

深度解读HTTP的前世今生
source link: https://segmentfault.com/a/1190000040631005
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
深度解读HTTP的前世今生
HTTP的全名叫做超文本传输协议,是万维网所基于的应用层传输协议,建立之初,主要就是为了将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器。最初的版本是HTTP 0.9,是在80年的后期产生的,后面在1996年升级到了1.0。
但是到了 WEB2.0以来,我们的页面变得复杂,不仅仅单纯的是一些简单的文字和图片,同时我们的 HTML 页面有了 CSS,Javascript,来丰富我们的页面展示,当 ajax 的出现,我们又多了一种向服务器端获取数据的方法,这些其实都是基于 HTTP 协议的。同样到了移动互联网时代,我们页面可以跑在手机端浏览器里面,但是和 PC 相比,手机端的网络情况更加复杂,这使得我们开始了不得不对 HTTP 进行深入理解并不断优化过程中。所以在1997年出现了HTTP1.1,随后到2014年,HTTP1.1都一直都在更新。
然后到了2015年,为了适应快速发送的web应用和现代浏览器的需求,在Google的SPDY项目基础上发展出了新的HTTP2协议。
又过了4年,在2019年,Google又开发出了一个新的协议标准QUIC协议,它就是HTTP3的基石,其目的是为了提高用户与网站和API交互的速度和安全性。
HTTP1.0
早先的HTTP1.0版本,是一种无状态、无连接的应用层协议。
HTTP1.0规定浏览器和服务器保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器处理完成后立即断开TCP连接(无连接),服务器不跟踪每个客户端也不记录过去的请求(无状态)。
TCP建立连接时间 = 1.5RTT
- 一去 (
SYN)- 二回 (
SYN + ACK)- 三去 (
ACK)
RTT(Round Trip Time)是指通信一来一回的时间
这种无状态性可以借助cookie/session机制来做身份认证和状态记录。而下面两个问题就比较麻烦了。
理解这两个问题有一个十分重要的前提:客户端是依据域名来向服务器建立连接,一般PC端浏览器会针对单个域名的server同时建立6~8个连接,手机端的连接数则一般控制在4~6个
无法复用连接,每次请求都要经历三次握手和慢启动,三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求影响较大。
TCP连接会随着时间进行自我「调谐」,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐则被称为TCP慢启动。- 队头阻塞(
head of line blocking),由于HTTP1.0规定下一个请求必须在前一个请求响应到达之后才能发送。假设前一个请求响应一直不到达,那么下一个请求就不发送,同样的后面的请求也给阻塞了。
为了解决这些问题,HTTP1.1出现了。
HTTP1.1
对于HTTP1.1,不仅继承了HTTP1.0简单的特点,还克服了诸多HTTP1.0性能上的问题。
- 缓存处理,在
HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since,If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。 - 带宽优化及网络连接的使用,
HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。 - 错误通知的管理,在
HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。 - Host头处理,在
HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。 - 长连接(Persistent Connection),
HTTP1.1增加了一个Connection字段,通过设置Keep-Alive可以保持HTTP连接不断开,避免了每次客户端与服务器请求都要重复建立释放建立TCP连接,提高了网络的利用率。如果客户端想关闭HTTP连接,可以在请求头中携带Connection: false来告知服务器关闭请求。 - 管道化(Pipelining),基于
HTTP1.1的长连接,使得请求管线化成为可能。管线化使得请求能够“并行”传输。举个例子来说,假如响应的主体是一个html页面,页面中包含了很多img,这个时候keep-alive就起了很大的作用,能够进行“并行”发送多个请求。
这里的“并行”并不是真正意义上的并行传输,这是因为服务器必须按照客户端请求的先后顺序依次回送相应的结果,以保证客户端能够区分出每次请求的响应内容。
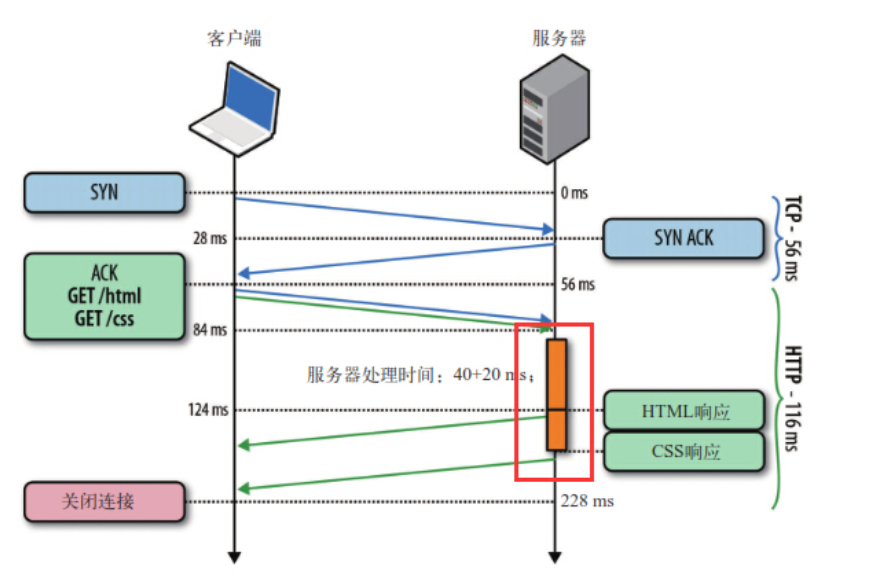
如图所示,客户端同时发了两个请求分别来获取html和css,假如说服务器的css资源先准备就绪,服务器也会先发送html再发送css。
换句话来说,只有等到html响应的资源完全传输完毕后,css响应的资源才能开始传输。也就是说,不允许同时存在两个并行的响应。
另外,pipelining还存在一些缺陷:
pipelining只能适用于http1.1,一般来说,支持http1.1的server都要求支持pipelining;- 只有幂等的请求(
GET,HEAD)能使用pipelining,非幂等请求比如POST不能使用,因为请求之间可能会存在先后依赖关系; - 绝大部分的
http代理服务器不支持pipelining; - 和不支持
pipelining的老服务器协商有问题; - 可能会导致新的
Front of queue blocking问题;
可见,HTTP1.1还是无法解决队头阻塞(head of line blocking)的问题。同时“管道化”技术存在各种各样的问题,所以很多浏览器要么根本不支持它,要么就直接默认关闭,并且开启的条件很苛刻...而且实际上好像并没有什么用处。
那我们在谷歌控制台看到的并行请求又是怎么一回事呢?
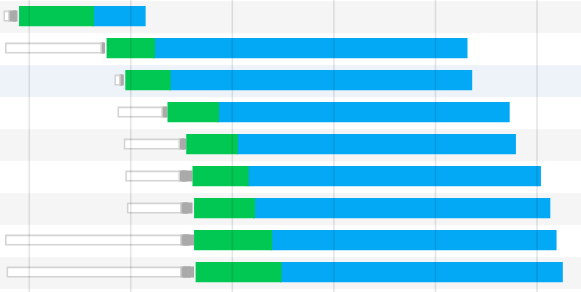
如图所示,绿色部分代表请求发起到服务器响应的一个等待时间,而蓝色部分表示资源的下载时间。按照理论来说,HTTP响应理应当是前一个响应的资源下载完了,下一个响应的资源才能开始下载。而这里却出现了响应资源下载并行的情况。这又是为什么呢?
其实,虽然HTTP1.1支持管道化,但是服务器也必须进行逐个响应的送回,这个是很大的一个缺陷。实际上,现阶段的浏览器厂商采取了另外一种做法,它允许我们打开多个TCP的会话。也就是说,上图我们看到的并行,其实是不同的TCP连接上的HTTP请求和响应。这也就是我们所熟悉的浏览器对同域下并行加载6~8个资源的限制。而这,才是真正的并行!
HTTP2.0
HTTP 2.0 的出现,相比于 HTTP 1.x ,大幅度的提升了 web 性能。在与 HTTP/1.1 完全语义兼容的基础上,进一步减少了网络延迟。而对于前端开发人员来说,无疑减少了在前端方面的优化工作。本文将对 HTTP 2.0 协议 个基本技术点进行总结,联系相关知识,探索 HTTP 2.0 是如何提高性能的。
初露锋芒
HTTP/2: the Future of the Internet 这是 Akamai 公司建立的一个官方的演示,用以说明 HTTP/2 相比于之前的 HTTP/1.1 在性能上的大幅度提升。 同时请求 379 张图片,从Load time 的对比可以看出 HTTP/2 在速度上的优势。

此时如果我们打开 Chrome Developer Tools 查看 Network一栏可以发现,HTTP/2 在网络请求方面与 HTTP /1.1的明显区别。
HTTP/1:

HTTP/2:

多路复用 (Multiplexing)
http1.1最初对同一个域名只支持2个tcp, 但是由于性能原因rfc后面又有修改到可以用6-8个。 此外,keep-alive用的是http pipelining本质上也是multiplexing, 但是由于会存在head of line blocking问题, 主流浏览器都默认禁止pipelining,而http2.0才真正的解决了hol问题
多路复用允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息。
众所周知 ,在 HTTP/1.1 协议中 「浏览器客户端在同一时间,针对同一域名下的请求有一定数量限制。超过限制数目的请求会被阻塞」。
Clients that use persistent connections SHOULD limit the number of simultaneous connections that they maintain to a given server. A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy. A proxy SHOULD use up to 2*N connections to another server or proxy, where N is the number of simultaneously active users. These guidelines are intended to improve HTTP response times and avoid congestion.
该图总结了不同浏览器对该限制的数目。

这也是为何一些站点会有多个静态资源 CDN 域名的原因之一,拿 Twitter 为例,http://twimg.com,目的就是变相的解决浏览器针对同一域名的请求限制阻塞问题。而 HTTP/2 的多路复用(Multiplexing) 则允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息。

因此 HTTP/2 可以很容易的去实现多流并行而不用依赖建立多个 TCP 连接,HTTP/2 把 HTTP 协议通信的基本单位缩小为一个一个的帧,这些帧对应着逻辑流中的消息。并行地在同一个 TCP 连接上双向交换消息。
二进制分帧
在不改动 HTTP/1.x 的语义、方法、状态码、URI 以及首部字段….. 的情况下, HTTP/2 是如何做到「突破 HTTP1.1 的性能限制,改进传输性能,实现低延迟和高吞吐量」的 ?
关键之一就是在 应用层(HTTP/2)和传输层(TCP or UDP)之间增加一个二进制分帧层。

在二进制分帧层中, HTTP/2 会将所有传输的信息分割为更小的消息和帧(frame),并对它们采用二进制格式的编码 ,其中 HTTP1.x 的首部信息会被封装到 HEADER frame,而相应的 Request Body 则封装到 DATA frame 里面。

下面是几个概念:
- 流(
stream):已建立连接上的双向字节流。 - 消息:与逻辑消息对应的完整的一系列数据帧。
- 帧(
frame):HTTP2.0通信的最小单位,每个帧包含帧头部,至少也会标识出当前帧所属的流(stream id)
HTTP/2 通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流。
每个数据流以消息的形式发送,而消息由一或多个帧组成。这些帧可以乱序发送,然后再根据每个帧头部的流标识符(stream id)重新组装。
举个例子,每个请求是一个数据流,数据流以消息的方式发送,而消息又分为多个帧,帧头部记录着stream id用来标识所属的数据流,不同属的帧可以在连接中随机混杂在一起。接收方可以根据stream id将帧再归属到各自不同的请求当中去。
另外,多路复用(连接共享)可能会导致关键请求被阻塞。HTTP2.0里每个数据流都可以设置优先级和依赖,优先级高的数据流会被服务器优先处理和返回给客户端,数据流还可以依赖其他的子数据流。
可见,HTTP2.0实现了真正的并行传输,它能够在一个TCP上进行任意数量HTTP请求。而这个强大的功能则是基于“二进制分帧”的特性。
总结:
- 单连接多资源的方式,减少服务端的链接压力,内存占用更少,连接吞吐量更大
- 由于
TCP连接的减少而使网络拥塞状况得以改善,同时慢启动时间的减少,使拥塞和丢包恢复速度更快
首部压缩(Header Compression)
HTTP/1.1并不支持 HTTP 首部压缩,为此 SPDY 和 HTTP/2 应运而生, SPDY 使用的是通用的DEFLATE 算法,而 HTTP/2 则使用了专门为首部压缩而设计的 HPACK 算法。

在HTTP1.x中,头部元数据都是以纯文本的形式发送的,通常会给每个请求增加500~800字节的负荷。
比如说cookie,默认情况下,浏览器会在每次请求的时候,把cookie附在header上面发送给服务器。(由于cookie比较大且每次都重复发送,一般不存储信息,只是用来做状态记录和身份认证)
HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。高效的压缩算法可以很大的压缩header,减少发送包的数量从而降低延迟。
服务端推送(Server Push)
服务端推送是一种在客户端请求之前发送数据的机制。在 HTTP/2 中,服务器可以对客户端的一个请求发送多个响应。Server Push 让 HTTP1.x 时代使用内嵌资源的优化手段变得没有意义;如果一个请求是由你的主页发起的,服务器很可能会响应主页内容、logo 以及样式表,因为它知道客户端会用到这些东西。这相当于在一个 HTML 文档内集合了所有的资源,不过与之相比,服务器推送还有一个很大的优势:可以缓存!也让在遵循同源的情况下,不同页面之间可以共享缓存资源成为可能。

HTTP3
HTTP/3 现在还没正式推出,不过自 2017 年起, HTTP/3 已经更新到 34 个草案了,基本的特性已经确定下来了,对于包格式可能后续会有变化。
所以,这次 HTTP/3 介绍不会涉及到包格式,只说它的特性。

美中不足的 HTTP/2
HTTP/2 通过头部压缩、二进制编码、多路复用、服务器推送等新特性大幅度提升了 HTTP/1.1 的性能,而美中不足的是 HTTP/2 协议是基于 TCP 实现的,于是存在的缺陷有三个。
- 队头阻塞;
TCP与TLS的握手时延迟;- 网络迁移需要重新连接;
HTTP/2 多个请求是跑在一个 TCP 连接中的,那么当 TCP 丢包时,整个 TCP 都要等待重传,那么就会阻塞该 TCP 连接中的所有请求。
因为 TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且有序的,如果序列号较低的 TCP 段在网络传输中丢失了,即使序列号较高的 TCP 段已经被接收了,应用层也无法从内核中读取到这部分数据,从 HTTP 视角看,就是请求被阻塞了。

TCP 与 TLS 的握手时延迟
发起 HTTP 请求时,需要经过 TCP 三次握手和 TLS 四次握手(TLS 1.2)的过程,因此共需要 3 个 RTT 的时延才能发出请求数据。

另外, TCP 由于具有「拥塞控制」的特性,所以刚建立连接的 TCP 会有个「慢启动」的过程,它会对 TCP 连接产生"减速"效果。
网络迁移需要重新连接
一个 TCP 连接是由四元组(源 IP 地址,源端口,目标 IP 地址,目标端口)确定的,这意味着如果 IP 地址或者端口变动了,就会导致需要 TCP 与 TLS 重新握手,这不利于移动设备切换网络的场景,比如 4G 网络环境切换成 WIFI。
这些问题都是 TCP 协议固有的问题,无论应用层的 HTTP/2 在怎么设计都无法逃脱。要解决这个问题,就必须把传输层协议替换成 UDP,这个大胆的决定,HTTP/3 做了!


QUIC 协议的特点
我们深知,UDP 是一个简单、不可靠的传输协议,而且是 UDP 包之间是无序的,也没有依赖关系。
而且,UDP 是不需要连接的,也就不需要握手和挥手的过程,所以天然的就比 TCP 快。
当然,HTTP/3 不仅仅只是简单将传输协议替换成了 UDP,还基于 UDP 协议在「应用层」实现了 QUIC 协议,它具有类似 TCP 的连接管理、拥塞窗口、流量控制的网络特性,相当于将不可靠传输的 UDP 协议变成“可靠”的了,所以不用担心数据包丢失的问题。
QUIC 协议的优点有很多,这里举例几个,比如:
- 无队头阻塞;
- 更快的连接建立;
- 连接迁移;
无队头阻塞
QUIC 协议也有类似 HTTP/2 Stream 与多路复用的概念,也是可以在同一条连接上并发传输多个 Stream,Stream 可以认为就是一条 HTTP 请求。
由于 QUIC 使用的传输协议是 UDP,UDP 不关心数据包的顺序,如果数据包丢失,UDP 也不关心。
不过 QUIC 协议会保证数据包的可靠性,每个数据包都有一个序号唯一标识。当某个流中的一个数据包丢失了,即使该流的其他数据包到达了,数据也无法被 HTTP/3 读取,直到 QUIC 重传丢失的报文,数据才会交给 HTTP/3。
而其他流的数据报文只要被完整接收,HTTP/3 就可以读取到数据。这与 HTTP/2 不同,HTTP/2 只要某个流中的数据包丢失了,其他流也会因此受影响。
所以,QUIC 连接上的多个 Stream 之间并没有依赖,都是独立的,某个流发生丢包了,只会影响该流,其他流不受影响。

更快的连接建立
对于 HTTP/1 和 HTTP/2 协议,TCP 和 TLS 是分层的,分别属于内核实现的传输层、openssl 库实现的表示层,因此它们难以合并在一起,需要分批次来握手,先 TCP 握手,再 TLS 握手。
HTTP/3 在传输数据前虽然需要 QUIC 协议握手,这个握手过程只需要 1 RTT,握手的目的是为确认双方的「连接 ID」,连接迁移就是基于连接 ID 实现的。
但是 HTTP/3 的 QUIC 协议并不是与 TLS 分层,而是QUIC 内部包含了 TLS,它在自己的帧会携带 TLS 里的“记录”,再加上 QUIC 使用的是 TLS1.3,因此仅需 1 个 RTT 就可以「同时」完成建立连接与密钥协商,甚至在第二次连接的时候,应用数据包可以和 QUIC 握手信息(连接信息 + TLS 信息)一起发送,达到 0-RTT 的效果。
如下图右边部分,HTTP/3 当会话恢复时,有效负载数据与第一个数据包一起发送,可以做到 0-RTT:

在前面我们提到,基于 TCP 传输协议的 HTTP 协议,由于是通过四元组(源 IP、源端口、目的 IP、目的端口)确定一条 TCP 连接,那么当移动设备的网络从 4G 切换到 WIFI 时,意味着 IP 地址变化了,那么就必须要断开连接,然后重新建立连接,而建立连接的过程包含 TCP 三次握手和 TLS 四次握手的时延,以及 TCP 慢启动的减速过程,给用户的感觉就是网络突然卡顿了一下,因此连接的迁移成本是很高的。
而 QUIC 协议没有用四元组的方式来“绑定”连接,而是通过连接 ID来标记通信的两个端点,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要仍保有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感,达到了连接迁移的功能。
HTTP/3 协议
了解完 QUIC 协议的特点后,我们再来看看 HTTP/3 协议在 HTTP 这一层做了什么变化。
HTTP/3 同 HTTP/2 一样采用二进制帧的结构,不同的地方在于 HTTP/2 的二进制帧里需要定义 Stream,而 HTTP/3 自身不需要再定义 Stream,直接使用 QUIC 里的 Stream,于是 HTTP/3 的帧的结构也变简单了。


从上图可以看到,HTTP/3 帧头只有两个字段:类型和长度。
根据帧类型的不同,大体上分为数据帧和控制帧两大类,HEADERS 帧(HTTP 头部)和 DATA 帧(HTTP 包体)属于数据帧。
HTTP/3 在头部压缩算法这一方便也做了升级,升级成了 QPACK。与 HTTP/2 中的 HPACK 编码方式相似,HTTP/3 中的 QPACK 也采用了静态表、动态表及 Huffman 编码。
对于静态表的变化,HTTP/2 中的 HPACK 的静态表只有 61 项,而 HTTP/3 中的 QPACK 的静态表扩大到 91 项。
HTTP/2 和 HTTP/3 的 Huffman 编码并没有多大不同,但是动态表编解码方式不同。
所谓的动态表,在首次请求-响应后,双方会将未包含在静态表中的 Header 项更新各自的动态表,接着后续传输时仅用 1 个数字表示,然后对方可以根据这 1 个数字从动态表查到对应的数据,就不必每次都传输长长的数据,大大提升了编码效率。
可以看到,动态表是具有时序性的,如果首次出现的请求发生了丢包,后续的收到请求,对方就无法解码出 HPACK 头部,因为对方还没建立好动态表,因此后续的请求解码会阻塞到首次请求中丢失的数据包重传过来。
HTTP/3 的 QPACK 解决了这一问题,那它是如何解决的呢?
QUIC 会有两个特殊的单向流,所谓的单项流只有一端可以发送消息,双向则指两端都可以发送消息,传输 HTTP 消息时用的是双向流,这两个单向流的用法:
- 一个叫
QPACK Encoder Stream, 用于将一个字典(key-value)传递给对方,比如面对不属于静态表的HTTP请求头部,客户端可以通过这个 Stream 发送字典; - 一个叫
QPACK Decoder Stream,用于响应对方,告诉它刚发的字典已经更新到自己的本地动态表了,后续就可以使用这个字典来编码了。
这两个特殊的单向流是用来同步双方的动态表,编码方收到解码方更新确认的通知后,才使用动态表编码 HTTP 头部。
HTTP/2 虽然具有多个流并发传输的能力,但是传输层是 TCP 协议,于是存在以下缺陷:
- 队头阻塞,
HTTP/2多个请求跑在一个TCP连接中,如果序列号较低的TCP段在网络传输中丢失了,即使序列号较高的TCP段已经被接收了,应用层也无法从内核中读取到这部分数据,从 HTTP 视角看,就是多个请求被阻塞了; TCP和TLS握手时延,TCL三次握手和TLS四次握手,共有3-RTT的时延;- 连接迁移需要重新连接,移动设备从
4G网络环境切换到WIFI时,由于TCP是基于四元组来确认一条TCP连接的,那么网络环境变化后,就会导致IP地址或端口变化,于是TCP只能断开连接,然后再重新建立连接,切换网络环境的成本高;
HTTP/3 就将传输层从 TCP 替换成了 UDP,并在 UDP 协议上开发了 QUIC 协议,来保证数据的可靠传输。
QUIC 协议的特点:
- 无队头阻塞,
QUIC连接上的多个Stream之间并没有依赖,都是独立的,也不会有底层协议限制,某个流发生丢包了,只会影响该流,其他流不受影响; - 建立连接速度快,因为
QUIC内部包含TLS1.3,因此仅需 1 个RTT就可以「同时」完成建立连接与TLS密钥协商,甚至在第二次连接的时候,应用数据包可以和QUIC握手信息(连接信息 +TLS信息)一起发送,达到0-RTT的效果。 - 连接迁移,
QUIC协议没有用四元组的方式来“绑定”连接,而是通过「连接ID」来标记通信的两个端点,客户端和服务器可以各自选择一组ID来标记自己,因此即使移动设备的网络变化后,导致IP地址变化了,只要仍保有上下文信息(比如连接ID、TLS密钥等),就可以“无缝”地复用原连接,消除重连的成本;
另外 HTTP/3 的 QPACK 通过两个特殊的单向流来同步双方的动态表,解决了 HTTP/2 的 HPACK 队头阻塞问题。
下图来自又拍云,表示 HTTP/2 和 HTTP/3 多路复用两个请求时,数据包丢失及其影响:
HTTP/2 多路复用 2 个请求。响应被分解为多个数据包,一旦一个数据包丢失了,两个请求都被阻止
HTTP/3 复用 2 个请求。虽然浅色的数据包丢失了,但是深色的数据包传输得很好。

参考:
[HTTP1.0 HTTP1.1 HTTP2.0 主要特性对比](https://segmentfault.com/a/11...)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK