

从 CVPR 2021 的论文看计算机视觉的现状
source link: https://bbs.cvmart.net/articles/5292
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

计算机视觉(Computer Vision, CV)是人工智能领域的一个领域,致力于让计算机能够像人类一样识别和处理图像和视频中的物体。以前,计算机视觉只能在有限的能力下工作。但由于深度学习的进步,该领域近年来取得了巨大的飞跃,现在正在迅速改变不同的行业!


CV的变化如此之快,实际上仅去年一年,我们就经历了10年的变化,发表了超过4.5万篇论文,OpenAI (iGPT[18]和CLIP[10])和谷歌(v - g /14[19])等大型科技公司发布了许多怪物模型!跟上这个领域对每个人来说都是一个挑战!
在这篇文章中,你可以阅读我们的CVPR会议总结。CVPR (Computer Vision and Pattern Recognition,计算机视觉与模式识别)是计算机视觉领域最重要的会议之一。今年,CVPR共举办了83个研讨会,30个教程,50多个赞助者,12次会议共发表了超过1600篇论文(其中7093篇论文,录收率约23\%)。
最近的趋势
在2021年的CVPR上,CV的各个子领域都显示出了有希望的改进。在过去几年中,包括分割和对象分类在内的一些主题一直是人们关注的焦点,但最近又出现了一些新主题,并在2021年登上了中心舞台。我们的总结集中在以下主题:
- 使用对抗性例子学习
- 自监督和对比学习
- 视觉语言模型
- 有限数据学习
我们还分享了对CV很重要的两个行业的见解:
使用对抗性示例学习概述
深度学习和计算机视觉系统在各种任务上都取得了成功,但它们也有缺点。最近引起研究界注意的一个问题是这些系统对对抗样本的敏感性。一个对抗性的例子是一个嘈杂的图像,旨在欺骗系统做出错误的预测 [1]。为了在现实世界中部署这些系统,它们必须能够检测到这些示例。为此,最近的工作探索了通过在训练过程中包含对抗性示例来使这些系统更强大对抗对抗性攻击的可能性。
使用对抗样本学习的利弊
优点:传统的深度学习方法对数据集中的每个训练样本均等地加权,而不管标签的正确性。这可能会使学习过程脱轨,尤其是在标签包含噪声的情况下。通过对抗性学习,当加入不同级别的噪声时,每个样本的可靠性可以根据其预测标签的稳定性来估计。这使模型能够识别和关注对噪声更具弹性的样本,从而降低其对对抗性示例的敏感性。此外,在训练机制中包含对抗性示例已被证明超过了标准任务的基准,例如对象分类和检测。这在半监督设置中很有用,即当标记数据供应有限时。
缺点:对抗性训练涉及设置“epsilon”参数,该参数控制添加到每个样本的噪声量。过高的“epsilon”可能会阻碍学习过程。此外,[2] 中所做的实验表明,随着大型标记数据集的可用,监督学习技术的性能赶上了对抗性训练技术,使得对抗性训练的优势变得不那么深刻。
使用对抗样本学习的最新技术
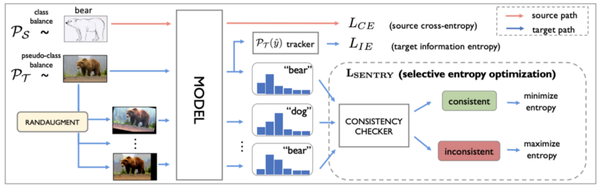
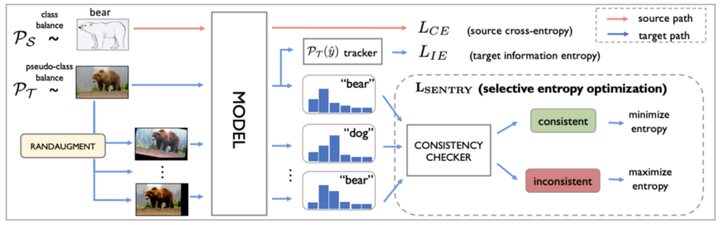
SENTRY:此方法在迁移学习的设置中使用对抗性示例。迁移学习是深度学习的领域,其中在源分布上训练的模型在不同的目标分布上进行微调和评估。在目标分布中,SENTRY 解决了分配给所有样本的权重相等的问题。它使用“预测一致性”方法识别可靠的目标实例。在这种方法中,模型的预测置信度在被认为可靠的高度一致的目标实例上增加。更具体地说,一个实例,连同它自身的几个增强版本,被输入到一个模型集合中。评估每个模型的预测的一致性。如果更多模型的预测一致,则目标实例是可靠的,因此应该用于最小化熵损失。如果预测不一致,则目标实例不可靠,因此应忽略。按照这种方法,SENTRY 在 DomainNet [3] 上实现了 SOTA,这是一个标准数据集,用于评估模型的迁移学习能力。
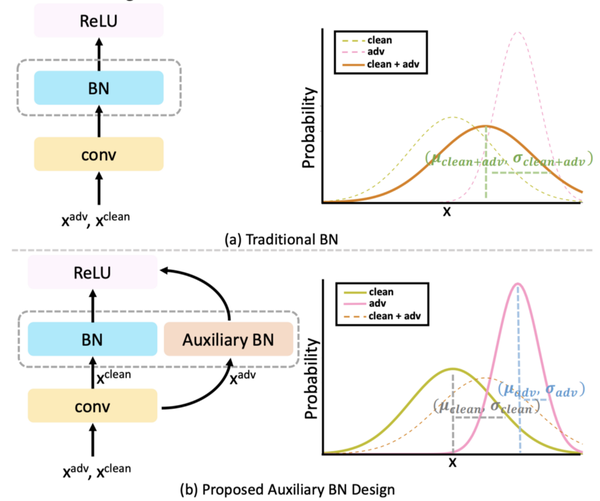
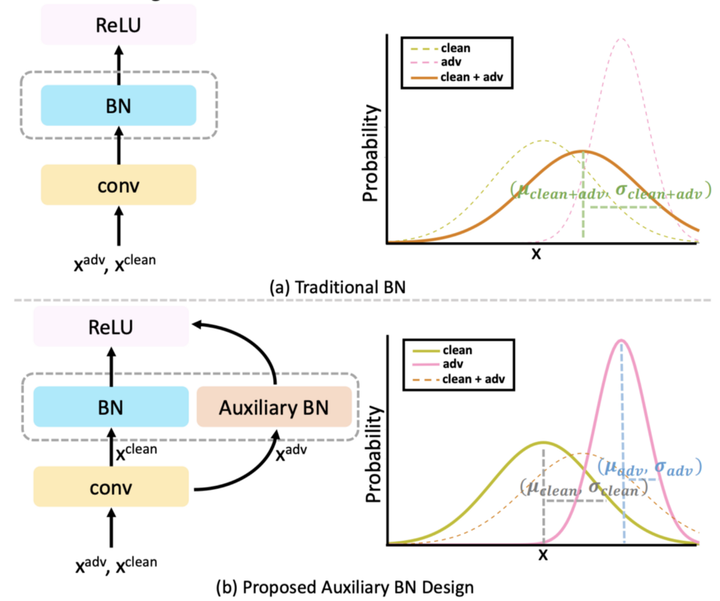
AdvProp:在训练中包含对抗性示例已被证明可以提高模型性能并导致更符合人类解释的特征 [4]。这项工作探索了干净和对抗性图像的联合训练模型。以前的工作探索了对抗样本的预训练模型,然后对干净的图像进行微调。虽然这提高了分类性能,但模型变得容易受到“灾难性遗忘”的影响,其中模型忘记了它在预训练阶段(在域转移的情况下)学习的特征。为了解决这个问题,提出了辅助批量归一化(BN)层来专门对对抗样本进行归一化。另一方面,正常的 BN 层用于标准化干净的图像。这允许归一化层根据干净样本和对抗样本的不同分布而表现不同。在推理过程中,辅助 BN 层被删除,而正常的 BN 层用于预测。这种训练机制与作为主干架构的 EfficientNet 一起在 ImageNet 分类精度上实现了前 1 名的 SOTA 性能。此外,AdvProp 在更难的 ImageNet 版本上实现了 SOTA 性能:ImageNet-a、ImageNet-c 和 Stylized ImageNet。此外,在训练中包括对抗样本也实现了目标检测的 SOTA [5]。
自监督和对比学习概述
深度学习需要干净的标记数据,这对于许多应用程序来说很难获得。注释大量数据需要大量的人力劳动,这是耗时且昂贵的。此外,数据分布在现实世界中一直在变化,这意味着模型必须不断地根据不断变化的数据进行训练。自监督方法通过使用大量原始未标记数据来训练模型来解决其中的一些挑战。在这种情况下,监督是由数据本身(不是人工注释)提供的,目标是完成一个间接任务。间接任务通常是启发式的(例如,旋转预测),其中输入和输出都来自未标记的数据。定义间接任务的目标是使模型能够学习相关特征,这些特征稍后可用于下游任务(通常有一些注释可用)。自监督学习在 2020 年变得更加流行,当时它终于开始赶上全监督方法的性能。有贡献的一项特殊技术是对比学习 (Contrastive Learning)。
CL 的灵感来自一个古老的想法 [6],即相似的项目应该在嵌入空间中保持靠近,而不同的项目应该相距很远。为了实现这一点,CL 形成了样本对。对于给定的样本,使用样本项和它的增强版本创建一个正对。类似地,使用相同的项目和不同的项目创建负对。然后,学习特征使得正对在嵌入空间中很近,而负对相距很远。这允许相似的项目在嵌入空间中聚集在一起。聚类中心可以表示语义或对象类。由于没有使用标签,CL 可以利用大量未标记的原始数据。
自我监督和对比学习的利弊
优点:自监督学习是一种数据高效的学习范式。监督学习方法教会模型擅长特定任务。另一方面,自监督学习允许学习不专门用于解决特定任务的一般表示,而是为各种下游任务封装更丰富的统计数据。在所有自监督方法中,使用 CL 进一步提高了提取特征的质量。自监督学习的数据效率特性使其有利于迁移学习应用。
缺点:自监督学习的大部分成功都归功于精心选择的图像增强,例如缩放、模糊和裁剪。因此,为特定任务选择正确的增强集和程度可能是一个具有挑战性的过程。此外,CL 可能会误导模型区分包含相同对象的两个图像。例如,对于一匹马的图像,为了创建负对,CL 可能会选择另一个也包含一匹马的图像。在这种情况下,模型认为是负对的实际上是正对。
最先进的自我监督和对比学习
SimSiam: Exploring Simple Siamese Representation Learning:Siamese 网络框架是一种在自监督学习中广受欢迎的架构。 与创建正负对的 CL 不同,该框架仅最大化图像增强之间的相似性,这有助于学习有用的表示。自监督学习中的并行工作使用对比损失,这些工作的成功依赖于 (i) 负对 [7] 的使用,(ii) 批次大小,以及 (iii) 动量编码器 [8]。然而,SimSiam 不依赖于这些因素,使其对超参数的选择更加稳健。此外,SimSiam 使用“stop-gradient”技术来防止特征崩溃。特征崩溃是一种现象,模型在不学习有用表示的情况下学习了最小化目标函数的捷径。因此,学习到的特征是不可泛化的。通过避免特征崩溃,SimSiam 在 ImageNet 和后续下游任务(例如 COCO 对象检测和实例分割)上取得了有竞争力的结果。
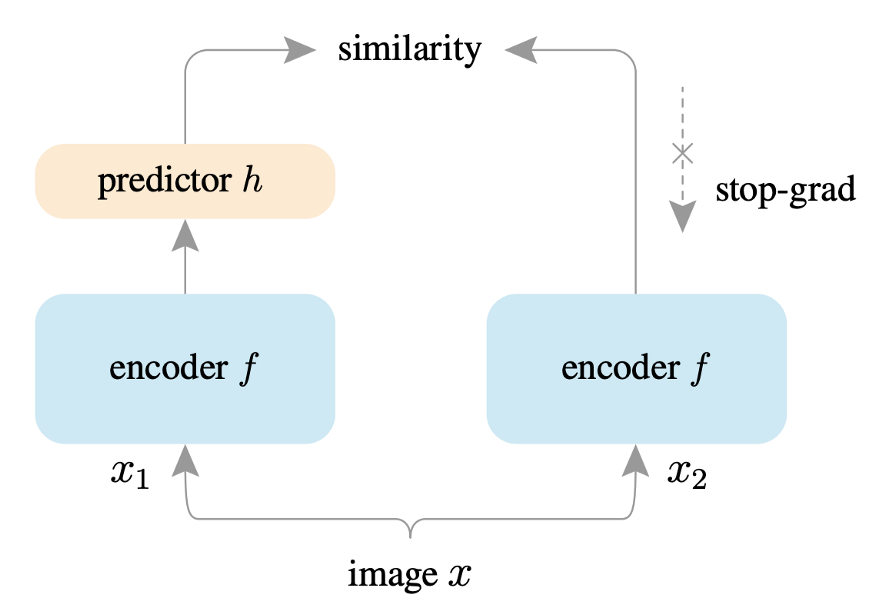
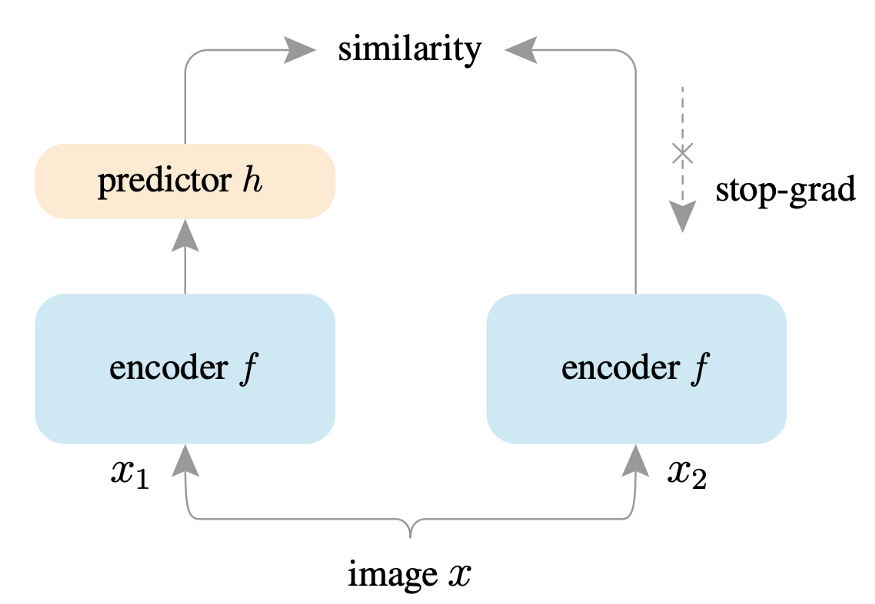
DINO:自监督视觉Transformers的新兴特性:DINO 建立在 SwAV [9] 之上,包括无标签的自蒸馏。 使用的主干架构是Transformers [10],它已被证明优于卷积网络。 使用transformers + DINO框架,改进了图像分类任务的SOTA。 DINO 可应用于复制检测和图像检索等应用。 给定一个查询图像,尽可能快地检索该图像的所有可能副本。 此外,DINO 免费提供分段功能。 与监督方法相比,在 DINO 中学习的特征已被证明在显着图生成方面表现更好。 最后,通过仔细的阈值设置,DINO 可以开箱即用地应用于每帧视频对象分割,而无需进行时间一致性训练。
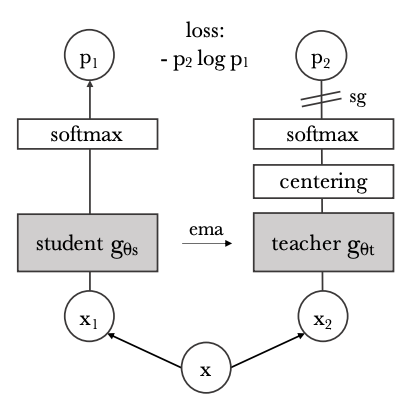
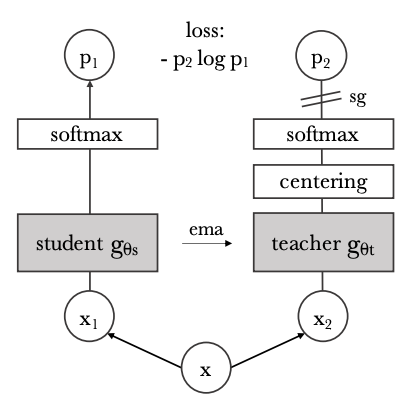


视觉语言模型概述
Vision-Language (VL) 涉及对图像和文本模式有共同理解的训练系统。 VL 类似于人类与世界互动的方式; 视觉是人类如何感知世界的很大一部分,而语言是人类交流方式的很大一部分。 VL 模型学习不同数据模态的联合嵌入空间。 对于训练,使用图像和文本对,其中文本通常描述图像。 该领域的大部分最新工作都使用基于转换器的自监督学习来从数据中提取特征。 另一方面,视频-文本对已开始用于学习更丰富和更密集的表示。 然而,它仍然是一个具有巨大潜力的新兴领域。
视觉语言模型的优缺点
优点:VL 使用不同形式的数据,可以更好地进行特征映射和提取。此外,可以使用大量数据样本(例如 YouTube 视频和自动生成的注释)来训练这些系统。与自监督学习类似,学习到的特征是通用的,可用于多个下游任务,例如
- 图像字幕 (IC)
- 视觉问答 (VQA)
此外,VL 模型可用于学习更好的视觉特征和增强语言表示,如
- OpenAI-CLIP [11]
- Google ALIGN [12]
- OpenAI-DALL-E [13]
- Vokenization [14]
缺点:VL 模型专门使用英语来创建图像-文本对。因此,多语种工作在这一领域仍需取得进展。至于视频文本模型,没有足够的统一基准来评估它们。而且,类似于基于图像-文本的 VL 模型,视频-文本模型也可以通过更多地关注多语言功能来使不同的语言受益。
最先进的视觉语言模型
VinVL:重新审视视觉语言模型中的视觉表示:VinVL 改进了 VL 任务的视觉表示。 VL 模型通常具有对象检测器模型和语言提取器模型,然后是融合模型。融合模型负责合并视觉和语言嵌入。以前的 VL 模型主要侧重于改进视觉语言融合模型 [15],同时保持对象检测模型不变。 VinVL 表明视觉特征在 VL 模型中非常重要,并提出了改进的对象检测模型。对象检测模型检测几乎覆盖图像所有语义区域的边界框,而不是仅覆盖重要对象的传统边界框。最后,视觉特征通过转换器 [16] 与语言嵌入融合。在对多个数据集进行预训练后,VinVL 针对多个下游任务(VQA、IC 等)进行了微调,并在七个公共基准上实现了 SOTA 性能。性能提升可归因于改进的对象检测模型。


有限数据学习概述
监督学习方法需要大量数据,其性能在很大程度上取决于训练数据的质量和大小。然而,在现实世界中,大量标记数据的获取通常很昂贵或不容易获得。当考虑需要基于专家知识(例如医学成像)进行注释的视觉类、很少出现的类或标记需要大量工作(例如图像分割)的任务时,这个问题变得更加严重。在过去的十年中,出现了各种研究领域来应对这些挑战。弱监督学习、迁移学习和自/半监督等领域试图通过使 ML 模型从有限、弱或嘈杂的监督中学习来克服这些挑战。由于上面已经介绍了自/半监督,这里我们主要关注弱监督学习和迁移学习。
有限数据学习的利弊
优点:弱监督学习和迁移学习有助于减少训练 CV 模型所需的标记数据量,从而增加这些模型在工业中的应用和采用。弱监督学习还可以帮助模型在存在噪声标签的情况下表现得更好,这在现实世界中经常出现。此外,基于实例的迁移学习方法可用于克服现实世界数据集自然产生的类不平衡挑战(例如,视觉世界的长尾分布[17])。
缺点:弱监督学习和迁移学习都是相对较新的领域,仍需要时间才能在工业中使用。这些方法通常是根据从受控环境收集的基准来开发和评估的,因此在实际环境中进行测试时,它们的性能通常会下降。此外,这些领域中最有趣的论文都是基于研究环境中的假设而开发的,但不一定在现实环境中。在使用这些论文解决实际问题时,请注意这些论文中隐含和显式的假设。
使用有限数据进行最先进的学习
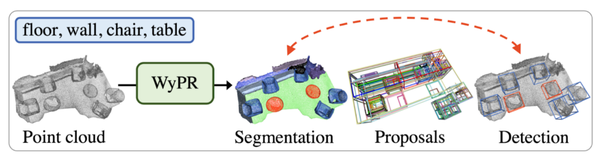
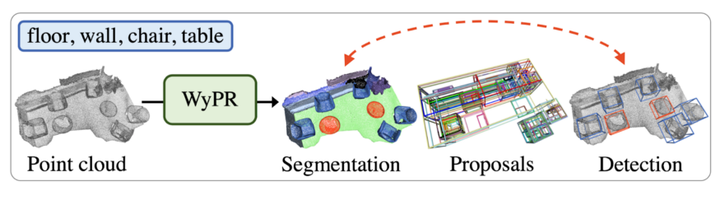
WyPR:弱监督点识别:WyPR 以点云为输入,共同解决分割、提议生成和检测。共同完成这些任务有几个好处,包括:
- 将语义分割作为检测的替代任务可以提供点级预测,形成自下而上的解决方案
- 这些任务是互利的,例如,检测结果可用于细化分割
- 多任务设置可以实现更好的表征学习。
WyPR 使用多实例学习 (MIL) 和自我训练技术进行训练,并在任务和转换中定义了额外的一致性损失。 WyPR 在 ScanNet 数据上的性能比之前的分割方法高 6.3\% mIoU。同样,它在 ScanNet 上的提议生成和检测方面优于先前的提议方法。
DatasetGAN:DatasetGAN 使用生成对抗网络 (GAN) 和小样本学习(迁移学习的一个子领域)来生成真实的训练数据——图像和标签。 该方法建立在 StyleGAN[20] 之上,StyleGAN[20] 是用于生成逼真图像的最新模型。 StyleGAN 默认只生成图像。 为了使 StyleGAN 能够在图像之外生成标签(例如语义分割图),他们在 StyleGAN 的合成块中添加了一个标签分支。 标签分支只是几层多层感知器,在这项工作中用 16 个标记样本进行训练。 论文表明,即使只有一个标记示例,该方法也能获得合理的结果,并且当提供 30 个标记示例时,它达到了全监督方法的性能。 此外,作者表明相同的想法可用于生成带有标签的合成视频 [21]。


从自助结账到产品推荐,CV 在过去几年帮助零售公司取得了重要进展。 以下是一些使用简历来提升零售体验的公司和初创公司的例子:
Grabango 是一家位于伯克利的零售视觉初创公司,它正在应用 CV 进行无摩擦结账,类似于 AmazonGo。这家初创公司的目标是生成一个虚拟购物篮,用于识别购物者选择的商品,简化结账流程。为了实现自助结账,由加州大学伯克利分校的 Trevor Darrell 教授领导的数据科学团队将问题分解为三个部分:跟踪,跟踪店内顾客的动向,检测诸如取走/保留商品等事件。货架和预测产品 ID。 Grabango 在商店中放置了数以千计的传感器、访问大量历史数据以及来自 BAIR(伯克利人工智能研究)的专门研究人员团队,Grabango 正在使自助结账成为现实。
Facebook AI Research (FAIR):通过从 Facebook Marketplace 访问数百万个零售数据点,Facebook 能够创建 CV 模型,根据文本描述向用户推荐产品。简而言之,用户输入他们想要购买的产品的描述。 Facebook 使用此描述作为查询来获取并向用户显示最相关的产品图片。在幕后,Facebook 使用 GrokNet,这是一个训练用于大规模产品识别的 CV 模型。使用著名的 ArcFace 模型和 Catalyzer 的改进,GrokNet 在产品推荐任务上取得了令人印象深刻的结果。
几年来,自动驾驶汽车一直是人们关注的焦点。谷歌、特斯拉、优步、丰田和 Waabi 等多家公司和初创公司投资于自动驾驶汽车。虽然实现 5 级自治的基本原则(即汽车在无人干预的情况下自动驾驶)保持一致,但该领域的领导者对哪些传感器性能更好有不同的看法。自动驾驶汽车广泛使用传感器来获取有关其周围环境的数据。然后将这些数据馈送到 CV 模型以获得自动驾驶所需的预测。一些公司将仅使用摄像头的传感器作为黄金标准,而另一些公司则更喜欢将摄像头和雷达传感器混合使用。
特斯拉:由 Andrej Karpathy 博士领导的自动驾驶团队仅使用摄像头传感器进行预测。该团队通过实验展示了使用摄像头传感器而不是雷达的好处。特斯拉首席执行官埃隆马斯克甚至发了推文!此外,该团队认为摄像头传感器比雷达便宜,这使得它们在大规模生产时更经济。与其竞争对手相比,特斯拉已经在街上拥有数千辆自动驾驶汽车。这使他们能够收集训练期间未考虑的独特驾驶条件的实时数据。为此,特斯拉拥有一个名为“车队”的基础设施,其唯一目的是从世界不同地区收集有关不同驾驶条件的数据。以“大数据=自动驾驶解决”的理念,特斯拉在自动驾驶行业的研发中处于领先地位。
Waabi:由自动驾驶行业专家兼首席执行官 Raquel Urtasun 博士领导,Waabi 是一家总部位于多伦多的初创公司,专注于长途卡车驾驶。 Waabi 使用一套传感器在卡车周围创建导航环境。使用概率模型,环境能够模拟和合成现实生活中遇到的不同交通状况和场景。从这个环境中采样不同的路径轨迹,然后输入到为特定任务设计的 CV 模型。 Waabi 认为,获取真实交通中可能发生的所有可能场景的实时数据是很困难的。在这里,模拟环境可用于创建多个边缘情况场景,然后可用于训练模型。
相关推荐:
计算机视觉顶会文章的解读汇总 CVPR/ECCV/ICCV/NIPS
CVPR2021 论文解读汇总(更新中)
 0
0 0
0 2846
2846
Recommend
-
49
The 2018 Conference on Computer Vision and Pattern Recognition (CVPR) took place last week in Salt Lake City, USA. It’s the world’s top conference in the field of computer vision. This year, CVPR received 3,300 main confe...
-
26
加入极市专业CV交流群,与 1 0000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流! 同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业...
-
41
在2月24日,CVPR 2020 公布接收论文结果公布,从 6656 篇有效投稿中录取了 1470 篇论文,录取率约为 22%。3月13日,CVPR Oral结果公布了。有大佬已经分享了自己的工作,本文整理了已中Oral的论文,持续更新,分享给大家阅读。 10.P...
-
7
论文推荐 | CVPR 2020 获奖论文;知识蒸馏综述 5个月前 ⋅...
-
12
CVPR 2017 论文解读集锦 1年前 ⋅ 2455...
-
12
CVPR2020 论文解读集锦【计算机视觉】【CVPR】 10个月前 ⋅...
-
3
CVPR 2018 论文解读集锦(190326 更新) 2年前 ⋅...
-
10
作者:CV君 来源:微信公众号@我爱计算机视觉跟踪在计算机视觉里有很广泛的内涵,本文所指的跟踪为通用目标跟踪,不包括比如人脸特征点跟踪、视线跟踪等特定领域。 本文总结了 19 篇相关论文,列出了代码地址,并大...
-
11
-
7
📝笔记:CVPR 2020 视觉定位挑战赛冠军方案 Posted on 2020-10-31 ...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK