库表合并。通常,公司在其数据库中为客户和交易 记录维护单独的表 。而且,很多时候这些公司需要使用这些单独表格中的数据生成分析报告。因此,他们使用公共列(外键)(如客户 ID 等)对这些单独的表执行连接操作,以生成组合表。然后,他们分析这个组合表以获得所需的分析报告。
MapReduce 中的连接
就像 SQL join 一样,我们也可以在 MapReduce 中对不同的数据集进行 join 操作。MapReduce 中有两种类型的连接操作:
- Map Side Join:顾名思义,join操作是在map阶段本身进行的。因此,在 map side join 中,mapper 执行 join 并且每个 map 的输入都必须根据键进行分区和排序。
- 减少副加入:顾名思义,在减少侧加入,减速是 负责执行连接操作。由于排序和改组阶段将具有相同键的值发送到同一个 reducer,因此它比 map side join 相对简单和容易实现,因此,默认情况下,数据是为我们组织的。
现在,让我们详细了解reduce side join。
什么是减少侧连接?
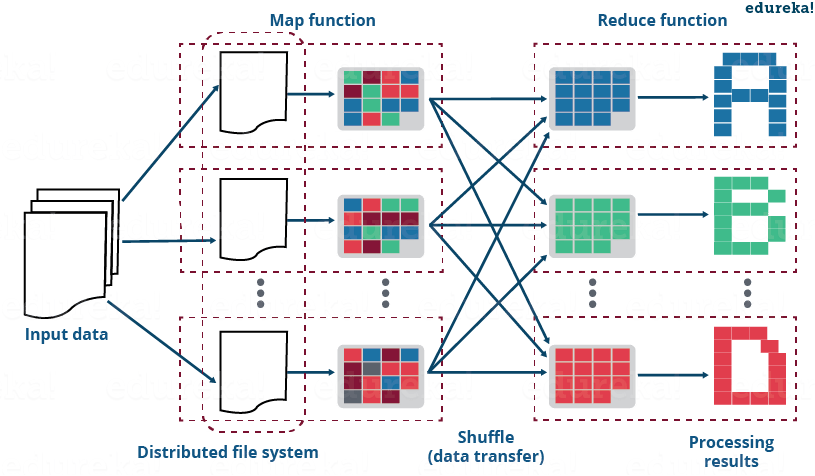
如前所述,reduce side join 是在reducer 阶段执行join 操作的过程。基本上,reduce side join 以下列方式发生:
- Mapper 根据公共列或连接键读取要组合的输入数据。
- 映射器处理输入并向输入添加标签以区分属于不同来源或数据集或数据库的输入。
- 映射器输出中间键值对,其中键只是连接键。
- 在排序和改组阶段之后,会为减速器生成一个键和值列表。
- 现在,reducer 将列表中存在的值与键连接起来,以给出最终的聚合输出。
减少边连接的 MapReduce 示例
假设我有两个单独的运动场数据集:
- cust_details: 它包含客户的详细信息。
- transaction_details: 包含客户的交易记录。
使用这两个数据集,我想知道每个客户的生命周期价值。在 这样做时,我将需要以下东西:
- 此人的姓名以及该人访问的频率。
- 他/她购买设备所花费的总金额。
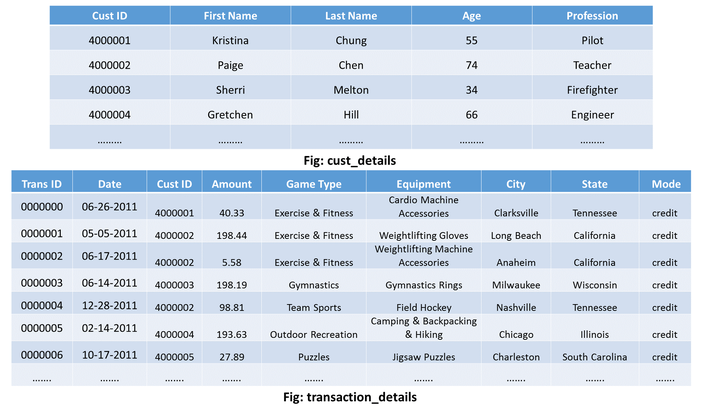
上图只是向您展示了我们将对其执行reduce side join 操作的两个数据集的schema。单击下面的按钮下载包含此 MapReduce 示例的源代码和输入文件的整个项目:
在将上面的 MapReduce 示例项目在 reduce 端加入 Eclipse 时,请记住以下几点:
- 输入文件位于项目的 input_files 目录中。将这些加载到您的 HDFS 中。
- 不要忘记根据您的系统或VM构建Hadoop Reference Jars的路径(存在于reduce side join项目lib目录中)。
现在,让我们了解在这个 MapReduce 示例中的 map 和 reduce 阶段内部发生了什么关于reduce side join:
1. 地图阶段:
我将为两个数据集中的每一个设置一个单独的映射器,即一个映射器用于 cust_details 输入,另一个用于 transaction_details 输入。
cust_details 的映射器:
public static class CustsMapper extends Mapper <Object, Text, Text, Text>
{
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{String record = value.toString();
String[] parts = record.split(",");
context.write(new Text(parts[0]), new Text("cust " + parts[1]));
}
}-
- 我将一次读取一个元组的输入。
- 然后,我将令牌化在元组的每个字并用的名字一起取卡斯特ID个人Ø ñ 。
- Ť ħ È Ç乌斯ID将是我的键值对键,我的映射器将最终生成。
- 我还将添加一个标签“ Ç乌斯” ,以表明该输入元组是cust_details类型。
- 因此,我的 cust_details 映射器将生成以下中间键值对:
键 - 值对:[客户 ID,客户名称]
例如:[4000001,Ç乌斯 克里斯蒂娜],[4000002,卡斯特佩奇]等
transaction_details 的映射器:
public static class TxnsMapper extends Mapper <Object, Text, Text, Text>
{
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
String record = value.toString();
String[] parts = record.split(",");
context.write(new Text(parts[2]), new Text("tnxn " + parts[3]));
}
}- 就像 cust_details 的映射器一样,我将在这里遵循类似的步骤。但是,会有一些差异:
- 我将获取金额值而不是人名。
- 在这种情况下,我们将使用“tnxn”作为标签。
- 因此,客户 ID 将是映射器最终生成的键值对的我的键。
- 最后,transaction_details 映射器的输出将采用以下格式:
键值对:[客户 ID,tnxn 金额]
示例: [4000001, tnxn 40.33]、[4000002, tnxn 198.44] 等。
2. 排序和洗牌阶段
排序和改组阶段将生成与每个键对应的值的数组列表。换句话说,它将中间键值对中每个唯一键对应的所有值放在一起。排序和改组阶段的输出将采用以下格式:
键 - 值列表:
- {cust ID1 – [(cust name1), (tnxn amount1), (tnxn amount2), (tnxn amount3),.....]}
- {客户 ID2 – [(客户名称 2), (tnxn amount1), (tnxn amount2), (tnxn amount3),.....]}
例子:
- {4000001 – [(cust kristina), (tnxn 40.33), (tnxn 47.05),…]};
- {4000002 – [(cust paige), (tnxn 198.44), (tnxn 5.58),…]};
现在,框架将为每个唯一的连接键(cust id)和相应的值列表调用 reduce() 方法(reduce(Text key, Iterable<Text> values, Context context))。 然后,reducer 将对相应值列表中存在的值执行连接操作,以最终计算所需的输出。因此,执行的reducer 任务的数量将等于唯一客户ID 的数量。
现在让我们了解在这个 MapReduce 示例中,reducer 如何执行连接操作。
3.减速器阶段
如果您还记得,执行这种减少侧连接操作的主要目标是找出特定客户访问综合体育馆的次数以及该客户在不同运动上花费的总金额。因此,我的最终输出应采用以下格式:
Key – Value 对:[客户姓名] (Key) – [总金额,访问频率] (Value)
减速机代码:
public static class ReduceJoinReducer extends Reducer <Text, Text, Text, Text>
{
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException
{
String name = "";
double total = 0.0;
int count = 0;
for (Text t : values)
{
String parts[] = t.toString().split(" ");
if (parts[0].equals("tnxn"))
{
count++;
total += Float.parseFloat(parts[1]);
}
else if (parts[0].equals("cust"))
{
name = parts[1];
}
}
String str = String.format("%d %f", count, total);
context.write(new Text(name), new Text(str));
}
}因此,将在每个减速器中采取以下步骤来实现所需的输出:
- 在每个减速器中,我都会有一个键和值列表,其中键只是客户 ID。值列表将具有来自两个数据集的输入,即来自 transaction_details 的金额和来自 cust_details 的名称。
- 现在,我将遍历 reducer 中的值列表中存在的值。
- 然后,我将拆分值列表并检查该值是 transaction_details 类型还是 cust_details 类型。
- 如果是transaction_details类型,我将执行以下步骤:
- 我将计数器值加一来计算这个人的访问频率。
- 我将累积更新金额值以计算该人花费的总金额。
- 另一方面,如果值是 cust_details 类型,我会将它存储在一个字符串变量中。稍后,我会将名称指定为我的输出键值对中的键。
- 最后,我将在我的 HDFS 的输出文件夹中写入输出键值对。
因此,我的减速器将生成的最终输出如下:
克里斯蒂娜,651.05 8
佩奇,706.97 6
…..
而且,我们上面所做的整个过程在 MapReduce 中称为Reduce Side Join。
源代码:
上面的减少侧连接的 MapReduce 示例的源代码如下:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ReduceJoin {
public static class CustsMapper extends Mapper <Object, Text, Text, Text>
{
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException
{
String record = value.toString();
String[] parts = record.split(",");
context.write(new Text(parts[0]), new Text("cust " + parts[1]));
}
}
public static class TxnsMapper extends Mapper <Object, Text, Text, Text>
{
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException
{
String record = value.toString();
String[] parts = record.split(",");
context.write(new Text(parts[2]), new Text("tnxn " + parts[3]));
}
}
public static class ReduceJoinReducer extends Reducer <Text, Text, Text, Text>
{
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException
{
String name = "";
double total = 0.0;
int count = 0;
for (Text t : values)
{
String parts[] = t.toString().split(" ");
if (parts[0].equals("tnxn"))
{
count++;
total += Float.parseFloat(parts[1]);
}
else if (parts[0].equals("cust"))
{
name = parts[1];
}
}
String str = String.format("%d %f", count, total);
context.write(new Text(name), new Text(str));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "Reduce-side join");
job.setJarByClass(ReduceJoin.class);
job.setReducerClass(ReduceJoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
MultipleInputs.addInputPath(job, new Path(args[0]),TextInputFormat.class, CustsMapper.class);
MultipleInputs.addInputPath(job, new Path(args[1]),TextInputFormat.class, TxnsMapper.class);
Path outputPath = new Path(args[2]);
FileOutputFormat.setOutputPath(job, outputPath);
outputPath.getFileSystem(conf).delete(outputPath);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}运行这个程序
最后,在reduce side join上运行上述MapReduce示例程序的命令 如下:
hadoop jar reducejoin.jar ReduceJoin /sample/input/cust_details /sample/input/transaction_details /sample/output
结论:
在排序和reducer 阶段,reduce 侧连接过程会产生巨大的网络I/O 流量,在这个阶段,相同键的值被聚集在一起。因此,如果您有大量具有数百万个值的不同数据集,您很可能会遇到 OutOfMemory 异常,即您的 RAM 已满,因此溢出。在我看来,使用reduce side join的优点是:
- 这很容易实现,因为我们利用 MapReduce 框架中的内置排序和改组算法,该算法组合相同键的值并将其发送到同一个减速器。
- 在reduce side join 中,您的输入不需要遵循任何严格的格式,因此您也可以对非结构化数据执行连接操作。
一般来说,人们更喜欢 Apache Hive,它是 Hadoop 生态系统的一部分,来执行连接操作。因此,如果您来自 SQL 背景,则无需担心编写 MapReduce Java 代码来执行连接操作。您可以使用 Hive 作为替代方案。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK