

腾讯Angel Graph团队刷新GNN最强榜单OGB世界纪录!
source link: https://my.oschina.net/u/4956788/blog/5219657
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
腾讯Angel Graph团队刷新GNN最强榜单OGB世界纪录!

导读 / Introduction
近日,在国际顶级图学习标准OGB(Open Graph Benchmark)挑战赛中,腾讯大数据Angel Graph团队联合北京大学-腾讯协同创新实验室,以较大优势在三个最大的OGB分类数据集:ogbn-papers100M、ogbn-products和ogbn-mag三项任务榜单第一!

OGB是目前公认最权威的图学习通用性能评价基准数据集,由斯坦福大学Jure Leskovec教授团队建立并开源,并吸引了斯坦福大学、康奈尔大学、Facebook、NVIDIA、百度、阿里巴巴和字节跳动等国际顶尖高校与科技巨头参与。该数据集来源广泛——涵盖了生物网络、分子图、学术网络和知识图谱等领域,且囊括了基本的节点预测、边预测、图预测等图学习任务,数据真实、极具挑战性,素有图神经网络领域“ImageNet”之称,已成为全球图神经网络研究者检验自身功力的“试剑石”。
一、问题背景
图结构数据广泛存在于现实生活中。如图1所示,在推荐系统中可以用图来表示用户与商品之间的交互、在社交网络和知识图谱中图可以来表示各个用户或者实体之间的关系,图还可以用来建模各种药物和新材料。随着深度学习的兴起,研究者开始将深度学习应用到图数据,推动了图领域的相关研究蓬勃发展。作为图领域的重要的技术手段,图神经网络(GNN)已经成为解决图问题的重要算法,并受到了学术界和工业界的广泛关注。
图1 常见的图数据类型
二、技术难点
尽管GNN在多个应用场景中取得了巨大的成功,在工业界的大规模数据集上使用GNN还是存在着以下两个问题:
1. 可扩展性低
1.1 单机的存储问题 (High Memory Cost)
传统的GNN层中包含两个操作,特征传播和非线性变换。其中,特征传播操作涉及一个较大的稀疏邻接矩阵和特征矩阵的乘法,需要花费较多的时间;而且,如果在训练时使用GPU加速,那么就必须把稀疏邻接矩阵放置到GPU的显存上,但这一需求对于大图来说是无法被满足的。比如,OGB节点分类数据集中最大的ogbn-papers100M数据集的稀疏邻接矩阵大小超过50GB,目前仅有80GB显存版本的Tesla A100才能存下,而这还不包括存储特征和模型的空间。因此,如果要想在超大规模的图上应用传统的GNN模型,如GCN[1],目前唯一可行的方法是使用分布式训练。
1.2 分布式训练的通信问题 (High Communication Cost)
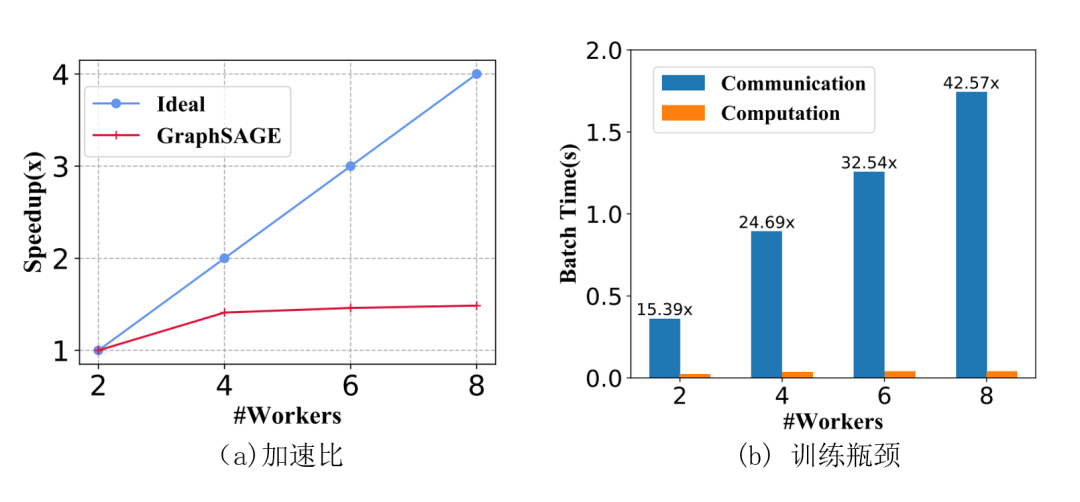
图2 增加worker数量时两层GraphSAGE的加速比和训练瓶颈
GNN的每一次特征传播都需要拉取邻居特征,对于k层的GNN来说,每个节点需要拉取的k跳以内邻居节点特征随着层数增加以指数增加。对于稠密的连通图,每个节点在每次训练的时候几乎需要拉取全图的节点信息,造成海量的通信开销。尽管有一些采样算法能缓解这个问题,但并不能很好地解决。我们以两层的GraphSAGE[2]为例,图2(a) 显示当增加workers数量之后加速比和理想情况下相差甚远,这是因为当图节点被切分到多个workers上后需要去不同workers节点上拉取邻居的频率也显著增加。如图2(b) 所示,随着workers数量增加,通信开销会明显大于计算开销。因此,如何支持超大规模图数据的分布式训练一直是一个研究热点。
2. 灵活性差 (Low Flexibility)
2.1 约束非线性变换深度恒等于特征传播深度
如图3所示,对于常见的耦合的图神经网络,它在每一层中都强制要求非线性变换紧接着特征传播,去掉特征传播后GCN就退化为MLP。我们之前对深层GNN的评测工作[3]表明,图神经网络存在着两种深度:特征传播的深度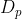 和非线性变换的深度
和非线性变换的深度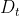 ,他们分别导致了GNN里的过平滑以及模型退化问题。另外,这个工作还指出我们在图稀疏(标签、特征或者边稀疏)的时候需要增大,在图规模较大的时候需要增大。假设图稀疏且规模较小,这个时候我们需要大的和小的,强行约束
,他们分别导致了GNN里的过平滑以及模型退化问题。另外,这个工作还指出我们在图稀疏(标签、特征或者边稀疏)的时候需要增大,在图规模较大的时候需要增大。假设图稀疏且规模较小,这个时候我们需要大的和小的,强行约束 会造成次优效果。
会造成次优效果。
图3 GCN和MLP的关系示意
2.2 没有考虑节点特异性
图4 感受野扩展速度的示例
图5 不同节点的预测准确性和特征传播步数的关系
我们通过一个简单的示例来说明这个问题。图4中有1个被标蓝的节点并位于图中相对稠密的区域,而绿色节点位于图中相对稀疏的区域。同样进行2次特征传播操作,可以看到位于稠密区域的蓝色节点的感受野已经相对较大了,而位于稀疏区域的绿色节点的感受野却只包含了3个节点。这个实例形象地说明了不同节点的感受野的扩张速度存在较大的差异。在GNN中,一个节点感受野的大小表示它能捕获邻域信息的多少,感受野太大,则该节点可能会捕获许多不相关节点的信息,感受野太小,则该节点无法捕获足够的邻域信息得到高质量的节点表示。因此,对于不同特征传播步数的节点特征,GNN模型需要对不同的节点自适应地分配权重。否则,便会出现无法兼顾位于稠密区域和稀疏区域节点的情况,导致最后无法得到高质量的节点表示。
为了验证我们的猜想,我们在常用的Citeseer数据集的验证集和测试集上随机挑选了20个点,在不同的特征传播步数下,使用SGC[4]模型进行节点分类测试,记录连续运行的100次中预测正确的次数占总的次数的比例,实验结果展现在图5中。从实验结果中,我们可以看到不同节点的预测准确率随特征传播步数的增加而变化的趋势并不相同。部分节点,如节点10,在传播步数为1时达到了预测准确率的最大值,随后预测准确率不断降低;而另有部分节点,如节点4,的预测准确率则随特征传播步数的增加而不断增加。这种强烈的差异性验证了我们的猜想,即在对不同传播步数的节点特征做加权求和时,应该给予不同的权重。
三、Scalable GNN调研
Sampling:采样是最常见的扩展图神经网络的方法,它也被广泛应用于多个分布式图神经网络系统里,比如PyG[5],DGL[6] 以及AliGraph[7]。从采样算法的种类来看,它又可以分为三种:基于图的采样(如GraphSAGE[2]和VR-GCN[8]),基于层的采样(如FastGCN[9]和AS-GCN[10]),以及基于节点的采样(如Cluster-GCN[11]和GraphSAINT[12])。由于采样和本工作的优化方向是两个不同的方向,因此在这里不再赘述。
Model Decoupling:近期,有研究指出[4],GNN的性能主要归功于各个层中的特征传播操作,而不是非线性变换操作。由此催生出了一系列解耦的GNN,他们在设计GNN模型时解耦了特征传播操作和非线性变换操作,在预处理时就预先做完所有的特征传播操作,在模型训练时就不必再费时费力地去传播特征。因此,在可扩展性方面,只要能够在预处理时完成特征传播操作中的稀疏矩阵稠密矩阵乘法,后续的模型训练可以很轻松地在单机单卡上进行。由于特征传播操作是在预处理过程中完成,因此不需要利用GPU进行加速,完全可以仅使用CPU进行矩阵乘法操作。在我们的实验中,在ogbn-papers100M这个亿级规模的数据集上做特征传播,需要大概250GB的内存,这一需求相比于50GB的显存来说容易满足得多。将传统GNN模型中的特征传播和非线性变换操作解耦的设计既大大提升了模型的可扩展性,也大大提升了模型的效率。
但大多数解耦的GNN在训练时没有区分不同节点的特异性。比如在k层的SGC[4]中,所有的节点都只考虑第k个步数的特征。S2GC[13]和SIGN[14]虽然考虑到了不同特征传播步数的节点特征表示, 但他们只是对这些特征做平均或者拼接,这样当步数过大的时候依然会出现过平滑的问题。另外,在目前的SOTA解耦GNN模型GBP[15]中,作者首先利用特征传播操作得到不同传播步数的特征矩阵,然后使用一个人为设计的权重,对这些特征矩阵做加权求和。虽然GBP能够较好地利用不同特征传播步数的节点特征表示,但它没有考虑到不同节点之间存在的特异性,只是简单地给予所有的节点相同的权重进行求和。和我们的想法类似,SAGN[16]也提出用注意力机制给不同节点的不同权重来融合各个步数的传播特征,但我们还额外考虑到了模型退化以及不同注意力机制的影响。此外,还有一类解耦的模型是先做非线性变换后做特征传播,比如APPNP[17],AP-GCN[18]和DAGNN[19]。相较于APPNP,AP-GCN和DAGNN都考虑到了不同节点的特异性,但它们在每个epoch都需要拉取邻居节点做完非线性变换后的表征,不能像前一类解耦方法一样预处理好所有的特征传播操作,因此他们还是面临着可扩展性低的问题。
四、图注意力多层感知器(Graph Attention MLP)
我们的模型分为2个分支:(1)如图6所示,第一分支在预处理时得到不同特征传播步数的节点特征,并使用注意力机制为不同的节点分配不同的权重,最终通过加权求和的方式得到融合特征矩阵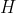 。此外,初始残差连接(Initial Residual)也被用来解决深层MLP带来的模型退化问题;(2)第二分支在预处理时对训练集节点标签应用标签传播算法,将训练集节点标签信息扩展到全图,得到经
。此外,初始残差连接(Initial Residual)也被用来解决深层MLP带来的模型退化问题;(2)第二分支在预处理时对训练集节点标签应用标签传播算法,将训练集节点标签信息扩展到全图,得到经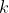 步传播的标签矩阵
步传播的标签矩阵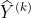 。这两个分支的结果和分别输入两个不同的MLP,并将两个MLP的结果简单相加,得到模型最终的低维节点嵌入
。这两个分支的结果和分别输入两个不同的MLP,并将两个MLP的结果简单相加,得到模型最终的低维节点嵌入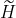 。在损失函数的选择方面,我们的模型使用了节点分类问题常用的交叉熵损失函数。
。在损失函数的选择方面,我们的模型使用了节点分类问题常用的交叉熵损失函数。
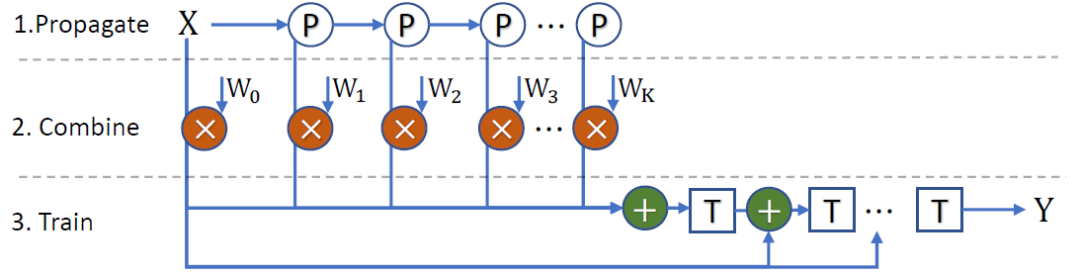
图6 GAMLP特征分支示意图
4.1 三种不同的注意力机制
为了能够让图中的每个节点都能自适应选择不同感受野的特征,我们设计了3种不同类型的注意力机制来自适应地为不同的节点分配针对不同特征传播步数的节点特征的不同权重。它们的差别主要在于参考向量的选择:
-
平滑注意力机制(Smoothing):把经无穷次传播的节点特征
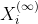 作为参考向量
作为参考向量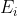 。在实际计算的时候有公式可以直接带入数值求解,并不需要真的进行无穷次特征传播。该注意力机制希望能够学习到不同传播步数的节点特征相对于的距离,并用这个距离来指导权重的选择。
。在实际计算的时候有公式可以直接带入数值求解,并不需要真的进行无穷次特征传播。该注意力机制希望能够学习到不同传播步数的节点特征相对于的距离,并用这个距离来指导权重的选择。 -
递归注意力机制(Recursive):使用递归计算的方式,在计算赋予经
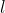 步传播的节点特征
步传播的节点特征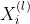 的权重时,把前
的权重时,把前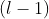 步的融合节点特征作为参考向量。该注意力机制希望能够学习到相比前步的融合节点特征的信息增益,并用这个信息增益来指导权重的选择。
步的融合节点特征作为参考向量。该注意力机制希望能够学习到相比前步的融合节点特征的信息增益,并用这个信息增益来指导权重的选择。 -
知识跳跃注意力机制(JK):如图7所示,我们把预处理阶段得到的所有经特征传播的节点特征全都按列拼接起来,并让这个向量过一个MLP,以MLP的输出结果作为参考向量
。该注意力机制中的参考向量包含了所有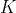 个经特征传播的节点特征矩阵中的信息,该注意力机制希望能够学习到不同传播步数的节点特征相对于大向量的重要性,并用这个重要性来指导权重的选择。
个经特征传播的节点特征矩阵中的信息,该注意力机制希望能够学习到不同传播步数的节点特征相对于大向量的重要性,并用这个重要性来指导权重的选择。
得到参考向量以后,使用常规的注意力计算机制计算赋予经步传播的节点特征的权重:
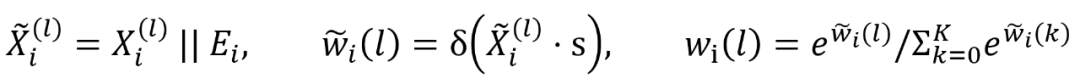
其中 是可学习的向量,
是可学习的向量,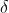 在我们的模型中为sigmoid函数。
在我们的模型中为sigmoid函数。
在得到了每个节点针对不同特征传播步数的权重以后,我们通过加权求和的方式得到最终的融合特征矩阵。
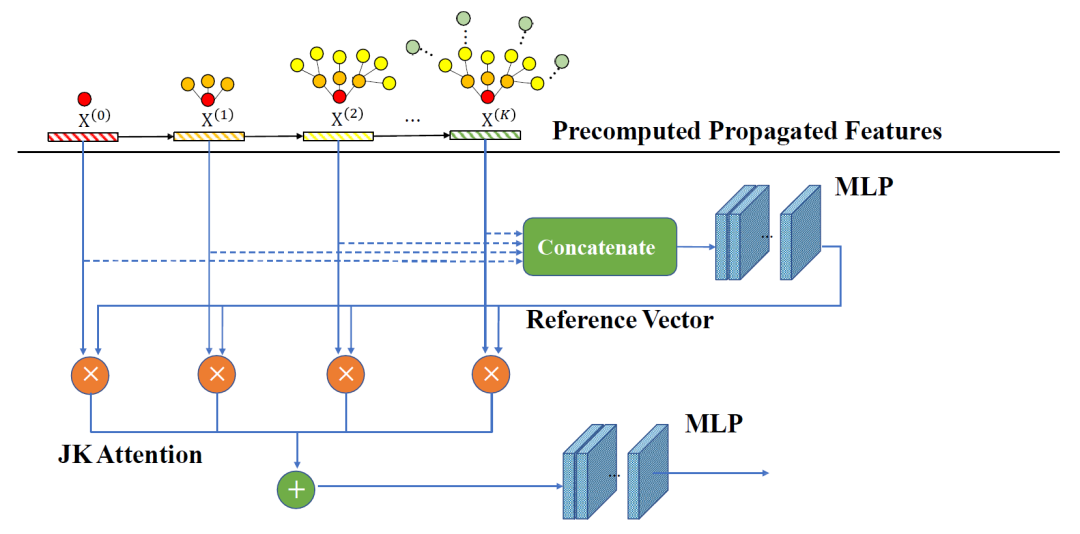
图 7 知识跳跃注意力机制的图示
4.2 利用训练集标签信息
为了充分利用训练集节点的信息,我们在模型训练过程中不仅将训练集标签用于损失函数的计算,同时也让它们作为节点的另一维度的特征参与模型的前向。具体来说,我们使用标签传播算法(Label Propagation),将训练集节点标签的信息传播到全图,得到经过标签传播算法传播了步的节点标签矩阵。
4.3 模型训练
在进行模型训练时,我们将融合特征矩阵和节点标签矩阵分别过两个不同的MLP,并将结果相加,得到最终的节点低维嵌入。其中,我们为融合特征矩阵设计的MLP层数较深,并添加了原始节点特征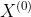 的跳跃连接,以此来减轻模型退化问题对深层神经网络的负作用;而为节点标签矩阵设计的MLP层数较浅,主要作用是为了让映射到融合特征矩阵所在的空间。在训练时,我们使用了常规的针对节点分类问题的交叉熵损失函数。
的跳跃连接,以此来减轻模型退化问题对深层神经网络的负作用;而为节点标签矩阵设计的MLP层数较浅,主要作用是为了让映射到融合特征矩阵所在的空间。在训练时,我们使用了常规的针对节点分类问题的交叉熵损失函数。
4.4 RLU(Reliable Influence Utilization),可信的标签利用
为了进一步提升我们模型的性能,我们把整个训练过程分为几个连续的阶段,前一个训练阶段的预测结果能够为后一训练阶段提供额外的输入特征和监督信号。可信的标签利用首先要求确定一个高置信度节点集合,我们在这里设置一个超参数 作为阈值,如果前一个训练阶段的预测结果中,该节点的所属类的预测概率大于阈值,那么这个节点就被添加到高置信度节点集合中。
作为阈值,如果前一个训练阶段的预测结果中,该节点的所属类的预测概率大于阈值,那么这个节点就被添加到高置信度节点集合中。
值得注意的是,我们在筛选的时候只在验证集和测试集节点中挑选,因为训练集中的节点在训练过程中已经有强力的真实标签信息的指导。对前一个训练阶段高置信度节点预测结果的利用在我们的模型中分为两部分。
第一部分是对模型第二分支的输入特征的加强。从第二个阶段开始,我们将高置信度节点的软预测结果填入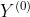 矩阵中。这样一来,我们最终得到的中便加入了前一训练阶段模型的高置信度节点的预测信息,对输入特征做了增强。
矩阵中。这样一来,我们最终得到的中便加入了前一训练阶段模型的高置信度节点的预测信息,对输入特征做了增强。
第二部分是在模型训练过程中的加强。从第二个阶段开始,我们在模型前向时,同时输入训练集节点和前一个训练阶段的高置信度节点,训练集节点仅参与交叉熵损失函数的计算,而针对这些高置信度节点,我们计算当前模型的输出与前一训练阶段对这些节点的软预测结果的KL散度。
该新增的KL散度损失函数是为了将前一个训练阶段对这些高置信度节点的预测信息蒸馏到当前的模型中,增强当前模型对这些节点的预测能力,提升模型在验证集和测试集上的预测准确性。在3个大型数据集上的结果表明我们加入的可信的标签利用机制能够有效地提升模型在验证集和测试集上的性能。
五、实验结果
5.1 数据集描述
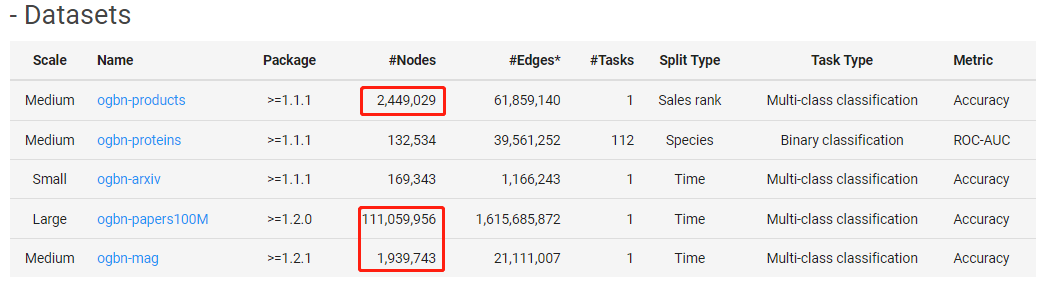
此次,腾讯参与了OGB三个赛道里挑战难度最大、竞争最激烈的节点性质预测任务。另外,ogbn-papers100M、ogbn-products和ogbn-mag也是该赛道5个数据集里规模最大的前三项,极具业务价值。其中,ogbn-papers100M是已知的最大的开源图数据集,拥有超过1.1亿个节点和16亿条边,ogbn-mag是该赛道里最大的异构图。
5.2 实验结果分析
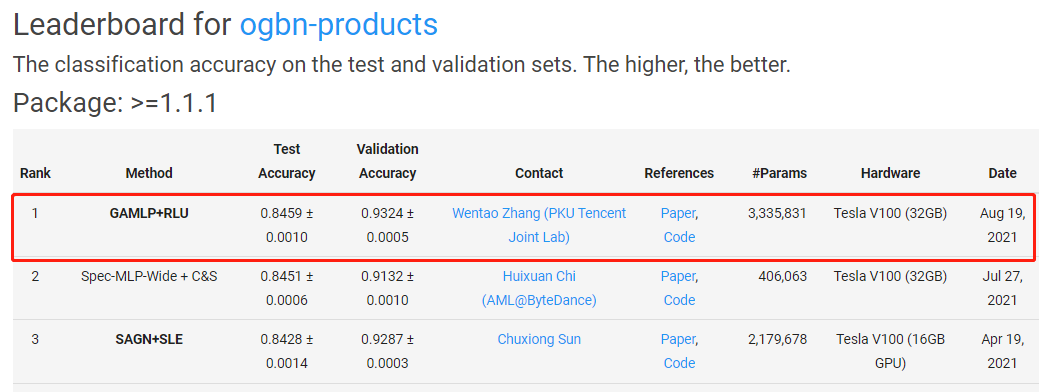
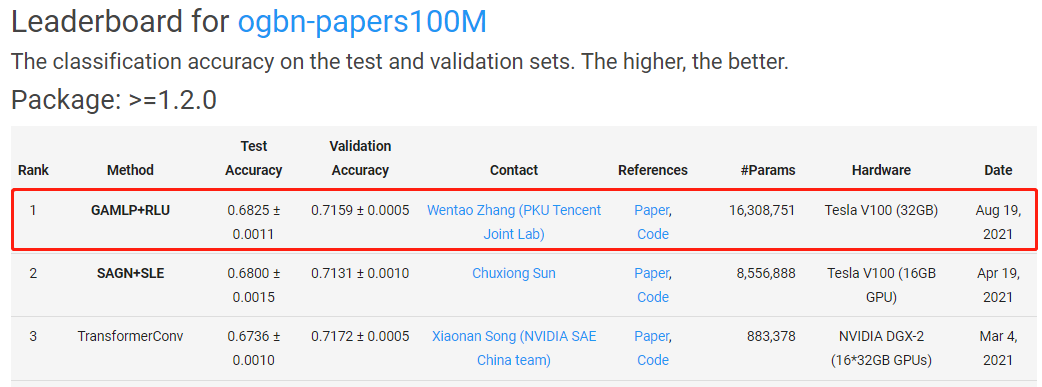
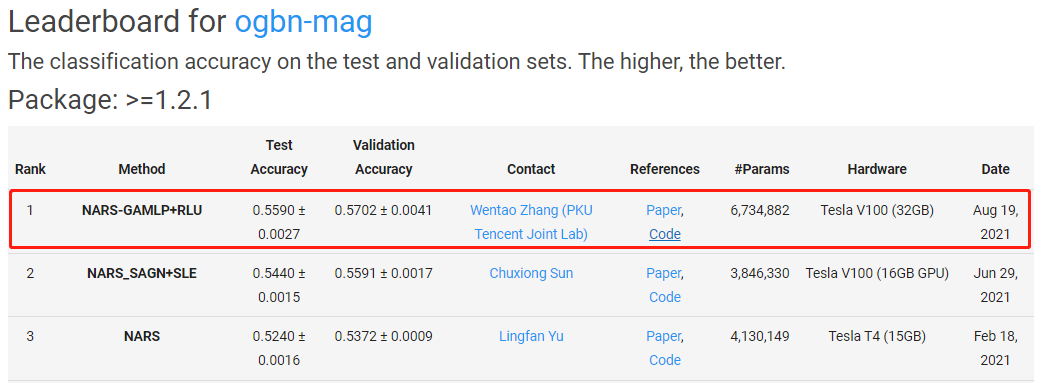
可以看到,我们提出的GAMLP+RLU在三个最大的OGB分类数据集上均取得了Top #1的成绩。特别的,我们在异构图ogbn-mag上的性能显著超过第二名,领先优势达到1.5%。
六、应用前景
6.1 解决大规模图训练问题
和SGC类似,我们提出的GAMLP使得单机可以训练超过一亿节点和十亿边的超大规模图数据。在分布式训练过程中,我们没有拉取特征的通信开销,只需要交换训练过程中的梯度信息。随着worker数量的增加,可以达到和MLP类似的加速比,非常适合工业界的超大规模图数据应用场景。
6.2 解决图稀疏问题
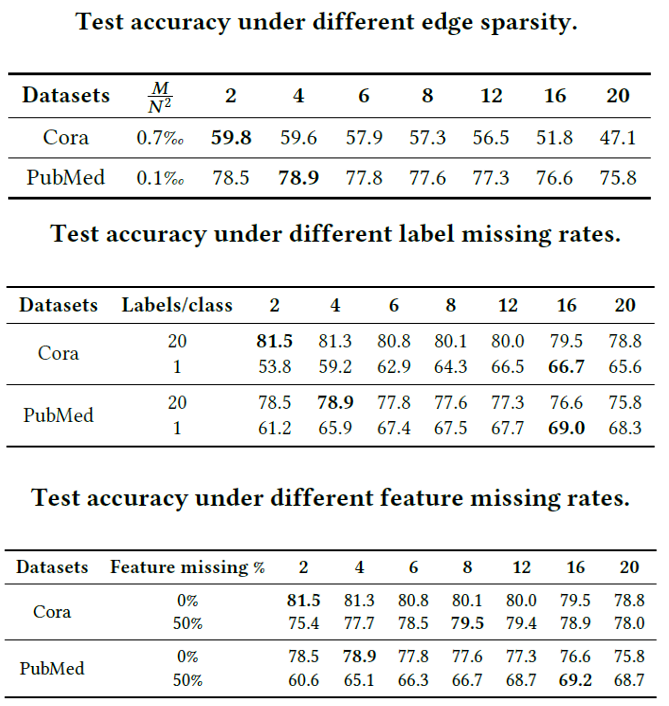
图8 不同深度SGC随着feature/edge/label 稀疏的表现
我们提出的GAMLP非常适合真实世界中广泛存在的图稀疏场景。如我们先前的深层GNN评测工作[3]里的图7所示, 当图存在特征稀疏(如推荐里某些新用户没有特征信息),标签稀疏(很多节点没有标签)以及边稀疏(图里的边极少)的时候,我们更需要深的图结构信息,而GAMLP就能够通过给不同特征传播步数的节点特征分配权值来间接调整最适合每个节点的深度。
七、关于我们
7.1 Angel Graph图计算团队
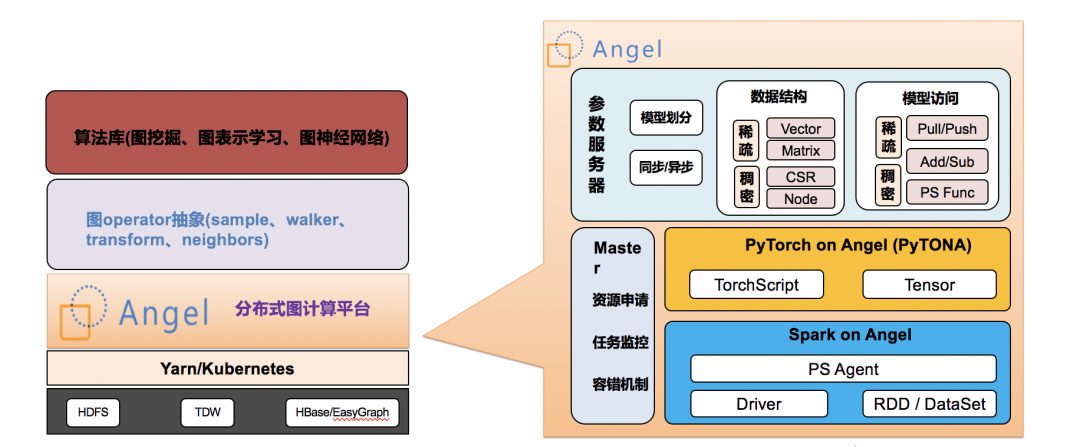
图9 Angel Graph系统架构图
Angel Graph是腾讯自研的高性能图计算框架, 吸收了Angel参数服务器、Spark以及PyTorch优势,使得传统图计算、图表示学习和图神经网络“三位一体”,实现了高性能、高可靠、易用的大规模分布式图计算框架。
Angel Graph有以下核心能力:
-
复杂异构网络。工业界的图数据组成复杂多样,数据规模往往具有十亿级顶点、百亿甚至千亿级边。Angel Graph通过Spark On Angel或Pytorch进行分布式训练,可以轻松支持十亿级顶点、千亿级边的大规模图计算。
-
端到端的图计算。工业界的大数据生态多为Spark、Hadoop。Angel Graph基于Spark On Angel的架构,可以无缝衔接Spark,以便利用Spark 的ETL能力,支持端到端的图学习。
-
传统图挖掘。支持十亿级顶点、千亿级边的传统图算法,如Kcore、PageRank分析节点重要性,Louvain进行社区发现等。提供对顶点的测度分析和丰富的图特征,以便应用到机器学习或推荐风控等业务模型中。
-
图表示学习。支持十亿级顶点,千亿级边的Graph Embedding算法,如LINE、Word2Vec等。
-
图神经网络。支持十亿级顶点,数百亿边的图神经网络算法,利用顶点或边上丰富的属性信息进行深度学习。
7.2 北京大学-腾讯协同创新实验室
北京大学-腾讯协同创新实验室成立于2017年,主要在人工智能、大数据等领域展开前沿探索和人才培养,打造国际领先的校企合作科研平台和产学研用基地。
协同创新实验室通过合作研究,在理论和技术创新、系统研发和产业应用方面取得重要成果和进展,已在国际顶级学术会议和期刊发表学术论文20余篇,除合作研发Angel外,实验室还自主开发了多个开源系统,例如:
黑盒优化系统OpenBox
https://github.com/PKU-DAIR/open-box
AutoML系统Mindware
https://github.com/PKU-DAIR/mindware
分布式深度学习系统Hetu
https://github.com/PKU-DAIR/Hetu
详细了解GAMLP,请访问下方链接地址↓
GAMLP论文:
https://arxiv.org/abs/2108.10097
GAMLP代码:
https://github.com/PKU-DAIR/GAMLP
Angel项目代码:
https://github.com/Angel-ML/angel
本工作将很快部署在Angel Graph上,届时欢迎大家试用!
参考资料:
[1] Thomas N. Kipf, and Max Welling. Semi-Supervised Classification with Graph Convolutional Networks. ICLR 2017.
[2] Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representationlearning on large graphs. In NIPS. 1024–1034.
[3] Zhang W, Sheng Z, Jiang Y, et al. Evaluating Deep Graph Neural Networks[J]. arXiv preprint arXiv:2108.00955, 2021.
[4] Felix Wu, Tianyi Zhang, Amauri Holanda de Souza Jr., Christopher Fifty, Tao Yu, and Kilian Q. Weinberger. Simplifying graph convolutional networks. ICML 2019.
[5] Fey, Matthias and Lenssen, Jan E. Fast Graph Representation Learning with {PyTorch Geometric. ICLR workshop 2019.
[6] Wang M, Yu L, Zheng D, et al. Deep Graph Library: Towards Efficient and Scalable Deep Learning on Graphs[J]. 2019.
[7] R. Zhu, K. Zhao, H. Yang, W. Lin, C. Zhou, B. Ai, Y. Li, and J.Zhou,“Aligraph: A comprehensive graph neural network platform,”Proc. VLDB Endow., vol. 12, no. 12, p. 2094–2105, Aug. 2019.
[8] J. Chen, J. Zhu, and L. Song. Stochastic training of graph convolutional networks with variance reduction. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018.
[9] J. Chen, T. Ma, and C. Xiao. Fastgcn: Fast learning with graph convolutional networks via importance sampling. In 6th International Conference on Learning Representations, ICLR 2018.
[10] W. Huang, T. Zhang, Y. Rong, and J. Huang. Adaptive sampling towards fast graph representation learning. In NIPS 2018.
[11] W.-L. Chiang, X. Liu, S. Si, Y. Li, S. Bengio, and C.-J. Hsieh. Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks. In SIGKDD 2019.
[12] H. Zeng, H. Zhou, A. Srivastava, R. Kannan, and V. K. Prasanna. Graphsaint: Graph sampling based inductive learning method. In ICLR 2020.
[13] H. Zhu and P. Koniusz. Simple spectral graph convolution. In ICLR, 2021.
[14] E. Rossi, F. Frasca, B. Chamberlain, D. Eynard, M. Bronstein, and F. Monti. Sign: Scalable inception graph neural networks. arXiv preprint arXiv:2004.11198, 2020.
[15] Ming Chen, Zhewei Wei, Bolin Ding, Yaliang Li, Ye Yuan, Xiaoyong Du, Ji-Rong Wen. Scalable Graph Neural Networks via Bidirectional Propagation. NeurIPS 2020.
[16] Sun C, Wu G. Scalable and Adaptive Graph Neural Networks with Self-Label-Enhanced training[J]. arXiv preprint arXiv:2104.09376, 2021.
[17] J. Klicpera, A. Bojchevski, and S. Günnemann. Predict then propagate: Graph neural networks meet personalized pagerank. In ICLR 2019.
[18] I. Spinelli, S. Scardapane, and A. Uncini. Adaptive propagation graph convolutional network. 355 IEEE Transactions on Neural Networks and Learning Systems, 2020.
[19] M. Liu, H. Gao, and S. Ji. Towards deeper graph neural networks. In SIGKDD 2020.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK