

就这?分布式 ID 发号器实战
source link: https://www.cnblogs.com/liangzaiit/p/15140209.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


分布式 ID 需要满足的条件:
- 全局唯一:这是最基本的要求,必须保证 ID 是全局唯一的。
- 高性能:低延时,不能因为一个小小的 ID 生成,影响整个业务响应速度。
- 高可用:无限接近于100%的可用性。
- 好接入:遵循拿来主义原则,在系统设计和实现上要尽可能简单。
- 趋势递增:这个要看具体业务场景,最好要趋势递增,一般不严格要求。
让我来先捋一捋常见的分布式 ID 的解决方案有哪些?
1、数据库自增 ID
这是最常见的方式,利用数据库的 auto_increment 自增 ID,当我们需要一个ID的时候,向表中插入一条记录返回主键 ID。简单,代码也方便,但是数据库本身就存在瓶颈,DB 单点无法扛住高并发场景。
针对数据库单点性能问题,可以做高可用优化,设计成主从模式集群,而且要多主,设置起始数和增长步长。
-- MySQL_1 配置:
set @@auto_increment_offset = 1; -- 起始值
set @@auto_increment_increment = 2; -- 步长
-- 自增ID分别为:1、3、5、7、9 ......
-- MySQL_2 配置:
set @@auto_increment_offset = 2; -- 起始值
set @@auto_increment_increment = 2; -- 步长
-- 自增ID分别为:2、4、6、8、10 ....
但是随着业务不断增长,当性能再次达到瓶颈的时候,想要再扩容就太麻烦了,新增实例可能还要停机操作,不利于后续扩容。
2、UUID
UUID 是 Universally Unique Identifier 的缩写,它是在一定的范围内(从特定的名字空间到全球)唯一的机器生成的标识符,UUID 是16字节128位长的数字,通常以36字节的字符串表示,比如:4D2803E0-8F29-17G3-9B1C-250FE82C4309。
生成ID性能非常好,基本不会有性能问题,代码也简单但是长度过长,不可读,也无法保证趋势递增。
3、雪花算法
雪花算法(Snowflake)是 twitter 公司内部分布式项目采用的 ID 生成算法,开源后广受国内大厂的好评,在该算法影响下各大公司相继开发出各具特色的分布式生成器。
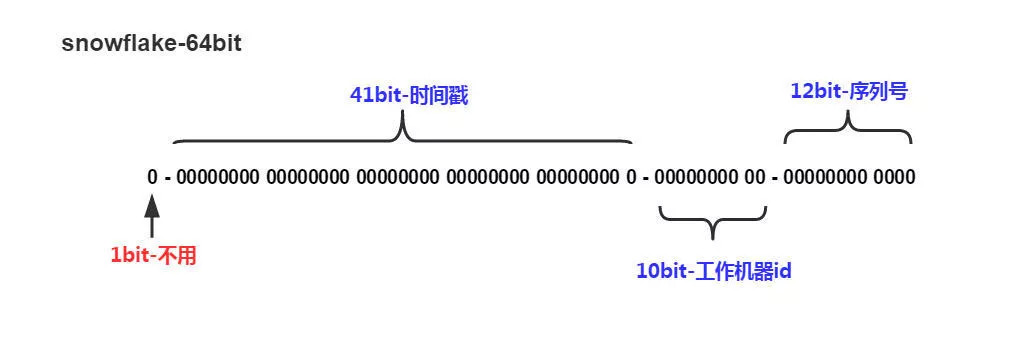
组成结构:正数位(占1 bit)+ 时间戳(占41 bit)+ 机器 ID(占10 bit)+ 自增值(占12 bit),总共64 bit 组成的一个 long 类型。
- 第一个 bit 位(1 bit):Java 中 long 的最高位是符号位代表正负,正数是0,负数是1,一般生成 ID 都为正数,所以默认为0
- 时间戳部分(41 bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 - 固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
- 工作机器id(10bit):也被叫做 workId,这个可以灵活配置,机房或者机器号组合都可以,通常被分为 机器 ID(占5 bit)+ 数据中心(占5 bit)
- 序列号部分(12bit):自增值支持同一毫秒内同一个节点可以生成4096个 ID
雪花算法不依赖于数据库,灵活方便,且性能优于数据库,ID 按照时间在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。

雪花算法好像挺不错的样子,靓仔决定采用这个方案试下。
于是一套操作猛如虎,写个 demo 给领导看下。

只能继续思考方案了
4、百度(Uid-Generator)
uid-generator 是基于 Snowflake 算法实现的,与原始的 snowflake 算法不同在于,它支持自定义时间戳、工作机器 ID 和 序列号 等各部分的位数,而且 uid-generator 中采用用户自定义 workId 的生成策略,在应用启动时由数据库分配。
具体不多介绍了,官方地址:https://github.com/baidu/uid-generator
也就是说它依赖于数据库,并且由于是基于 Snowflake 算法,所以也不可读。
5、美团(Leaf)
美团的 Leaf 非常全面,即支持号段模式,也支持 snowflake 模式。
也不多介绍了,官方地址:https://github.com/Meituan-Dianping/Leaf
号段模式是基于数据库的,而 snowflake 模式是依赖于 Zookeeper 的
6、滴滴(TinyID)
TinyID 是基于数据库号段算法实现,还提供了 http 和 sdk 两种方式接入。
文档很全,官方地址:https://github.com/didi/tinyid
7、Redis 模式
其原理就是利用 redis 的 incr 命令实现 ID 的原子性自增,众所周知,redis 的性能是非常好的,而且本身就是单线程的,没有线程安全问题。但是使用 redis 做分布式 id 解决方案,需要考虑持久化问题,不然重启 redis 过后可能会导致 id 重复的问题,建议采用 RDB + AOF 的持久化方式。
分析到这里,我觉得 Redis 的方式非常适用于目前的场景,公司系统原本就用到了 redis,而且也正是采用的 RDB + AOF 的持久化方式,这就非常好接入了,只需少量编码就能实现一个发号器功能。
话不多说,直接开始干吧。

本案例基于 Spring Boot 2.5.3 版本
首先在 pom 中引入 redis 依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- lettuce客户端连接需要这个依赖 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
application.yml 中配置 redis 连接
spring:
redis:
port: 6379
host: 127.0.0.1
timeout: 5000
lettuce:
pool:
# 连接池大连接数(使用负值表示没有限制)
max-active: 8
# 连接池中的大空闲连接
max-idle: 8
# 连接池中的小空闲连接
min-idle: 0
# 连接池大阻塞等待时间(使用负值表示没有限制)
max-wait: 1000
# 关闭超时时间
shutdown-timeout: 100
将 RedisTemplate 注入 Spring 容器中
@Configuration
public class RedisConfig{
@Bean
@ConditionalOnMissingBean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(connectionFactory);
// 使用Jackson2JsonRedisSerializer来序列化/反序列化redis的value值
Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<Object>(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, com.fasterxml.jackson.annotation.JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
// value
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
// 使用StringRedisSerializer来序列化/反序列化redis的key值
RedisSerializer<?> redisSerializer = new StringRedisSerializer();
// key
redisTemplate.setKeySerializer(redisSerializer);
redisTemplate.setHashKeySerializer(redisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
使用 redis 依赖中的 RedisAtomicLong 类来实现 redis 自增序列,从类名就可以看出它是原子性的。
看一下 RedisAtomicLong 的部分源码
// RedisAtomicLong 的部分源码
public class RedisAtomicLong extends Number implements Serializable, BoundKeyOperations<String> {
private static final long serialVersionUID = 1L;
//redis 中的 key,用 volatile 修饰,获得原子性
private volatile String key;
//当前的 key-value 对象,根据传入的 key 获取 value 值
private ValueOperations<String, Long> operations;
//传入当前 redisTemplate 对象,为 RedisTemplate 对象的顶级接口
private RedisOperations<String, Long> generalOps;
public RedisAtomicLong(String redisCounter, RedisConnectionFactory factory) {
this(redisCounter, (RedisConnectionFactory)factory, (Long)null);
}
private RedisAtomicLong(String redisCounter, RedisConnectionFactory factory, Long initialValue) {
Assert.hasText(redisCounter, "a valid counter name is required");
Assert.notNull(factory, "a valid factory is required");
//初始化一个 RedisTemplate 对象
RedisTemplate<String, Long> redisTemplate = new RedisTemplate();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericToStringSerializer(Long.class));
redisTemplate.setExposeConnection(true);
//设置当前的 redis 连接工厂
redisTemplate.setConnectionFactory(factory);
redisTemplate.afterPropertiesSet();
//设置传入的 key
this.key = redisCounter;
//设置当前的 redisTemplate
this.generalOps = redisTemplate;
//获取当前的 key-value 集合
this.operations = this.generalOps.opsForValue();
//设置默认值,如果传入为 null,则 key 获取 operations 中的 value,如果 value 为空,设置默认值为0
if (initialValue == null) {
if (this.operations.get(redisCounter) == null) {
this.set(0L);
}
//不为空则设置为传入的值
} else {
this.set(initialValue);
}
}
//将传入 key 的 value + 1并返回
public long incrementAndGet() {
return this.operations.increment(this.key, 1L);
}
}
看完源码,我们继续自己的编码
使用 RedisAtomicLong 封装一个基础的 redis 自增序列工具类
// 只封装了部分方法,还可以扩展
@Service
public class RedisService {
@Autowired
RedisTemplate<String, Object> redisTemplate;
/**
* 获取链接工厂
*/
public RedisConnectionFactory getConnectionFactory() {
return redisTemplate.getConnectionFactory();
}
/**
* 自增数
* @param key
* @return
*/
public long increment(String key) {
RedisAtomicLong redisAtomicLong = new RedisAtomicLong(key, getConnectionFactory());
return redisAtomicLong.incrementAndGet();
}
/**
* 自增数(带过期时间)
* @param key
* @param time
* @param timeUnit
* @return
*/
public long increment(String key, long time, TimeUnit timeUnit) {
RedisAtomicLong redisAtomicLong = new RedisAtomicLong(key, getConnectionFactory());
redisAtomicLong.expire(time, timeUnit);
return redisAtomicLong.incrementAndGet();
}
/**
* 自增数(带过期时间)
* @param key
* @param expireAt
* @return
*/
public long increment(String key, Instant expireAt) {
RedisAtomicLong redisAtomicLong = new RedisAtomicLong(key, getConnectionFactory());
redisAtomicLong.expireAt(expireAt);
return redisAtomicLong.incrementAndGet();
}
/**
* 自增数(带过期时间和步长)
* @param key
* @param increment
* @param time
* @param timeUnit
* @return
*/
public long increment(String key, int increment, long time, TimeUnit timeUnit) {
RedisAtomicLong redisAtomicLong = new RedisAtomicLong(key, getConnectionFactory());
redisAtomicLong.expire(time, timeUnit);
return redisAtomicLong.incrementAndGet();
}
}
根据业务需求编写发号器方法
@Service
public class IdGeneratorService {
@Autowired
RedisService redisService;
/**
* 生成id(每日重置自增序列)
* 格式:日期 + 6位自增数
* 如:20210804000001
* @param key
* @param length
* @return
*/
public String generateId(String key, Integer length) {
long num = redisService.increment(key, getEndTime());
String id = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyyMMdd")) + String.format("%0" + length + "d", num);
return id;
}
/**
* 获取当天的结束时间
*/
public Instant getEndTime() {
LocalDateTime endTime = LocalDateTime.of(LocalDate.now(), LocalTime.MAX);
return endTime.toInstant(ZoneOffset.ofHours(8));
}
}
由于业务需求,需要每天都重置自增序列,所以这里以每天结束时间为过期时间,这样第二天又会从1开始。
@SpringBootTest
class IdGeneratorServiceTest {
@Test
void generateIdTest() {
String code = idGeneratorService.generateId("orderId", 6);
System.out.println(code);
}
}
// 输出:20210804000001
6位自增序列每天可以生成将近100w个编码,对于大多数公司,已经足够了。
经过本地环境测试,开启10个线程,1秒内每个线程10000个请求,没有丝毫压力。
如果觉得有些场景下连续的编号会泄漏公司的数据,比如订单量,那么可以设置随机增长步长,这样就看不出具体订单量了。但是会影响生成的编码数量,可以根据实际情况调整自增序列的位数。

没有最好的,只有最合适的。在实际工作中往往都是这样,需要根据实际业务需求来选择最合适的方案。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK