

g1源码从写屏障到Rset全面解析
source link: https://my.oschina.net/u/3645114/blog/5159519
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
笔者在之前讲解g1 youngGC源码的博客(https://my.oschina.net/u/3645114/blog/5119362)中提到过关于g1写屏障和Rset(记忆集合)等相关知识点,之前限于文章长度(ps:全部介绍完博客会比较长)跳过了这个部分只是简单介绍了下概念,今天我们来继续从源码出发,探究g1的写屏障和记忆集合等相关技术内幕。
一.写屏障(write barrier)
关于写屏障,其实要从垃圾回收的三色标记说起,网上关于三色标记的文章很多,具体说明也比较详细,笔者在这里就不在进行详细说明,本文的重点还是放在源码解析与阅读上。
在三色标记算法中,只有同时满足以下两种条件就会产生漏标的问题:
- 灰色对象断开了白色对象的引用(直接或间接的引用);即灰色对象原来成员变量的引用发生了变化。
- 黑色对象重新引用了该白色对象;即黑色对象成员变量增加了新的引用。
我们只要破坏其中一个条件就可以解决这个问题,而解决这个问题就需要用到读屏障和写屏障,在jvm的垃圾回收器中,zgc使用的是读屏障,笔者有篇相关博客专门介绍了zgc的技术内幕(https://my.oschina.net/u/3645114/blog/5060830),而我们现在说的g1则是使用的写屏障,准确的说是SATB+写屏障(cms用的是写屏障+增量更新)。
写屏障是在对象属性引用另一个对象的时候才会触发,我们先写一段这样的java代码:
public class Test {
public static void main(String[] args) {
A a = new A();
B b = new B();
//这里我们将A对象的两个属性以不同方式修改引用
//1.public修饰的b属性直接修改
//2.private修饰的c属性用set方法修改
a.b = b;
a.b = null;
a.setC(b);
a.setC(null);
}
}
public class A {
public B b;
private B c;
public void setC(B c) {
this.c = c;
}
}
public class B {
}
因为java是先编译成.class字节码文件,之后由jvm将字节码逐行进行解释执行(当然弱代码执行的次数达到一定阈值,也会将其编译成机器码,本文重点不在这里,笔者就不过多阐述)
我们将刚才写的代码编译成.class文件,用字节码反编译器查看下字节码:
A.class 的set方法
0 aload_0
1 aload_1
//我们看到这里调用了putfield字节码
2 putfield #2 <B.a : Ljava/lang/String;>
5 return
Test.class 的main方法
0 new #2 <A>
3 dup
4 invokespecial #3 <A.<init> : ()V>
7 astore_1
8 new #4 <B>
11 dup
12 invokespecial #5 <B.<init> : ()V>
15 astore_2
//这里是两个入栈操作,后面我们会讲到
16 aload_1
17 aload_2
//我们看到这里调用了putfield字节码
18 putfield #6 <A.b : LB;>
21 aload_1
22 aconst_null
//我们看到这里调用了putfield字节码
23 putfield #6 <A.b : LB;>
26 aload_1
27 aload_2
28 invokevirtual #7 <A.setC : (LB;)V>
31 aload_1
32 aconst_null
33 invokevirtual #7 <A.setC : (LB;)V>
36 return
由此可见putfield字节码命令就是我们这次查看源码的入口啦!
从jdk的源码中找到putfield的字节码命令,在templateTable.cpp中,这个文件是模板解释器,我们简单介绍下,模板解释器是字节码解释器(早期版本jdk的解释器)的优化,早期字节码解释器是逐条翻译,效率低下现在已经不用了,而模板解释器是将每一条字节码与一个模板函数(主要是汇编)关联,用模板函数直接生成机器码从而提高性能。
我们来看看putfield的定义:
void TemplateTable::initialize() {
......
//def方法是用来创建模板的,我们可以简单理解成会将字节码putfield和putfield模板进行关联
//当碰到putfield字节码,就会调用putfield函数模板
def(Bytecodes::_putfield, ubcp|____|clvm|____, vtos, vtos, putfield,f2_byte);
}
我们直接来看putfield函数模板:
//putfield模板
void TemplateTable::putfield(int byte_no) {
//第二个参数是是否是static属性
putfield_or_static(byte_no, false);
}
//我们看到这个方法里就由很多封装的汇编指令了,我们略过一些汇编指令,来看下写屏障的核心逻辑
void TemplateTable::putfield_or_static(int byte_no, bool is_static) {
......
//获取属性的地址(用对象和属性的偏移量封装成address)
const Address field(obj, off, Address::times_1);
......
// 对象类型
{
//这个方法会出栈一个对象引用,并将其放入rax寄存器(内存寄存器)中
//这里解释下,我们的例子中字节码是这样的
//aload_1
//aload_2
//putfield
//局部变量表中编号1是引用a, 编号2是引用b,都是引用类型,存的都是地址
//在执行aload_2前会把aload_1加载的a引用入栈
//在执行putfield前会把aload_2加载的b引用入栈
//所以这里第一次出栈是b的引用
__ pop(atos);
//第二次出栈是a的引用
if (!is_static) pop_and_check_object(obj);
//存储对象的方法,我们进去看下
do_oop_store(_masm, field, rax, _bs->kind(), false);
if (!is_static) {
patch_bytecode(Bytecodes::_fast_aputfield, bc, rbx, true, byte_no);
}
//跳到结束
__ jmp(Done);
}
//后面是一些其他基本类型,这里就不进行展开
......
}
//这个方法逻辑还是比较清晰的
//这里注意obj是可以理解为a.b这个引用,后文会统一用obj代替a.b这个引用
//val也是指向B对象的引用
static void do_oop_store(InterpreterMacroAssembler* _masm,
Address obj,
Register val,
BarrierSet::Name barrier,
bool precise) {
//根据屏障类型判断
switch (barrier) {
//g1这里会走这个分支
case BarrierSet::G1SATBCT:
case BarrierSet::G1SATBCTLogging:
{
//这里判断如果obj不是属性,则直接将obj的值传输到rdx寄存器(本案例中不会进入这里)
if (obj.index() == noreg && obj.disp() == 0) {
if (obj.base() != rdx) {
__ movq(rdx, obj.base());
}
} else {
//这里会把传入的a引用地址传输到rdx寄存器
__ leaq(rdx, obj);
}
//写前屏障,主要是SATB处理
//这里的横线__是汇编器的别名,根据不同的系统会调用不同的汇编器
//本文我们只看64位linux的代码
//rdx和rbx都是内存寄存器
//rdx此时已经存储了obj的地址
__ g1_write_barrier_pre(rdx /* obj */,
rbx /* pre_val */,
r15_thread /* thread */,
r8 /* tmp */,
val != noreg /* tosca_live */,
false /* expand_call */);
//如果对象是null则进入这个方法,在a.b上存空值
if (val == noreg) {
__ store_heap_oop_null(Address(rdx, 0));
} else {
......
//把指向b对象的引用存到a.b上
//准确的说是把引用存到本例中A对象的b属性偏移量上
__ store_heap_oop(Address(rdx, 0), val);
//写后屏障
__ g1_write_barrier_post(rdx /* store_adr */,
new_val /* new_val */,
r15_thread /* thread */,
r8 /* tmp */,
rbx /* tmp2 */);
}
}
break;
//非g1会走这个分支,我们就不再展开
case BarrierSet::CardTableModRef:
case BarrierSet::CardTableExtension:
{
if (val == noreg) {
__ store_heap_oop_null(obj);
} else {
__ store_heap_oop(obj, val);
if (!precise || (obj.index() == noreg && obj.disp() == 0)) {
__ store_check(obj.base());
} else {
__ leaq(rdx, obj);
__ store_check(rdx);
}
}
}
break;
......
}这里涉及到的入栈出栈的知识点是——栈顶缓存,网上有许多关于这方面的文章,有兴趣的读者可以自行了解下,这里就不做过多介绍。
我们看到在引用对象的方法之前和之后都由屏障,类似切面,我们来看看这两个屏障方法:
//找到x86架构的汇编器文件macroAssembler_x86.cpp
//写前屏障方法
void MacroAssembler::g1_write_barrier_pre(Register obj,
Register pre_val,
Register thread,
Register tmp,
bool tosca_live,
bool expand_call) {
//前面很多封装的汇编指令我们忽略,会做一些检测
......
//如果obj不为空,我们就根据obj引用获取其之前引用的对象的地址
if (obj != noreg) {
load_heap_oop(pre_val, Address(obj, 0));
}
//这个命令其实是比较之前的对象是不是空值,如果是空值则不继续执行
cmpptr(pre_val, (int32_t) NULL_WORD);
jcc(Assembler::equal, done);
......
//这里是false
if (expand_call) {
LP64_ONLY( assert(pre_val != c_rarg1, "smashed arg"); )
pass_arg1(this, thread);
pass_arg0(this, pre_val);
MacroAssembler::call_VM_leaf_base(CAST_FROM_FN_PTR(address, SharedRuntime::g1_wb_pre), 2);
} else {
//这里会用汇编指令调用SharedRuntime::g1_wb_pre这个方法
call_VM_leaf(CAST_FROM_FN_PTR(address, SharedRuntime::g1_wb_pre), pre_val, thread);
}
......
}
//真正的写前屏障方法,JRT_LEAF可以理解是一个定义方法的宏
JRT_LEAF(void, SharedRuntime::g1_wb_pre(oopDesc* orig, JavaThread *thread))
if (orig == NULL) {
assert(false, "should be optimized out");
return;
}
//将对象的指针加入satb标记队列
thread->satb_mark_queue().enqueue(orig);
JRT_END
//写后屏障方法
void MacroAssembler::g1_write_barrier_post(Register store_addr,
Register new_val,
Register thread,
Register tmp,
Register tmp2) {
#ifdef _LP64
assert(thread == r15_thread, "must be");
#endif // _LP64
Address queue_index(thread, in_bytes(JavaThread::dirty_card_queue_offset() +
PtrQueue::byte_offset_of_index()));
Address buffer(thread, in_bytes(JavaThread::dirty_card_queue_offset() +
PtrQueue::byte_offset_of_buf()));
BarrierSet* bs = Universe::heap()->barrier_set();
CardTableModRefBS* ct = (CardTableModRefBS*)bs;
assert(sizeof(*ct->byte_map_base) == sizeof(jbyte), "adjust this code");
Label done;
Label runtime;
//下面几条命令涉及到汇编逻辑比较,有兴趣的读者可以自行查阅,笔者这里就不进行展开
//判断是否跨regions
//先将引用的地址放到r8寄存器(tmp参数上个方法传入的)中
//再将新对象的地址和r8中的地址进行异或运算,结果存入r8中
//之后将r8的结果逻辑右移LogOfHRGrainBytes位(region大小的log指数+1),并将移出的最后一位加入cf指示器
//最后判断cf中是0还是1即可判断store_addr与new_val两个地址之间是否相差一个region大小
//0即不相差,1即相差
movptr(tmp, store_addr);
xorptr(tmp, new_val);
shrptr(tmp, HeapRegion::LogOfHRGrainBytes);
jcc(Assembler::equal, done);
//判断是否为空
cmpptr(new_val, (int32_t) NULL_WORD);
jcc(Assembler::equal, done);
const Register card_addr = tmp;
const Register cardtable = tmp2;
//将存储的地址赋值给card_addr变量
movptr(card_addr, store_addr);
//将地址逻辑右移card_shift个位,可以理解为计算出其所属card的index
shrptr(card_addr, CardTableModRefBS::card_shift);
//加载卡表数组的基址的偏移量到cardtable
movptr(cardtable, (intptr_t)ct->byte_map_base);
//加上卡表数组的基址偏移量即可算出card在card数组中的有效地址
addptr(card_addr, cardtable);
//判断是否是young区的卡,如果是则不继续执行
cmpb(Address(card_addr, 0), (int)G1SATBCardTableModRefBS::g1_young_card_val());
jcc(Assembler::equal, done);
//判断是否已经是脏卡,如果是则不继续执行
cmpb(Address(card_addr, 0), (int)CardTableModRefBS::dirty_card_val());
jcc(Assembler::equal, done);
//将card赋值脏卡
movb(Address(card_addr, 0), (int)CardTableModRefBS::dirty_card_val());
......
//执行写后屏障方法
call_VM_leaf(CAST_FROM_FN_PTR(address, SharedRuntime::g1_wb_post), card_addr, thread);
......
}
//真正的写后屏障
JRT_LEAF(void, SharedRuntime::g1_wb_post(void* card_addr, JavaThread* thread))
//将card加入dcq队列
thread->dirty_card_queue().enqueue(card_addr);
JRT_END
这里用到的汇编命令比较多,笔者将几步关键步骤进行了标注,如果有兴趣,读者可以自行了解下相关命令,这里就不进行过多讲解。
到这里我们都知道g1修改对象属性引用时会使用的两种写屏障,并且为了提高效率都是先将要处理的数据放到队列中:
1.写前屏障——处理SATB(本质是快照,用于解决并发标记时修改引用可能会造成漏标的问题),将修改前引用的对象的地址加入satb队列,待到gc并发标记的时候处理。(关于写前屏障本文不重点介绍,以后笔者会介绍GC相关的文章中再介绍)
2.写后屏障——找到对应的card标记为dirty_card,加入dirty_card队列
本文我们重点关注下写后屏障,通过上面的源码分析,我们已经看到被修改过引用所处的card都已经被标记为dirty_card,即将卡表数组(本质是字节数组,元素可以理解为是一个标志)中对对应元素进行修改为dirty_card。说到card(卡页),dirty_card(脏卡),我们不得不先从他们的起源card_table(卡表)说起。
二.卡表(card_table)
在写后屏障的源码中有一段关于card计算的汇编代码,可能比较难以理解,笔者在这里画个图来方便解释,通过这张图我们也可以理解卡表,卡页,脏卡的概念:

结合图和我们之前看的写屏障的源码,我们概括下卡表,卡页,脏卡还有写屏障的关系:
卡表(card_table)全局只有一个可以理解为是一个bitmap,并且其中每个元素即是卡页(card)与堆中的512字节内存相互映射,当这512个字节中的引用发生修改时,写屏障就会把这个卡页标记为脏卡(dirty_card)。
接下来我们看看卡表创建的源码:
//卡表相关类的初始化列表
CardTableModRefBS::CardTableModRefBS(MemRegion whole_heap,
int max_covered_regions):
ModRefBarrierSet(max_covered_regions),
_whole_heap(whole_heap),
_guard_index(cards_required(whole_heap.word_size()) - 1),
_last_valid_index(_guard_index - 1),
_page_size(os::vm_page_size()),
_byte_map_size(compute_byte_map_size())
{
.....
//申请一段内存空间,大小为_byte_map_size
//且没有传入映射内存映射的基础地址,即从随机地址映射
//底层会调内核mmap(),这里就不进行展开
ReservedSpace heap_rs(_byte_map_size, rs_align, false);
MemTracker::record_virtual_memory_type((address)heap_rs.base(), mtGC);
...
//赋值给卡表
_byte_map = (jbyte*) heap_rs.base();
//计算偏移量
byte_map_base = _byte_map - (uintptr_t(low_bound) >> card_shift);
.....
}网上许多文章会说卡表是在堆中的,然而从源码中我们可以看到严格来说并不是属于java_heap管理的,而是一段额外的数组进行管理。
我们再看看java_heap内存申请的代码:
//申请堆内存的方法,会在申请card_table之前申请
ReservedSpace Universe::reserve_heap(size_t heap_size, size_t alignment) {
......
//计算堆的地址
char* addr = Universe::preferred_heap_base(total_reserved, alignment, Universe::UnscaledNarrowOop);
//total_reserved是最大堆内存
//申请内存,这里会传入地址从特定地址开始申请,默认从0开始申请最大堆内存
ReservedHeapSpace total_rs(total_reserved, alignment, use_large_pages, addr);
.....
return total_rs;
}
//进入下面的初始化列表方法
ReservedHeapSpace::ReservedHeapSpace(size_t size, size_t alignment,
bool large, char* requested_address) :
//ReservedHeapSpace是ReservedSpace的子类底层还是会调用mmap()
ReservedSpace(size, alignment, large,
requested_address,
(UseCompressedOops && (Universe::narrow_oop_base() != NULL) &&
Universe::narrow_oop_use_implicit_null_checks()) ?
lcm(os::vm_page_size(), alignment) : 0) {
if (base() > 0) {
//注意这里标记的是mtJavaHeap,即为javaHeap申请的内存
MemTracker::record_virtual_memory_type((address)base(), mtJavaHeap);
}
protect_noaccess_prefix(size);
}由于card_table在heap之后才会申请创建,且是随机映射,而heap是根据对应地址去映射,所以card_table并不是使用的heap空间。
三.记忆集合(Remembered Set)
了解了卡表和写屏障等相关知识,我们就可以继续看源码了,在应用中不免会存在跨代的引用关系,我们在youngGC时就不得不扫描老年代的region,甚至整个老年代,而老年代占堆的比例是相当大的,所以为了节省开销,增加效率就有了记忆集合(Remembered Set),专门用来记录跨代引用,方便我们在GC的时候直接处理记忆集合从而避免遍历老年代,在每个region中都有一个记忆集合。
怎样才能完整的记录所有的跨代引用呢?再jvm中我们其实借助的是写屏障和卡表来记录,每次的引用修改都会执行我们的写屏障方法,而写屏障方法会把对应位置的卡页标记为脏卡,并加入脏卡队列中,这样所有的有效引用关关系都会在脏卡队列中,只要我们处理脏卡队列,就可以从中过滤出所有跨代引用。
脏卡队列一般是Refine线程异步处理,Refine线程中存在白,绿,黄,红四个标记,不同的标记处理脏卡队列的refine线程数不一样,当到达红标记时,Mutator线程(java应用线程)也参与处理(关于标记部分网上由许多文章讲的比较详细,笔者在这里就不过多阐述)。我们接着写屏障的源码继续看:
JRT_LEAF(void, SharedRuntime::g1_wb_post(void* card_addr, JavaThread* thread))
//获取java线程中的dcq将卡页入列
//enqueue入列方法最终会调用脏卡队列的父类PtrQueue的入列方法enqueue
thread->dirty_card_queue().enqueue(card_addr);
JRT_END
//脏卡队列类:DirtyCardQueue 继承 PtrQueue
//脏卡队列集合:DirtyCardQueueSet 继承 PtrQueueSet
//PtrQueue的入列方法
void enqueue(void* ptr) {
if (!_active) return;
//我们直接看这个方法
else enqueue_known_active(ptr);
}
//PtrQueue(DirtyCardQueue)内部有个_buf可以理解为时一个数组,默认容量是256
void PtrQueue::enqueue_known_active(void* ptr) {
//_index是下标,与一般下标不一样的是只有初始化和_buf满时_index会为0
while (_index == 0) {
//这个方法只有在初始化和扩容的时候会进入
handle_zero_index();
}
//每入列一个元素_index会减少
_index -= oopSize;
_buf[byte_index_to_index((int)_index)] = ptr;
}
//我们看下handle_zero_index()方法
void PtrQueue::handle_zero_index() {
//判断是初始化还是扩容为null则为初始化
//true为扩容
if (_buf != NULL) {
......
//判断是否有锁,这里只有shared dirty card queue会是true,因为shared_dirty_card_queue可能会有
//多个线程操作,关于shared dirty card queue笔者在讲youngGC的文章中有介绍,这里就不再阐述
if (_lock) {
void** buf = _buf; // local pointer to completed buffer
_buf = NULL; // clear shared _buf field
locking_enqueue_completed_buffer(buf); // enqueue completed buffer
if (_buf != NULL) return;
} else {
//我们来看这里,写屏障会调用这个方法
if (qset()->process_or_enqueue_complete_buffer(_buf)) {
_sz = qset()->buffer_size();
_index = _sz;
return;
}
}
}
//初始化queue申请_buf,修改_index
_buf = qset()->allocate_buffer();
_sz = qset()->buffer_size();
_index = _sz;
}
//这里会调用PtrQueueSet的方法
//每个java线程都有自己的DirtyCardQueue(PtrQueue)
//所有的DirtyCardQueue都关联一个全局DirtyCardQueueSet(PtrQueueSet)
bool PtrQueueSet::process_or_enqueue_complete_buffer(void** buf) {
//判断是否是java线程
if (Thread::current()->is_Java_thread()) {
//如果是java线程判断是否到达红标记(_max_completed_queue即red标记,在DirtyCardQueueSet初始化时会传入)
if (_max_completed_queue == 0 || _max_completed_queue > 0 &&
_n_completed_buffers >= _max_completed_queue + _completed_queue_padding) {
//达到红标记则自己处理
bool b = mut_process_buffer(buf);
if (b) {
return true;
}
}
}
//这个方法最后会将满的_buf加入DirtyCardQueueSet,自己再重新申请一个buf
enqueue_complete_buffer(buf);
return false;
}这里我们稍微解释下DirtyCardQueue和DirtyCardQueueSet,每个java线程都有一个私有的DirtyCardQueue(PtrQueue),所有的DirtyCardQueue都关联一个全局DirtyCardQueueSet(PtrQueueSet),每个DirtyCardQueue默认大小为256,当一个DirtyCardQueue满了之后会将其中满的数组(_buf)添加到DirtyCardQueueSet中,并为DirtyCardQueue重新申请一个新的数组(_buf),关于这方面的知识笔者在之前将youngGC的文章也有过介绍,有兴趣的读者也可以看下。
其实Mutator线程(java应用线程)和Refine线程处理脏卡队列的最终方法都是一样的,只不过调用过程不一样,我们继续看下Mutator线程(java应用线程):
bool DirtyCardQueueSet::mut_process_buffer(void** buf) {
bool already_claimed = false;
//获取当前java线程
JavaThread* thread = JavaThread::current();
//获取线程的par_id
int worker_i = thread->get_claimed_par_id();
//如果worker_i不为-1就证明线程已经申请过par_id
if (worker_i != -1) {
already_claimed = true;
} else {
//否则重新获取个par_id
worker_i = _free_ids->claim_par_id();
//存储par_id
thread->set_claimed_par_id(worker_i);
}
bool b = false;
if (worker_i != -1) {
//这是处理脏卡队列的核心方法
//_closure参数是一个迭代器RefineCardTableEntryClosure
//buf是之前传入的脏卡队列中的数组
b = DirtyCardQueue::apply_closure_to_buffer(_closure, buf, 0,
_sz, true, worker_i);
if (b) Atomic::inc(&_processed_buffers_mut);
//如果是本次调用申请的par_id则要归还
if (!already_claimed) {
// 归还par_id
_free_ids->release_par_id(worker_i);
//同时将线程par_id设置为-1
thread->set_claimed_par_id(-1);
}
}
return b;
}
bool DirtyCardQueue::apply_closure_to_buffer(CardTableEntryClosure* cl,
void** buf,
size_t index, size_t sz,
bool consume,
int worker_i) {
if (cl == NULL) return true;
//遍历
for (size_t i = index; i < sz; i += oopSize) {
int ind = byte_index_to_index((int)i);
//获取card
jbyte* card_ptr = (jbyte*)buf[ind];
if (card_ptr != NULL) {
if (consume) buf[ind] = NULL;
//真正处理card的逻辑
if (!cl->do_card_ptr(card_ptr, worker_i)) return false;
}
}
return true;
}到这里我们先停一下,一起看下Refine线程是怎么处理脏卡队列的:
//由于篇幅有限,笔者直接截取ConcurrentG1RefineThread类的run()方法
void ConcurrentG1RefineThread::run() {
......
do {
......
//调用脏卡队列集合的方法
//最后一个参数是绿标记
} while (dcqs.apply_closure_to_completed_buffer(_worker_id + _worker_id_offset, cg1r()->green_zone()));
......
}
bool DirtyCardQueueSet::apply_closure_to_completed_buffer(int worker_i,
int stop_at,
bool during_pause) {
//传入的还是_closure闭包即RefineCardTableEntryClosure
return apply_closure_to_completed_buffer(_closure, worker_i,
stop_at, during_pause);
}
bool DirtyCardQueueSet::apply_closure_to_completed_buffer(CardTableEntryClosure* cl,
int worker_i,
int stop_at,
bool during_pause) {
//这个方法是获取已经满的buf
//stop_at是之前传入的绿标记,即Refine线程只处理绿标记以上的,而白标记到绿标记的部分只会在gc的时候处理
BufferNode* nd = get_completed_buffer(stop_at);
//进行处理
bool res = apply_closure_to_completed_buffer_helper(cl, worker_i, nd);
if (res) Atomic::inc(&_processed_buffers_rs_thread);
return res;
}
bool DirtyCardQueueSet::
apply_closure_to_completed_buffer_helper(CardTableEntryClosure* cl,
int worker_i,
BufferNode* nd) {
if (nd != NULL) {
void **buf = BufferNode::make_buffer_from_node(nd);
size_t index = nd->index();
//可以看到还是调用和Mutator同样的方法
//apply_closure_to_buffer
bool b =
DirtyCardQueue::apply_closure_to_buffer(cl, buf,
index, _sz,
true, worker_i);
if (b) {
deallocate_buffer(buf);
return true; // In normal case, go on to next buffer.
} else {
enqueue_complete_buffer(buf, index);
return false;
}
} else {
return false;
}
}我们看到Refine和Mutator最终的处理方式都是调用apply_closure_to_buffer方法之后调用闭包的do_card_ptr()
关于do_card_ptr()这个方法,笔者在讲youngGC的文章中也提到过,只不过在youngGC中用的的闭包和现在提到的闭包不一样,
在youngGC中是:RefineRecordRefsIntoCSCardTableEntryClosure
在Refine和Mutator线程中都是:RefineCardTableEntryClosure
我们分别把这两个闭包的do_card_ptr方法拿出来看看:
//RefineCardTableEntryClosure
bool do_card_ptr(jbyte* card_ptr, int worker_i) {
bool oops_into_cset = _g1rs->refine_card(card_ptr, worker_i, false);
if (_concurrent && _sts->should_yield()) {
return false;
}
return true;
}
//RefineRecordRefsIntoCSCardTableEntryClosure
bool do_card_ptr(jbyte* card_ptr, int worker_i) {
if (_g1rs->refine_card(card_ptr, worker_i, true)) {
_into_cset_dcq->enqueue(card_ptr);
}
return true;
}我们看到最终都是调用这个方法_g1rs->refine_card()只不过第三个参数不同,关于这个参数我们后面会讲到。
_g1rs是G1RemSet类,是G1记忆集合的基类,到这里就涉及到记忆集合了,我们继续看下这个方法refine_card():
bool G1RemSet::refine_card(jbyte* card_ptr, int worker_i,
bool check_for_refs_into_cset) {
//判断card是否是脏卡,如果不是则直接返回
if (*card_ptr != CardTableModRefBS::dirty_card_val()) {
return false;
}
//获取card所映射的内存开始地址
HeapWord* start = _ct_bs->addr_for(card_ptr);
//找到card所在的region
HeapRegion* r = _g1->heap_region_containing(start);
//判断是否为空
if (r == NULL) {
return false;
}
//判断是不是young,这里是判断引用所在的region是否是young,因为在youngGc时,我们只关注old->young的引用关系
//这样才能避免我们遍历所有老年代,如果是young->young或young->old则只需要判断其是否在gcRoot的引用链
if (r->is_young()) {
return false;
}
//判断在不在回收集合中,引用所在的region在回收集合中,就证明其在下次GC时会被扫描,所以也不用进入记忆集合
if (r->in_collection_set()) {
return false;
}
//热卡缓存,判断是否用了热卡缓存,如果用了则加入
G1HotCardCache* hot_card_cache = _cg1r->hot_card_cache();
if (hot_card_cache->use_cache()) {
card_ptr = hot_card_cache->insert(card_ptr);
if (card_ptr == NULL) {
// There was no eviction. Nothing to do.
return false;
}
start = _ct_bs->addr_for(card_ptr);
r = _g1->heap_region_containing(start);
if (r == NULL) {
return false;
}
}
//计算card映射的内存终点
HeapWord* end = start + CardTableModRefBS::card_size_in_words;
//声明脏区域,即card映射的内存区
MemRegion dirtyRegion(start, end);
#if CARD_REPEAT_HISTO
init_ct_freq_table(_g1->max_capacity());
ct_freq_note_card(_ct_bs->index_for(start));
#endif
OopsInHeapRegionClosure* oops_in_heap_closure = NULL;
//这个参数时之前我们提到的第三个参数
//youngGC在这里是true会使用youngGC的闭包,会将引用push到一个队列中(笔者在youngGC的文章中讲过)
//refine这里则是false,oops_in_heap_closure为Null
if (check_for_refs_into_cset) {
oops_in_heap_closure = _cset_rs_update_cl[worker_i];
}
//之后声明了许多闭包,我们重点关注下这个,是更新Rs或者入列引用的闭包
G1UpdateRSOrPushRefOopClosure update_rs_oop_cl(_g1,
_g1->g1_rem_set(),
oops_in_heap_closure,
check_for_refs_into_cset,
worker_i);
update_rs_oop_cl.set_from(r);
G1TriggerClosure trigger_cl;
FilterIntoCSClosure into_cs_cl(NULL, _g1, &trigger_cl);
G1InvokeIfNotTriggeredClosure invoke_cl(&trigger_cl, &into_cs_cl);
G1Mux2Closure mux(&invoke_cl, &update_rs_oop_cl);
//这个闭包封装了G1UpdateRSOrPushRefOopClosure,可以看到当oops_in_heap_closure为null
//会直接使用update_rs_oop_cl
FilterOutOfRegionClosure filter_then_update_rs_oop_cl(r,
(check_for_refs_into_cset ?
(OopClosure*)&mux :
(OopClosure*)&update_rs_oop_cl));
bool filter_young = true;
//我们进入这个方法看下
HeapWord* stop_point =
r->oops_on_card_seq_iterate_careful(dirtyRegion,
&filter_then_update_rs_oop_cl,
filter_young,
card_ptr);
......
}
HeapWord* HeapRegion::oops_on_card_seq_iterate_careful(MemRegion mr,
FilterOutOfRegionClosure* cl,
bool filter_young,
jbyte* card_ptr) {
//先判断是否时年轻代(略)
.....
//这里会把card脏标记去掉,进入rset的card都是干净的标记的脏卡
if (card_ptr != NULL) {
*card_ptr = CardTableModRefBS::clean_card_val();
OrderAccess::storeload();
}
// 计算 Region的边界
HeapWord* const start = mr.start();
HeapWord* const end = mr.end();
//寻找跨越start的对象初始地址,HeapWord* 是一个指向堆的指针
HeapWord* cur = block_start(start);
oop obj;
HeapWord* next = cur;
//处理跨越start的对象
while (next <= start) {
cur = next;
obj = oop(cur);
//对象在region上是连续排列的,如果为null则后面没有对象了
if (obj->klass_or_null() == NULL) {
return cur;
}
next = (cur + obj->size());
}
//判断对象是否存活
if (!g1h->is_obj_dead(obj)) {
//这里会调用很多宏命令定义的方法,最后会用传入的闭包G1UpdateRSOrPushRefOopClosure进行遍历
obj->oop_iterate(cl, mr);
}
//继续查看后面的对象
while (cur < end) {
obj = oop(cur);
if (obj->klass_or_null() == NULL) {
// Ran into an unparseable point.
return cur;
};
next = (cur + obj->size());
//判断是否存活
if (!g1h->is_obj_dead(obj)) {
if (next < end || !obj->is_objArray()) {
//对象不跨region,也不是数组
obj->oop_iterate(cl);
} else {
//处理array
obj->oop_iterate(cl, mr);
}
}
cur = next;
}
return NULL;
}
看到这里读者可能会疑惑为什么计算出card映射的区域之后要遍历?因为之前我们讲过每个卡页映射的区域都是512字节,当这个卡页被标记为脏时,说明这512字节中会存在被修改的引用,所以我们要遍历这个区域的所有引用。
接下来就可以锁定核心方法,我们之前提到的闭包G1UpdateRSOrPushRefOopClosure的G1UpdateRSOrPushRefOopClosure::do_oop_nv()方法:
//闭包方法
inline void G1UpdateRSOrPushRefOopClosure::do_oop_nv(T* p) {
//将P转换为oop
oop obj = oopDesc::load_decode_heap_oop(p);
//获取被引用对象所在的region
HeapRegion* to = _g1->heap_region_containing(obj);
//_from是之前set进来的原引用持有对象所在card所在的region
if (to != NULL && _from != to) {
//这里是之前refine_card方法传入的第三个参数,存在三种情况
// 1.Refine线程异步更新,则传入false,直接更新rset
// 2.youngGC时进行updateRset时,传入的是true,如果引用的对象属于回收集合则push到引用迁移集合
// 之后会进行对象copy和修改引用
// 3.youngGC是引用对象不属于回收集合则更新rset
if (_record_refs_into_cset && to->in_collection_set()) {
if (!self_forwarded(obj)) {
_push_ref_cl->do_oop(p);
}
return;
}
//更新to的RSet
to->rem_set()->add_reference(p, _worker_i);
}
}这里我们可以看到在youngGC时被引用的对象如果在回收集合中则会直接Push到迁移集合等待后面迁移处理,在Refine和Mutator线程中则会更新Rem_set,即记忆集合。
这里我们只关注更新记忆集合的方法:
void OtherRegionsTable::add_reference(OopOrNarrowOopStar from, int tid) {
......
//计算引用所在的card
int from_card = (int)(uintptr_t(from) >> CardTableModRefBS::card_shift);
......
//获取card所在的region和region_id
HeapRegion* from_hr = _g1h->heap_region_containing_raw(from);
RegionIdx_t from_hrs_ind = (RegionIdx_t) from_hr->hrs_index();
//如果在粗粒度位图中,直接返回
//这个粗粒度位图的key是region_id
if (_coarse_map.at(from_hrs_ind)) {
return;
}
//找到细粒度PerRegionTable
//region_id根据细粒度PerRegionTable的最大容量取模
size_t ind = from_hrs_ind & _mod_max_fine_entries_mask;
//获取对应的细粒度PerRegionTable
PerRegionTable* prt = find_region_table(ind, from_hr);
//PerRegionTable不存在
if (prt == NULL) {
MutexLockerEx x(&_m, Mutex::_no_safepoint_check_flag);
//再次确认是否已经存在对应ID的PerRegionTable
prt = find_region_table(ind, from_hr);
if (prt == NULL) {
......
//获取card_index
CardIdx_t card_index = from_card - from_hr_bot_card_index;
if (G1HRRSUseSparseTable &&
//直接加入稀疏表,如果成功则返回,失败则继续执行
_sparse_table.add_card(from_hrs_ind, card_index)) {
......
return;
} else {
//打印稀疏表满了的日志
if (G1TraceHeapRegionRememberedSet) {
gclog_or_tty->print_cr(" [tid %d] sparse table entry "
"overflow(f: %d, t: %d)",
tid, from_hrs_ind, cur_hrs_ind);
}
}
//判断细粒度PerRegionTable是否满了
if (_n_fine_entries == _max_fine_entries) {
//如果满了则删除当前表并加入粗粒度位图中
prt = delete_region_table();
//再重新初始化
prt->init(from_hr, false /* clear_links_to_all_list */);
} else {
//如果没满,则证明没有这个细粒度PerRegionTable申请并与所有细粒度PerRegionTable关联
prt = PerRegionTable::alloc(from_hr);
link_to_all(prt);
}
//将新申请的或者初始化的细粒度PerRegionTable加入细粒度PerRegionTable表集合中
PerRegionTable* first_prt = _fine_grain_regions[ind];
prt->set_collision_list_next(first_prt);
_fine_grain_regions[ind] = prt;
_n_fine_entries++;
if (G1HRRSUseSparseTable) {
//获取对应的region_id稀疏表,遍历并将其加入细粒度PerRegionTable表
//对应稀疏表满了所以需要删除并退化为细粒度表
SparsePRTEntry *sprt_entry = _sparse_table.get_entry(from_hrs_ind);
for (int i = 0; i < SparsePRTEntry::cards_num(); i++) {
CardIdx_t c = sprt_entry->card(i);
if (c != SparsePRTEntry::NullEntry) {
prt->add_card(c);
}
}
//删除稀疏表
bool res = _sparse_table.delete_entry(from_hrs_ind);
}
}
}
//将card加入PerRegionTable的位图中,这个位图key是card_id
//这个方法就不进行展开
prt->add_reference(from);
......
}这里涉及了记忆集合(Rset)的三级数据结构,我们这里简单画张图讲述下:
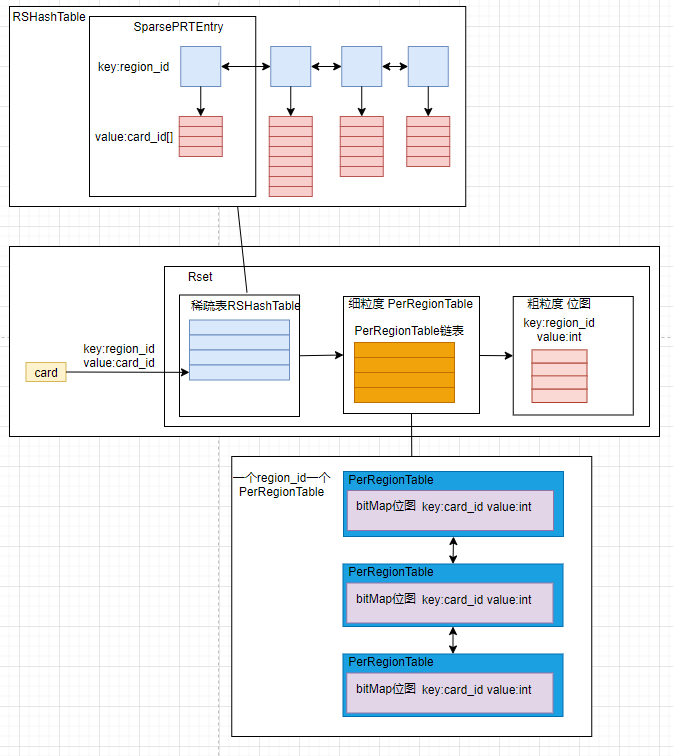
首先,根据card找到其对应的region_id和card_id,将其添加到RHashTable中,RHashTable可以看作一个hash表,key是region_id,value是card_id的数组。即先根据region_id找到对应的桶位(SparsePRTEntry),然后将card_id加入card_id数组中。若一个SparsePRTEntry满了,则会先扩容,如果达到最大容量就会退化为细粒度PerRegionTable的链表,即创建一个PerRegionTable(以region_id为维度),其内部是一个bitMap位图,key是card_id,如果对应card_id的card有跨代引用则value为1,反之则为1。当PerRegionTable链表也达到最大容量时,就会继续退化为一个粗粒度BitMap位图,key是region_id,value表示这个region是否有引用到Rset所在的region,并清空PerRegionTable。这时候虽然会丢失这个region中card到Rset所在Region的引用细节,但证明有这个region中有很多引用到Rset所在的region,所以再gc时遍历region并不会损失很多cpu性能。
至此,从写屏障到记忆集合的源码已经全部结束了。关于写屏障,卡表和记忆集合,三个简单的概念就能挖掘出如此多的细节,也令笔者非常惊讶。这部分代码功能虽然仅仅是为了破坏三色标记时漏标的条件,解决跨代引用,提升GC效率的,但其实现的细节却相当复杂繁琐。不过仔细想想,我们平时工作中,许多看似简单的功能,实现起来也需要一步一步的推衍和设计,迭代,最终才能达到目标需求,从过程上也是相互照应的。
笔者再看源码之前对于这关于写屏障,卡表和记忆集合的概念一直很模糊,从而无法理解G1的GC源码,只有真正看了关于这部分的源码,分析源码才能了解到jvm的设计原理和实现细节,并且在继续学习G1源码的路上帮助我们披荆斩棘。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK