

Paper read: Designing Access Methods: The RUM Conjecture
source link: https://zhuanlan.zhihu.com/p/404352955
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Paper read: Designing Access Methods: The RUM Conjecture
这篇论文主要提出了RUM猜想(Conjecture),宏观角度、概述性质的介绍了已有的存储引擎是如何映射到RUM思想上的。
1. INTRODUCTION
Access methods包括read times (R),update cost (U), memory (or storage) overhead (M),也就是RUM三个字母的缩写。为了minimize RUM overheads,提出RUM猜想(Conjecture):在Read, Update, Memory三者之间找平衡 – 优化二者必然以牺牲第三方为代价 Optimize Two at the Expense of the Third。
Designing access methods that set an upper bound for two of the RUM overheads, leads to a hard lower bound for the third over head which cannot be further reduced.
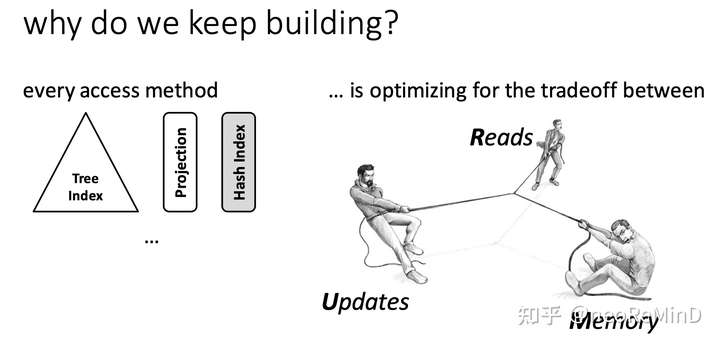
RUM形成的三角形tradeoff,有时候可以优化到某个点,让三者都达到某种程度的最优(个人认为类似帕累托最优Pareto Optimality,虽然不能鱼与熊掌兼得,但是只要有付出,总可以取得某个相对最优解)。比如block-based clustered indexing (有点类似clickhouse MergeTree,全局有序,靠稀疏索引来加速主键order by key的点查和范围查),再有compression in bitmap indexes。
RUM-aware access method design的思想在于提供versatile tool来满足不同workload, application, hardware 条件下的access methods tradeoff,而不是创造一个universal best access methods,因为这是不存在的。
2. THE RUM OVERHEADS
2.1 Read Overhead (RO) 定义
定义索引相关的数据叫做auxiliary data,数据本身叫做base data。那么RO就是读放大(amplification)。
RO = amount of auxiliary and base data read / amount of retrieved data.
比如MySQL B+Tree,走二级索引查询,就是先走二级索引B+Tree,然后再反查主键B+Tree取数据的read overhad。
2.2 Update Overhead (UO) 定义
UO = the size of the physical updates performed for one logical update / the size of the logical update.
2.3 Memory Overhead (MO) 定义
存储auxiliary data的space overhead,即空间放大。
2.4 Minimizing RUM overheads 案例
举例来说,假设一个数组按照block粒度切分。
- Minimizing Only RO
blkId = value,稀疏数组,可以通过索引定位数据,read最佳,同时先empty old blk再insert new value,时间复杂度常数项2,空间消耗很大
min(RO) = 1.0 ⇒ UO = 2.0 and MO → ∞
- Minimizing Only UO
每次update都写增量log,读和空间放大。
min(UO) = 1.0 ⇒ RO → ∞ and MO → ∞
- Minimizing Only MO
no auxiliary data,full scan read
min(MO) = 1.0 ⇒ RO = N and UO = 1.0
3. THE RUM CONJECTURE
An access method that can set an upper bound for two out of the read, update, and memory overheads, also sets a lower bound for the third overhead.
4. RUM IN PRACTICE
论文通过列举场景的工业界以及学术界的存储设计,来映射到RUM三角形里面,如下图。
- Read-optimized access methods
B-Trees [22], Tries [19], Prefifix B-Trees [9], and Skiplists [45]
- Write-optimized differential structures
基本思想是consolidate updates and apply them in bulk to the base data。
Log-structured Merge Tree [44], the Partitioned B-tree (PBT) [21], the Materialized Sort-Merge (MaSM) algorithm [7, 8], the Stepped Merge algorithm [35], and the Positional Differential Tree [28]. LA-Tree [3] and FD-Tree [38] 。
- Space-effificient access methods
Bloom fifilters [12], lossy hash-based indexes like count-min sketches [16], bitmaps with lossy encoding [51], and approximate tree indexing [5, 40]. Sparse indexes, which are light-weight secondary indexes, like ZoneMaps [18], Small Materialized Aggregates [42] and Column Imprints [50]
- Adaptive access methods
位于三角形中间区域,提供参数来调整RUM tradoff,包括Database Cracking [31, 32, 33, 48], Adaptive Merging [22, 25], and Adaptive Indexing [23, 24, 26, 34]。
上面提到的数据结构在附录中都有引用,可以查阅。
下图展示了不同数据结构在各个场景下的时间复杂度。
- The Memory Hierarchy
上面的分析都基于同一种存储介质的假设,实际场景中数据会在内存,NVM,SSD或者机械硬盘上,如果数据都存在cache中(内存,甚至CPU cache中)性能表现会完全不一样,在做access methods的设计时候不能忽视这一点。
下面这些数据结构对内存中数据做了特殊的优化,包括Fractal Prefetching B+-Trees [15],Cache sensitive B+-Trees [47], SB-Trees [43],BW-Tree [37] and Masstree [41] ,SILT [39]。
5. BUILDING RUM ACCESS METHODS
这个章节主要还是介绍如何平衡RUM tradoff,做到tunnable,dynamic的设计,不再赘述。
这篇论文是16年的,从概念角度针对access methods,提出了RUM猜想(Conjecture),旨在宏观上来指导存储引擎设计中要意识到读R、更新U、空间M三者的tradeoff,并且举了很多实际的数据结构来佐证,大家处于哪个象限。未来的趋势是要兼顾硬件分层、不同场景要求,来实现能调优和自适应的access methods,即RUM-aware access methods。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK