

【Python从入门到精通】(九)Python中字符串的各种骚操作你已经烂熟于心了么?【收藏...
source link: https://blog.csdn.net/u014534808/article/details/118655017
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
本文将重点介绍Python字符串的各种常用方法,字符串是实际开发中经常用到的,所有熟练的掌握它的各种用法显得尤为重要。
干货满满,建议收藏,欢迎大家一键三连哦。 小伙伴们如有问题及需要,欢迎踊跃留言哦~ ~ ~。
在前面介绍序列那一篇文章已经对字符串做了一些简要的介绍,欢迎小伙伴先看看【Python从入门到精通】(五)Python内置的数据类型-序列和字符串,没有女友,不是保姆,只有拿来就能用的干货
,这篇文章将对字符串的各种常用用法做一个详细的介绍。欢迎大家意见三联哦。
字符串拼接
通过+运算符
现有字符串码农飞哥好,,要求将字符串码农飞哥牛逼拼接到其后面,生成新的字符串码农飞哥好,码农飞哥牛逼
举个例子:
str6 = '码农飞哥好,'
# 使用+ 运算符号
print('+运算符拼接的结果=',(str6 + '码农飞哥牛逼'))
运行结果是:
+运算符拼接的结果= 码农飞哥好,码农飞哥牛逼
字符串截取(字符串切片)
切片操作是访问字符串的另一种方式,它可以访问一定范围内的元素,通过切片操作,可以生成一个新的字符串。切片操作的语法格式是:
sname[start : end : step]
各个参数的含义分别是:
- sname: 表示字符串的名称
- start:表示切片的开始索引位置(包括该位置),此参数也可以不指定,不指定的情况下会默认为0,也就是从序列的开头开始切片。
- end:表示切片的结束索引位置(不包括该位置),如果不指定,则默认为序列的长度。
- step: 表示步长,即在切片过程中,隔几个存储位置(包括当前位置)取一次元素,也就是说,如果step的值大于1,比如step为3时,则在切片取元素时,会隔2个位置去取下一个元素。
还是举个栗子说明下吧:
str1='好好学习,天天向上'
# 取出索引下标为7的值
print(str1[7])
# 从下标0开始取值,一直取到下标为7(不包括)的索引值
print(str1[0:7])
# 从下标1开始取值,一直取到下标为4(不包括)的索引值,因为step等于2,所以会隔1个元素取值
print(str1[1:4:2])
# 取出最后一个元素
print(str1[-1])
# 从下标-9开始取值,一直取到下标为-2(不包括)的索引值
print(str1[-9:-2])
运行的结果是:
向
好好学习,天天
好习
上
好好学习,天天

分割字符串
Python提供了split()方法用于分割字符串,split() 方法可以实现将一个字符串按照指定的分隔符切分成多个子串,这些子串会被保存到列表中(不包含分隔符),作为方法的返回值反馈回来。该方法的基本语法格式如下:
str.split(sep,maxsplit)
此方法中各部分参数的含义分别是:
- str: 表示要进行分割的字符串
- sep: 用于指定分隔符,可以包含多个字符,此参数默认为None,表示所有空字符,包括空格,换行符"\n"、制表符"\t"等
- maxsplit: 可选参数,用于指定分割的次数,最后列表中子串的个数最多为maxsplit+1,如果不指定或者指定为-1,则表示分割次数没有限制。
在 split 方法中,如果不指定 sep 参数,那么也不能指定 maxsplit 参数。
举例说明下:
str = 'https://feige.blog.csdn.net/'
print('不指定分割次数', str.split('.'))
print('指定分割次数为2次',str.split('.',2))
运行结果是:
不指定分割次数 ['https://feige', 'blog', 'csdn', 'net/']
指定分割次数为2次 ['https://feige', 'blog', 'csdn.net/']
合并字符串
合并字符串与split的作用刚刚相反,Python提供了join() 方法来将列表(或元组)中包含的多个字符串连接成一个字符串。其语法结构是:
newstr = str.join(iterable)
此方法各部分的参数含义是:
- newstr: 表示合并后生成的新字符串
- str: 用于指定合并时的分隔符
- iterable: 做合并操作的源字符串数据,允许以列表、元组等形式提供。
依然是举例说明:
list = ['码农飞哥', '好好学习', '非常棒']
print('通过.来拼接', '.'.join(list))
print('通过-来拼接', '-'.join(list))
运行结果是:
通过.来拼接 码农飞哥.好好学习.非常棒
通过-来拼接 码农飞哥-好好学习-非常棒
统计字符串出现的次数
count()方法用于检索指定字符串在另一字符串中出现的次数,如果检索的字符串不存在,则返回0,否则返回出现的次数。其语法结构是:
str.count(sub[,start[,end]])
此方法各部分参数的含义是:
- str: 表示原字符串
- sub: 表示要检索的字符串.
- start: 指定检索的起始位置,也就是从什么位置开始检测,如果不指定,默认从头开始检索。
- end: 指定检索的终止位置,如果不指定,则表示一直检索到结尾
举个例子说明:
str = 'https://feige.blog.csdn.net/'
print('统计.出现的次数', str.count('.'))
print('从1位置到倒数第五个位置统计.出现的次数', str.count('.', 1, -5))
运行结果是:
统计.出现的次数 3
从1位置到倒数第6个位置统计.出现的次数 2
检测字符串是否包含某子串
Python提供find方法,用于检索字符串中是否包含目标字符串,如果包含,则返回第一次出现该字符串的索引,反之,则返回-1。其语法结构是:
str.find(sub[,start[,end]])
此方法各参数的含义是:
- str: 表示原字符串
- sub: 表示要检索的目标字符串
- start: 表示开始检索的起始位置,如果不指定,则默认从头开始检索
- end: 表示结束检索的结束位置,如果不指定,则默认一直检索到结尾。
Python还提供了rfind()方法,与find()方法最大的不同在于,rfind()是从字符串右边开始检索。
依然是举例说明:
str = '码农飞哥'
print('检索是否包含字符串"飞哥"', str.find('飞哥'))
print("检索是否包含字符串'你好'", str.find('你好'))
运行结果是:
检索是否包含字符串"飞哥" 2
检索是否包含字符串'你好' -1
Python还提供了indext()方法检测字符串中是否包含某子串,方法的参数与find方法相同,唯一不同之处在于当指定的字符串不存在时,index()方法会抛出异常。在此就不在赘述了。
字符串对齐方法
Python str提供了3种可用来进行文本对齐的方法,分别是ljust(),rjust()和center()方法
- ljust()用于向指定字符串的右侧填充指定字符,从而达到左对齐文本的目的,其语法结构是:
S.ljust(width[, fillchar])
此方法中各个参数的含义是:
- S: 表示要进行填充的字符串
- width: 表示包括S本身长度在内,字符串要占的总长度
- fillchar: 作为可选参数,用来指定填充字符串时所用的字符,默认情况使用空格。
- rjust() 方法是向字符串的左侧填充指定字符,从而达到右对齐文本的目的。
- center()方法用于让文本居中,而不是左对齐或右对齐
举个例子说明下:
str1 = 'https://feige.blog.csdn.net/'
str2 = 'https://www.baidu.com/'
print("通过-实现左对齐", str1.ljust(30, '-'))
print("通过-实现左对齐", str2.ljust(30, '-'))
print("通过-实现右对齐", str1.rjust(30, '-'))
print("通过-实现右对齐", str2.rjust(30, '-'))
print("通过-实现居中对齐", str1.center(30, '-'))
print("通过-实现居中对齐", str2.center(30, '-'))
运行结果是:
通过-实现左对齐 https://feige.blog.csdn.net/--
通过-实现左对齐 https://www.baidu.com/--------
通过-实现右对齐 --https://feige.blog.csdn.net/
通过-实现右对齐 --------https://www.baidu.com/
通过-实现居中对齐 -https://feige.blog.csdn.net/-
通过-实现居中对齐 ----https://www.baidu.com/----
检索字符串是否以指定字符串开头(startswith())
startswith()方法用于检索字符串是否以指定字符串开头,如果是返回True;反之返回False。其语法结构是:
str.startswith(sub[,start[,end]])
此方法各个参数的含义是:
- str: 表示原字符串
- sub: 要检索的子串‘
- start: 指定检索开始的起始位置索引,如果不指定,则默认从头开始检索
- end: 指定检索的结束位置索引,如果不指定,则默认一直检索到结束。
举个栗子说明下:
str1 = 'https://feige.blog.csdn.net/'
print('是否是以https开头', str1.startswith('https'))
print('是否是以feige开头', str1.startswith('feige', 0, 20))
运行结果是:
是否是以https开头 True
是否是以feige开头 False
检索字符串是否以指定字符串结尾(endswith())
endswith()方法用于检索字符串是否以指定字符串结尾,如果是则返回True,反之则返回False。其语法结构是:
str.endswith(sub[,start[,end]])
此方法各个参数的含义与startswith方法相同,再此就不在赘述了。
字符串大小写转换(3种)函数及用法
Python中提供了3种方法用于字符串大小写转换
- title()方法用于将字符串中每个单词的首字母转成大写,其他字母全部转为小写。转换完成后,此方法会返回转换得到的字符串。如果字符串中没有需要被转换的字符,此方法会将字符串原封不动地返回。其语法结构是
str.title() - lower()用于将字符串中的所有大写字母转换成小写字母,转换完成后,该方法会返回新得到的子串。如果字符串中原本就都是小写字母,则该方法会返回原字符串。 其语法结构是
str.lower() - upper()用于将字符串中的所有小写字母转换成大写字母,如果转换成功,则返回新字符串;反之,则返回原字符串。其语法结构是:
str.upper()。
举例说明下吧:
str = 'feiGe勇敢飞'
print('首字母大写', str.title())
print('全部小写', str.lower())
print('全部大写', str.upper())
运行结果是:
首字母大写 Feige勇敢飞
全部小写 feige勇敢飞
全部大写 FEIGE勇敢飞

去除字符串中空格(删除特殊字符)的3种方法
Python中提供了三种方法去除字符串中空格(删除特殊字符)的3种方法,这里的特殊字符,指的是指表符(\t)、回车符(\r),换行符(\n)等。
- strip(): 删除字符串前后(左右两侧)的空格或特殊字符
- lstrip():删除字符串前面(左边)的空格或特殊字符
- rstrip():删除字符串后面(右边)的空格或特殊字符
Python的str是不可变的,因此这三个方法只是返回字符串前面或者后面空白被删除之后的副本,并不会改变字符串本身
举个例子说明下:
str = '\n码农飞哥勇敢飞 '
print('去除前后空格(特殊字符串)', str.strip())
print('去除左边空格(特殊字符串)', str.lstrip())
print('去除右边空格(特殊字符串)', str.rstrip())
运行结果是:
去除前后空格(特殊字符串) 码农飞哥勇敢飞
去除左边空格(特殊字符串) 码农飞哥勇敢飞
去除右边空格(特殊字符串)
码农飞哥勇敢飞
encode()和decode()方法:字符串编码转换
最早的字符串编码是ASCll编码,它仅仅对10个数字,26个大小写英文字母以及一些特殊字符进行了编码,ASCII码最多只能表示256个字符,每个字符只需要占用1个字节。为了兼容各国的文字,相继出现了GBK,GB2312,UTF-8编码等,UTF-8是国际通用的编码格式,它包含了全世界所有国家需要用到的字符,其规定英文字符占用1个字节,中文字符占用3个字节。
- encode() 方法为字符串类型(str)提供的方法,用于将 str 类型转换成 bytes 类型,这个过程也称为“编码”。其语法结构是:
str.encode([encoding="utf-8"][,errors="strict"]) - 将bytes类型的二进制数据转换成str类型。这个过程也称为"解码",其语法结构是:
bytes.decode([encoding="utf-8"][,errors="strict"])
举个例子说明下:
str = '码农飞哥加油'
bytes = str.encode()
print('编码', bytes)
print('解码', bytes.decode())
运行结果是:
编码 b'\xe7\xa0\x81\xe5\x86\x9c\xe9\xa3\x9e\xe5\x93\xa5\xe5\x8a\xa0\xe6\xb2\xb9'
解码 码农飞哥加油
默认的编码格式是UTF-8,编码和解码的格式要相同,不然会解码失败。
序列化和反序列化
在实际工作中我们经常要将一个数据对象序列化成字符串,也会将一个字符串反序列化成一个数据对象。Python自带的序列化模块是json模块。
- json.dumps() 方法是将Python对象转成字符串
- json.loads()方法是将已编码的 JSON 字符串解码为 Python 对象
举个例子说明下:
import json
dict = {'学号': 1001, 'name': "张三", 'score': [{'语文': 90, '数学': 100}]}
str = json.dumps(dict,ensure_ascii=False)
print('序列化成字符串', str, type(str))
dict2 = json.loads(str)
print('反序列化成对象', dict2, type(dict2))
运行结果是:
序列化成字符串 {"name": "张三", "score": [{"数学": 100, "语文": 90}], "学号": 1001} <class 'str'>
反序列化成对象 {'name': '张三', 'score': [{'数学': 100, '语文': 90}], '学号': 1001} <class 'dict'>
本文详细介绍了Python中字符串str的各种常见用法,熟练的掌握str的各种用法是我们的基本功。
Python知识图谱
为了更好帮助更多的小伙伴对Python从入门到精通,我从CSDN官方那边搞来了一套 《Python全栈知识图谱》,尺寸 870mm x 560mm,展开后有一张办公桌大小,也可以折叠成一本书的尺寸,有兴趣的小伙伴可以了解一下------扫描下图中的二维码即可购买。
我本人也已经用上了,感觉非常好用。图谱桌上放,知识心中留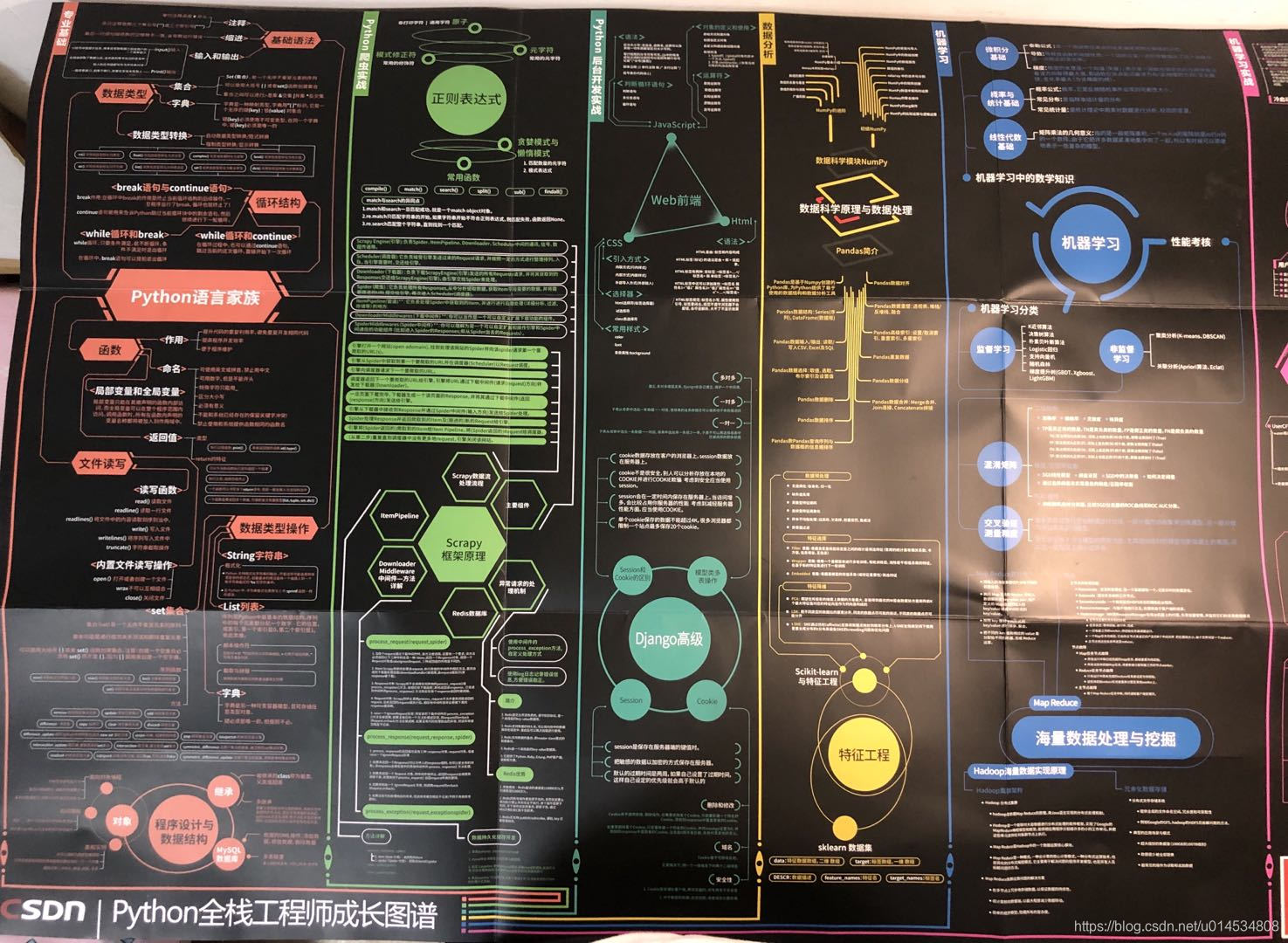
我是码农飞哥,再次感谢您读完本文。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK