

快准狠的数据挖掘分析,用了这些方法!复旦 & Zilliz 梦幻联动
source link: https://my.oschina.net/u/4209276/blog/5231856
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

快准狠的数据挖掘分析,用了这些方法!复旦 & Zilliz 梦幻联动
「交互式数据探索系统中,『快』与『准』的需求如何做好平衡?」
「小白用户想做数据挖掘,分析方法不会选,怎么办?」
「数据检索需要遍历每一个数据,如何提升检索性能?」
上周五,Z 宝参加了一场干货满满的 Tech Talk,复旦大学计算机科学技术学院的荆一楠副教授和张凯副教授来到 Zilliz,与 Z 星的工程师们分享数据库领域前沿的研究方向。一起来看一看我们的思想火花吧:
从“语言级”、“工具级”到“智能级”,AI 技术让数据分析更“聪明”
荆一楠从哈勃望远镜谈起,引入数据探索的概念,介绍了团队在数据自动分析、数据可视化方向做的一系列工作,分享了团队研发的智能大数据探索系统—— DataHubble。

“让用户轻松地做选择”是荆一楠团队研发的初心。为了让系统实现更智能的分析方法推荐,DataHubble 首创了一种基于协同过滤和知识图谱的分析模型推荐方法(ModelAdvisor),与现有的 AutoML 方法相比,ModelAdvisor 引入了专家知识,大大增强了分析方法推荐的准确度,同步提升推荐可解释性。
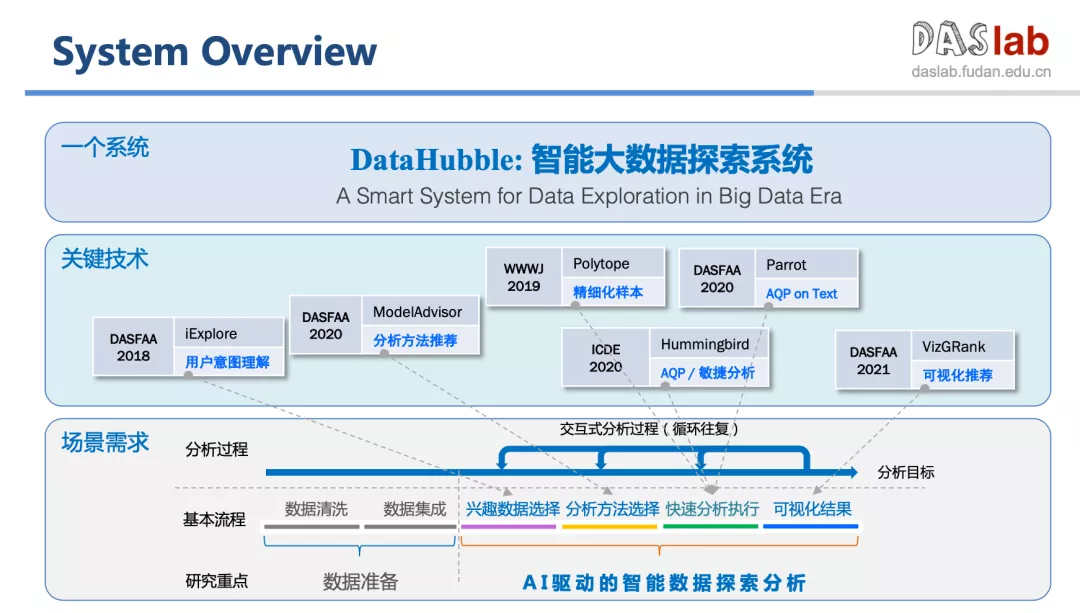
除了分析方法推荐,DataHubble 在用户意图理解、精细化样本、敏捷分析、AQP on Text 等方面也取得了关键成果:
智能数据分析,融合了人工智能能力,可实现增强式的智能数据分析;自然语言交互,提升了大数据分析系统的易用性和分析效率;可视化的推荐,从根本上减少了人和数据之间的 gap。
两种方法左右横跳?BinDex 用一种方法把数据扫描的性能提升了 1.6 倍
张凯从现有的数据检索痛点入手,分享了 BinDex 数据扫描方法。

现有的数据检索分为索引扫描(Index scan) 和顺序扫描(Sequential scan) 两种方式,这两种方式各有优缺点:索引扫描通常采用 B+ 树等索引结构进行扫描,仅会访问满足谓词约束的数据,但是扫描过程会产生大量的随机访问,影响吞吐率;顺序扫描依次访问存储介质,扫描吞吐量高,但需要遍历所有数据。
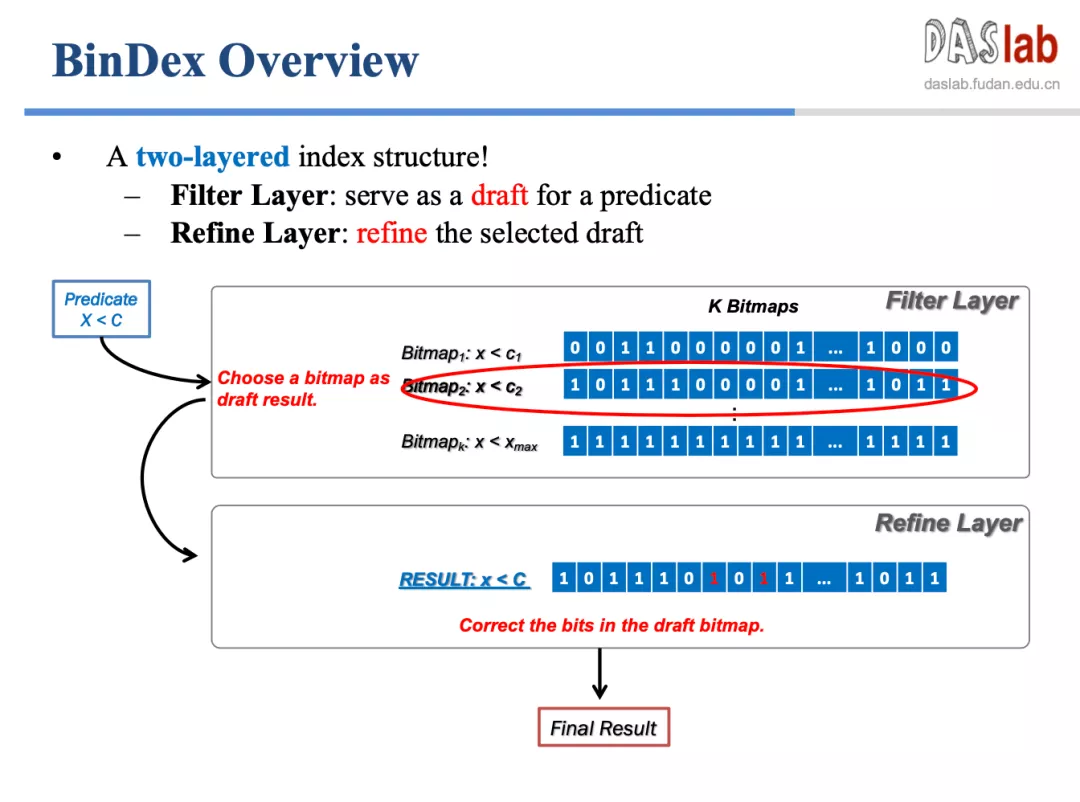
为了找到较优的方法,用户在数据检索前要预判成本。然而,成本估算不一定准确,用户有时无法确定要使用哪种扫描方式。针对这个问题,张凯团队尝试用新的方法加速扫描过程。张凯团队研发的 BinDex 方法吸取了索引扫描和顺序扫描两者的优点,只需要触碰到满足条件的数据,在不同选择率(selectivity) 下都能达到比较好的性能。
如此强大的 BinDex 是如何实现的?张凯进一步介绍了 BinDex 的架构原理:BinDex 使用两层索引,第一层 Filter Layer 实现近似查找,第二层 Refine Layer 针对性地修改少量错误数据。当用户发出一个查询请求,系统会先找到和所要结果最相近的查找,随后更正并输出正确答案。
有了 BinDex 扫描,用户无需按传统的方法“预判-选择”,而是可以直接上手扫描。经测试,扫描速度至少提升了 1.6 倍。
在未来,我们的科技乐园 Z 星会举办更多有趣、有用的技术沙龙。
让我们一起对新技术永葆好奇,创造革新的数据科学平台!
Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz 构建了 Milvus 向量数据库,以加快下一代数据平台的发展。Milvus 是 LF AI & Data 基金会的毕业项目,能够管理大量非结构化数据集,在新药发现、推荐引擎、聊天机器人等方面具有广泛的应用。
Recommend
-
63
用了那么久 Siri,这些技巧你都知道了吗
-
30
这次我真的完全抛弃了 iPhone,在用 Find X。
-
9
从需求分析到上手设计,如何快准狠?收好这3大秘籍 编辑: 土拨鼠
-
24
用了 Google 这么久,竟然不知道还有这些高级技巧 ...
-
7
《分析与思考:黄奇帆的复旦经济课》读书笔记 — 浮云的博客前几星期,看到网上有人说,黄奇帆之前在复旦上的公开课整理出书了。去微信读书找了一下,发现这本《分析与思考:黄奇帆的复旦经济课》,于是花了一些时间看完了这本书。 中国的官员,退休后写...
-
3
摘要:除了拥有 ClickHouse 本身的极致性能外,GaussDB(for MySQL)的HTAP只读分析在 MaterilizeMySQL引擎的性能和稳定性等方面具有更优秀的表现,为提供更快更准的数据分析保驾护航。 引言
-
7
首页 > 新闻 > 海外市场 乌克兰局势扑朔迷离,华尔街操盘手用了这些对冲策略 第一财经 2小时后 作者:李爱琳 责编:...
-
5
这些新功能让Windows 11文件管理器更好用了-51CTO.COM 这些新功能让Windows 11文件管理器更好用了 作者:cnBeta 2022-02-21 11:31:25 微软终于根据用户反馈重新回归了一项任务栏功能:将图像或者...
-
5
每年六月份,都是教育行业的旺季...
-
4
区县药店SKU优化,如何快准狠 转载 2023-03-20 02:12:49 阅 2.9w 3月19日,2023西鼎会进入次日议程,上午大会上,中康科技副总裁蒋炜女士带来了题为《区县药店SKU优化,如何快准狠》的精彩分享,就区县药店如何优化品类...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK