

再次刷新单模型纪录!快手登顶多模态理解权威榜单VCR
source link: https://my.oschina.net/u/4580856/blog/5122678
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
再次刷新单模型纪录!快手登顶多模态理解权威榜单VCR - DLer_JohnSon的个人空间 - OSCHINA - 中文开源技术交流社区
近日,多模态理解领域国际权威榜单 VCR(视觉常识推理,Visual Commonsense Reasoning)刷新了排名,来自国内短视频平台快手研究团队MMU(Multimedia understanding)自研的 VLUA 多模态模型以两个单项成绩「82.3、87.0」和总成绩「72.0」的分数登上榜首。多模态理解领域的权威排行榜纪录,又被来自国内的技术团队刷新了。
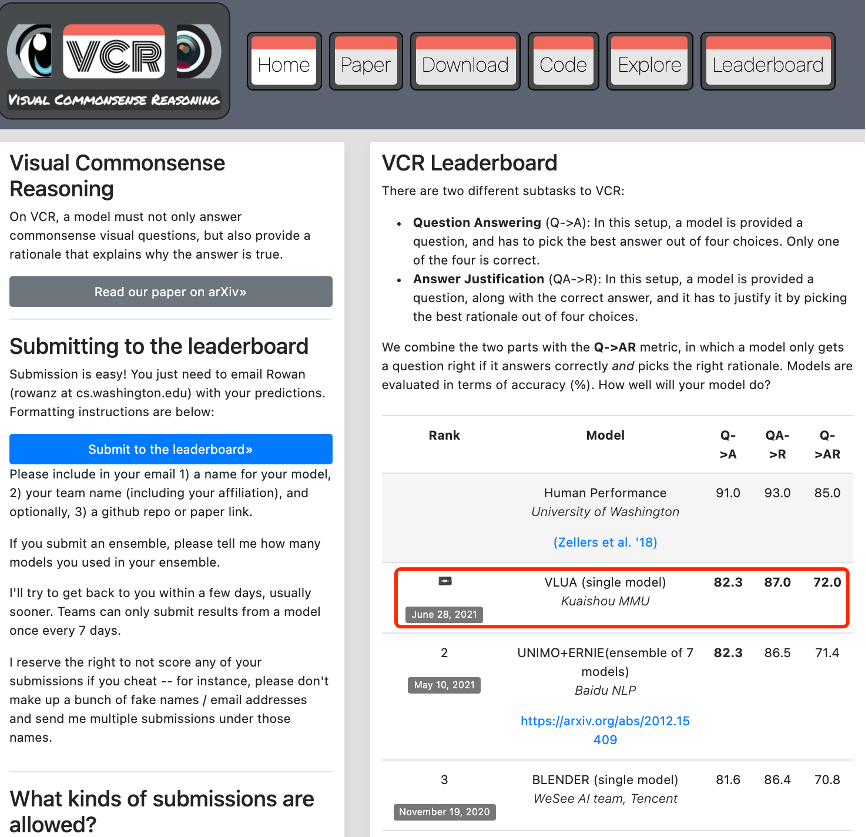
近年来,多模态理解技术在视频内容社区、电商等领域有着广泛的应用场景,VCR 榜单由华盛顿大学等研究机构于 2018 年发起,基于大规模图文多模态数据集,旨在将图像和自然语言理解二者结合,验证多模态模型高阶认知和常识推理的能力,让机器拥有「看图说话」的能力,是多模态理解领域最权威的排行榜之一。 VCR 任务设置了问答 (question answering) 和解释 (rationale) 两个子任务。具体而言,在问答任务中,给定一张图片,计算机要回答一个用自然语言描述的和图片相关的问题;在解释任务中,计算机将在给出答案的基础上,给出为什么选择这个答案的原因。
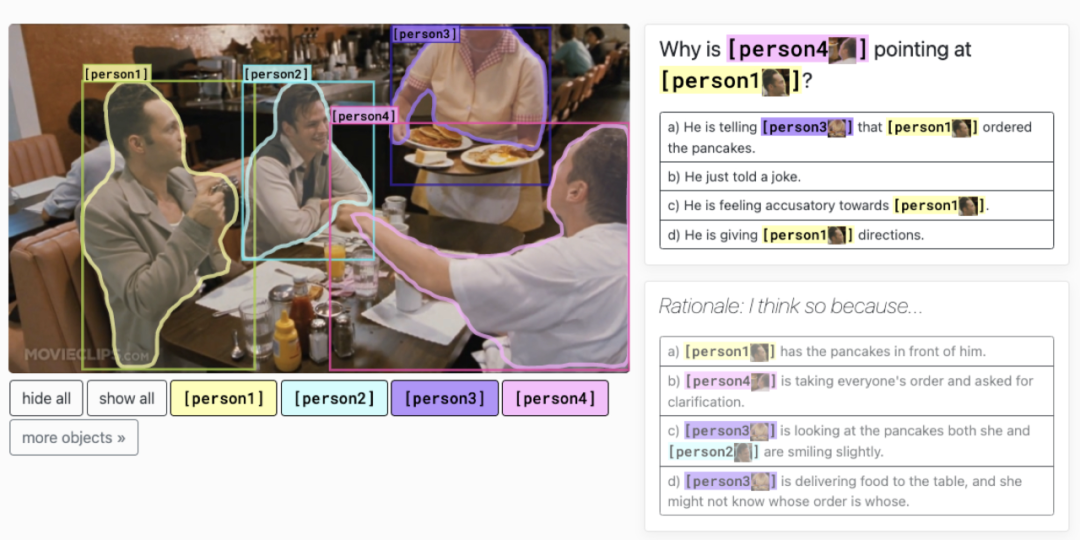
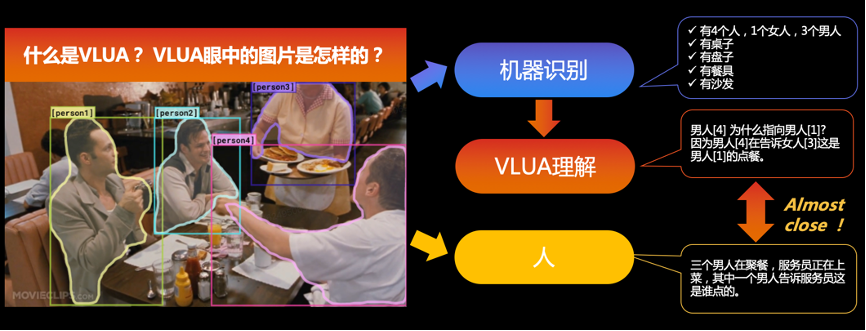
快手自研 VLUA,有何过人之处? 快手团队自主研发的 VLUA(Vision and Language Understanding via a Unified Architecture)多模态算法模型采用单流的 transformer 结构,针对视觉特征和文本特征输入的多样性,设计了统一的多模态特征处理模块,构建了图像背景和前景的信息互补策略,支持局部、全局、浅层、高层等各个维度的特征抽取。
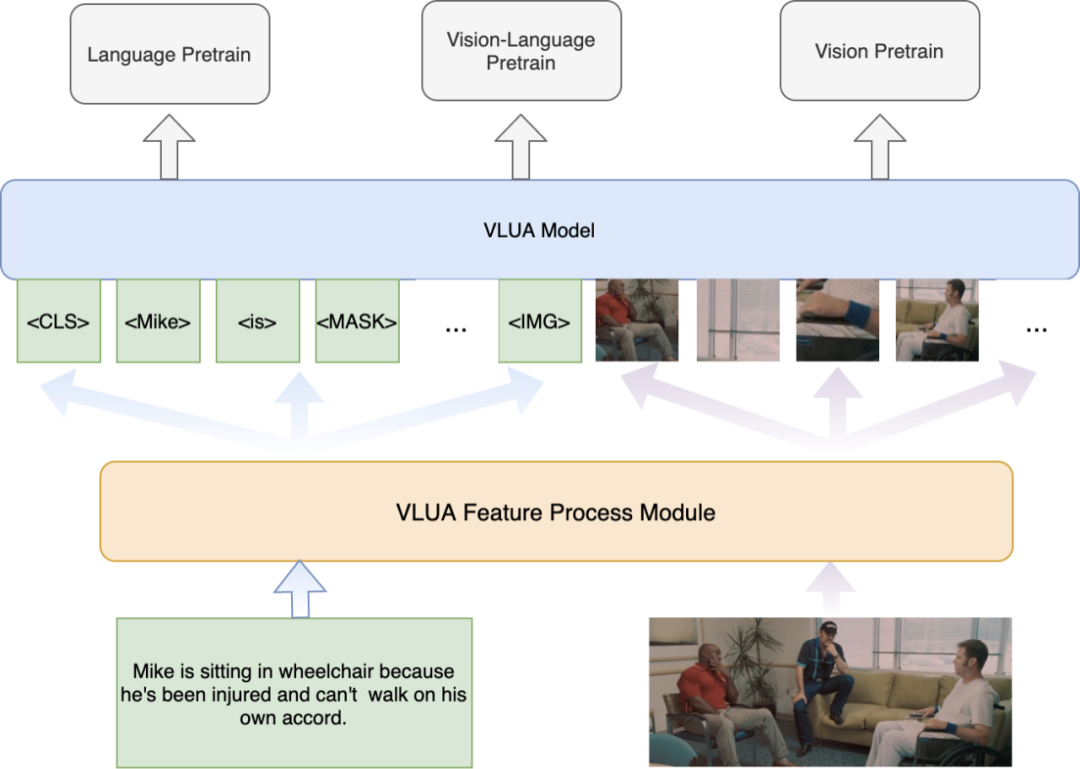

目前,VLUA 已应用于快手视频审核、推荐、搜索、创作等多个业务场景,能够根据应用场景的不同灵活的产出子模型及不同维度的多模态特征。
在视频审核业务中,基于 VLUA 产出的视频内容质量理解模型将视频内容质量进行分层,精确的识别了劣质视频和优质视频,极大了提升了视频审核的效率和社区内优质内容的供给;
在视频推荐业务中,以冷启动场景为例,基于 VLUA 产出的多模态内容理解特征,大幅提升了冷启动的效率,帮助更多的优质内容及优质作者在社区内获得更好的成长;
在视频搜索场景,通过 VLUA 提供的视觉文本对齐的多模态特征,大幅提升了搜索召回的相关性;
在视频创作方面,通过 VLUA 对视频多模态信息实现高层次的理解,为智能创作过程提供更加精准的素材检索能力,提升生成内容的流畅性及可读性。例如在直播场景,定位直播中的精彩片段,混剪形成有趣、高密度的短视频;在商业化场景,通过分析广告主广告素材或者挖掘站内优质素材,混剪形成新的创意广告,丰富广告数量。
招聘邮箱:[email protected]
重磅!DLer-计算机视觉&Transformer群已成立!
大家好,这是计算机视觉&Transformer论文分享群里,群里会第一时间发布最新的Transformer前沿论文解读及交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、视频超分、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如Transformer+上交+小明)

👆 长按识别,邀请您进群!
本文分享自微信公众号 - 深度学习技术前沿(gh_a540734f538c)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK