

什么是DevOps?谷歌开展DevOps的SRE方法介绍!
source link: https://my.oschina.net/u/4763244/blog/5198606
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
DevOps这个概念已实施多年,但是在业界不同公司的实施程度落差很大,走在前面的公司可以玩的很熟练的,有的还不知道什么叫DevOps。
定义:DevOps是什么?
根据维基百科的定义:DevOps是过程、方法和系统的统称,促进Development、Opeartion和QA部门间的沟通、协作与整合。
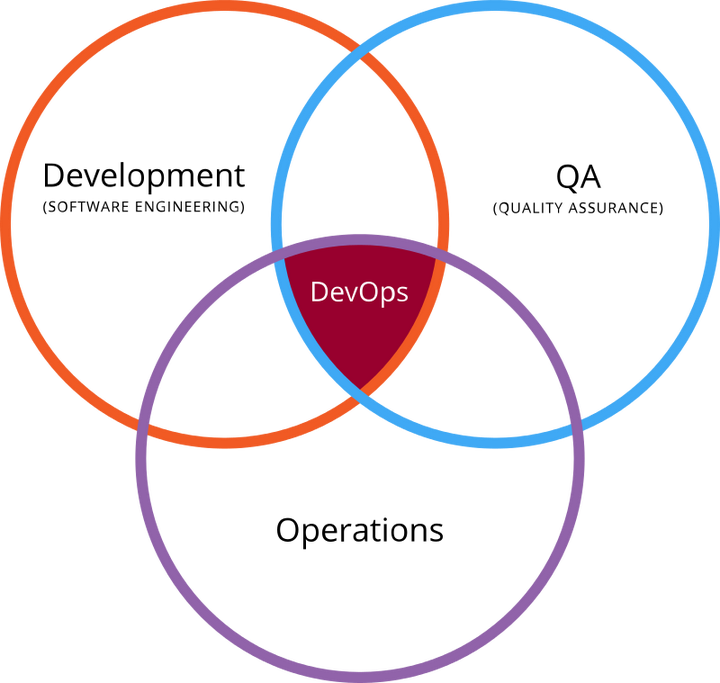
DevOps示意图,来源:维基百科
为什么要DevOps?
随着公司持续成长,系统的规模、功能、复杂度、事件与更新次数变多,有很多额外的工作,必须要手动处理回应各项事件。
而公司通常在应用程序的发展中,分开发和运维,有些会有测试部门,而开发与运维部门由不同背景、技能、目标和激励措施不同,容易产生冲突。
- 开发:我做了个超炫的功能,什么时候可以上线?
- 运维:不要停机,不要更新,不要挂掉
如果程序发生了重大错误时间,就会变成这样:
- 开发:都是你没上新版,新版已经解决了这个bug
- 运维:你还敢说,上个月那一版,部署完网站就挂了
- 开发:可是我在电脑上是好的!
这种情况发生在任何角落,不仅仅在开发和运维上,也就是我们所说的“谷仓效应”
简单说就是各部门之间变成孤岛,发生冲突之后,部门之间互不信任,使用各种措施阻碍对方:
- 维运:根据以前发生过的错误,准备一连串的 Checklist。
- 开发:强调这不是改版,是微调,可以直接上。
部门间从合作变成互相角力,拖慢了整个系统开发流程。
同样的事情发生在 Google ,而 Google 又怎麽解决这样的问题呢?
2003年成立 SRE Team (Site Reliability Engineering) ,组成如下:
- 50%~60% 纯软件工程师。
- 40%~50% SRE软件工程师(网站可靠性工程师)。
SRE 软件工程师必须要:
- 建一个系统來执行运维的人工操作
Google 规定, SRE 只能花50%的时间做 ticket、on call、人工操作,超过 50% 的部分,指派给开发团队负责。
所以开发团队则是要:
- 如果 SRE 太忙,要帮忙分担工作
所以 SRE 除了做运维,也要写运维的程序,而开发团队除了写产品的程序,也要做运维。==>>产生交叉培训。
也带來了其他好处:
- 系统变大变复杂,却不需雇佣更多人。
- 软件更新速度保持不变。
- 软件不用停机就可以直接进行修改。
什么时候导入DevOps?
那什么时候要导入 DevOps 呢?只要有以下症状,都可以考虑看看:
- 开发部门无法在开发早期侦测软件缺陷
- 无法确定问题出现在哪一个部门
- 人为错误经常发生
- 只要部署出去, Dev 就认为工作完成
- 问题发生,相互指责
如何导入DevOps?SRE导入方法
那要如何导入 DevOps 呢?五大原则如下:
- 接受失败(Failure),视失败为开发周期中的一个元素
- 减少组织之间的仓谷效应
- 善用工具和自动化
- 任何事都是可以被量测的
1.接受失败(Failure)
就像我们去考试一样,从90分进步到99分比较容易,还是从99分进步到100分比较容易?
Google 的解释是这样的,为了达到 SLA (Service Level Agreements)100%,中间有太多不可抗力因素,例如从你的应用程序传信息要先到电信商的基地台,中间可能已经是99.9%的 SLA ,再从基地台传到你的手机可能又是99.9的 SLA ,这里都还没算到你开发的应用程序可用性, SLA 就已经是98.9%了,那你要怎麽做到100%?
先买下电信商,再买下那支手机的制造商,然后请超厉害的工程师把APP写到100分?然后呢?你做到 SLA 100%了,客户感受到你0.1%的进步吗?客户愿意为了你0.1%的进步而多付100万吗?
我们回过头来讲错误预算,直白一点的意思是“在没有超过约定好的中断时间之下,我们有多少时间可以拿来做一些创新的尝试”。所以错误预算可以:
- 培养不究责的文化 Blamelessness => 以利事后调查
- 允许犯错 => 鼓励创新
- 用来承担 Launch 的风险 => 做到快速 Launch
这看起来有没有像我们学生时代,老师对我们的教诲,不要怕犯错,Try and Error?
现在呢?多做多错,少做少错,不做不错。欢迎来到大人的世界。大人讲的都是对的吗?官越大,越正确,你不知道吗?(怨念好深……)
是的,现在是团队合作的社会,为了不造成别人麻烦,或怕被惩罚,或是怕犯错变成别人攻击的对象,我们总是避免犯错。为了避免犯错,我们就不再创新了。枪打出头鸟啊~ DevOps 第一条原则就把我们的脸打得好肿。
2.减少仓谷效应-infrastructure as a code
就是尽可能让环境,用统一规管的格式或设定档(例如 yaml 档)来部署,而不是人为去设定网络和服务器等:
- 让开发/测试/生产环境长得几乎一模一样,提早发现错误
- 可以被版本控制工具所管理 (如 git),这代表任何的改变都有迹可寻
- 减少人工所产生的错误
- 达成自动化
这样如果一套程序在开发环境run不起来,在测试或生产环境一样run不起来,要发现错误容易的多,大家一起来看 yaml 档就好了。而且谁做错全部的人都知道,不用推责任给别人,也不用故意放大检视他人,大家心里知道就好,犯错的人也会默默检讨,毋需指责。
3.持续改善 – 使用 CI/CD
什么意思?谁不会持续改善,每个人都会不是吗?听起来好像废话。
这里讲的持续可以用“渐进”来解释,以前系统要改进,可能是收集完使用者回馈的100项缺点,一口气全部改完再给使用者,就跟瀑布模式的系统开发流程一样,常常要交付给使用者时才发现跟原始的需求不一样。
所以这里强调的是,只要修正一个点,就交付给用户测试看看,测试OK再改下一个。这里用到的具体做法就是 CI/CD,注意CD有两种:
- 持续整合 Continuous Integration
持续验证开发结果 ,小部分小部分地尽早确认,期望产出符合需求,或依据产出进行快速修正。
- 建置 (build)
- 测试 (test)
- 程序码分析 (source code analysis)
- 持续交付 Continuous Delivery
- 发行到测试环境,确保软体持续保持在随时可以释出的状况。
- 持续部署 Continuous Deployment
- 自动部署到生产环境。
自动化 – 减少手动
什么是手动呢?手动的特征如下:
- 手动执行 script、开关机、上新版程序
- 对每个新客户进行的重复性工作
- 没有永久的价值(长期的改善)
因为这些工作是不断重复的,因为重复就会感到单调,因为单调做起来就觉得很没劲,甚至厌烦,久了甚至会忽视,不专心地做这些事情,这样出错的机率反而就会提高。
我曾经在以前的某个公司,也做过某件明明对公司就非常重要,却没有人重视也没有人关心的手动,刚好有一次工作太忙,又觉得自己做很多次自以为熟悉,就忽略了一两个检查步骤,然后好死不死就刚好系统有问题没检查到,造成最后一条龙的流程全部受到影响,并且要全部重来,最后在检讨会议上给别人盯着看~
所以自动化说有多重要就有多重要,并且搭配渐进式部署 (Progressive Rollout)
- 一次发布一点点变动,并且针对少量使用者发布,每次的变动都可以密切地监控效能是否有什么影响。
- 快速准确地发现问题。
- 出现问题时安全地回滚更改。
- 只要错误减少,产品交付就会加快。
任何事都是可以被量测的
这一点是跟 CI/CD 最大的差异之处,它强调的重点如下:
- 监控是追踪系统健康和可用性最好的方法
- 如果必须要有人阅读电子邮件, 并判断是否需要采取行动的系统,从根本上是有缺陷的。
- 只有一定要采取行动的时候,系统才发出通知。
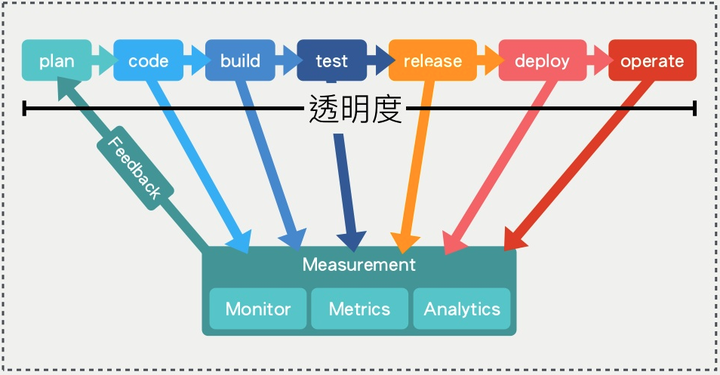
透明监控达成资讯透明
跟之前「减少谷仓效应」的概念类似,就是要让所有事情都透明化,所以才需要监控这个关键步骤,这样发生任何事,都能快速找到原因,而不是浪费时间在那边跟别人吵架。
以上提到的实施方法,就是 Google 提出的 SRE (Site Reliability Engineering) 概念。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK