

使用 Python 自动识别防疫二维码
source link: https://blog.yuanpei.me/posts/1509692610/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
使用 Python 自动识别防疫二维码
这个月月初的时候,朋友兴奋地和我描述着他的计划——准备带孩子到宁夏自驾游。朋友感慨道,“小孩只在书本上见过黄河、见过沙漠,这样的人生多少有一点遗憾”,可正如新冠病毒会变异为德尔塔一样,生活里唯一不变的变化本身,局部地区疫情卷土重来,朋友为了孩子的健康着想,不得不取消这次计划,因为他原本就想去宁夏看看的。回想过去这一年多,口罩和二维码,是每天打交道最多的东西。也许,这会成为未来几年里的常态。在西安,不管是坐公交还是地铁,都会有人去检查防疫二维码,甚至由此而创造了不少的工作岗位。每次看到那些年轻人,我都有种失落感,因为二十九岁高龄的我,已然不那么年轻了,而这些比我更努力读书、学历更高的年轻人,看起来在做着和学历/知识并不相称的工作。也许,自卑的应该是我,因为国家刚刚给程序员群体定性——新生代农民工。可是,我这个农民工,今天想做一点和学历/知识相称的事情,利用 Python 来自动识别防疫二维码。
对于防疫二维码而言,靠肉眼去看的话,其实主要关注两个颜色,即标识健康状态的颜色和标识疫苗注射状态的颜色。与此同时,为了追踪人的地理位置变化,防疫/安检人员还会关注地理位置信息,因此,如果要自动识别防疫二维码,核心就是读出其中的颜色以及文字信息。对于颜色的识别,我们可以利用 OpenCV 中的 inRange() 函数来实现,只要我们定义好对应颜色的 HSV 区间即可;对于文字的识别,我们可以利用 PaddleOCR 库来进行提取。基于以上原理,我们会通过 OpenCV 来处理摄像头的图像,只要我们将手机二维码对准摄像头,即可以完成防疫二维码的自动识别功能。考虑到检测不到二维码或者颜色识别不到这类问题,程序中增加了蜂鸣报警的功能。写作本文的原因,单纯是我觉得这样好玩,我无意借此来让人们失业。可生而为人,说到底不能像机器一样活着,大家不都追求有趣的灵魂吗?下面是本文中使用到的第三方 Python 库的清单:
- pyzbar == 0.1.8
- opencv-contrib-python == 4.4.0.46
- opencv-python == 4.5.3.56
- paddleocr == 2.2.0.2
- paddlepaddle == 2.0.0
下面是一张从手机上截取的防疫二维码图片,从这张图片中我们看出,整个防疫二维码,可以分为三个部分,即:上方的定位信息图块,中间的二维码信息图块,以及下方的核酸检验信息图块。

对于二维码的检测,我们可以直接使用 pyzbar 这个库来解析,可如果直接对整张图进行解析,因为其中的干扰项实在太多,偶尔会出现明明有二维码,结果无法进行解析的情况。所以,我们可以考虑对图片进行切分,而切分的依据就是图中的这三个图块。这里,我们利用二值化函数 threshold() 和 轮廓提取函数 findContours() 来实现图块的检测:
# 灰度化 & 二值化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 135, 255, cv2.THRESH_BINARY)
# 检测轮廓,获得对应的矩形
contours = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2]
for i in range(len(contours)):
block_rect = cv2.boundingRect(contours[i])
这里有一个感触颇深的地方,在检测图块的过程中,博主发现中间和底部这两个图块,其检测要更为简单一点,因为它有明显的边界、属于规则的矩形,而上方的图块,因为带有装饰性的纹理,以及灰色的过渡区,二值化并不能检测到其边缘,如下图所示,地铁上使用的二维码,相比商场里使用的二维码,轮廓线要更为清晰一点。所以,这里选择一个什么样的阈值来做二值化,个人感觉是需要反复去尝试的。考虑到要兼容这种轮廓不规则的图块,实际上我使用了一点小技巧,即:在得到下面两个图块以后,利用高度的换算关系,人为地生成上方图块的矩形范围。

那么,这是否说明,代表美的设计,在代表绝对理性的算法面前,其实更像是一种噪音。也许,它们各自的领域不同、观点不同,可都一样在为这个世界发光发热,生活不止一种真相,世界不止一种回声,有微小的差异,同样有宏大的统一。
二维码检测
好了,我们可以注意到,一旦完成图块的切分,此时,二维码位于中间这个图块,检测二维码在这里并不是重点,因为检测这个二维码是第一步,按照这个二维码所在的矩形去检测中心的的色彩,这是这里的重点,因为这个二维码解析以后就是一个 URL 地址,本身并没有包含任何信息,我们想要知道一个人是否健康,唯一的办法就是检测中间的色彩。其实,理论上剩余两个图块同样需要检测色彩,可考虑到三者在含义的表达上是一致的,即三者拥有相同的颜色,我们只需要处理其中一个即可。下面是利用 pyzbar 库对二维码区块进行解析,获取二维码信息、二维码所在的矩形等信息的代码片段:
# 检测二维码
def detect_qrcode(image, block):
block_image, block_rect, _ = block
block_x, block_y, _, _ = block_rect
gray = cv2.cvtColor(block_image, cv2.COLOR_BGR2GRAY)
qrcodes = decode(gray, [ZBarSymbol.QRCODE])
if len(qrcodes) > 0:
qrcode = qrcodes[0]
qrcodeData = qrcode.data.decode("utf-8")
x, y, w, h = qrcode.rect
abs_x = block_x + x
abs_y = block_y + y
cv2.rectangle(image, (abs_x, abs_y), (abs_x + w, abs_y + h), color_marker, 2)
return True, qrcodeData, (abs_x, abs_y, w, h)
else:
return False, None, None
可以注意到,通过 pyzbar 这个库,我们不单单可以获取到二维码的信息,同时还可以获得二维码在图块中的矩形范围,由此我们可以推算出,二维码在整张图片中的矩形范围,我们会绘制一个矩形来标识二维码的位置,这样使用者就可以清楚的知道,我们的的确确检测到了二维码。
一旦我们确定了二维码的矩形范围,接下来的工作,就是在这个矩形范围里检测颜色啦!譬如一个人如果健康状态,二维码的中间部分会显示为绿色。如果一个人完成了疫苗的注射,二维码边上的区域会显示为金色。所以,基于这样的原理,我们只需要检测对应区域是否有对应的颜色即可,这里主要利用了HSV颜色模型,不同于RGB颜色模型,HSV颜色模型利用色相、饱和度和亮度三个指标来描述颜色,是一种把RGB色彩空间中的点放在倒圆锥体上的表示方法。其中:
- H,即 Hue,表示色相,它通过角度来度量,因此,它的取值范围是0 到 360 度,如下图所示,红色对应 0 度,绿色对应 120 度,蓝色对应 240 度:
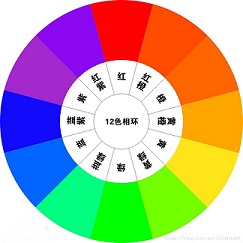
- S,即 Saturation,表示饱和度,用 0 到 100% 之间的数值表示,如果用下面的倒圆锥体来表示,则 S 表示的是色彩点到所在圆形切面圆心的距离与该圆半径的比值:
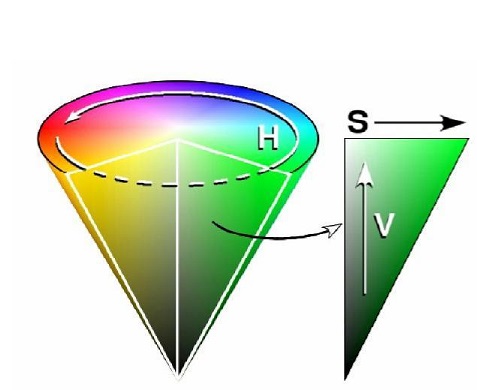
- V,即 Value,表示亮度,同样用 0 到 100% 之间的数值表示,参考上面的倒圆锥体,可以了解到,V 表示的是色彩点所在圆形切面圆心与该圆圆心在垂直距离上的比值:
此时此刻,你有没有回想起小时候调电视机画面时的经历呢?

对于HSV颜色模型,我们可以参考下面的取值范围:
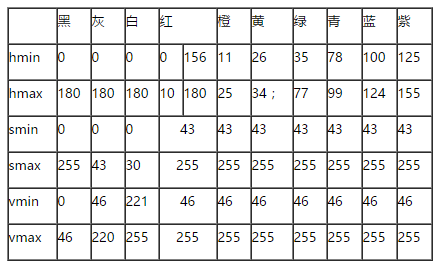
以红色为例,其 H 分量取值范围为:0 到 10;S 分量取值范围为:43 到 255;V 分量取值范围为:46 到 255。OpenCV 中的 inRange() 函数,可以判断某个 HSV 数组(此时图片使用一个数组来表示)是否在某个给定的区间范围内。于是,我们的思路就是:定义好目标颜色的 HSV 区间,同时提供一份 HSV 格式的图片数据。此时,其实现逻辑如下:
# 颜色范围定义
color_dist = {
'red': {'Lower': np.array([0, 60, 60]), 'Upper': np.array([6, 255, 255])},
'blue': {'Lower': np.array([100, 80, 46]), 'Upper': np.array([124, 255, 255])},
'green': {'Lower': np.array([35, 43, 35]), 'Upper': np.array([90, 255, 255])},
'golden': {'Lower': np.array([26, 43, 46]), 'Upper': np.array([34, 255, 255])},
}
# 检测颜色
def detect_color(image, color):
# gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 灰度
gs = cv2.GaussianBlur(image, (5, 5), 0) # 高斯模糊
hsv = cv2.cvtColor(gs, cv2.COLOR_BGR2HSV) # HSV
erode_hsv = cv2.erode(hsv, None, iterations=2) # 腐蚀
inRange_hsv = cv2.inRange(erode_hsv, color_dist[color]['Lower'], color_dist[color]['Upper'])
contours = cv2.findContours(inRange_hsv.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2]
if len(contours) > 0:
draw_color_area(image, contours)
return True
else:
winsound.Beep(440, 5000)
return False
这里,我们先对图片做了一次高斯模糊、然后将其转换为 HSV 格式,经过侵蚀以后传给 inRange()函数,这样我们就得到了所有符合这个区间范围的点。接下来,单单找到颜色还不行,我们还需要根据这些点得到一个轮廓,此时,findContours()函数再次登场,为了让使用者更直观地找到对应的颜色区域,我们这里使用下面的方法将其“画”出来:
# 标记颜色区域
def draw_color_area(image, contours):
max, index = 0, -1
for i in range(len(contours)):
area = cv2.contourArea(contours[i])
if area > max:
max = area
index = i
if index >= 0:
rect = cv2.minAreaRect(contours[index])
cv2.ellipse(image, rect, color_marker, 2, 8)
cv2.circle(image, (np.int32(rect[0][0]), np.int32(rect[0][1])), 2, color_marker, 2, 8, 0)
以中间部分的二维码图块为例,此时,我们可以得到下面的结果,这是做了两次颜色检测得到的,第一次检测绿色,第二次检测金色:

OCR 识别
OCR识别没有太多悬念,因为我们直接使用 PaddleOCR 即可,因为我们已经完成对图块的切分,只需要依次对图片进行检验即可:
python -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple
python -m pip install paddleocr
在安装的过程中,可能会得到这样的错误信息:Microsoft Visual C++ 14.0 is required。如果你安装了 Visual Studio 依然提示错误,解决方案就是找到 Visual Studio 安装包,然后勾选那些和 Microsoft Visual C++ 14.0 相关的可选的安装项,再安装了这些必要组件以后,重新使用pip安装即可。

因为 PaddleOCR 接受的是PIL库中的Image类型,所以,在拆分图块的时候,实际上是为伟哥图块生成了一个对应的文件。此时,OCR 识别部分的代码实现如下。首先,我们需要初始化 PaddleOCR ,首次运行会自动下载训练好的模型文件:
# PaddleOCR
ocr = PaddleOCR()
这里,我们通过detect_text来检测每个图块的文字,并在原始图片中标记出文字位置:
# 检测文字
def detect_text(image, block):
_, block_rect, block_file = block
block_x, block_y, _, _ = block_rect
result = ocr.ocr(block_file)
for line in result:
boxes = line[0]
texts = line[1][0]
x = int(boxes[0][0])
y = int(boxes[0][1])
w = int(boxes[2][0]) - x
h = int(boxes[2][1]) - y
abs_x = block_x + x
abs_y = block_y + y
cv2.rectangle(image, (abs_x, abs_y), (abs_x + w, abs_y + h), color_marker, 2)
yield texts
以底部图块的检测结果为例,其文字位置标记及文字识别结果如下图所示:


到现在为止,主要的部分我们已经编写完成,接下来,我们只需要接入摄像头,从摄像头捕捉图像即可。这里,请允许在下推荐一个非常好用的软件:iVCam,它可以让手机摇身一变成为摄像头,从而可以让我们模拟扫描二维码的场景。使用 OpenCV 捕捉来自摄像头的图片非常简单,大家可以参考我曾经的博客:视频是不能P的系列:OpenCV人脸检测,这里我们直接给出代码:
def handle_video():
cap = cv2.VideoCapture(0)
while True:
ret, image = cap.read()
if ret:
# 检测画面中的图块
blocks = list(detect_blocks(image))
# 处理每个图块
for block in blocks:
image = handle_block(image, block)
# 展示处理结果
cv2.imshow('QRCode Detecting', image)
# 按 Q 退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
continue
cap.release()
cv2.destroyAllWindows()
此时,我们就可以看到下面的结果。可以注意到,在实际应用中,通过视频采集的图像会受到环境光照、拍摄角度等因素的影响,受此影响,我们的图块检测在这个环节表现不佳,它甚至把整张图片当成了一个图块,这直接导致最重要的二维码没有检测出来。百度的 PaddleOCR 表现倒是可圈可点,识别速度和准确性还是非常出色的。对于视频这种级别的输入,特别是在人流量较大的商场、车站等场所,对于识别准确性、可靠性都有着非比寻常的要求,如果要考虑这个思路的落地,应该在图像采集的预处理、图像检测的算法上去下功夫,特别是在拆分图块这个环节,识别的准确性还会受到二维码样式的影响,而这些显然是这篇博客背后的故事啦!正所谓,”路漫漫其修远兮,吾将上下而求索”,如果大家对这个项目感兴趣的话,可以到 Github 上做进一步的了解。
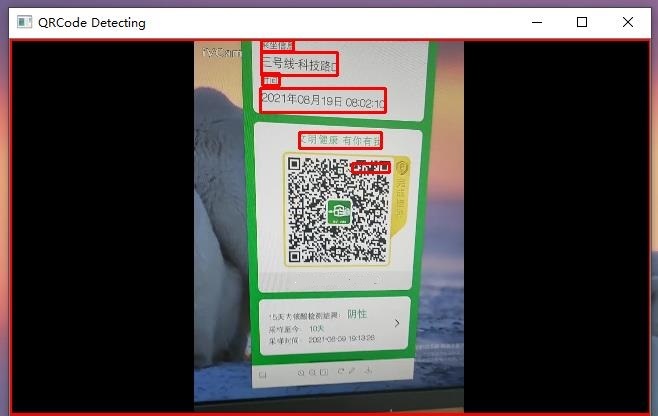
写完这篇博客的时候,我不由地会想,也许,屏幕前的某个人会在看完这篇博客以后,一脸鄙夷地说道,就这?可这的确就是基础性研究的现状,即:投入了时间和精力,并不一定能得到满意的结果。我们从小到大接受的关于成功的理念,无非都是“只要功夫深,铁杵磨成针”、“吃得苦中苦,方为人上人”……可不知道为什么,这种理念在被一点一点的打破,某种意义上来讲,国家和个人在这个时代面对的选择是相似的,在选择挣快钱还是挣慢钱这个问题上。多年以前,在实验室里捣腾化学试剂的我,曾经一度认为做实验、分析数据、写报告这些事情是枯燥而无用的,因为在当时看来,这些东西距离实际应用都挺遥远的。可是,此刻我大概不得不承认,这些基础工作的重要性。的确,写算法、做模型,这些事情都是科学家去做的事情,我们普通人只要奉行“拿来主义”就好,可当 OpenCV 就放在你手里,而你依然做不好这件事情的时候,大概还是我输了罢,说“认真你就输了”的人,真的真的真的认真过吗?
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK