

MySQL 亿级数据迁移 之 Cassandra概述
source link: https://segmentfault.com/a/1190000040511710
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
MySQL 亿级数据迁移 之 Cassandra概述
原项目中诸如 用户浏览文章记录等写多读少的表,数据量亿级以上,用MySQL存储性能不太佳,所以尝试迁移到 NoSQL 数据库,对比后选择了 ScyllaDB。
Scylla是一个开源、分布式、去中心化、弹性可扩展、高可用、容错、可调一致性、面向行的数据库。
Scylla使用C++重新实现了Cassandra,以提高性能并利用多核服务。它解决了Apache Cassandra的一些陷阱,是Apache Cassandra的嵌入式替换数据库,这两个数据库之间的驱动程序互相兼容。
Hbase与ScyllaDB
- Scylla是p2p架构,无单点失效问题,Hbase是主从结构,需要选主,维护主从关系;
- Scylla是AP系统,也可以通过调整参数使它成为CP系统(只要R+W>N),HBase是CP系统,对数据有强一致性需求就使用HBase;
- Scylla是一个数据存储和数据管理系统。HBase只负责数据管理,它需要配合HDFS和zookeeper来搭建集群;
- Scylla写性能好一些,由于数据哈希较分散,读性能不如HBase。HBase写过程比较繁琐,但其数据在regin内是排序的,读性能更好;
- 两个都适合存放 time-series data,例如传感器数据,网站访问,用户行为,股市交易数据等;
- Scylla擅长数据接入,因为写性能比较好。
Docker搭建ScyllaDB集群
docker run --name scylla-node2 -p 8042:9042 -p 8160:9160 -p 1000:10000 -p 8180:9180 -v /data/scylladb2:/var/lib/scylla -d scylladb/scylla --seeds="$(docker inspect --format='{{ .NetworkSettings.IPAddress }}' scylla)"
docker run --name scylla-node3 -p 10042:9042 -p 10160:9160 -p 1100:10000 -p 10180:9180 -v /data/scylladb3:/var/lib/scylla -d scylladb/scylla --seeds="$(docker inspect --format='{{ .NetworkSettings.IPAddress }}' scylla)"
docker run --name scylla-node4 -p 11042:9042 -p 11160:9160 -p 1200:10000 -p 11180:9180 -v /data/scylladb4:/var/lib/scylla -d scylladb/scylla --seeds="$(docker inspect --format='{{ .NetworkSettings.IPAddress }}' scylla)"接下来先介绍Cassandra的基础信息。
Cassandra的数据模型借鉴了谷歌BigTable的设计思想,有以下几个概念:
- 键空间(keyspace):相当于关系型数据库模型中的database,是最上层的命令空间。
- Key:对应 SQL 数据库中的主键,在 Cassandra 中,每一行数据记录是以 key/value 的形式存储的,其中 key 是唯一标识。
- 列族:列族是有序行集合的容器,反过来,每一行都是有序的列集合。
- 列(column):最基本的数据结构单元,由name和value组成,其包含时间戳和生存时间属性(可以通过writetime()或者ttl()函数查看。
- 超级列(super column):超级列是一个特殊列,因此它也是一个键值对。但是超级列存储子列的映射。Cassandra 允许 key/value 中的 value 是一个 map(key/value_list),即某个 column 有多个子列。
Cassandra中Keyspace的基本属性有
- 复制因子 : 它是群集中将接收相同数据副本的计算机数量.
- 副本放置策略 : 它只不过是将复制品置于戒指中的策略.我们有策略,例如简单策略(机架感知策略),旧网络拓扑策略(机架感知策略)和网络拓扑策略 (数据中心共享策略).
- 列族 : Keyspace是一个或多个列族列表的容器.反过来,列族是行集合的容器。每行包含有序列,列族表示数据的结构,每个键空间至少有一个且通常很多列族。
创建Keyspace的语法如下
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};三种主要的键
Cassandra主要由三种键:
- primary key:用于确定一条数据的键,由partition key 和clustering key组成(clustering key不是必要的)
- partition key:用于数据分区。从群集读取或写入数据时,将使用一个名为Partitioner的函数来计算分区键的哈希值。该哈希值用于确定包含该行哈希值的节点
- clustering key:主要用于进行范围查找及排序(相当于SortedMap中的key)
Cassandra会对partition key做一个hash计算,并自己决定将记录放到哪个NODE,partition key 可以是单一主键,也可以是复合主键,但是主键不能重复(主键重复的记录很可能会被。clustering key主要用于进行Range Query(范围查找),并且使用的时候需要按照建表顺序进行提供信息。
CREATE TABLE brows_record_by_target (
target_id bigint,
create_user bigint,
TYPE text,
app_id text,
create_time timestamp,
id bigint,
PRIMARY KEY ((target_id, TYPE, app_id), create_user, create_time))
WITH CLUSTERING
ORDER BY
(create_user DESC, create_time DESC);其中(target_id, TYPE, app_id)是分区键,create_user, create_time是聚集键,整个组合成PRIMARY KEY。

Cassandra的核心组件包括:
Gossip:点对点的通讯协议,用来相互交换节点的位置和状态信息。当一个节点启动时就立即本地存储Gossip信息,但当节点信息发生变化时需要清洗历史信息,比如IP改变了。通过Gossip协议,每个节点定期每秒交换它自己和它已经交换过信息的节点的数据,每个被交换的信息都有一个版本号,这样当有新数据时可以覆盖老数据,为了保证数据交换的准确性,所有的节点必须使用同一份集群列表,这样的节点又被称作seed。
Partitioner:负责在集群中分配数据,由它来决定由哪些节点放置第一份的copy,一般情况会使用Hash来做主键,将每行数据分布到不同的节点上,以确保集群的可扩展性。
Replica placement strategy:复制策略,确定哪个节点放置复制数据,以及复制的份数。
Snitch:定义一个网络拓扑图,用来确定如何放置复制数据,高效地路由请求。
cassandra.yaml:主配置文件,设置集群的初始化配置、表的缓存参数、调优参数和资源使用、超时设定、客户端连接、备份和安全
从Cassandra1.2开始,Cassandra每个节点可以拥有很多个token(哈希范围)。这种新的模式叫做虚拟节点。虚拟节点允许每个节点拥有很多集群中哈希范围。虚拟节点也是用一致性哈希分布数据,但是用它却不需要生成和分配令牌。每个节点根据配置的虚拟节点从哈希环中随机获取m个虚拟节点(m为配置的虚拟节点数)。
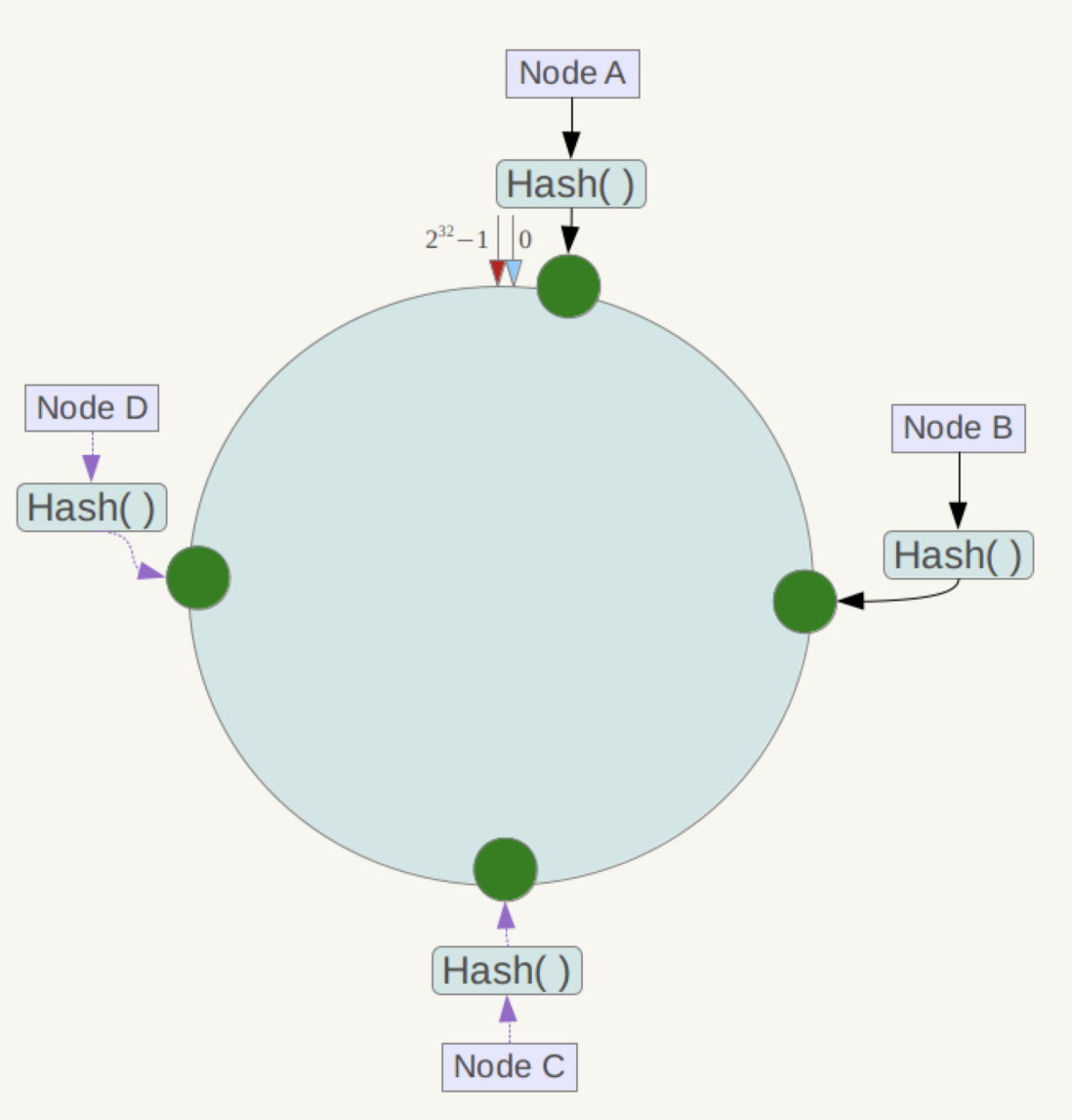
使用虚拟点的好处
- 无需计算和分配集群中每个节点的token。
- 添加或者删除节点时,集群会自动重新平衡负载。当一个节点加入集群,它将分摊来自集群中其他节点的部分数据;如果某个节点发生故障,则在该节点上的数据将会平均分配到集群中的其他节点
- 重建死掉的节点更快。
- 允许同一集群内使用不同性能的机器
CQL的简单使用
对标SQL差异化
- 支持了json方式的select\insert
- update执行如果不存在会新增
- 更新where条件必须包含所有主键,且不能更新类型为static的字段
- 增删改查必须在主键列上 ,对于(A,B)形式的主键,假如查询条件不带分区键A,则查询语句需要开启allow filtering。
- partition key字段过多会对以后的查询造成很大困扰,在建表的时候首先一定要考虑好数据模型,以免后期掉坑
查询限制
- 在利用主键进行查询时,由于 partition key 是 hash 实现的,所以只能用=;
而 clustering key, 是 sortedMap 实现的,可以用做范围查找与等号查找。例如:定义
PRIMARY KEY ((mainland), state, uid),则(mainland), state, uid构成联合主键,其中 mainland 是 partition key ,而 state 和 UID 是 clustering key。select * from users where mainland = 'northamerica' and state > '1' and state < '5';
- 复合的partition key 查询时则要满足key_part_one=' ' and key_part_two =' '
此外,Cassandra 整体数据可以理解成一个巨大的嵌套的Map。 只能按顺序一层一层的深入,不能跳过中间某一层。例如:
select * from users where location = 'shanghai' and uid < 5;
由于没有提供state的信息,不可行。
总之,Cassandra 中的存储,是2-level nested Map(2级嵌套map):Partition Key –> Custering Key –> Data
索引查询
索引:索引可以创建在除了 partition key 之外所有的列上,当然有些类型除外,例如集合类型。采用索引进行查询时,具体限制为:
- 索引列只可以用=号查询
- 如果查询条件里,有一个是根据索引查询,那其它非索引非主键字段,可以通过加一个ALLOW FILTERING来过滤实现。例如
SELECT * FROM user WHERE c>0 ALLOW FILTERING;
总结,在某一列加了索引后,某种程度上相当于把该列变成了partition key。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK