

刚哥谈架构(十四)大数据软件开源版图(续)
source link: https://my.oschina.net/taogang/blog/5118502
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
在上一篇的 刚哥谈架构(十三)大数据软件开源版图中因为篇幅问题,没有对大数据开源版图中的各个部分的内容做详细的介绍今天我们就接着上次的话题,具体看看在大数据开源版图中的各部分内容。
我们对每个领域挑出三个典型的选项,给大家做个简单的介绍。
数据摄取和转换 Data Ingestion & ETL
大数据系统的数据源来源多种多样,主要包含以下的种类:
-
存在事务数据库中的业务数据 (MySQL Oracle)
-
业务应用系统(SAP ERP/Salesforce)
-
第三方系统的开放API
-
文件和对象存储
大数据系统的第一个重要子系统是对数据源进行摄取和转换,传统的定义叫ETL(Extract,Transform,Load)。现代化的数据系统逐渐从ETL转为ELT,转化的工作会交给后续的数据处理子系统来进行。我们也可以称这一部分为大数据管道。

Airbyte 是一个由开源社区创建的平台,用于以编程方式创作、安排和监控工作流。 Airbyte 用户可以利用其预先构建或自定义的连接器来自动化和控制数据管道。 Airbyte支持用自己喜欢的语言构建自己的管道和连接器。 Airbyte 连接器作为 Docker 容器运行,开箱即可使用。用户可以利用其 UI 和 API 进行监控、调度和编排。由于 Airbyte 使用单个开源存储库进行标准化和整合,因此这些连接器具有更高的质量。 Airbyte 呈指数级增长,围绕它建立了一个充满活力的支持社区。然而,这项技术仍然是新的,还没有完全成熟。Airbyte于今年5月完成了2600万美元的A轮融资。
Vector 是一种高性能的可观察性数据管道,可让组织控制其可观察性数据。收集、转换您的所有日志、指标和跟踪,并将其路由到需要的任何地方。
Vector 使用Rust开发的数据管道,速度快,内存效率高。它旨在处理最苛刻的环境。 端到端 Vector 旨在成为从 A 到 B 获取数据所需的唯一工具,部署为守护进程、边车Sidecar或服务。 Vector 支持日志、指标和事件,可以轻松收集和处理所有可观察性数据。 Vector 不支持任何存储, 可编程转换(T),提供可编程运行时的全部功能。无限制地处理复杂的用例。Vector使用自己开发的数据管道定义和转换DSL来实现数据变形的功能。
Vector背后的公司timber.io 成立于2016年,这是一个与供应商无关的高性能可观察性数据管道,可让客户在本地和云环境中收集,丰富和转换日志及其他可观察性数据。于今年2月被datadog收购。在被收购之前,Timber已经从NextView Ventures,Wonder Ventures和Notation Capital等投资者那里筹集了580万美元的风险投资资金。
Airflow 是一个由社区创建的平台,用于以编程方式创作、安排和监控工作流。严格意义上说,Airflow不是一款专本的ETL工具,它是一个更为通用的工作流平台。但是它可以被用于大数据的数据管道,提供定制的ETL的能力。
使用 Airflow 将工作流创作为任务的有向无环图 (DAG)。 Airflow 调度程序在遵循指定的依赖项的同时在一组工作人员上执行您的任务。丰富的命令行实用程序使在 DAG 上执行复杂的手术变得轻而易举。丰富的用户界面使可视化生产中运行的管道、监控进度和在需要时解决问题变得容易。当工作流被定义为代码时 (Workflow as Code),它们变得更加可维护、可版本化、可测试和协作。
数据仓库OLAP
在计算机领域,数据仓库是用于报告和数据分析的系统,被认为是商业智能的核心组件。 数据仓库是来自一个或多个不同源的集成数据的中央存储库。数据仓库将当前和历史数据存储在一起,用于为整个企业的员工创建分析报告。 存储在仓库中的数据从运行系统上传。
Apache Druid是开源分析数据库,专为对高维度和高基数数据进行亚秒级OLAP查询而设计,它由广告分析公司Metamarkets创建,到目前为止,已被许多公司使用,包括Airbnb,Netflix,Nielsen,eBay,Paypal和Yahoo。它结合了OLAP数据库,时间序列数据库和搜索系统的思想,以创建适用于广泛使用案例的统一系统。最初,Apache Druid在2012年获得GPL许可,成为开源软件,此后在2015年更改为Apache 2许可,并于2018年加入Apache Software Foundation作为孵化项目
作为俄罗斯搜索巨头Yandex开发的面向列存的关系型数据库,ClickHouse是过去两年中OLAP领域中最热门的,并于2016年开源。典型的用户包括著名的公司,例如字节,新浪和腾讯。
ClickHouse是基于MPP架构的分布式ROLAP(关系OLAP)分析引擎。每个节点都有同等的责任,并负责部分数据处理(不共享任何内容)。ClickHouse 是一个真正的列式数据库管理系统(DBMS)。在 ClickHouse 中,数据始终是按列存储的,包括矢量(向量或列块)执行的过程。只要有可能,操作都是基于矢量进行分派的,而不是单个的值它开发了矢量化执行引擎,该引擎使用日志合并树,稀疏索引和CPU功能(如SIMD单指令多数据)充分发挥了硬件优势,可实现高效的计算。因此,当ClickHouse面临大数据量计算方案时,通常可以达到CPU性能的极限。

Apache Kylin是用于大数据的分布式分析引擎,提供SQL接口和多维分析(OLAP)并可用于用Hadoop栈。它最初由eBay中国研发中心开发,于2014年开源并为Apache Software Foundation贡献力量,具有亚秒级的查询功能和超高的并发查询功能,被美团,滴滴,携程,壳牌,腾讯,58.com等许多主要制造商采用。
Kylin是基于Hadoop的MOLAP(多维OLAP)技术。核心技术是OLAP Cube;与传统的MOLAP技术不同,Kylin在Hadoop上运行,Hadoop是一个功能强大且可扩展的平台,可以支持大量(TB到PB)数据。它将预先计算(由MapReduce或Spark执行)的多维多维数据集导入到低延迟分布式数据库HBase中,以实现亚秒级的查询响应。最近的Kylin 4开始使用Spark + Parquet代替HBase来进一步简化架构。由于在脱机任务(多维数据集构造)过程中已完成大量聚合计算,因此在执行SQL查询时,它不需要访问原始数据,而是直接使用索引来组合聚合结果并再次进行计算。性能高于原始数据。一百甚至数千次;由于CPU使用率低,它可以支持更高的并发性,特别适合于自助服务分析,固定报告和其他多用户交互式分析方案。
数据湖 Datalake
数据湖,是指使用大型二进制对象或文件这样的自然格式储存数据的系统 。它通常把所有的企业数据统一存储,既包括源系统中的原始副本,也包括转换后的数据,比如那些用于报表, 可视化, 数据分析和机器学习的数据。数据湖可以包括关系数据库的结构化数据、半结构化的数据,非结构化数据和 二进制数据。

Delta Lake是一个开源存储层,可为数据湖带来可靠性。 Data Lake是一个集中的存储库,可以存储任何规模的数据。 通常,这些数据将为原始格式。 捕获数据时未定义数据或架构的结构。 这意味着可以存储所有数据,而无需进行仔细的设计或知道将来可能需要回答的问题。 Data Lake的一个问题是它缺乏可靠性,并且Data Lake中可能有不良数据。 Delta Lake是位于Data Lake之上的存储层。 Delta Lake将查看来自Data Lake的数据,并确保数据符合指定的架构。 这样,进入Delta Lake的数据将是正确和可靠的。 Delta Lake可以处理批量数据和流数据。 与Data Lakes相比,Delta Lakes还可以优化性能。
Apache Hudi 是一个快速迭代的数据湖存储系统,可以帮助企业构建和管理PB级数据湖,Hudi通过引入upserts、deletes和增量查询等原语将流式能力带入了批处理。这些特性使得统一服务层可提供更快、更新鲜的数据。Hudi表可存储在Hadoop兼容的分布式文件系统或者云上对象存储中,并且很好的集成了 Presto, Apache Hive, Apache Spark 和Apache Impala。Hudi开创了一种新的模型(数据组织形式),该模型将文件写入到一个更受管理的存储层,该存储层可以与主流查询引擎进行互操作,同时在项目演变方面有了一些有趣的经验。
Apache Hudi 这一类的数据湖相当于现有OLTP和OLAP技术的桥梁。他们能够以现有OLTP中的数据结构存储数据,支持CRUD,同时提供跟现有OLAP框架的整合(如Hive,Impala),以实现OLAP分析Apache Kudu,需要单独部署集群。而Apache Hudi则不需要,它可以利用现有的大数据集群比如HDFS做数据文件存储,然后通过Hive做数据分析,相对来说更适合资源受限的环境

Apache Iceberg 是一种用于跟踪超大规模表的新格式,是专门为对象存储(如S3)而设计的。Apache Iceberg 是由 Netflix开发开源的,其于 2018年11月16日进入 Apache 孵化器。是 Netflix公司数据仓库基础。在功能上和 Delta Lake 或者 Apache Hudi 类似,但各有优缺点。
Iceberg 的目标包括:
-
成为静态数据交换的开放规范,维护一个清晰的格式规范,支持多语言,支持跨项目的需求等。
-
提升扩展性和可靠性。能够在一个节点上运行,也能在集群上运行。所有的修改都是原子性的,串行化隔离。原生支持云对象存储,支持多并发写
-
修复持续的可用性问题,比如模式演进,分区隐藏,支持时间旅行、回滚等。
机器学习和运维 ML & MLOps
开源的机器学习和深度学习工具有很多,其中常用的算法工具有TensorFlow, PyTorch, Keras, Caffe, ONNX, Scikit-learn, LibSVM, 和XGBoost等。这些工具都非常成熟,随着AIOps/MLOps的兴起,我们更关注一些解决大规模机器学习的运维功能的平台型的开源工具。
当前机器学习所遇到的挑战:
-
使用的软件工具繁多,一个机器学习的项目基本上数据收集和准备,模型训练,模型部署的不断迭代过程,这个过程中的每一步都有很多不同的工具和选择。单就模型训练来说,我们就有scikit-learn,pytorch,spark,tensorflow,R 等等诸多选择。它们各自具有不同的优缺点和适用场合,对于数据科学家而言,要管理和适用这么多的工具,确实非常困难。
-
很难跟踪和重现数据处理,代码运行,参数调试的过程和结果。
-
很难对模型进行产品化,部署模型很困难。
-
当数据规模增长的时候,很难扩展和伸缩。
Kubeflow和MLFlow是google和databrick对于解决这些问题给出的答案。

Kubeflow,顾名思义,是Kubernetes + Tensorflow,是Google为了支持自家的Tensorflow的部署而开发出的开源平台,当然它同时也支持Pytorch和基于Python的SKlearn等其它机器学习的引擎。与其它的产品相比较,因为是基于强大的Kubernetes之上构建,Kubeflow的未来和生态系统更值得看好。
MLflow 是一个开源平台,用于管理端到端机器学习生命周期。MLflow 被组织成四个组件:跟踪、项目、模型和模型注册。可以单独使用这些组件中的每一个——例如,也许想以 MLflow 的模型格式导出模型而不使用跟踪或项目——但它们也被设计为可以很好地协同工作。
MLflow 的核心理念是对工作流程施加尽可能少的限制:它旨在与任何机器学习库一起使用,按照惯例确定有关您代码的大部分内容,并且只需最少的更改即可集成到现有代码库中。同时,MLflow 旨在采用以其格式编写的任何代码库,并使其可被多个数据科学家复制和重用。

MindSpore是华为开源的,端边云全场景按需协同的AI计算框架,提供全场景统一API,为全场景AI的模型开发、模型运行、模型部署提供端到端能力。
即席查询 (Ad hoc Query)

Presto是一个适用于大数据的分布式SQL查询引擎,使SQL可以访问任何数据源。可以使用Presto通过水平缩放查询处理来查询非常大的数据集。Presto用于对大小从GB到PB的各种数据源运行交互式分析查询。Presto是专为交互式分析而设计和编写的,可在扩展到Facebook之类的组织规模的同时,实现商业数据仓库的速度。虽然Presto理解并可以有效执行SQL,但是Presto不是数据库,因为它不包括自己的数据存储系统。它并不是要成为通用的关系数据库。Presto并非设计为处理OLTP的场景。

Apache Drill 可以在不同的数据源上执行SQL查询, 它是一个低延迟的大型数据集的分布式查询引擎,包括结构化和半结构化数据/嵌套。其灵感来自于谷歌的 Dremel,Drill 的设计规模为上千台节点并且能与 BI 或分析环境互动查询。 Apache Drill类似SparkSQL和Presto,Apache Drill可以在不同的数据源上执行SQL查询, 它是一个低延迟的大型数据集的分布式查询引擎,包括结构化和半结构化数据/嵌套。其灵感来自于谷歌的 Dremel,Drill 的设计规模为上千台节点并且能与 BI 或分析环境互动查询。在大型数据集上,Drill 还可以用于短,交互式的临时查询。Drill 能够用于嵌套查询,像 JSON 格式,Parquet 格式以及动态的执行查询。Drill 不需要一个集中的元数据仓库。
Apache Drill 的核心服务是 “Drillbit”,她负责接受来自客户端的请求,处理请求,并返回结果给客户端。Drillbit 服务能够安装在并运行在 Hadoop 集群上。当 Drillbit 运行在集群的每个数据节点上时,能够最大化去执行查询而不需要网络或是节点之间移动数据。Drill 使用 ZooKeeper 来维护集群的健康状态。虽然 Drill 工作于 Hadoop 集群环境下,但是 Drill 不依赖 Hadoop,并且可以运行在任何分布式集群环境下。唯一的先决条件就是需要 ZooKeeper。

Apache Spark是一个开源集群运算框架,最初是由加州大学柏克莱分校AMPLab所开发。相对于Hadoop的MapReduce会在运行完工作后将中介资料存放到磁盘中,Spark使用了存储器内运算技术,能在资料尚未写入硬盘时即在存储器内分析运算。Spark是大家非常熟悉的计算引擎,我们不需多讲。值得关注的是Databricks是由Apache Spark的最初创建者创建的企业软件公司。该公司还创建了Delta Lake,MLflow和Koalas,这是跨数据工程,数据科学和机器学习的流行开源项目。2021年2月1日,Databricks 宣布已完成10亿美元G轮融资。
实时流分析
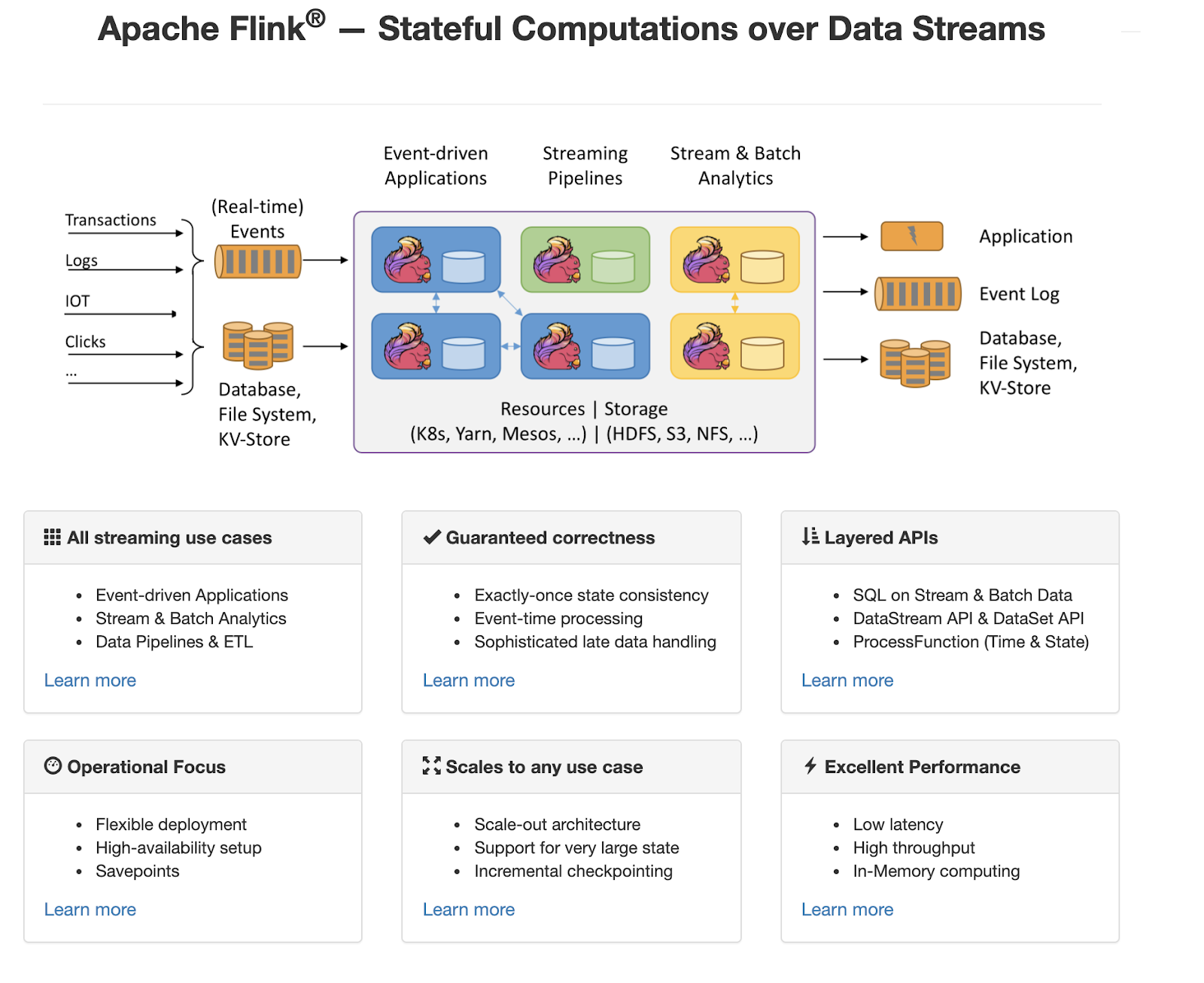
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。Apache Flink 擅长处理无界和有界数据集,精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
Kafka ksqlDB 是一个用于在 Apache Kafka 之上构建流处理应用程序的数据库。它是分布式的、可扩展的、可靠的和实时的。 ksqlDB 通过熟悉的轻量级 SQL 语法将实时流处理的强大功能与关系数据库的平易近人的感觉相结合。
Faust 是一个流处理库,它的想法是从 Kafka Streams 移植到 Python。
Faust本后的公司是Robinhood, Robinhood使用它来构建每天处理数十亿个事件的高性能分布式系统和实时数据管道。
Faust 提供流处理和事件处理,与 Kafka Streams/Apache Spark/Storm/Samza/Flink 等工具相似。
Faust提供的计算能力比较简单,适合比较轻量,简单的流式计算场景。
数据可视化和商务智能 Data Visualization & BI
数据展现和数据可视化是所有数据用户都喜欢使用的功能,也是传统BI的标配。在这个领域Tabluea是领军公司。

Superset是Airbnb开源的BI和数据可视化工具箱。 Superset快速,轻巧,直观,并带有各种选项,使各种技能的用户都可以轻松浏览和可视化其数据,从简单的折线图到高度详细的地理空间图。
目前,Superset已在许多公司大规模运行。 例如,Superset在Kubernetes内的Airbnb生产环境中运行,每天为600多个活跃用户提供服务,每天查看超过10万张图表。

Redash旨在使任何人,无论技术水平如何,都可以利用数据的力量。 SQL用户可以利用Redash来探索,查询,可视化和共享来自任何数据源的数据。他们的工作反过来使组织中的任何人都可以使用数据。每天,全球成千上万个组织中的数百万用户使用Redash来开发见解并制定数据驱动的决策。
Redash背后的公司创建于2015年,并于2020年被Spark的所有公司Databrick收购。
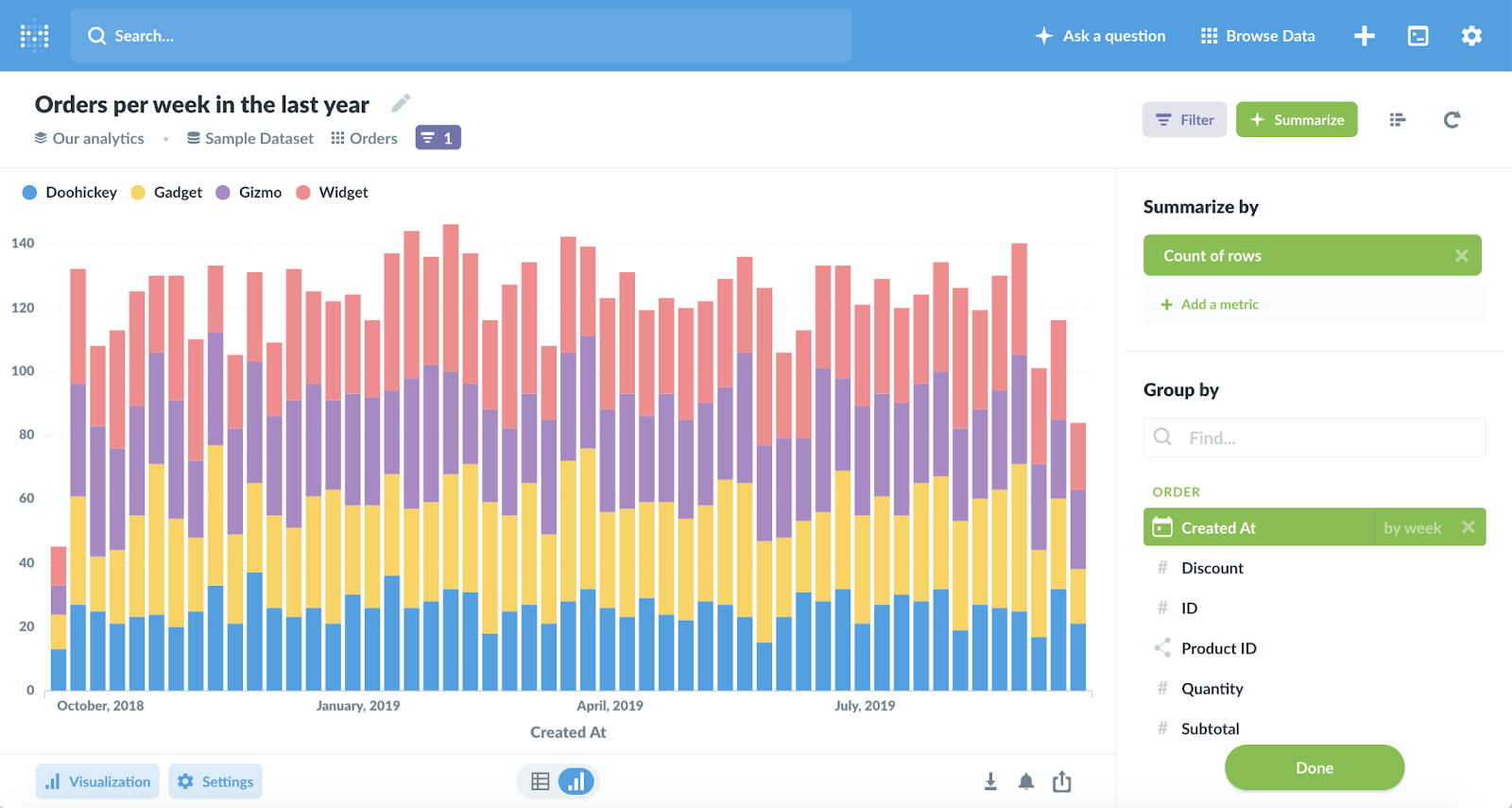
Metabase 2014年创建于美国硅谷,它的产品理念是公司中每个人都可以提出问题并从数据中学习的一种简单,开源的方式。
Metabase支持中文,支持三种不同的方式来解决查询问题。
Metabase支持常见的可视化类型。
Metabase通过可视化的方式来支持自定义查询,避免了写SQL。当然,它也支持SQL的编辑。
大数据搜索 Search
ElasticSearch是一个基于Lucene的开源搜索服务。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
ELK是ElasticSearch,Logstash,Kibana的缩写,分别提供搜索,数据接入和可视化功能,构成了Elastic的应用栈。
ELK基本上可以说是开源搜索的事实标准。拥有非常强大的社区支持。
Vespa.ai 是用于对大型数据集进行低延迟计算的引擎。它存储和索引数据,以便在服务时对数据进行查询、选择和处理。可以使用 Vespa 中托管的应用程序组件自定义和扩展功能。
Vespa 支持以下的功能
-
使用类似 sql 的查询和非结构化搜索选择内容
-
组织所有匹配以生成数据驱动的页面
-
通过手写或机器学习的相关模型对匹配进行排名
-
每个节点每秒数千次实时写入持久数据
-
在服务和编写的同时扩展、缩小和重新配置集群
Milvus 是一款开源的向量数据库,支持针对 TB 级向量的增删改操作和近实时查询,具有高度灵活、稳定可靠以及高速查询等特点。Milvus 集成了 Faiss、NMSLIB等广泛应用的向量索引库,提供了一整套简单直观的 API,让你可以针对不同场景选择不同的索引类型。此外,Milvus 还可以对标量数据进行过滤,进一步提高了召回率,增强了搜索的灵活性。
图数据库 Graph Database
关系数据库具有分类帐样式的结构。可以通过SQL查询它,这是大多数人所熟悉的。每个条目由表中的一行组成。表格是通过外键约束来关联的,外键约束是您可以将一个表的信息连接到另一个表(例如主键)的方式。查询关系数据库时,通常会涉及缓慢的多级联接。
对于图(特别是散点图),请将元素视为节点或点。折线图的元素类似地由顶点表示。每个节点都有键值对和标签。节点通过关系或边连接。关系具有类型和方向,并且可以具有属性。图形数据库仅由点和线组成。当含义在数据之间的关系中时,这种类型的数据库更简单,功能更强大。关系数据库可以轻松处理直接关系,但是间接关系在关系数据库中更难处理。

Neo4j是最老牌的图数据库。创建于2007年,被db-engines.com评为第一名的图形数据库。Neo4j是开源的,并支持多种编程语言,包括:.Net,Clojure,Elixir,Go,Groovy,Haskell,Java,JavaScript,Perl,PHP,Python,Ruby和Scala。服务器操作系统是Linux,OS X,Solaris和Windows。

Nebula Graph 是一款开源的分布式图数据库,擅长处理千亿个顶点和万亿条边的超大规模数据集。提供高吞吐量、低延时的读写能力,内置 ACL 机制和用户鉴权,为用户提供安全的数据库访问方式。
作为一款高性能高可靠的图数据库,Nebula Graph 提供了线性扩容的能力,支持快照方式实现数据恢复功能。在查询语言方面,开发团队完全自研开发查询语言——nGQL。
Dgraph是使用Golang构建的分布式,支持事务,快速的图形数据库。Dgraph的目标是提供谷歌生产水平的规模和吞吐量,具有足够低的延迟,可以提供超过数TB的结构化数据的实时用户查询。DGraph组件支持GraphQL的查询语法,以及响应JSON和协议缓冲区超过GRPC和HTTP。
数据质量和元数据 Metadata Management
企业内部可能运行多种类型数据库,从大类上可以分,大数据平台,sql数据库,nosql数据库,图数据库等,从具体的数据库类型可能是mysql,oracle,mongodb等,不管是什么类型的数据库,终归都是一个目的,存储数据,对怎么管理数据每个数据库有每个数据库的方式,以oracle为例
-
schema是一组数据库对象的集合
-
table是存储数据的实体
-
column列表示数据库的每个属性
-
view视图表示虚拟表,表示一组查询的逻辑集合
-
materialview物化视图则是对视图的实体化
-
同义词表示数据库对象的别名
-
...等等
那么schema,table,column这些描述数据的信息就是元数据,元数据库管理有什么用,我们平时做开发可能很少会去考虑这个问题,元数据管理对保证数据库质量是非常重要的,通过元数据管理
-
分析表,视图等数据库对象间的依赖关系
-
分析字段间的传递关系,在元数据库管理中,我们称之为数据血缘关系
-
分析是否存在重复字段,矛盾字段等
-
为企业提供数据地图
每个业务系统可能会自己定义表,视图,这些数据从哪来又流往哪去,数据之间是否存在关联,和其他系统的数据是否存在重复字段和矛盾字段,这些就是元数据管理要解决的问题。

Apache Atlas是托管于Apache旗下的一款元数据管理和治理的产品,Apache Atlas提供api和一系列插件可以方便将数据库元数据信息导入到atlas中进行分析。atlas也提供web界面对元数据进行管理,通过atlas,企业可以对数据库元数据建立资产目录,并对这些资产进行分类和治理,为数据分析,数据治理提供高质量的元数据信息。
面对海量且持续增加的各式各样的数据对象,必须考虑数据管理的实际情况,元数据与数据治理成为企业级数据湖的重要部分。为寻求数据治理的开源解决方案,Hortonworks 公司联合其他厂商与用户于2015年发起数据治理倡议,包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理等方面。Apache Atlas 项目就是这个倡议的结果,社区伙伴持续的为该项目提供新的功能和特性。该项目用于管理共享元数据、数据分级、审计、安全性以及数据保护等方面,努力与Apache Ranger整合,用于数据权限控制策略。
CKAN是一款开源的数据管理系统。它是一个制作开放数据网站的工具。 它可以帮助管理和发布数据集合。它被国家和地方、研究机构和其他收集大量数据的组织使用。
数据发布后,用户可以使用其分面搜索功能浏览和查找所需数据,并使用地图、图表和表格进行预览。
加拿大就是采用了CKAN来管理数据,作为用户,说实话,我觉得他的系统真的不太好用。

Amundsen.io 是一个数据发现和元数据引擎,用于提高数据分析师、数据科学家和工程师在与数据交互时的工作效率。今天,它通过索引数据资源(表、仪表板、流等)并根据使用模式支持页面排名样式搜索(例如,高度查询的表比查询较少的表更早显示)来实现这一点。将其视为 Google 搜索数据。该项目以挪威探险家罗尔德·阿蒙森(Roald Amundsen)的名字命名,他是第一个发现南极的人。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK