

分布式消息流平台:不要只想着Kafka,还有Pulsar
source link: https://my.oschina.net/u/4526289/blog/5237927
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
摘要:Pulsar作为一个云原生的分布式消息流平台,越来越频繁地出现在人们的视野中,大有替代Kafka江湖地位的趋势。
本文分享自华为云社区《MRS Pulsar:下一代分布式消息流平台全新发布!》,作者: Lothar。
Pulsar的前世今生
Apache Pulsar是一个发布-订阅消息系统,使用计算与存储分离的云原生架构。Pulsar 2018年9月成为ASF顶级项目,近两年,随着社区不断发展和诸多企业的应用和贡献,Pulsar作为一个云原生的分布式消息流平台,越来越频繁地出现在人们的视野中,大有替代Kafka江湖地位的趋势。
Pulsar和Kafka的对比
Pulsar和Kafka架构上最大的不同是,Kafka由Broker进行消息的收发和持久化,数据存储在本地文件系统,由Broker统一管理。这也意味着数据和消息处理是耦合的。
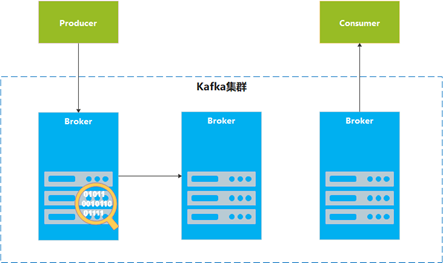
Kafka官网描述道:Kafka重度依赖文件系统,用于存储或缓存消息。当Broker接收到消息时,会将消息追加写到本地磁盘上。这一架构决定了Partition和Broker的对应关系是相对固定的,只有在partition reassign时才会发生数据迁移。Partition的Leader在数据副本分布节点上产生,用于处理生产消费请求。
而Pulsar采用了计算存储分离架构,这也是Pulsar被称作云原生平台的主要原因。Pulsar依赖Apache BookKeeper管理持久化数据,Apache BookKeeper是可扩展、可容错、低延迟的日志存储服务,能够保证在强持久性下的低延迟读写。
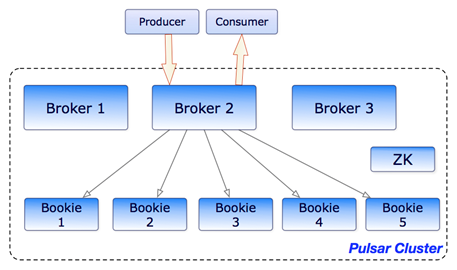
*引自Pulsar官网介绍:https://pulsar.apache.org/docs/en/concepts-architecture-overview/
Broker接收请求后,数据实际分布式存储在BookKeeper服务中。在数据的物理存储模型中某个Topic或Partition的数据并不固定存储在某个Bookie实例上。
Pulsar将分布式日志划分为多个Segment,每个Segment对应BookKeeper中的一个Ledger。与Kafka将某一Partition的数据日志保存在某一固定目录下不同,Pulsar通过划分Segment的方式,可以将同一topic或partition分布到不同的Bookie上。
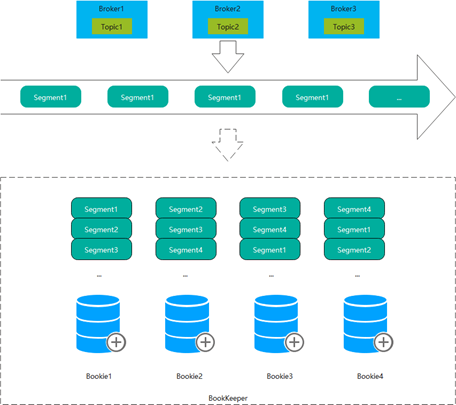
Pulsar的优势特性
相信很多使用Kafka的客户都有类似的经历:
- 磁盘空间不足,只能调整数据TTL,或扩容机器后向新的Broker中迁移Partition
- Topic或Partition间数据分配不均匀,节点之间或磁盘之间使用不均衡,有的磁盘已经满了,而有的磁盘还有很多空间
- Broker机器故障,需要将数据迁移到其他节点后下电维修
Pulsar的存算分离架构天然地避免了这些问题。Pulsar Broker本身是无状态的,当某个Broker故障时,另一个Broker可以立即接管对应的Topic而不需要迁移数据。BookKeeper分布式日志保证了存储节点间的数据均衡,不会因某一个Partitoin或Topic数据过多而导致IO集中在某一节点上。
当集群需要扩容时,Broker可以立即感知到新加入集群的Bookie,并将新写入的数据存储到新添加的Bookie中。
Kafka社区在KIP-37正在讨论加入NameSpace以实现多租户特性,而Pulsar已实现这一功能。在企业中,消息队列服务通常会被多个团队使用,在使用Kafka时,有时需要为每个团队维护一个Kafka集群。Pulsar可以配置多个租户,每个租户可以有多个NameSpace,管理员可以对NameSpace进行访问控制、配额管理。
更灵活的订阅模式
Kafka对消息的划分分为两层:对于属于同一个Group的KafkaConsumer,其获取到的消息是互斥的,即某一条消息只能被Group中的一个Consumer处理;对于不同的Group,某一条消息将同时被两个Group处理,消息是共享的。
而Pulsar提供了更灵活的订阅模式:
在任意时间,Topic中的数据只能被Group中的一个Consumer消费,不允许其他Consumer获取消息
多个Consumer同时消费同一个Topic时,只有一个Consumer被选为主Consumer,其他Consumer则成为备Consumer。当主Consumer故障时,发生主备倒换,备Consumer中的一个将升主,并继续消息的消费。
与Kafka类似,使用共享模式,消息将循环分发给不同的Consumer,当某个Consumer故障时,消息将被重新分配给其他Consumer。
Pulsar另一个很有吸引里的特性是,流式数据可以转冷并存储在更廉价的存储介质上。通常为了保证性能,流式处理系统配备高性能的SSD。对于Kafka来说,所有需要保留的消息都必须驻留在昂贵的SSD上。有些时候,数据写入一段时间后已不在会被使用,但仍需保留一段时间存档。Pulsar支持将这种冷数据转储到离线存储系统中,BookKeeper只需要保留一部分热数据,可以节省很多存储成本。该特性无疑是很有价值的,Kafka社区同样在进行设计(KIP-405),但目前还没有实现。
Pulsar的性能指标
Kafka和Pulsar社区都针对性能进行了对比测试。综合来看,由于Pulsar数据落盘时,会进行同步fsync,持久性要比Kafka更高,Pulsar社区对此作出修改后进行对比测试,部分测试结果如下:
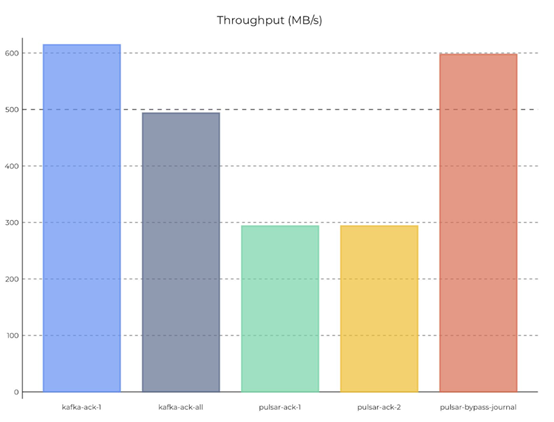
*引自Pulsar社区性能测试报告
在100 Partition时,默认配置下pulsar的吞吐量距离Kafka差距明显,但当本地持久化等级设置为与Kafka相同时,吞吐量与Kafka基本持平。
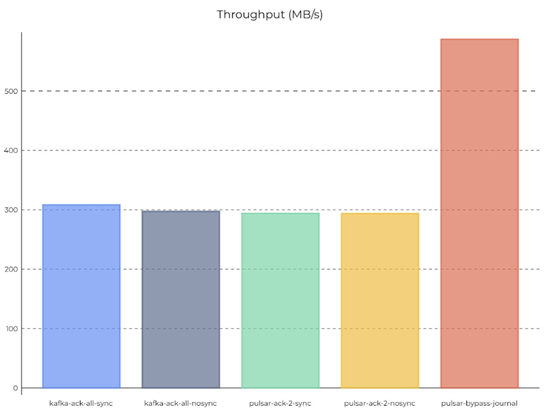
*引自Pulsar社区性能测试报告
当Partition数增加到2000个时,Pulsar默认本地持久度的吞吐量基本与Kafka持平。
更多细节请移步SreamNative的benckmarking测试报告:benchmarking pulsar kafka a more accurate perspective on pulsar performance.pdf
MRS上的Pulsar
MRS已发布Pulsar的POC版本,客户可以一键式部署Pulsar服务,包括Broker和Bookie角色。支持在Web UI上修改Pulsar配置、启停、监控。
此外MRS还默认集成了KoP。KoP是Pulsar社区开源的一个插件,运行在Pulsar上,用以兼容Kafka协议。使用时,Kafka客户端可以修改连接地址后直接切换到Pulsar集群上,而不需要修改业务对Kafka客户端的依赖。
在MRS Pulsar的商用版本正在规划中,我们将探索Pulsar在云上使用的更多可能,进一步发挥Pulsar存算分离的优势,降低成本,提升资源利用率,为客户创造更多价值,敬请期待。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK