

Could We Have Felt Evidence For SDP ≠ P?
source link: https://rjlipton.wpcomstaging.com/2014/03/15/could-we-have-felt-evidence-for-sdp-p/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Could We Have Felt Evidence For SDP ≠ P?
Evaluating mathematical beliefs
Leonid Khachiyan in 1979 caused arguably the most sudden surprise to the West’s popular scientific understanding since the successful launch of Sputnik in 1957. His ellipsoid method gave the first algorithm for linear programming whose polynomial running time was verified. Thanks largely to Narendra Karmarkar it has been superseded by faster interior-point methods, while older algorithms have since been noted to run in polynomial time, but the breakthrough and inspiration came from Khachiyan. Could something like it happen again?
Today Ken and I want to ask whether recent argument over beliefs about 
Khachiyan’s “rocket” had actually left the hangar ten months before, in a January 1979 Doklady Akademii Nauk paper whose title translates into English as, “A polynomial algorithm for linear programming.” As recounted by Berkeley’s Eugene Lawler, it was sighted at a May 1979 meeting Lawler attended in Oberwohlfach, and after Peter Gács and László Lovász supplied proofs missing in the paper, it was pronounced correct at a conference in Montreal. The discovery was picked up in October by Science News, and then by the magazine Science. An allusion by the latter to the NP-complete Traveling Salesman problem was moved to the headline of a Nov. 4 story in England’s Guardian newspaper, and reflected three days later in the New York Times’s front-page screamer, “A Soviet Discovery Rocks World of Mathematics.”
Our point is not to say that linear programming being in 

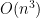

We raise this with regard to the main technical argument in a recent post by Scott Aaronson titled “The Scientific Case for 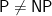


Scott’s Comments and Our Positions
Essentially Scott gave a quite reasonable argument for 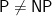
Our purpose with our recent post on a 13-GB certificate of unsatisfiability was not to start a discussion about 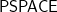
Almost the entire business model of this company is to solve
According to academic research on NP-hard problems, it’s impossible to guarantee that optimal solutions to difficult problems will be found in a reasonable time frame. However, with almost all real-life planning puzzles, you can get excellent results very quickly.
Hence our initial reaction was, who cares about discussions on
But. But Dick couldn’t resist adding some more sections, while Ken made some effort to counter Scott’s facts, counterfactually.
Dick Speaks
I feel compelled to explain why I am open-minded on this question perhaps more than anyone else. I have several reasons that I feel are important to remind all of us:
- In mathematics people have guessed wrong before on famous open questions.
-
The actual theorems about why
-
If
it could still be that
is computable in time
-
If
—while the evidence cited by Scott is properly for an exponential lower bound.

We’ll address the full 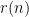

Bad Guesses
I have discussed guesses in mathematics many times before on this blog. One of the biggest issues in guessing wrong is that people do not take seriously the other possibility. Researchers tend not to work on showing
Here are some famous guesses that were essentially off by exponentials. For each I will list the time gap between the initial problem being raised and being solved.
-
The Borsuk Conjecture [60 years]. It was claimed that
was the answer to this geometric conjecture. Many top people worked on it for years and partial results were proved, showing
for some
, and possibly with
in the exponent.
-
Barrington’s Theorem [26 years]. I worked on lower bounds to show that bounded width computation could not compute the majority function. This was joint work with Ashok Chandra and Merrick Furst, which introduced multi-party communication. Then David Barrington came along and proved that bounded width could do all of
. Hmmmm.
-
Law of Small Numbers [118 years].
It was noticed by Gauss thatfor all reasonable size
. Here
is the logarithmic intergal
which is an asympotic approximation to
, the number of primes less than


By the way the “common clock” on 
Weak Theorems and Galactic Algorithms
We do have the theorem that 



The
-
allows
-time algorithm.
-
-time algorithm.
To be sure, some evidence cited by Scott is really for an exponential lower bound on 
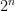
Aram Harrow communicates to us a more-concrete version of this point, which also serves as a bridge to Ken’s musings.
Aram’s Bridging Thoughts
Quoting Aram, with light editing: “One of the stronger reasons for 
But a counter-argument is that all of those seemingly independent researchers would always come up with algorithms that relied on a few kinds of structure—a lot is covered by just two kinds:
- Convexity/absence of local minima—cases where greedy algorithms work.
- Tree structure—cases where dynamic programming, divide-and-conquer, and related ideas work.
This paucity of algorithmic variety can be viewed in (at least) two ways:
-
Algorithms, like oil deposits, are a finite resource. We’ve found all the important ones, and
- The paucity is a sociological phenomenon, due to the fact that all researchers have learned essentially similar math backgrounds.
On the latter, Terry Tao’s recent breakthrough on the Navier-Stokes equations is an example of how much the same ideas keep recirculating, and how much more quickly progress can be made by cross-applying ideas rather than coming up with radically new ones. Going from Erwin Schrödinger’s equation to Peter Shor’s quantum factoring algorithm is a 60-minute lecture, but it took over 60 years (and a change in perspective coming from the computer revolution) to discover. Our lack of algorithms reveals only our lack of creativity, and it is arrogant to posit fundamental limits to mathematics just because we can’t solve a problem. Either way, the central question isn’t so much about
Where does the power of deterministic algorithms come from?
A related question is the power of the Lasserre hierarchy. It has been shown to be effective for a large number of problems, but with a surprisingly small number of truly different techniques. I would love to know whether further work will increase or decrease the number of ways in which we know how to use it; that is, either by discovering new methods or by unifying apparently different methods.”
Ken’s Sixth World
The Lasserre hierarchy builds upon LP’s and SDP’s, and this brings us back to the intro. I (still Dick) remember many people in the 1970’s trying to prove that certain linear/convex programming problems were
What if SDP’s really were hard?
Russell Impagliazzo famously categorized five worlds that are consistent with current knowledge of complexity. Is there room to analyze any more, ones that are inconsistent now, but might have been meaningfully consistent had our field taken a different path?
All of Impagliazzo’s worlds—including ones with 
One known way to get this effect is to narrow the definition of “easy” so that 

Countering Factuals with Counterfactuals
Scott replied to my comment about a possible
Since it would be inelegant and unnatural for the class
to be “severed into two” in this way, I’d say the much likelier possibility is simply that
.
Our point is, perhaps
Theorem 1 If
, then it is possible to compute in polynomial time close approximations to a function
of undirected graphs
that is sandwiched between the
-complete clique number
and chromatic number
, which all coincide whenever neither
Theorem 2 If
is polynomial-time approximable within
, even though it is
.
In the first theorem we have also inverted time by embracing the Strong Perfect Graph Theorem which was proved in 2002 (final in 2006), but this conjecture was strongly felt and makes it transparent that many important families of graphs are perfect. Hence the sweeping tractability of major 


Of course in the light of knowledge we understand how these two famous theorems work. On the latter the Unique Games Conjecture already helps explain how 
Open Problems
Can we make some formal sense of a world where Khachiyan’s breakthrough never happens?
Update 3/18/14: The comments section has some excellent replies, including ones on the argument of the last two sections by Scott Aaronson and by Timothy Gowers.
Update 3/17/14: The Lovász theta-function example replaced the post’s original quoting of Leslie Valiant’s first “Accidental Algorithm” under a mis-memory that LP’s were involved (and SDP’s in later developments). Snipping the irrelevant qualifier, it reads:
Theorem 3 Counting assignments to a certain class of planar formulas is deterministic polynomial-time computable modulo
, or modulo any Mersenne prime, even though it is
or
.
Aside from the fact that this computation belongs to a class called 
Like this:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK