

看动画轻松理解「链表」实现「LRU缓存淘汰算法」
source link: https://www.cxyxiaowu.com/1916.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

前几节学习了「链表」、「时间与空间复杂度」的概念,本节将结合「循环链表」、「双向链表」与 「用空间换时间的设计思想」来设计一个很有意思的缓存淘汰策略:LRU缓存淘汰算法。
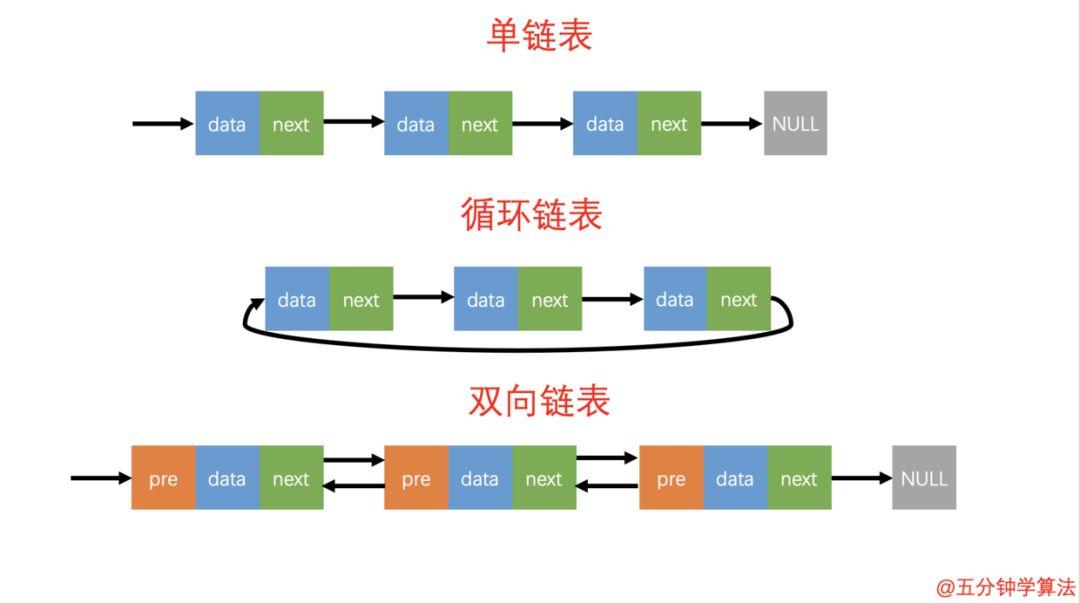 三种最常见的链表结构
三种最常见的链表结构循环链表的概念
如上图所示:单链表的尾结点指针指向空地址,表示这就是最后的结点了。而循环链表的尾结点指针是指向链表的头结点。
因此循环链表是一种特殊的单链表。它跟单链表唯一的区别就在于尾结点。它像一个环一样首尾相连,所以叫作「循环链表」。
循环链表的特点
和单链表相比,循环链表的优点是从链尾到链头比较方便,当要处理的数据具有环型结构特点时,适合采用循环链表。
双向链表概念
双向链表也叫双链表,是链表的一种,它的链接方向是双向的,它的每个数据结点中都包含有两个指针,分别指向直接后继和直接前驱。
所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
双向链表的数据结构中,会有两个比较重要的参数: pre 和 next 。
-
pre指向前一个数据结构 -
next指向下一个数据结构
 单链表与双链表的对比
单链表与双链表的对比双向链表的特点
-
与单链表对比,双链表需要多一个指针用于指向前驱节点,因此如果存储同样多的数据,双向链表要比单链表占用更多的内存空间
-
双链表的插入和删除需要同时维护 next 和 prev 两个指针。
-
双链表中的元素访问需要通过顺序访问,支持双向遍历,这就是双向链表操作的灵活性根本
双向链表的基本操作
1.添加元素。
与单向链表相对比双向链表可以在 O(1) 时间复杂度搞定,而单向链表需要 O(n) 的时间复杂度。
双向链表的添加元素包括头插法和尾插法。
 头插法和尾插法
头插法和尾插法头插法:将链表的左边称为链表头部,右边称为链表尾部。头插法是将右边固定,每次新增的元素都在左边头部增加。
尾插法:将链表的左边称为链表头部,右边称为链表尾部。尾插法是将左边固定,每次新增都在链表的右边最尾部。
2.查询元素
 查询元素
查询元素双向链表的灵活处就是知道链表中的一个元素结构就可以向左或者向右开始遍历查找需要的元素结构。因此对于一个有序链表,双向链表的按值查询的效率比单链表高一些。因为,我们可以记录上次查找的位置 p,每次查询时,根据要查找的值与 p 的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
3.删除元素
在实际的软件开发中,从链表中删除一个数据无外乎这两种情况:
-
删除结点中“值等于某个给定值”的结点
-
删除给定指针指向的结点
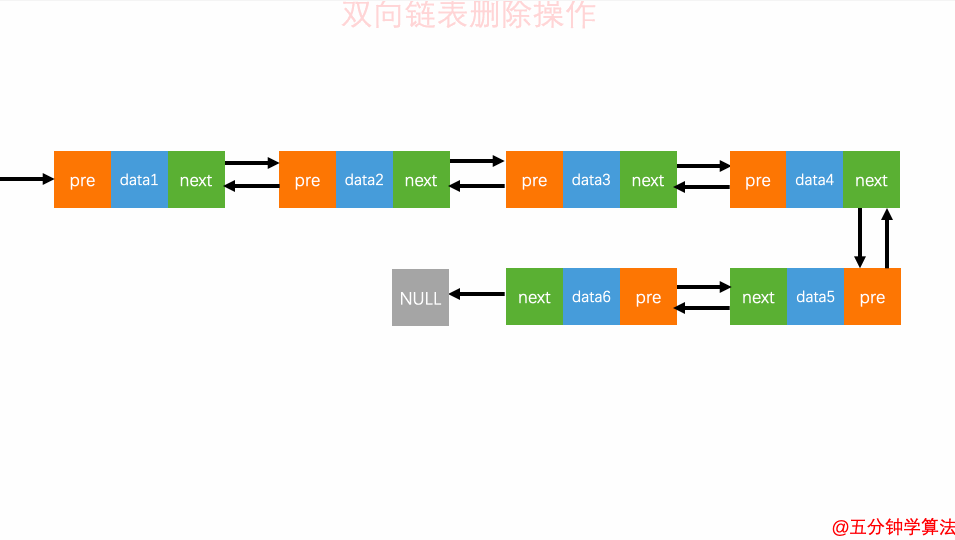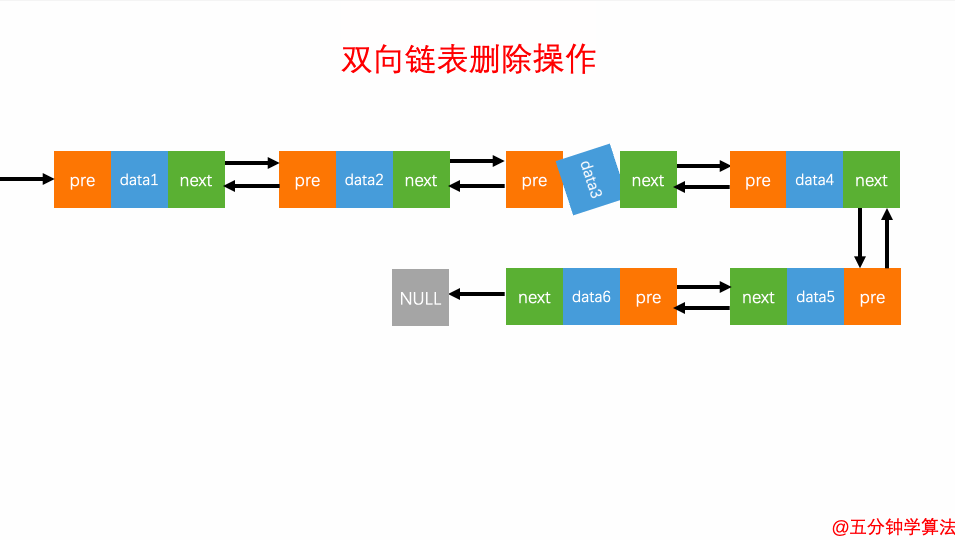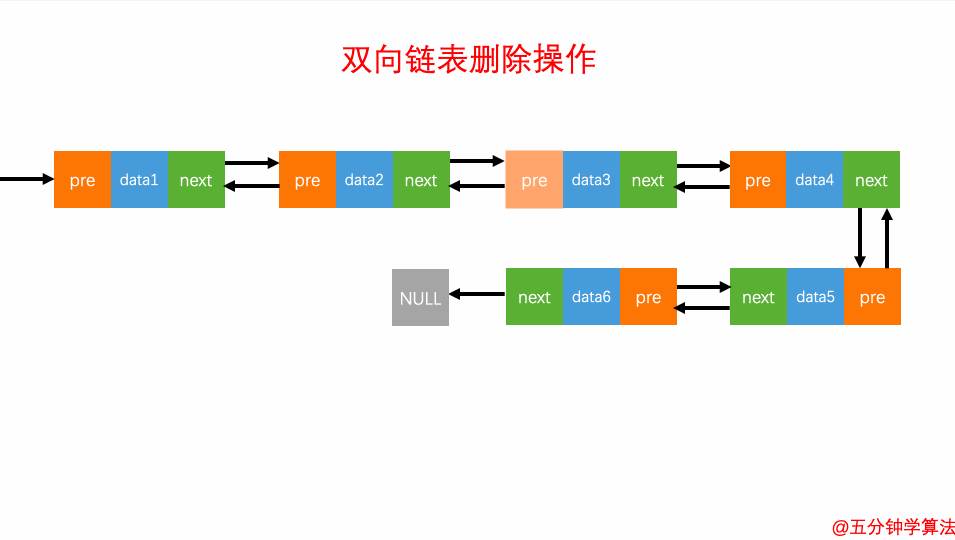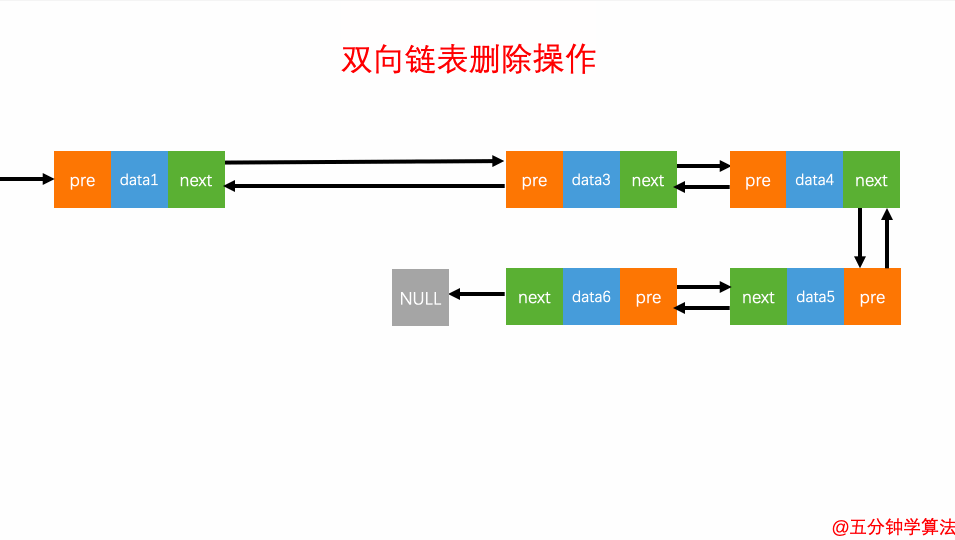 删除元素
删除元素对于双向链表来说,双向链表中的结点已经保存了前驱结点的指针,删除时不需要像单链表那样遍历。所以,针对第二种情况,单链表删除操作需要 O(n) 的时间复杂度,而双向链表只需要在 O(1) 的时间复杂度。
双向循环链表
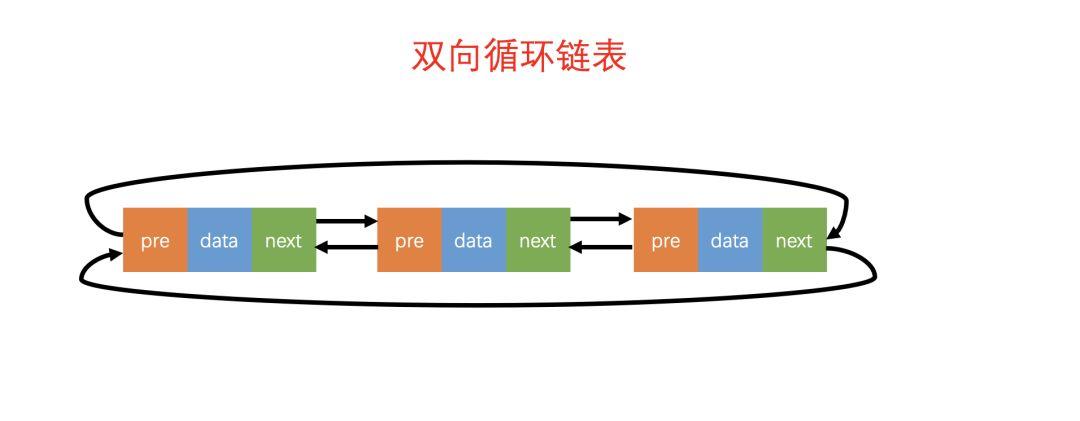 双向循环链表
双向循环链表如图所示,双向循环链表的概念很好理解:「双向链表」 + 「循环链表」的组合。
缓存淘汰策略
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常见的 CPU 缓存、数据库缓存、浏览器缓存等等。
缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。常见的策略有三种:先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。
在各个语言的第三方框架中都大量使用到了 LRU 缓存策略。程序员小吴接触到的有Java中的 「 Mybatis 」,iOS中的 「YYCache」与「Lottie」等。
LRU缓存淘汰算法
LRU是最近最少使用策略的缩写,是根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
 LRU概念
LRU概念链表实现LRU
将Cache的所有位置都用双链表连接起来,当一个位置被命中之后,通过调整链表的指向,将该位置调整到链表头的位置,新加入的Cache直接加到链表头中。
这样,在多次进行Cache操作后,最近被命中的,就会被向链表头方向移动,而没有命中的,而想链表后面移动,链表尾则表示最近最少使用的Cache。
当需要替换内容时候,链表的最后位置就是最少被命中的位置,我们只需要淘汰链表最后的部分即可。
链表实现LRU动画演示
-
如果此数据之前已经被缓存在链表中了,通过遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
-
如果此数据没有在缓存链表中,可以分为两种情况:
-
如果此时缓存未满,则将此结点直接插入到链表的头部;
-
如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。
 链表实现LRU
链表实现LRU
通过动图可以发现,如果缓存空间足够大,那么存储的数据也就足够多,通过缓存中命中数据的概率就越大,也就提高了代码的执行速度。这就是空间换时间的设计思想。
对于程序开发来说,时间复杂度和空间复杂度是可以相互转化的。说通俗一点,就是:
-
对于执行的慢的程序,可以通过消耗内存(即构造新的数据结构)来进行优化;
-
而消耗内存的程序,可以通过消耗时间来降低内存的消耗。
本篇文章的动画与图片程序员小吴花了较多时间与精力去处理,如果读者看完之后觉得有所收获,烦请点一下右下角的 「好看」。
感谢阅读:)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK