

使用Scrapy编写爬虫
source link: https://zhuanlan.zhihu.com/p/399915051
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

使用Scrapy编写爬虫
在前文送你一只爬虫——Python爬虫,梳理了编写爬虫的思路。本文继续记录我是如何使用scrapy爬取科学网的基金,用于汇总分析。源码在GitHub - Celthi/ScienceNetool
注:本文纯用于交流学习。
Scrapy
Scrapy是编写爬虫的Python框架,比较有名。刚开始学习Python的时候,想学一学并编写爬虫,可是后面搁置了。趁着上次帮朋友编写爬虫,使用Scrapy写了ScienceNetool。
ScienceNetool使用Scrapy编写,能够爬取科学网上的基金,并将符合关键词的基金存到Excel表格里面。
Scrapy的教程,只需要会英文,大致阅读一两个小时,即可上手。本文记录我觉得可以快速上手的一些思路。
上手需要理解的内容顺序如下(对于我)
- 理解第一个网址如何传递
- 理解如何登录
- 理解如何在登录后爬取内容——提取数据,和要爬取的网址
Scrapy官网提供了架构的讲解。这里梳理主要内容,细节部分等你用到的时候阅读官方教程更好。
Scrapy的架构如下,
从程序员的角度,我们需要知道如下的几个点,
- Spider将需要爬取的Requests(网址) 喂给Engine,见上图红色数字1。
- Engine 会定时的访问这些Request,然后爬取网页,得到Response,见红色4和5。
- Engine会将Response喂给Spider,然后Spider从Response里面提取新的Request,重复第二步,见红色数字7。
- Spider从Response提取新的Request的时候,也会提取相应的数据(Items)喂给Engine,见红色数字7。
- Engine拿到对应的Item后,会将Item交付给一堆流水线。流水线处理数据,比如存储到Execl里面,见红色数字8。
明白了这个架构,我们就会发现程序员,也就是你我,需要编写的代码主要是Spider和流水线中处理数据的代码。Engine是Scrapy框架提供的,它直接可以帮我们干活。
下面让我们以科学网爬取基金为例,讲讲我编写的那些代码。
科学网基金爬取
登录
首先需要登录,那么阅读Scrapy关于登录的代码,我们得到,可以使用FormRequst来进行登录,代码如下,
return scrapy.FormRequest.from_response(
response,
formdata={'phone': self.config["手机号码"],
'password': self.config["密码"]},
callback=self.after_login
)FormRequest会将手机号码和密码,提交到科学网。如果手机和密码正确,那么就会登录成功。
爬取的第一个网页
既然需要登录,那么爬取的第一个网页就是要登陆的界面,代码如下,
def start_requests(self):
urls = [
'http://fund.sciencenet.cn/login',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)登录以后
登录后,要做的就是提供关键词,搜索感兴趣的基金,代码如下,
def construct_search_url(self):
fuzzy_search = ""
if self.config["模糊查询"] == "开启":
fuzzy_search = "&match=1"
url = 'http://fund.sciencenet.cn/search?name={name}&yearStart={yearStart}&yearEnd={yearEnd}&subject={subject}&category={category}&fundStart={fundStart}&fundEnd={fundEnd}&submit=list'.format(
name=self.config["查询项目名称"],
yearStart=self.config['批准年度开始'],
yearEnd=self.config['批准年度结束'],
subject=self.config['学科分类'],
category=self.config['项目类别'],
fundStart=self.config['fundStart'],
fundEnd=self.config['fundEnd']) + fuzzy_search
return url遍历搜索到的网页
根据关键词返回的网页会有好多页,比如
我们希望把每一页的信息都提取出来,所以需要遍历每一页。注意,搜索范围太多时,搜索的内容很多。
怎么提取每一页的链接呢?这里我发现,根据页的网址如nextPage=1,改成nextPage=11,不会得到第11页。所以需要像爬虫一样,爬取一页,然后获取下面要爬取的页数。代码如下,
def iter_pages(self, response):
def is_page_link(link):
return re.search(urllib.parse.quote(self.config["查询项目名称"]), link) != None
pages_xpath = '//*[@id="page_button"]/span/a/@href'
links = response.xpath(pages_xpath).getall()
return filter(is_page_link, links)提取数据
获取到Response后,我们就可以从网页里面提取数据了,代码如下,
def collect_items(self, response):
item_xpath = '//*[@id="resultLst"]/div[@class="item"]'
for i in response.xpath(item_xpath):
yield self.get_item(i)
def get_item(self, item):
texts = item.xpath('p[@class="t"]/a//text()').getall()
author = item.xpath('div[@class="d"]/p/span[1]/i/text()').get()
number = item.xpath('div[@class="d"]/p/b/text()').get()
research_type = item.xpath('div[@class="d"]/p/i/text()').get()
department = item.xpath('div[@class="d"]/p/span[2]/i/text()').get()
year = item.xpath('div[@class="d"]/p/span[3]/b/text()').get()
money = item.xpath('div[@class="d"]/p[2]/span[1]/b/text()').get()
keywords = item.xpath('div[@class="d"]/p[2]/span[2]/i/text()').getall()
return {
"name": "".join(map(lambda s: s.strip(), texts)),
"author": author,
"number": number,
"department": department,
"research_type": research_type,
"year": year,
"money": money,
"keywords": "".join(map(lambda s: s.strip(), keywords)),
}这里我们提取感兴趣的部分,如项目名称,负责人,研究类型,批准年度等等。使用的scrapy自带的提取函数。你可以使用你顺手的方法。
存储到Excel
提取数据以后,我们就可以存储到Excel里面了,代码如下,
def process_item(self, item, spider):
cells = {}
for k, v in output_schema.items():
cells[v["cell"]] = item[k]
self.ws.append(cells)
return item经过上面几步,爬虫就写好了,然后运行scrapy crawl quotes,就可以爬取内容了!
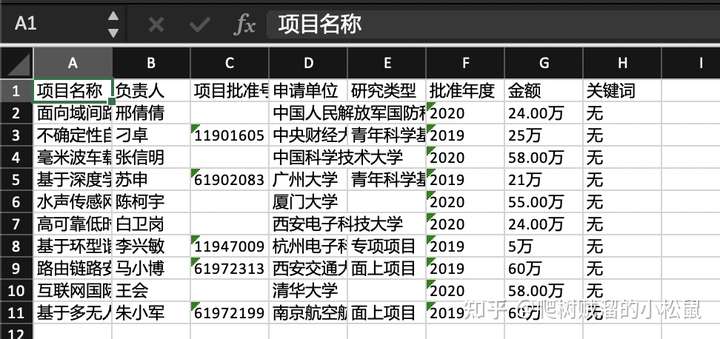
推荐你下载代码,然后提供相应的手机号和用户名,运行代码切实的感受一下。
Recommend
-
8
导读:如何使用scrapy框架实现爬虫的4步曲?什么是CrawSpider模板?如何设置下载中间件?如何实现Scrapyd远程部署和监控?想要了解更多,下面让我们来看一下如何具体实现吧! Scrapy安装(mac) pip install scrapy...
-
10
Python爬虫编程思想(145):使用Scrapy Shell抓取Web资源
-
24
Python爬虫编程思想(146):创建和使用Scrapy工程 ...
-
4
Python爬虫编程思想(147):在PyCharm中使用Scrapy ...
-
8
Python爬虫编程思想(149):使用Scrapy抓取数据,并通过XPath指定解析规则 ...
-
8
Python爬虫编程思想(150):使用Scrapy抓取数据,并将抓取到的数据保存为多种格式的文件 ...
-
7
Python爬虫编程思想(151):使用Scrapy抓取数据,用ItemLoader保存单条抓取的数据 ...
-
13
Python爬虫编程思想(153):使用Scrapy抓取数据,抓取多个Url ...
-
9
Python爬虫编程思想(152):使用Scrapy抓取数据,使用ItemLoader保存多条抓取的数据 ...
-
2
Python爬虫编程思想(157):使用Scrapy从CSV格式转换到JSON格式 ...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK